实验|Vachel 算力支持|幻方AIHPC
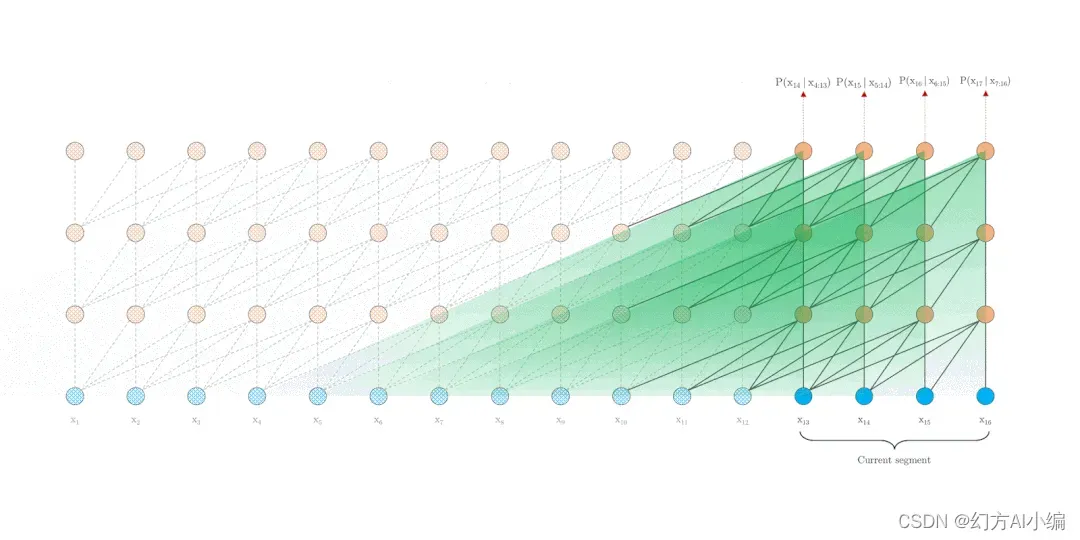
长时间序列预测(Long Sequence Time-Series Forecasting,以下称为 LSTF)在现实世界中是比较基础但又十分重要的研究场景,例如商品销量及库存的预测、电力消耗的规划、股票价格、疾病传播与扩散等实际问题。然而LSTF因为其历史数据量大、计算复杂性高、预测精度要求高,一直以来并没有取得太好的效果。
今年人工智能顶级大会AAAI的最佳论文奖项中有一篇来自北京航空航天大学:Informer,其主要的工作是改造 Transfomer 算法来实现LSTF,并开源了代码与数据。笔者最近在幻方AI的萤火平台上尝试复现了该论文的实验,为大家带来第一手的测试体验。(原文链接见文末附录)
模型介绍
近年来的研究表明,Transformer具有提高预测能力的潜力。然而,Transformer也存在几个问题,使其不能直接适用于LSTF问题,例如时间复杂度、高内存使用和“编码-解码”体系结构的固有局限性。为了解决这些问题,作者基于Transformer设计了一种适用于LSTF问题的模型,即Informer模型,该模型具有三个显著特征:
-
ProbSpare self-attention机制,有效降低了时间复杂度和内存使用量。
-
通过将级联层输入减半来突出Self-attention中的主导因子,有效地处理过长的输入序列。
-
对长时间序列进行一次预测而不是一步步方式进行预测,极大提高了长序列预测的推理速度。
Informer模型的整体框架如下图所示,可以看出该模型仍然保存了Encoder-Decoder的架构:
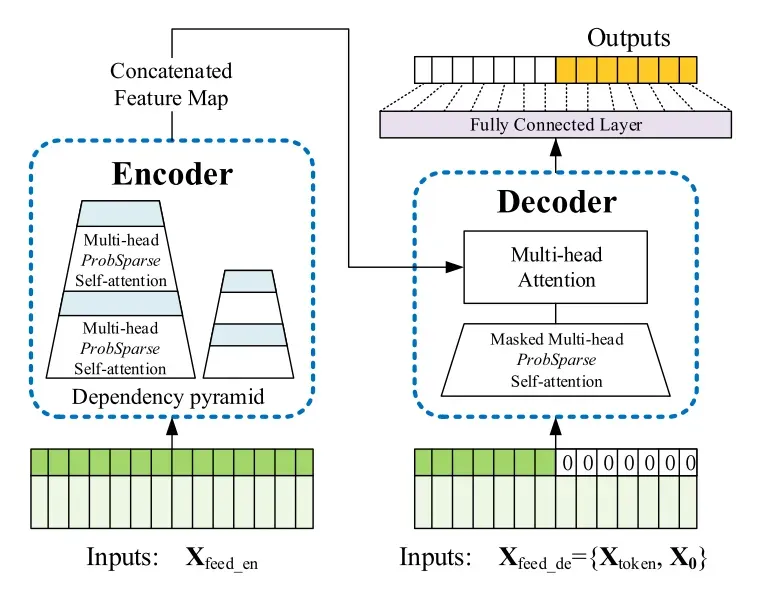
编码过程(左):编码器接收长序列输入(绿色部分),通过ProbSparse自注意力模块和自注意力蒸馏模块,得到特征表示。ProbSparse自注意力机制利用稀疏矩阵来替代原来的注意力矩阵,大幅减少算力需求的同时并保持的良好的性能。
解码过程(右):解码器接收长序列输入(预测目标部分设置为0),通过多头注意力与编码特征进行交互,最后直接预测输出目标部分(橙黄色部分)。这里作者采用的是一次生成式预测方式,并说明该方式相比step-by-step方式推理速度更快且效果相当。
至于特征输入,在 LSTF 问题中,时序建模不仅需要局部时序信息还需要层次时序信息,如星期、月和年等,以及突发事件或某些节假日等。经典自注意力机制很难直接适配,因此Informer提出了三层特征输入形式,如下图所示:
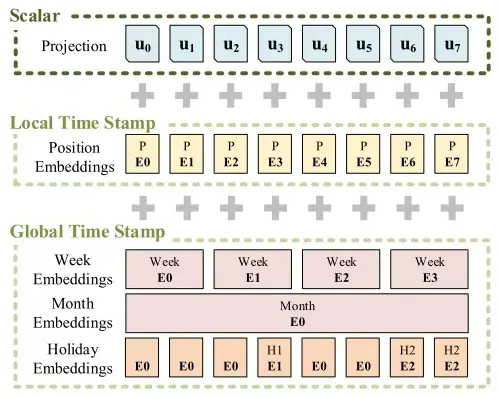
Informer的输入分为了三种位置嵌入表示:
-
局部时间戳,即Transformer中的固定位置嵌入。
-
全局时间戳。对于层次时间信息,构建一个词汇表,通过Embedding特征表示每一个词汇。
-
对齐维度,使用一维卷积将输入的序列标量转化为向量。
模型实践
看完上述的介绍,是否有想一试算法的冲动了呢?笔者也是带着好奇,在幻方萤火二号上尝试复现论文中的实验效果。
作者的开源比较完备,包含ETT(变压器温度)、ECL(耗电量)和WTH(气象)3个数据集,采用PyTorch实现且没有特殊包依赖的模型代码。作者提供了执行的脚本 scripts/*.sh,包括了不同的实验参数:
### M
python -u main_informer.py –model informer –data ETTh1 –features M –seq_len 48 –label_len 48 –pred_len 24 –e_layers 2 –d_layers 1 –attn prob –des ‘Exp’ –itr 5 –factor 3
python -u main_informer.py –model informer –data ETTh1 –features M –seq_len 96 –label_len 48 –pred_len 48 –e_layers 2 –d_layers 1 –attn prob –des ‘Exp’ –itr 5
python -u main_informer.py –model informer –data ETTh1 –features M –seq_len 168 –label_len 168 –pred_len 168 –e_layers 2 –d_layers 1 –attn prob –des ‘Exp’ –itr 5
### S
python -u main_informer.py –model informer –data ETTh1 –features S –seq_len 720 –label_len 168 –pred_len 24 –e_layers 2 –d_layers 1 –attn prob –des ‘Exp’ –itr 5
python -u main_informer.py –model informer –data ETTh1 –features S –seq_len 720 –label_len 168 –pred_len 48 –e_layers 2 –d_layers 1 –attn prob –des ‘Exp’ –itr 5
python -u main_informer.py –model informer –data ETTh1 –features S –seq_len 720 –label_len 336 –pred_len 168 –e_layers 2 –d_layers 1 –attn prob –des ‘Exp’ –itr 5
一共有60组不同的实验,我们用幻方萤火二号快速运行一下。
接入萤火二号
萤火提供了统一的训练管理平台,可以将大量的训练任务依据优先级负载均衡到不同的GPU上执行。我们只需加入几行代码,便可以把训练任务提交给萤火,喝杯咖啡,坐等结果。
1. 登录幻方萤火二号,引入hf_env, hfai
./main_informer.py
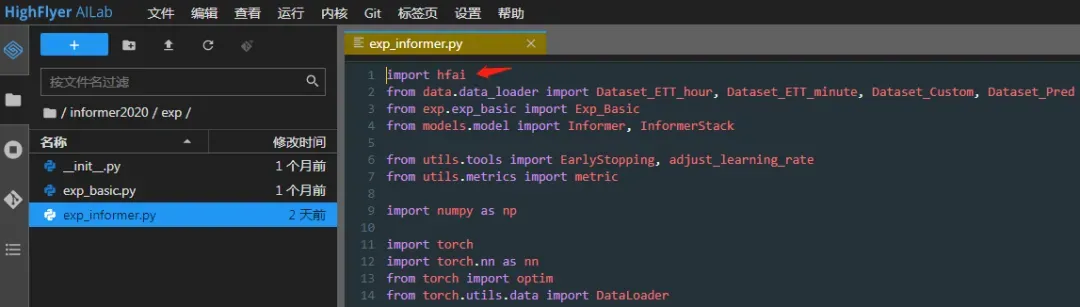
./exp/exp_informer.py
2. 对于每一轮训练,加入接收集群调度的逻辑代码,并做好模型checkpoint的保存。
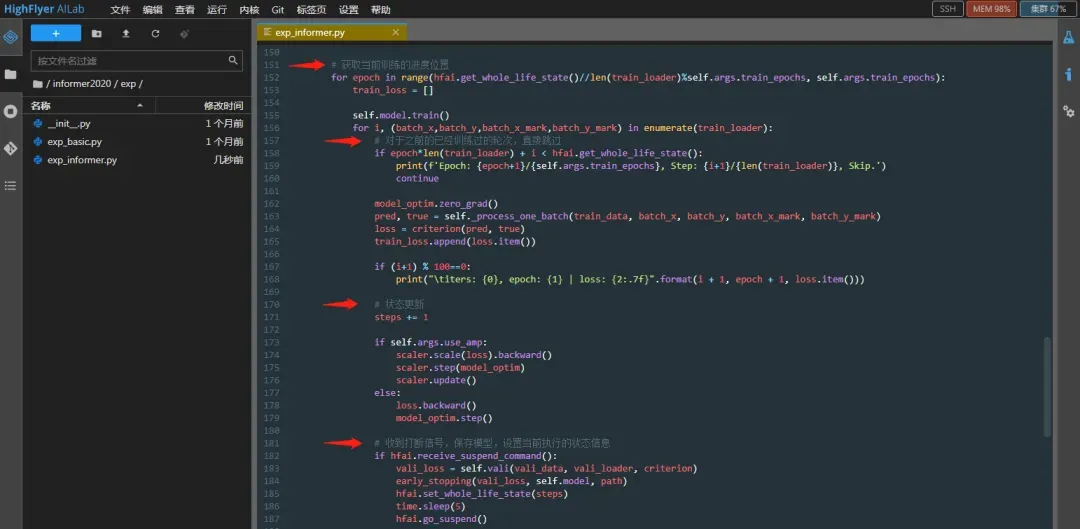
3. 提交任务,等待执行结果。
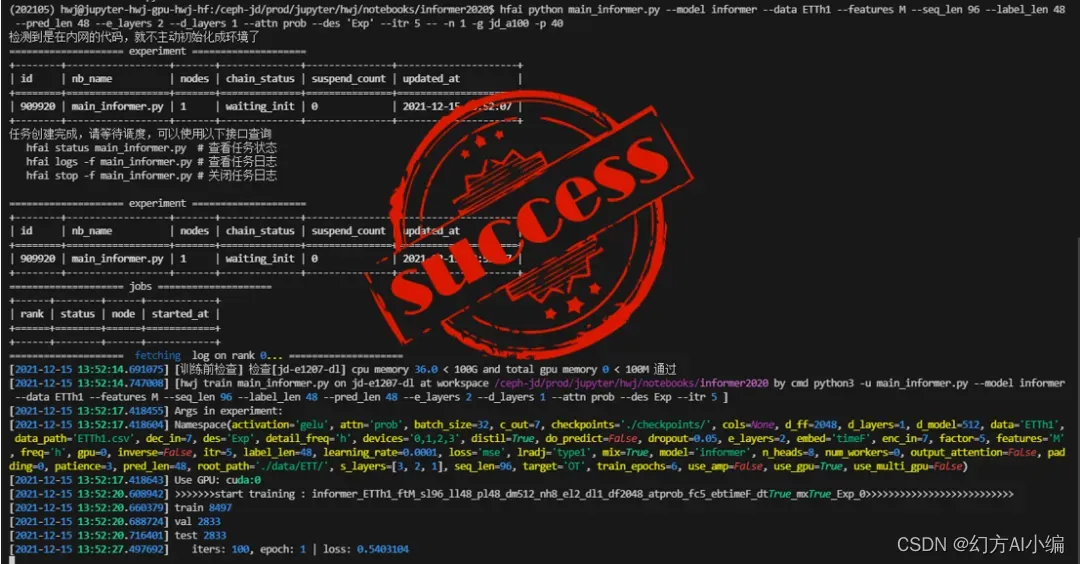
Informer开源的测试数据不大(10MB以内),集群测试中单个Epoch执行花费6-7s左右。我选择对每组实验配一块A100卡,全部60组实验历时1小时48分完成。在长时序单变量预测和长时序多变量预测这两个任务上,测试结果基本与论文所公布的MSE和MAE结果吻合,在某些参数上甚至跑出了更好的成绩。
体验总结
Informer作为今年AAAI的Best Paper之一,对Transformer模型进行了很多切实有效的改进,使其计算、内存和体系结构更加高效。同时,作者也做了完整的开源,代码结构清晰,笔者能够很流畅的对其进行复现。借助超算,我们很快就拿到了全部的实验数据。
综合体验打分如下:
01:研究新颖度 ★★
该模型着眼于长时间序列的预测问题,是一个广泛研究的基础课题。
02:开源指数 ★★★★★
数据和代码都已开源,代码逻辑清晰可读性高。
03:算力需求 ★★
数据量小,模型计算、内存和体系结构均已优化,普通高性能PC即可运行。
04:通用指数 ★★★
模型是对Transformer的优化,深入改进了自注意力机制,能适用于长序列预测场景,其他场景待验证。
05:模型适配度 ★★★★★
依赖简单,PyTorch框架构建的模型,只需要修改几行代码就能在萤火超算上执行。
附录
论文标题:
Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
原文地址:https://ojs.aaai.org/index.php/AAAI/article/view/17325
源码地址:
https://github.com/zhouhaoyi/Informer2020
文章出处登录后可见!