先附代码和文章,可以先结合来看
代码:GitHub – LeapLabTHU/ACmix: Official repository of ACmix (CVPR2022)
文章:[2111.14556] On the Integration of Self-Attention and Convolution (arxiv.org)
ACmix是卷积网络和transformer两种强大的网络优势的集合,具有较低的计算开销,同时也能提升网络性能,在卷积网络和transformer各行其是的今天,是一种融合两种优势的不错方法。
这篇文章此次先介绍下ACmix的结构和代码,该结构的具体应用有时间更新。
首先,该作者认为一个kxk卷积可以看做是由kxk个1×1卷积的拼接构成的,而transformer中的线性层也可以看做是一个1×1的卷积,这是这篇文章成立的前提。
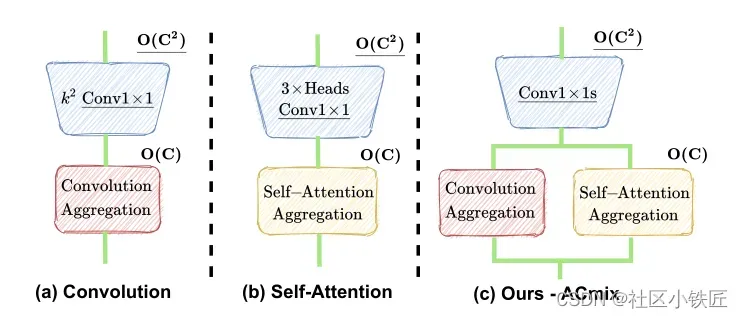
其次,作者在此基础上探索将两者的优势结合,提出如下图所示的结构,在两者都是由1×1卷积构成的前提下,将1×1卷积进行不同的组合构成卷积或者self-Attention,再将两种结构并行连接。
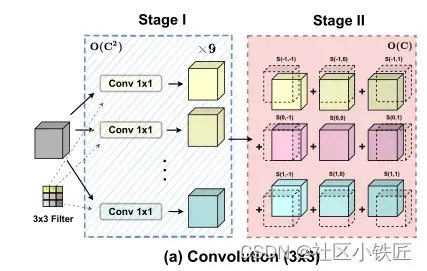
首先卷积部分,当一个3×3卷积滑过一张图时,可分为两阶段,第一阶段是采用9个1×1卷积分别对图片做卷积操作,第二阶段是将得到的9个特征图按照一定的方式排列求和。例如,3×3卷积核的左上角的点不能与图片右上角像素点做乘积,而图片左上角像素点只与卷积核左上角权重相乘,则相应位置的1×1卷积应该往左上方偏移一个像素同时舍弃掉最右列与最下排的像素点,同理,可分析出9个1×1卷积的排列方式如下图所示:
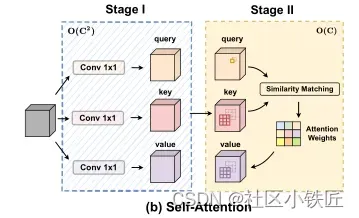
其次, self-Attention也可分为两个阶段如下图所示,第一阶段是3个1×1卷积,第二阶段是注意力权重的计算和聚集局部特征。具体操作可参考代码。
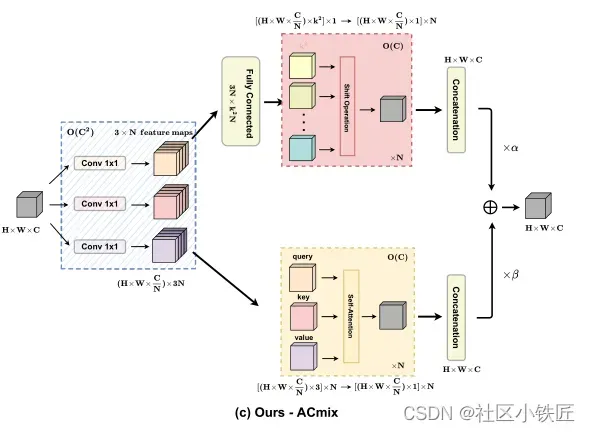
最后,ACmix是将卷积与自注意力的第一阶段合并,再各自并行第二阶段,得到的结果加权求和如下图所示:
具体代码及部分注释如下:
# 生成(1,2,h,w)形状的张量,参与后面位置编码操作
def position(H, W, is_cuda=True):
if is_cuda:
loc_w = torch.linspace(-1.0, 1.0, W).cuda().unsqueeze(0).repeat(H, 1)
loc_h = torch.linspace(-1.0, 1.0, H).cuda().unsqueeze(1).repeat(1, W)
else:
loc_w = torch.linspace(-1.0, 1.0, W).unsqueeze(0).repeat(H, 1)
loc_h = torch.linspace(-1.0, 1.0, H).unsqueeze(1).repeat(1, W)
loc = torch.cat([loc_w.unsqueeze(0), loc_h.unsqueeze(0)], 0).unsqueeze(0)
return loc
def stride(x, stride):
b, c, h, w = x.shape
return x[:, :, ::stride, ::stride] # 前两维全取,在h和w的维度上以stride的步长取值
def init_rate_half(tensor):
if tensor is not None:
tensor.data.fill_(0.5) # 将tensor中的值都填充为0.5
def init_rate_0(tensor):
if tensor is not None:
tensor.data.fill_(0.)
class ACmix(nn.Module):
def __init__(self, in_planes=10, out_planes=10, kernel_att=7, head=4, kernel_conv=3, stride=1, dilation=1):
super(ACmix, self).__init__()
self.in_planes = in_planes # 输入通道
self.out_planes = out_planes # 输出通道
self.head = head
self.kernel_att = kernel_att
self.kernel_conv = kernel_conv
self.stride = stride
self.dilation = dilation # 扩张
self.rate1 = torch.nn.Parameter(torch.Tensor(1))
self.rate2 = torch.nn.Parameter(torch.Tensor(1))
self.head_dim = self.out_planes // self.head
self.conv1 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv3 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv_p = nn.Conv2d(2, self.head_dim, kernel_size=1)
self.padding_att = (self.dilation * (self.kernel_att - 1) + 1) // 2
# torch.nn.ReflectionPad2d;对输入图像以最外围像素为对称轴,做四周的轴对称镜像填充
self.pad_att = torch.nn.ReflectionPad2d(self.padding_att)
# nn.Unfold():将Tensor切割成kernel_size大小的块,输出是(bs,Cxkernel_size[0]xkernel_size[1],L)
self.unfold = nn.Unfold(kernel_size=self.kernel_att, padding=0, stride=self.stride)
self.softmax = torch.nn.Softmax(dim=1)
self.fc = nn.Conv2d(3*self.head, self.kernel_conv * self.kernel_conv, kernel_size=1, bias=False)
self.dep_conv = nn.Conv2d(self.kernel_conv * self.kernel_conv * self.head_dim, out_planes, kernel_size=self.kernel_conv, bias=True, groups=self.head_dim, padding=1, stride=stride)
self.reset_parameters()
def reset_parameters(self):
init_rate_half(self.rate1) # 把rate1设置为0.5
init_rate_half(self.rate2) # 把rate2设置为0.5
kernel = torch.zeros(self.kernel_conv * self.kernel_conv, self.kernel_conv, self.kernel_conv) # 9*3*3
for i in range(self.kernel_conv * self.kernel_conv):
kernel[i, i//self.kernel_conv, i%self.kernel_conv] = 1. # 将长方体对角线上的设置为1
kernel = kernel.squeeze(0).repeat(self.out_planes, 1, 1, 1)
self.dep_conv.weight = nn.Parameter(data=kernel, requires_grad=True) # 加入位置编码
self.dep_conv.bias = init_rate_0(self.dep_conv.bias)
def forward(self, x):
q, k, v = self.conv1(x), self.conv2(x), self.conv3(x)
scaling = float(self.head_dim) ** -0.5
b, c, h, w = q.shape
h_out, w_out = h//self.stride, w//self.stride # 等效后的尺寸
# ### att
# ## positional encoding -1到1上分别有h和w个数的组成的(1,head_dim,h,w)
pe = self.conv_p(position(h, w, x.is_cuda))
q_att = q.view(b*self.head, self.head_dim, h, w) * scaling
k_att = k.view(b*self.head, self.head_dim, h, w)
v_att = v.view(b*self.head, self.head_dim, h, w)
if self.stride > 1: # 在 h,w方向按步长取值
q_att = stride(q_att, self.stride)
q_pe = stride(pe, self.stride)
else:
q_pe = pe
unfold_k = self.unfold(self.pad_att(k_att)).view(b*self.head, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out) # b*head, head_dim, k_att^2, h_out, w_out
unfold_rpe = self.unfold(self.pad_att(pe)).view(1, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out) # 1, head_dim, k_att^2, h_out, w_out
# 求和会降维
# q*k
att = (q_att.unsqueeze(2)*(unfold_k + q_pe.unsqueeze(2) - unfold_rpe)).sum(1) # (b*head, head_dim, 1, h_out, w_out) * (b*head, head_dim, k_att^2, h_out, w_out) -> (b*head, k_att^2, h_out, w_out)
att = self.softmax(att)
# q*k*v
out_att = self.unfold(self.pad_att(v_att)).view(b*self.head, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out)
out_att = (att.unsqueeze(1) * out_att).sum(2).view(b, self.out_planes, h_out, w_out)
## conv
f_all = self.fc(torch.cat([q.view(b, self.head, self.head_dim, h*w), k.view(b, self.head, self.head_dim, h*w), v.view(b, self.head, self.head_dim, h*w)], 1))
f_conv = f_all.permute(0, 2, 1, 3).reshape(x.shape[0], -1, x.shape[-2], x.shape[-1])
out_conv = self.dep_conv(f_conv)
return self.rate1 * out_att + self.rate2 * out_conv
#具体ACmix我本人测试了下,相比于普通卷积效果有所提升,但是相应计算量也比较大,具备条件的可以采用。
文章出处登录后可见!