文章目录
前言
🗿 hello大家好啊,我是作家桑。本文为大家介绍提升 Python 代码性能的六个技巧,希望大家看完有所收获。
为什么要写本文?
首先讨厌 Python 的人呢,总是会吐槽 Python 的性能速度慢。但是事实上程序运行速度的快慢都在很大程度上取决于编写程序的开发人员,以及开发人员的算法能力和对代码的优化能力。Python 虽然在运行效率上有所欠缺,但是值得一提的是在开发效率方面 Python 却比其它编程语言高很多。为了弥补 Python 在运行效率上的不足,所以笔者开始创作本文为大家介绍提升 Python 代码性能的技巧。
某乎上的一位网友对 Python 的吐槽:

1、代码性能检测
在对代码进行优化之前,通常需要检测是哪些代码片段拖慢了整个程序的运行速度。在这里笔者推荐三个方法帮助开发者们找出程序的瓶颈,这样就知道应该把注意力放在哪里。
以一个 Python 实现斐波那契数列的程序为示例:
# 斐波那契数列
def Fibonacci():
a, b = 0, 1
i = 0
while i < 100:
print(b)
a, b = b, a+b
i += 1
Fibonacci()
1.1、使用 timeit 库
timeit 模块是 Python 的内置模块。timeit 模块致力于衡量代码的性能,模块内提供了许多个函数和类,以便开发者能够精确地测量代码的执行时间。timeit 模块用法较为简单,适合用来计算一小段代码的运行时间。
代码示例:
import timeit
def Fibonacci():
a, b = 0, 1
i = 0
while i < 100:
print(b)
a, b = b, a+b
i += 1
result = timeit.timeit(Fibonacci, number=5)
print(f"Fibonacci函数的运行时间为: {result}")
运行结果:

1.2、使用 memory_profiler 库
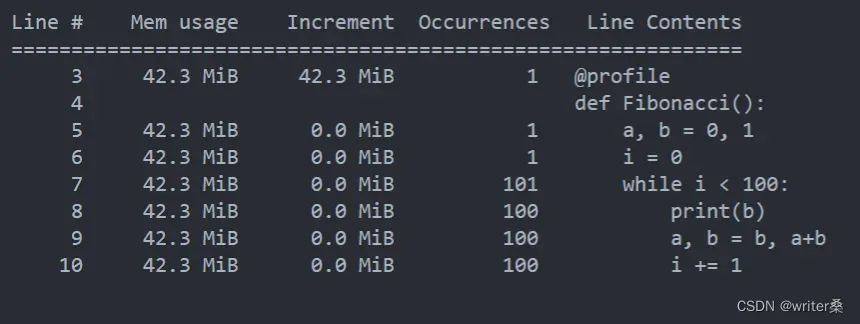
memory_profiler 是 Python 的第三方库(需要使用 pip 命令进行安装),是一个可根据每行代码查看内存占用的工具。开发者使用 memory_profiler 库可以有效的定位到程序中占有内存最多的代码,以此找到程序运行的瓶颈。
pip 命令安装:

代码示例:
from memory_profiler import profile
@profile
def Fibonacci():
a, b = 0, 1
i = 0
while i < 100:
print(b)
a, b = b, a+b
i += 1
Fibonacci()
运行结果:
1.3、使用 line_profiler 库
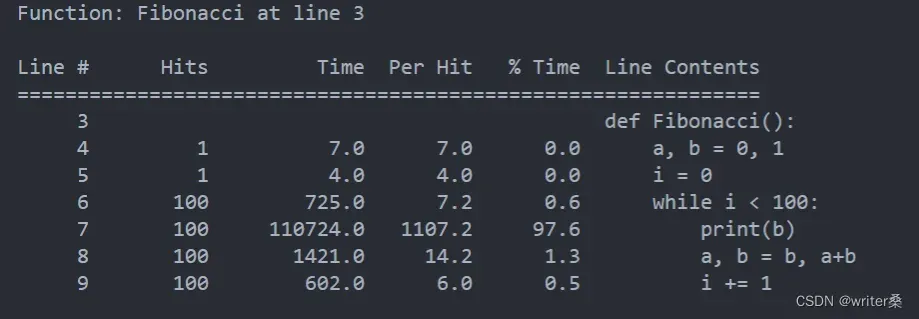
和 memory_profiler 类似,line_profiler 也是 Python 的第三方库,是一个可以逐行参看代码运行耗时的分析工具。
代码示例:
from line_profiler import LineProfiler
def Fibonacci():
a, b = 0, 1
i = 0
while i < 100:
print(b)
a, b = b, a+b
i += 1
lp = LineProfiler()
lp_wrap = lp(Fibonacci)
lp_wrap()
# 输出统计数据
lp.print_stats()
运行结果:
接下来就开始介绍提升 Python 代码性能的六个技巧。
2、使用内置函数和库
Python 的内置函数和库与我们常用的自定义函数、自定义数据类型相比,运行速度会显得非常快。这主要是因为内置数据类型的底层是使用 C 语言实现的,而 C 语言又是目前为止执行效率最高的高级语言,这是使用 Python 所无法比较的。而且 Python 的开发团队也对这些内置函数和库进行了良好的测试和优化。
示例代码:
my_list = []
word_list = "hello,world"
for word in word_list:
my_list.append(word.upper())
print(my_list)
更好的方法:
word_list = "hello,world"
# 使用内置map函数
my_list = map(str.upper, word_list)
print(list(my_list))
3、使用内插字符串 f-string
在 Python 程序中,使用支持插值的 f-string 取代 C 风格的格式字符串与 str.format 方法,会使得字符串操作效率得到提高。根据《Effective Python》一书中的介绍, 使用 f-string 是个简洁而强大的机制,它在简洁性、可读性和速度方面都比其他构建字符串的方式要更好。
示例代码:
places = 3
number = 1.23456
my_str = "number值和places值分别为{0}和{1}".format(number, places)
print(my_str)
更好的方法:
places = 3
number = 1.23456
my_str = f"number值和places值分别为{number}和{places}"
print(my_str)
4、使用列表推导式
在小片段的 Python 代码中,使用列表推导式代替循环语句可以使得代码更加简洁易读;在大型项目中,相较于使用循环语句,使用列表推导式的执行效率也会更高。这是因为列表推导式是直接在 C 语言的环境下运行的,所以速度更快,而循环语句的解析执行往往比列表推导式的步骤更多,所以速度就更慢。
示例代码:
my_list = []
# 计算1到100以内的奇数
for i in range(1, 100):
if i % 2 == 1:
my_list.append(i)
print(my_list)
更好的方法:
my_list = [i for i in range(1, 100) if i % 2 == 1]
print(my_list)
5、使用 lru_cache 装饰器缓存数据
将程序执行时的信息存储在缓存中可以使程序运行的更加高效。在 Python 中也可以导入functools 库中的 lru_cache 装饰器来实现缓存操作,该操作会在内存中存储特定类的缓存,以此来达到程序更快的驱动速度。
示例代码:
import time
def my_func(x):
time.sleep(2) # 模拟程序执行时间
return x
print(my_func(1))
print("=========")
print(my_func(1))
更好的方法:
import functools
import time
# 最多缓存128个不同的结果
@functools.lru_cache(maxsize=2)
def my_func(x):
time.sleep(2) # 模拟程序执行时间
return x
print(my_func(1))
print("=========")
print(my_func(1)) # 结果已被缓存,无需等待立即返回
6、针对循环结构的优化
在通常情况下,循环语句在程序中的执行总是会占据大量时间。因此我们开发 Python 程序时都会强调优化其中的循环结构,比方说避免在一个循环中使用点操作符和不必要的重复操作等。
示例代码:
my_list = []
word_list = ["hello,", "word"]
for word in word_list:
new_str = str.lower(word) # 不必要的重复操作和点运算符
my_list.append(new_str)
print(my_list)
更好的方法:
my_list = []
word_list = ["hello,", "word"]
lower = str.lower
for word in word_list:
my_list.append(lower(word))
print(my_list)
7、选择合适算法和数据结构
提到代码的运行效率,就不得不提到算法和数据结构能力了。 算法也就是程序解决问题的步骤,而数据结构是指数据的存储和组织。选择合适的算法和数据结构,可以在很大程度上提升 Python 代码的运行效率。
示例代码:
# 在有序数组中,使用二分查找算法查找元素要比使用顺序查找算法效率更高
def sequential_search(nums,target):
for num in nums:
if num == target:
return nums.index(num)
return -1 # 返回-1表示没有找到目标元素
nums = [1, 8, 10, 11, 22]
target = 11
print(sequential_search(nums, target))
更好的方法:
# 二分查找
def binary_search(nums,target):
first,last = 0, len(nums) - 1 # 定义数组的第一个元素下标和最后一个元素下标
while first <= last: #左闭右闭区间
mid_index = (first + last) // 2 #中间元素的下标值
if nums[mid_index] < target:
first = mid_index + 1
elif nums[mid_index] > target:
last = mid_index - 1
else:
return mid_index
return -1
nums = [1, 8, 10, 11, 22]
target = 11
print(binary_search(nums, target))
8、推荐书籍
在文章的最后,为了能够让大家编写高质量的 Python 代码,推荐给大家一本书叫 《Effective Python》,书中讲的是编写高质量 Python 代码的90个有效方法。

结语
🎪 以上就是提升 Python 代码性能的技巧介绍啦,希望对大家有所帮助。感谢大家的支持。
文章出处登录后可见!