1、背景:
最近在工作中遇到越来越多的的使用pandas或者python来处里写入操作,尤其是对excel文件或者csv文件的操作更是常见,这里将写入操作总结如下,方便记忆,也分享给大家,希望对阅读者能够有所帮助
2、pandas写入数据的各种场景使用详解
2.1、df.to_excel()参数详解
df.to_excel(
excel_writer, #存放excel文件的地址。如果是只写文件名,不写具体的地址也可。会和py文件存放到一起。
sheet_name='Sheet1', #sheet的名字。一般默认为sheet1
na_rep='', #缺失值表示方式,一般默认为''。
float_format=None, #格式化浮点数的字符串。
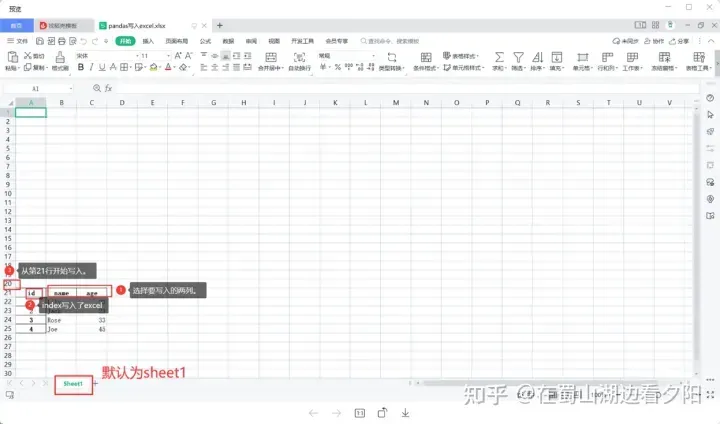
columns=None, #要写入excel中的列。list。一般默认None,即全部写入。
header=True, #header即列名是否为columns,一般默认为True。
index=True, #index是否写入excel,一般默认为True。
index_label=None, #要写入excel中的index列。
startrow=0, #从哪一行开始写入数据。默认为0,即第一行。
startcol=0, #从哪一列开始写入数据。默认为0,即第一列。
engine=None, #可选参数, 用于写入要使用的引擎, openpyxl或xlsxwriter
merge_cells=True, #返回布尔值, 其默认值为True。它将MultiIndex和Hierarchical行写为合并的单元格。
encoding=_NoDefault.no_default, #默认为'utf-8'
inf_rep='inf', #可选参数, 默认值为inf。它通常表示无穷大。
verbose=_NoDefault.no_default, #它的默认值为True。返回布尔值。它用于在错误日志中显示更多信息。
freeze_panes=None, #整数的元组(长度2),默认为None。可选参数, 用于指定要冻结的最底部一行和最右边一列。
storage_options=None#
)2.2 写入一个sheet表中
【注:要写入的excel和sheet已存在,则会覆盖】
import pandas as pd
#创建一个数据
df = pd.DataFrame({
'name':['Lily','Jack','Rose','Joe'],
'age':[23,23,33,45],
'job':['student','doctor','worker','lawyer']
},index=range(1,5),
)
#将index重新命名为id
df.index.name='id'
# print(df)
#写入excel
df.to_excel(r'C:\Users\XXXXXX\Desktop\pandas写入excel.xlsx',index=True,columns=['name','age'],header=True,startrow=20)
3 同一个excel中写入多个sheet,sheet名不同
3.1 利用pd.ExcelWriter()写入多个sheet中
pd.ExcelWriter(
path, #写入的excel的存放路径
engine=None, #一般默认为io.excel.<extension>.writer,用于编写的引擎。(目前这个参数不大懂。)
date_format=None, #设置写入excel的日期格式。如"YYYY-MM-DD"
datetime_format=None, #设置写入excel的日期时间格式。如"YYYY-MM-DD HH:MM:SS"
mode='w', #{"w","a"},一般默认为"w"。使用文件的模式,是追加还是写入。
**engine_kwargs
)
3.2 利用pd.ExcelWriter()写入多个sheet中
import pandas as pd
from pandas import ExcelWriter
#创建一个数据
df = pd.DataFrame({
'name':['Lily','Jack','Rose','Joe'],
'age':[23,23,33,45],
'job':['student','doctor','worker','lawyer']
},index=range(1,5),
)
#将index重新命名为id
df.index.name='id'
# print(df)
#设置存入路径
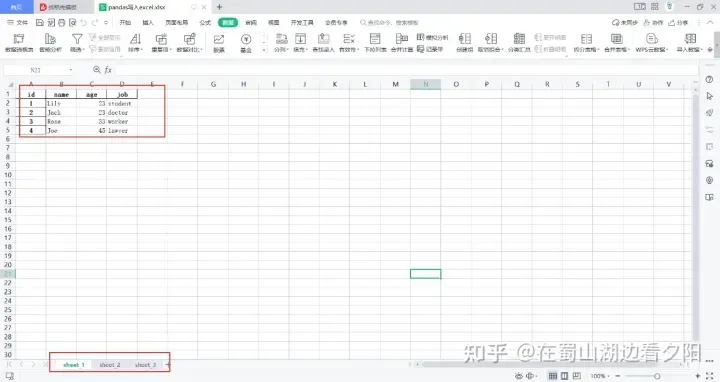
with ExcelWriter(r'C:\Users\XXXXXX\Desktop\pandas写入excel.xlsx',mode='w') as writer:
for i in ['sheet_1','sheet_2','sheet_3']:
df.to_excel(writer,sheet_name=i)
writer.save()
3.3 在原来的sheet中追加几个sheet表。(即不能覆盖原来的数据)
import pandas as pd
from pandas import ExcelWriter
#创建一个数据
df = pd.DataFrame({
'name':['Lily','Jack','Rose','Joe'],
'age':[23,23,33,45],
'job':['student','doctor','worker','lawyer']
},index=range(1,5),
)
#将index重新命名为id
df.index.name='id'
# print(df)
#设置存入路径,设置引擎,这是使用文件的模式。
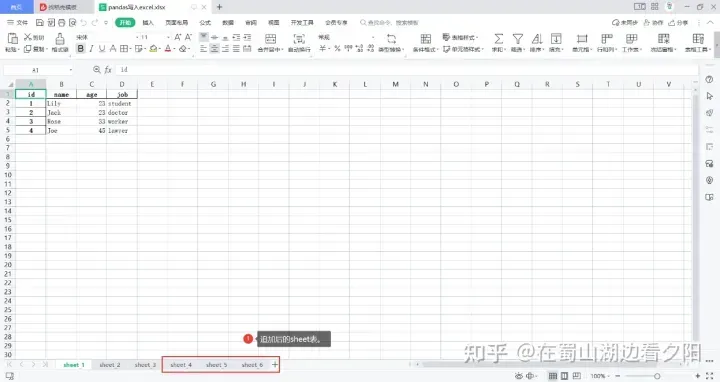
with ExcelWriter(r'C:\Users\XXXXXX\Desktop\pandas写入excel.xlsx',engine='openpyxl',mode='a') as writer:
for i in ['sheet_4','sheet_5','sheet_6']:
df.to_excel(writer,sheet_name=i)
writer.save()
4 在同一个excel,同一个sheet表中追加数据
【注:这里有两种思路
1)先读取原表,将现有数据与原表数据拼接后再写入;
2)直接追加】
4.1 先读取原表,将现有数据与原表数据拼接后再写入;
【注:将df_new写入excel,这个是只针对一个sheet的表格,如果是多个sheet,是消失的。因为,这其实相当于删除原来的,新建了一个表。】
import pandas as pd
#读取Excel中的数据
df_0 = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas写入excel.xlsx',sheet_name='sheet_1')
#修改一下索引,将id改成索引。
df_0 = df_0.set_index(keys=['id'])
print(df_0)
#创建一个数据
df = pd.DataFrame({
'name':['Lily','Jack','Rose','Joe'],
'age':[23,23,33,45],
'job':['student','doctor','worker','lawyer']
},index=range(1,5),
)
#将index重新命名为id
df.index.name='id'
print(df)
df_new = pd.concat([df,df_0],axis=0)
print(df_new)
#将df_new写入excel,这个是只针对一个sheet的表格,如果是多个sheet,是消失的。因为,这其实相当于删除原来的,新建了一个表。
df_new.to_excel(r'C:\Users\XXXXXX\Desktop\pandas写入excel.xlsx',sheet_name='sheet_1',index=True)
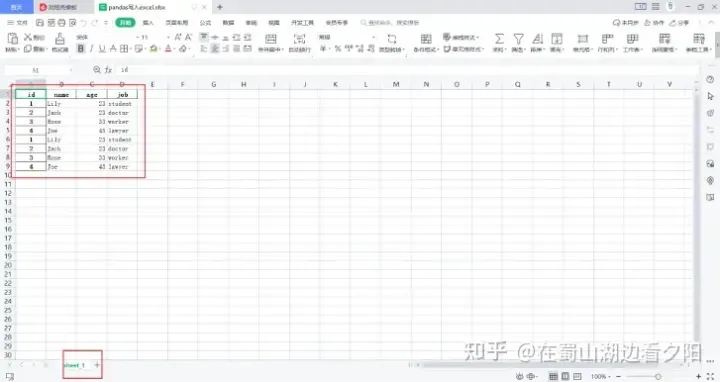
4.2 Python对excel追加数据
利用pd.ExcelWriter(),其实是重新写入。
import pandas as pd
from pandas import ExcelWriter
from openpyxl import load_workbook
#读取Excel中的数据
df_0 = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandaswriterexcel.xlsx',sheet_name='Sheet1')
#修改一下索引,将id改成索引。
df_0 = df_0.set_index(keys=['id'])
print(df_0)
old_rows = df_0.shape[0]
df = pd.DataFrame({
'name':['Lucy','Tofy','Anna','liting'],
'age':[10,12,12,9],
'job':['student','doctor','worker','lawyer']
},index=range(old_rows+1,old_rows+5),
)
#将index重新命名为id
df.index.name='id'
print(df)
writer = ExcelWriter(r'C:\Users\XXXXXX\Desktop\pandas写入excel.xlsx',mode='w')
#现将df_0存入
df_0.to_excel(writer,startrow=0,index=False,sheet_name='Sheet1')
#将df写入,注意开始行。
df.to_excel(writer,startrow=old_rows+1,header=None,index=False,sheet_name='Sheet1')
writer.save()
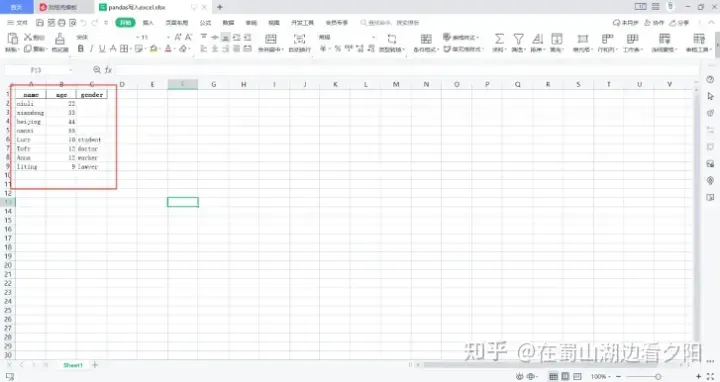
5 写入多个excel中
import pandas as pd
#读取Excel中的数据
df = pd.DataFrame({
'name':['Lucy','Tofy','Anna','liting'],
'age':[10,12,12,9],
'job':['student','doctor','worker','lawyer']
},index=range(1,5),
)
#将index重新命名为id
df.index.name='id'
#利用for循环存入多个excel
for i in range(1,3):
df.to_excel(fr'C:\Users\XXXXXX\Desktop\p_e_{i}.xlsx',index=True,engine='openpyxl')
6 两种数据类型转成DataFrame写入excel的案例
6.1 JSON解析后存入Excel
import pandas as pd
#读取JSON数据。
f_path = r'C:\Users\XXXXXX\Desktop\测试数据.json'
data = pd.read_json(f_path,encoding='utf-8')
# print(data)
#获取list,result的值。
data_list = data.loc['list','result']
# print(data_list)
df_list = []
for one_info in data_list:
df = pd.DataFrame(one_info,index=[0])
df_list.append(df)
data_excel = pd.concat(df_list)
data_excel.to_excel(r'C:\Users\XXXXXX\Desktop\json_2_excel.xlsx',index=False)
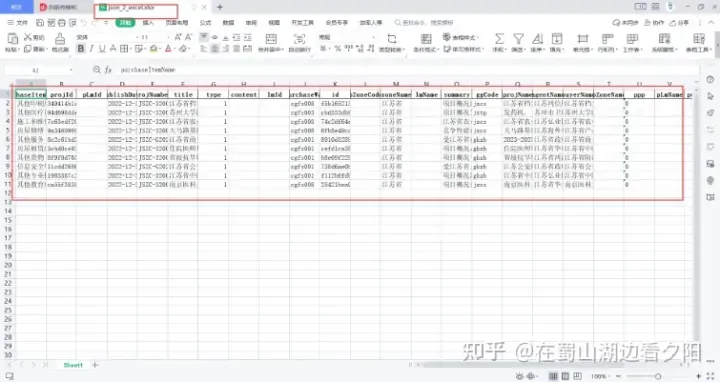
6.2 列表解析后存入Excel
import pandas as pd
#先构造一个列表数据
data_list = [['name','age','job'],['Lucy',33,'doctor'],['Tom',34,'teacher'],['Anna',22,'student']]
df = pd.DataFrame(data_list[1:],columns=data_list[0])
# print(df)
df.to_excel(r'C:\Users\XXXXXX\Desktop\list_2_excel.xlsx',index=False)
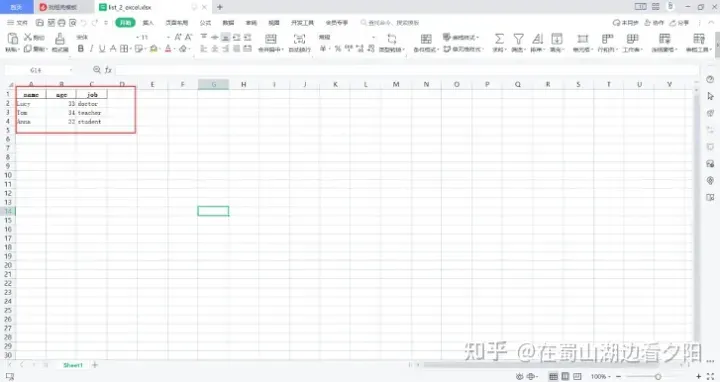
3、pandas写入csv、txt
3.1 df.to_csv()参数详解
df.to_csv(
path_or_buf=None, #文件存储路径
sep=',', #分隔符
na_rep='', #缺失值填充,默认为''
float_format=None, #浮点小数的格式。
columns=None, #list。要写入的字段。一般默认为None,即全部写入。
header=True, #列名。默认为True,即写入的列名为,df的列标签。
index=True, #行索引。默认为True,即写入的行索引为,df的行标签。
index_label=None, #索引列的标签名。
mode='w', #写入模式{"w","a","r","w+","a+","r+"},一般默认为"w",写入。
encoding=None, #编码。
compression='infer', #
quoting=None,
quotechar='"',
lineterminator=None,
chunksize=None, #一次写入的行数。
date_format=None, #日期格式。
doublequote=True,
escapechar=None,
decimal='.',
errors='strict',
storage_options=None
)
3.2 df.to_csv():写入数据
import pandas as pd
#先构造一个列表数据
data_list = [['name','age','job'],['Lucy',33,'doctor'],['Tom',34,'teacher'],['Anna',22,'student']]
df = pd.DataFrame(data_list[1:],columns=data_list[0])
# print(df)
df.to_csv(r'C:\Users\XXXXXX\Desktop\list_2_excel.csv',index=False,sep=',')
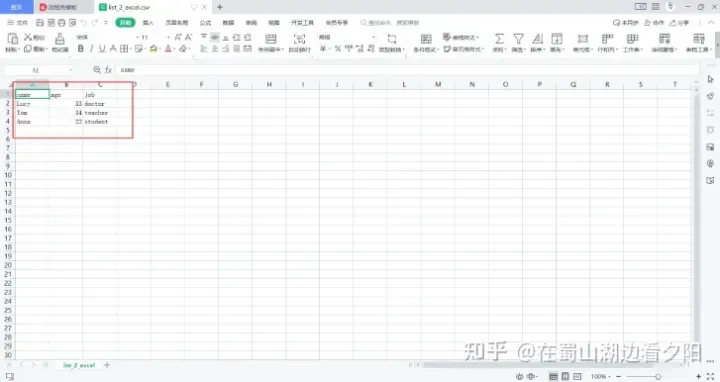
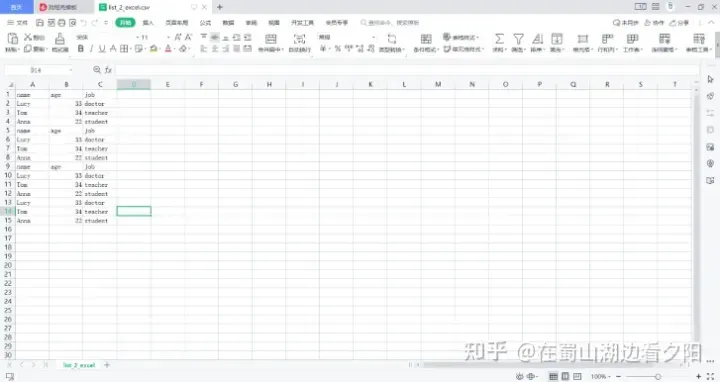
3.3 df.to_csv():追加数据
import pandas as pd
#先构造一个列表数据
data_list = [['name','age','job'],['Lucy',33,'doctor'],['Tom',34,'teacher'],['Anna',22,'student']]
df = pd.DataFrame(data_list[1:],columns=data_list[0])
# print(df)
df.to_csv(r'C:\Users\XXXXXX\Desktop\list_2_excel.csv',index=False,sep=',',mode='a',header=False)#header=False时,列名才不会追加进去。
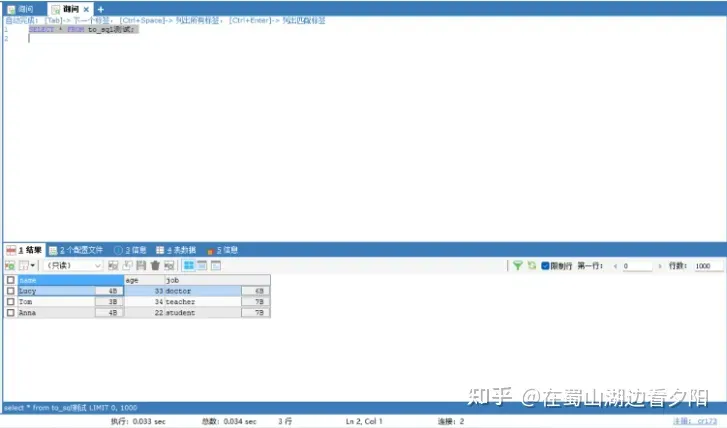
4、pandas写入SQL数据库
4.1 df.to_sql()参数详情
df.to_sql(
name='table', #表名。
con=con, #连接。
if_exists='append', #判断这个表是否存在,若存在,添加。
index=False,#索引是否写入,否。
dtype={'col1':sqlalchemy.types.INTEGER(),
'col2':sqlalchemy.types.NVARCHAR(length=255),
'col_time':sqlalchemy.DateTime(),
'col_bool':sqlalchemy.types.Boolean
}#每一列写入时的数据类型。可不填。
)
4.2 实操案例
#导入必要的模块
import pandas as pd
from sqlalchemy import create_engine
import pymysql
data_list = [['name','age','job'],['Lucy',33,'doctor'],['Tom',34,'teacher'],['Anna',22,'student']]
df = pd.DataFrame(data_list[1:],columns=data_list[0])
#连接MySQl
# engine = create_engine('mysql+pymysql://usrname:password@localhost:端口号/database')
engine = create_engine('mysql+pymysql://sh******ei:SCW*******scw@rm-uf6x********.mysql.rds.aliyuncs.com:3306/*****database')
con = engine.connect()
df.to_sql('to_sql测试',con=con,index=False,if_exists='append')
文章出处登录后可见!
已经登录?立即刷新