1 计算图原理
计算图(Computational Graph)是机器学习领域中推导神经网络和其他模型算法,以及软件编程实现的有效工具。
计算图的核心是将模型表示成一张拓扑有序(Topologically Ordered)的有向无环图(Directed Acyclic Graph),其中每个节点包含数值信息(可以是标量、向量、矩阵或张量)和算子信息
。拓扑有序指当前节点仅在全体指向它的节点被计算后才进行计算。
- 可以通过基本初等映射 的拓扑联结,形成复合的复杂模型,大多数神经网络模型都可以被计算图表示;
- 便于实现自动微分机(Automatic Differentiation Machine),对给定计算图可基于链式法则由节点局部梯度进行反向传播。
计算图的基本概念如表所示,基于计算图的基本前向传播和反向传播算法如表
| 符号 | 含义 |
|---|---|
| 计算图的节点数 | |
| 计算图的叶节点数 | |
| 计算图的叶节点索引集 | |
| 计算图的非叶节点索引集 | |
| 计算图的有向边集合 | |
| 计算图中的第 | |
| 节点 | |
| 输出节点关于输入节点的雅克比矩阵 |
2 基于计算图的传播
基于计算图的前向传播算法如下


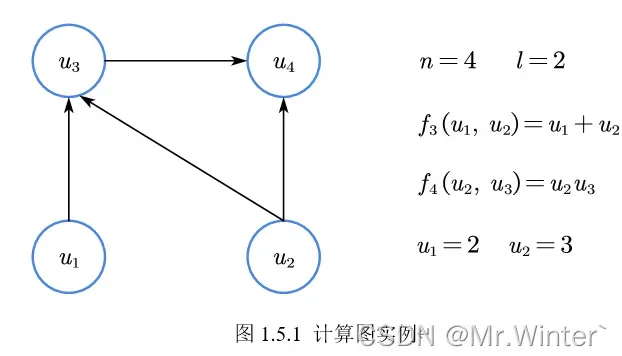
以第一节的图为例,可知。首先进行前向传播:
接着进行反向传播:
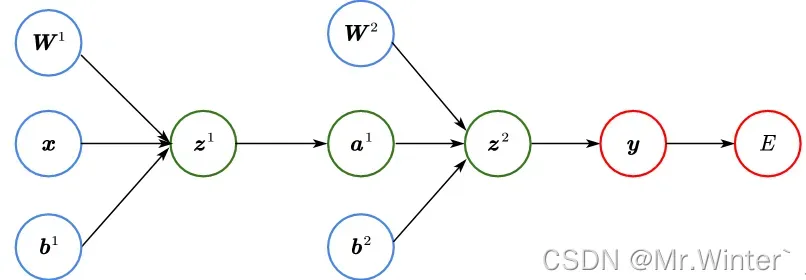
3 神经网络计算图
一个神经网络的计算图实例如下,所有参数都可以用之前的模型表示
4 自动微分机
自动微分机的基本原理是:
- 跟踪记录从输入张量到输出张量的计算过程,并生成一幅前向传播计算图,计算图中的节点与张量一一对应;
- 基于计算图反向传播原理即可链式地求解输出节点关于各节点的梯度。
必须指出,Pytorch不允许张量对张量求导,故输出节点必须是标量,通常为损失函数或输出向量的加权和;为节约内存,每次反向传播后Pytorch会自动释放前向传播计算图,即销毁中间计算节点的梯度和节点间的连接结构。
5 Pytorch中的自动微分
Tensor在自动微分机中的重要属性如表所示。
| 属性 | 含义 |
|---|---|
device | 该节点运行的设备环境,即CPU/GPU |
requires_grad | 自动微分机是否需要对该节点求导,缺省为False |
grad | 输出节点对该节点的梯度,缺省为None |
grad_fn | 中间计算节点关于全体输入节点的映射,记录了前向传播经过的操作。叶节点为None |
is_leaf | 该节点是否为叶节点 |
完成前向传播后,调用反向传播API即可更新各节点梯度,具体如下
backward(gradient=None, retain_graph=None, create_graph=None)
其中
gradient是权重向量,当输出节点不为标量时需指定与其同维的
gradient,并以标量为输出进行反向传播
retain_graph用于缓存前向传播计算图,可应用于一次传播测试多个损失函数等情形;creat_graph用于构造导数计算图,可用于进一步求解高阶导数。
5.1 梯度缓存
中间计算节点的梯度需要通过retain_grad()方法进行缓存
w1 = torch.tensor([[2.], [3.]], requires_grad=True)
b1 = torch.tensor([1.], requires_grad=True)
x = torch.tensor([[10.], [20.]])
y = torch.mm(w1.transpose(0, 1), x) + b1
y.retain_grad() # 若不缓存则y.grad=None
out = 3*y
out.backward()
>> tensor([[30.], [60.]]) tensor([3.]) None tensor([[3.]])
5.2 参数冻结
若希望冻结网络部分参数,只调整优化另一部分参数;或按顺序训练分支网络而屏蔽对主网络梯度的,可使用detach()方法从计算图中分离节点,阻断反向传播。分离的节点与原节点共享值内存,但不具有grad和grad_fn属性。
# 记第一层网络w1-b1为f,第二层网络w2-b2为g
w1 = torch.tensor([[2.], [3.]], requires_grad=True)
w2 = torch.tensor([3.], requires_grad=True)
b1 = torch.tensor([1.], requires_grad=True)
b2 = torch.tensor([2.], requires_grad=True)
x = torch.tensor([[10.], [20.]])
y = torch.mm(w1.transpose(0, 1), x) + b1
y_ = y.detach()
z = w2 * y_ + b2
out = 3*z
out.backward()
print(w1.grad, b1.grad, w2.grad, b2.grad)
>> None None tensor([243.]) tensor([3.]) # f被冻结,梯度不更新
# 若不使用detach冻结y之前的网络,则
>> tensor([[ 90.], [180.]]) tensor([9.]) tensor([243.]) tensor([3.])
🔥 更多精彩专栏:
文章出处登录后可见!
已经登录?立即刷新