博主简介
博主是一名大二学生,主攻人工智能研究。感谢让我们在CSDN相遇,博主致力于在这里分享关于人工智能,c++,Python,爬虫等方面知识的分享。 如果有需要的小伙伴可以关注博主,博主会继续更新的,如果有错误之处,大家可以指正。
专栏简介: 本专栏主要研究python在人工智能方面的应用,涉及算法,案例实践。包括一些常用的数据处理算法,也会介绍很多的Python第三方库。如果需要,点击这里 订阅专栏。
给大家分享一个我很喜欢的一句话:“每天多努力一点,不为别的,只为日后,能够多一些选择,选择舒心的日子,选择自己喜欢的人!”

目录
背景引入
特征值提取,在模式识别领域是很常见的一种算法和手段。特征值看起来好像很陌生,其实在我们日常生活中也很常见。我们使用的身份认证,ID,都可以视为不同系统下的特征值。
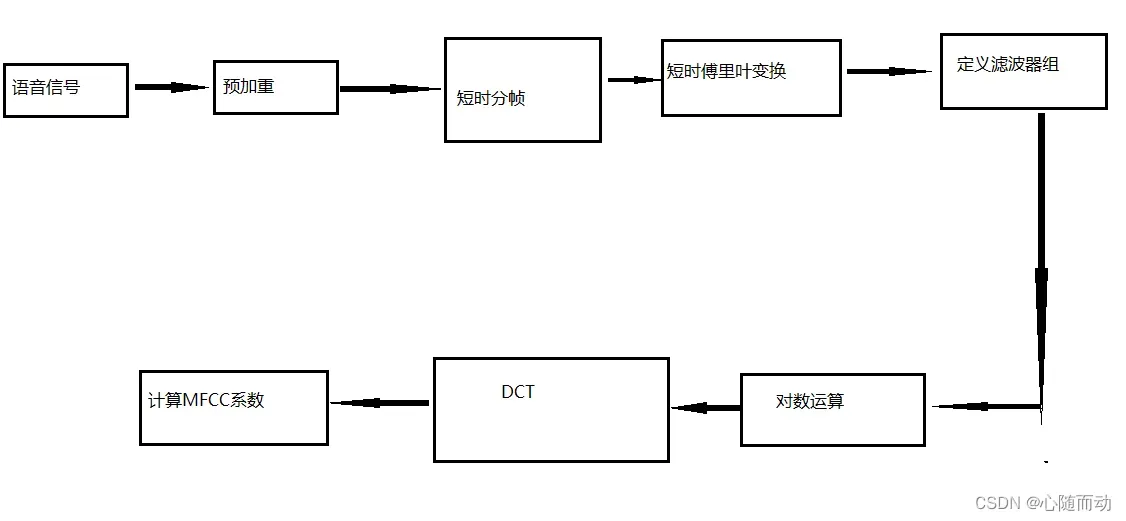
MFCC在语音识别领域就是一组特征向量,它通过对语音信号(频谱包络与细节)进行编码运算来得到。MFCC有39个系数,其中包括13个静态系数,13个一阶差分系数,以及13个二阶差分系数。差分系数用来描述动态特征,也就是声学特征在相邻帧间的变化情况。这些系数都是通过离散余弦变换(Discrete Cosine Transform,DCT)计算而来。
MFCC语音特征值提取算法简介
MFCC意为梅尔频率倒谱系数,顾名思义,MFCC语音特征提取包含两个关键步骤;将语音信号转化为梅尔频率,然后进行倒谱分析。梅尔频谱是一个可用来代表短期音频的频谱,梅尔刻度(Mel Scale)则是一种基于人耳对等距的音高变化的感官判断而确定的非线性频率刻度。梅尔频率和正常的频率f之间的关系:

当梅尔刻度均匀分布,则对应的频率之间的距离会越来越大。梅尔刻度的滤波器组在低频部分的分辨率高,跟人耳的听觉特性比较相符,这也是梅尔刻度的物理意义。在梅尔频域内,人对音调的感知度为线性关系,如果两段语音的梅尔频率相差两倍,则人耳听起来两者的音调也相差两倍。
转化为梅尔频率时,首先对时域信号进行离散傅里叶变换,将信号转换到频域,然后再利用梅尔刻度的滤波器组对频域信号进行切分,使每个频率段对应一个数值。倒谱(Cepstrum)通过对一个时域信号进行傅里叶变换后取对数,并再次进行反傅里叶变换(Inverse Fast Fourier Transform,IFFT)得到。倒谱可分为复倒谱(Complex Cepstrum),实倒谱(Real Cepstrum)和功率倒谱(Power Cepstrum)。倒谱分析可用于信号分解,也就是将两个信号的卷积转化为两个信号的相加。
MFCC的物理含义,简而言之,可理解为语音信号的能量在不同频率范围的分布。
人的发声过程可以看作是肺里的气流通过声带这个线性系统。如果用e(t)表示输入声音的音高,h(t)表示声带的响应(也即我们需要获取的语音特征),那么听到的语音信号x(t)即为二者的卷积:

x(t)为时域信号,对其进行离散傅里叶变换后可得到频域信号X(K),亦即频谱:

时域信号的卷积在频域内则可表示为二者的乘积:

通常,在频域分析中我们只关注频谱的能量而忽略其相位信息,即:

对频谱进行对数运算:

然后进行反傅里叶计算:

c(n)即为倒谱系数,已经和原始的时域信号x(t)不一样。并且时域信号的卷积关系已经转化为频域信号的线性相加关系。

语音信号分帧
语音信号属于准稳态信号,这也意味着,在一定的时间内,信号会保持稳定。这个时常对于我们人类来说,很短,一般只有10ms~30ms。在这一区间(即帧)内,可将语音信号看成稳态信号,只有稳态信号才能进行信号处理。
信号分帧一般会涉及到一个加窗的操作,即将原始信号与一个窗函数相乘。我们用计算机处理信号的时候,一般不会取无限长的信号,而是会取其中间的一段信号,这将会减少工作量,也会加快程序法分析的时间。
无限长的信号被截断后,其频谱会发生畸变,从而导致频谱能量泄露。 为了减少这种能量泄露,我们可采用不同的截取函数对信号进行截断。执行截断操作的函数称为窗函数,简称为窗。常用的窗函数有矩形窗,三角窗,汉明(Hamming)窗及汉宁窗等。
汉宁窗也叫升余弦窗,是很有用的窗函数。如果测试测试信号有多个频率分量,频谱表现非常复杂,测试目的更多在于关注频率点而非能量大小,则用汉宁窗。汉宁窗主瓣加宽并降低,旁瓣则显著减小,从减少泄漏的观点出发,汉宁窗明显优于矩形窗。但汉宁窗主瓣加宽,相当于分析带宽加宽,频率分辨率下降,他与矩形窗相比,泄露以及波动较小,选择性则相应较高。
汉明窗是用来加权余弦形成的锥形窗,也称之为改进的升余弦窗,只是加权系数不同,其旁瓣更小,但其旁瓣衰减速度比汉宁窗要慢。汉明窗是以著名的美国数学家理查德·卫斯理·汉明(Richard Wesley Hamming)的名字来命名:

下面的代码就是用python来生成汉明窗和汉宁窗:
import matplotlib.pyplot as plt import scipy #信号处理工具包 plt.figure(figsize=(6,2)) plt.plot(scipy.hanning(512),"b--",label="Hanning") #绘制汉宁窗 plt.plot(scipy.hamming(512),"r--",label="Hamming") #绘制汉明窗 plt.title("Demo Hanning & Hamming Window") plt.legend() plt.show()
除了scipy模块可以实现汉宁窗和汉明窗,我们也可以用NumPy来实现汉宁窗和汉明窗。示例代码如下:
import numpy as np import matplotlib.pyplot as plt hanWing=np.hanning(512)#定义汉宁窗 hamWin=np.hamming(512) #定义汉明窗 plt.plot(hanWing,'y--',label="Hanning") plt.plot(hamWin,'b--',label="Hamming") plt.title("Hamming & Hanning window") plt.ylabel("Amplitude") plt.xlabel("Sample") plt.legend() plt.show()
信号加窗,从本质上而言,就是将原始信号与一个窗函数相乘。进行加窗操作之后,我们就可以对信号进行傅里叶展开。加窗的代价就是,一帧信号的两端部分将会被消弱。所以在进行信号分帧处理时,帧与帧之间需要有部分重叠。相邻两帧重叠后,其起始位置的时间差称之为帧移,即步长(Stride) 。
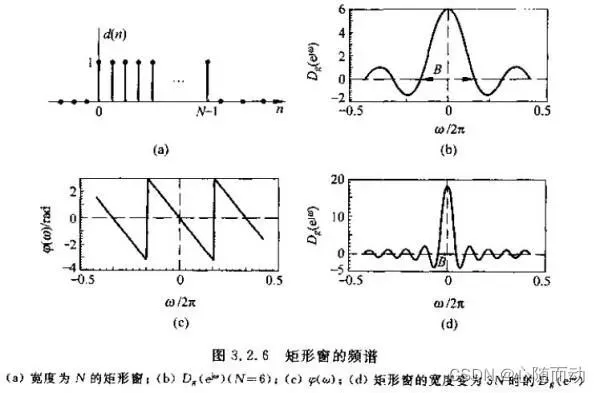
以下为简单的信号加窗操作示意图:
import numpy as np import matplotlib.pyplot as plt import scipy x=np.linspace(0,10,1000) originWav=np.sin(x**2) #示例原信号 win=scipy.hamming(1000) #定义一个窗函数,这里使用的汉明窗 winFrame=originWav*win #结果可视化 plt.title("Signal Chunk with Hamming Windows") plt.plot(originWav) plt.plot(win) plt.plot(winFrame) plt.legend() plt.show()
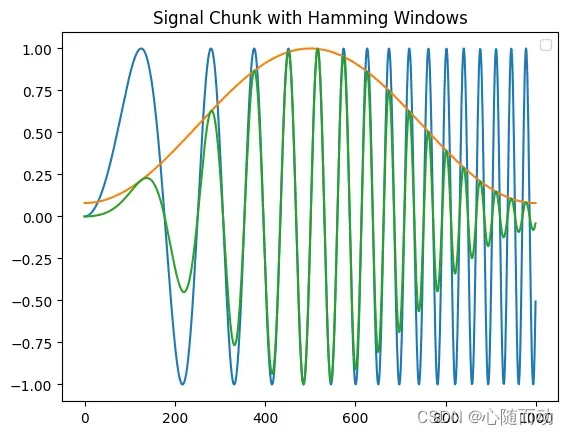
运行程序,其中蓝色波形为原信号,橙色波形为窗函数,绿色为加窗操作之后的信号。
假设x为语音信号,w为窗函数,则分帧信号为:

其中,w(n-m)为窗口序列,当n去不同的值时,窗口w(n-m)沿x(m)。因此,w(n-m)是一个“滑动的”窗口。y(n)为短时傅里叶变换(SIFT)。由于窗口是有限长度的,满足绝对可和条件,所以这个变幻的前提条件是存在的,这也是信号分帧的理论依据。
以下示例代码从指定文件夹读取一个音频文件,然后将该音频文件分帧并显示其中一个分帧信号的波形:
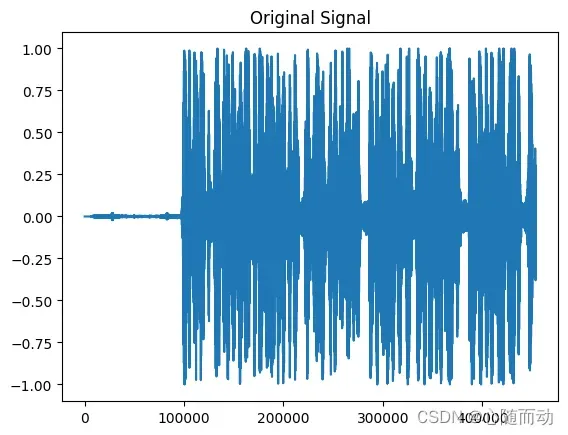
#读取指定音频文件 import matplotlib.pyplot as plt import numpy as np import wave #导入波形处理工具包 import os import soundfile def audioSignalFrame(signal,nw,inc): ''' signal:原始音频信号 nw:每一帧的长度 inc:相邻帧的间隔 ''' #信号总长度 signal_length=len(signal) #若信号长度小于一个帧的长度,则帧数定义为1 if signal_length<=nw: nf=1 else: nf=int(np.ceil((1.0*signal_length-nw+inc)/inc)) #所有帧加起来的总的铺平的长度 pad_length=int((nf-1)*inc+nw) #长度不够时,使用0填补,类似于FFT中的扩充数组长度 zeros=np.zeros((pad_length-signal_length,)) #填补后的信号 pad_signal=np.concatenate((signal,zeros)) #相当于对所有帧的时间点进行抽取,得到nf*nw的长度的矩阵 indices=np.tile(np.arange(0,nw),(nf,1))+np.tile(np.arange(0,nf*inc,inc),(nw,1)).T #将indices转化为矩阵 indices=np.array(indices,dtype=np.int32) #得到帧信号 frames=pad_signal[indices] #窗函数,这里默认取1 return frames def readSignalWave(filename): f=wave.open(filename,'rb') params=f.getparams() nchannels,sampwidth,frammerate,nframes=params[:4] #读取音频,字符串格式 strData=f.readframes(nframes) #将字符串转化为int waveData=np.fromstring(strData,dtype=np.int16) f.close() #信号幅值归一化 waveData=waveData*1.0/(max(abs(waveData))) waveData=np.reshape(waveData,[nframes,nchannels]).T return waveData if __name__=='__main__': filepath="./test.wav" #dirname=os.listdir(filepath) #filename=filepath+dirname[3] data=readSignalWave(filepath) #初始化每帧长度及帧间隔 nw=512 inc=128 Frame=audioSignalFrame(data[0],nw,inc) #显示原始信号 plt.plot(data[0]) plt.title("Original Signal") plt.show() #显示第一帧信号 plt.plot(Frame[0]) plt.title("First Frame") plt.show()
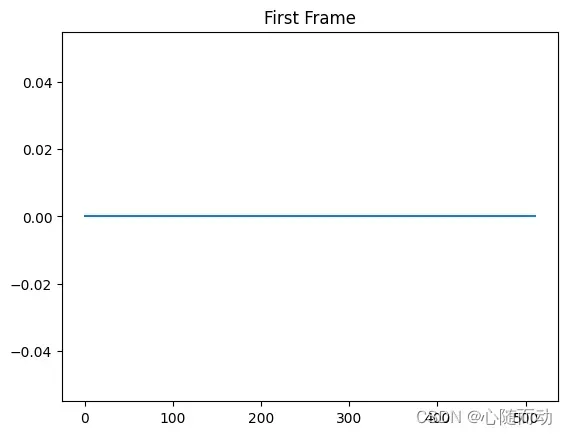
上面的代码中,没有对信号进行加窗处理,若要执行信号加床操作,只需将分帧函数稍作修改,
def audioSignalFrame(signal,nw,inc,winfunc): ''' signal:原始音频信号 nw:每一帧的长度 inc:相邻帧的间隔 ''' #信号总长度 signal_length=len(signal) #若信号长度小于一个帧的长度,则帧数定义为1 if signal_length<=nw: nf=1 else: nf=int(np.ceil((1.0*signal_length-nw+inc)/inc)) #所有帧加起来的总的铺平的长度 pad_length=int((nf-1)*inc+nw) #长度不够时,使用0填补,类似于FFT中的扩充数组长度 zeros=np.zeros((pad_length-signal_length,)) #填补后的信号 pad_signal=np.concatenate((signal,zeros)) #相当于对所有帧的时间点进行抽取,得到nf*nw的长度的矩阵 indices=np.tile(np.arange(0,nw),(nf,1))+np.tile(np.arange(0,nf*inc,inc),(nw,1)).T #将indices转化为矩阵 indices=np.array(indices,dtype=np.int32) #得到帧信号 frames=pad_signal[indices] #窗函数,这里默认取1 win=np.tile(winfunc,(nf,1)) return frames*win
当然,随着函数的改变,主函数中对函数的调用也需要改变,只需要改变参数即可。除了调用工具包中的汉明窗函数,也可以使用公式来定义。
def hamming(n):
return 0.54-0.46*cos(2*pi/n*(arange(n)+0.5))
语音信号在进行分帧之前,一般需要进行一个与加重操作。语音信号的预加重,是为了对语音的高频部分进行加重,使信号变得平坦,保持在地频到高频的整个频带中能用同样的信噪比求频谱。同时也为了消除发声过程中声带和口唇辐射效应,补偿语音信号受到发音系统所抑制的高频部分,增加语音的高频分辨率。
我们一般通过一阶有限长单位冲激响应(Finite Impulse Response,FIR)高通数字滤波器来实现预加重。FIR滤波器 作为传递函数,其中a为预加重系数,0.9<a<1.0。假设t时刻的语音采样值为x(t),经过预加重处理后的结果为
作为传递函数,其中a为预加重系数,0.9<a<1.0。假设t时刻的语音采样值为x(t),经过预加重处理后的结果为 .a一般默认取0.95.
.a一般默认取0.95.
信号的预加重处理示例代码:
def preemphasis(signal,coeff=0.95): ''' signal:要滤波的输入信号 coeff:预加重系数。0表示无过滤,默认为0.95 返回值:滤波信号 ''' return numpy.append(signal[0],signal[1:]-coeff*signal[:-1])
计算MFCC系数
由于信号在时域上的变换很难看出特征,因此,我们通常将它转换为频域上的能量分布以便于观察。不同的能量分布,代表不同语音的特征。语音原信号在与窗函数(如汉明窗)相乘后,每帧还必须再经过快速傅里叶变换以得到频谱上的能量分布。对语音信号分帧加窗后的各帧的频谱,然后对频谱进行取模平方运算后即为语音信号的功率谱。
对信号幅度谱、功率谱以及对数功谱的计算实例代码如下:
import numpy
import logging
def msgspec(frames,NFFT):
"""
计算帧中每个帧的幅度谱。如果帧为N*D,则输出N*(NFFT/2+1)
"""
if numpy.shape(frames)[1]>NFFT:
logging.warn('frame length (%d)is greater than FFT size(%d),frame will be truncated .Increase NFFT to avoid.',numpy.shape(frames)[1],NFFT)
complex_spec=numpy.fft.rfft(frames,NFFT)
return numpy.absolute(complex_spec)
def power_spectrum(frames,NFFT):
return 1.0/NFFT*numpy.square(spectrum_magnitude(frames,NFFT))
def log_power_spectrum(frames,NFFT,norm=1):
spec_power=power_spectrum(frames,NFFT)
spec_power[spec_power<1e-30]
log_spec_power=10*numpy.log10(spec_power)
if norm:
return log_spec_power-numpy.max(log_spec_power)
else:
return log_spec_power此外,信号的每一帧的音量(即能量),也是语音的特征,而且非常容易计算。因此,通常会再加上一帧的能量,使得每一帧基本的语音特征增加一个维度,包括一个对数能量和倒谱参数。标准的倒谱参数MFCC,只反映了语音参数的静态特征,语音参数的动态特征可以用这些静态特征的差分普来描述。
MFCC的全部组成如下:N维MFCC系数(N/3 MFCC系数+N/3 一阶差分系数+N/3二阶差分系数)+帧能量。以语音识别中常用的39维MFCC为例,即为:13个静态系数+13个一阶差分系数(Delta系数)+13个二阶差分系数(Delta-Delta系数)。其中,差分系数用来描述动态特征,即声学特征在相邻帧间的变化情况。
在MFCC计算中还涉及频率与梅尔刻度之间的转换,其转换方式如下:
def hz2mel(hz):
return 2595*numpy.log10(1+hz/700.0)

同样,我们也可以推出下列公式:

Delta系数的计算公式为:

其中, 为Delta系数,从帧t根据静态系数
为Delta系数,从帧t根据静态系数 计算而得。N一般取值为2。Delta-Delta(加速度)系数的计算方法相同,但他们是根据Delta而不是静态系数来进行计算得到的。计算Deltaa系数的示例代码如下:
计算而得。N一般取值为2。Delta-Delta(加速度)系数的计算方法相同,但他们是根据Delta而不是静态系数来进行计算得到的。计算Deltaa系数的示例代码如下:
def delta(feat,N): if N<1: raise ValueError('N must be an integer>=1') NUMFRAMES=len(feat) denominator=2*sum([i**2 for i in range(1,N+1)]) delta_feat=numpy.pad(feat,((N,N),(0,0)),mode='edge') for t in range(NUMFRAMES): delta_feat[t]=numpy.dot(numpy.arange(-N,N+1),padded[t:t+2*N+1])/denominator return delta_feat
当然除了自己定义函数,也可以直接使用工具包中的API。
对语音信号进行预加重
import numpy as np import matplotlib.pyplot as plt from python_speech_features.sigproc import * from python_speech_features import * from scipy.fftpack import dct import scipy.io.wavfile as wav sample_rate,signal=wav.read('./test.wav') #保留语音的前3.5秒 signal=signal[0:int(3.5*sample_rate)] #信号预加重 emphasized_signal=preemphasis(signal,coeff=0.95) #显示信号 plt.plot(signal) plt.title("Original Signal") plt.plot(emphasized_signal) plt.title("Preemphasis Signal") plt.show()
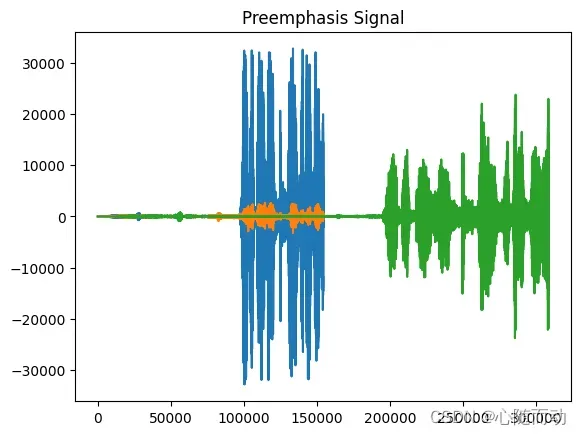
上述示例代码,对信号进行预加重处理的是preemphasis(signal,coeff)函数,除了这个函数,也可以使用以下代码实现:
pre_emphasis=0.95
emphasized_signal=numpy.append(signal[0],signal[1:]-pre_emphasis*signal[:-1])源代码:
import numpy as np import matplotlib.pyplot as plt from python_speech_features.sigproc import * from python_speech_features import * from scipy.fftpack import dct import scipy.io.wavfile as wav sample_rate,signal=wav.read('./test.wav') pre_emphasis=0.95 emphasized_signal=numpy.append(signal[0],signal[1:]-pre_emphasis*signal[:-1]) #保留语音的前3.5秒 #signal=signal[0:int(3.5*sample_rate)] #信号预加重 #emphasized_signal=preemphasis(signal,coeff=0.95) #显示信号 plt.plot(signal) plt.title("Original Signal") plt.plot(emphasized_signal) plt.title("Preemphasis Signal") plt.show()
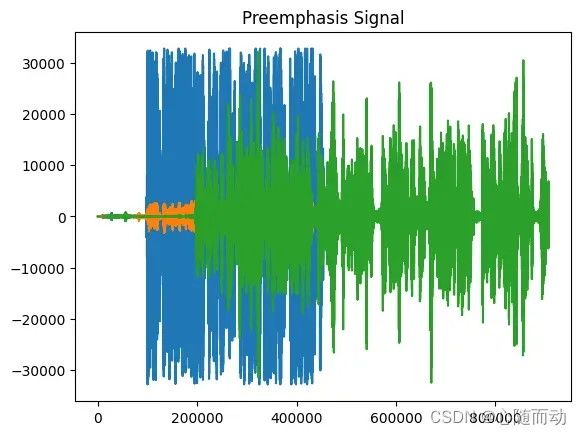
通过上面的程序可知,两种函数都可以进行预加重处理,可以自行选择合适的方法。
对语音信号进行短时傅里叶变换
在对语音信号进行处理之前,我们需要对不稳定的语音信号进行短时分帧以获取傅里叶变换必需的稳定信号。语音处理范围内的典型帧大小范围为20ms~40ms,连续帧之间重叠50%左右。因此一般将帧长度设置为25ms。短时傅里叶变换(Short-Time Fourier Transform,SIFT)在MFCC计算过程中主要用于短时分帧处理后,通过对信号进行时域到频域的转换来获取语音信号的频谱。
#对信号进行短时分帧处理 frame_size=0.025 #设置帧长 #计算帧对应采样数(frame_length)以及步长对应采样数(frame_step) frame_length,frame_step=frame_size*sample_rate,frame_stride*sample_rate signal_length=len(emphasized_signal) #信号总采样数 frame_length=int(round(frame_length)) #帧采样数 frame_step=int(round(frame_step)) #num_frames为总帧数,确保我们至少有一个帧 num_frames=int(np.ceil(float(np.abs(signal_length-frame_length))/frame_step)) pad_signal_length=num_frames*frame_step+frame_length z=np.zeros((pad_signal_length-signal_length)) #填充信号以后确保所有的帧的采样数相等 pad_signal=np.append(emphasized_signal,z) indices=np.tile(np.arange(0,frame_length),(num_frames,1))+np.tile(np.arange(0,num_frames*frame_step,frame_step),(frame_length,1)).T frames=pad_signal[indices.astype(np.int32,copy=False)]
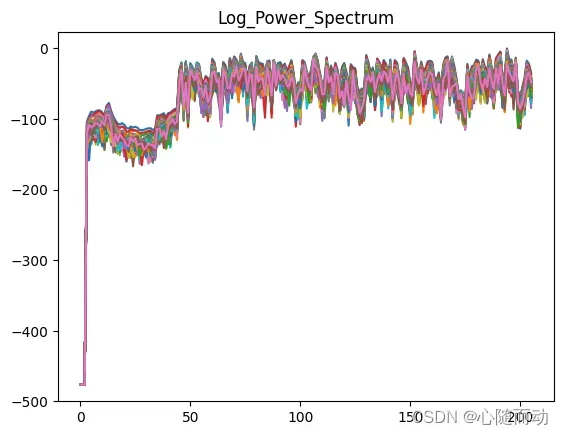
信号经过短时分帧之后,可通过短时傅里叶变换得到各种频谱
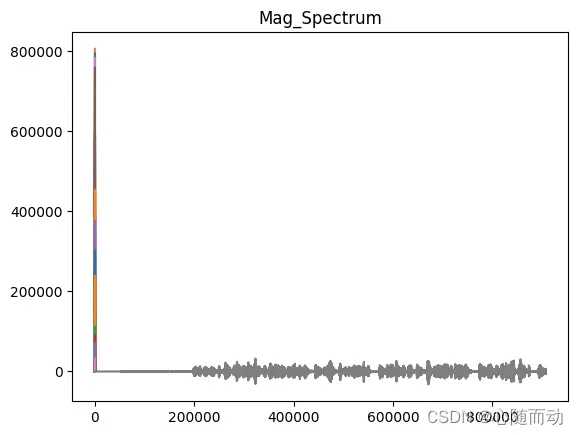
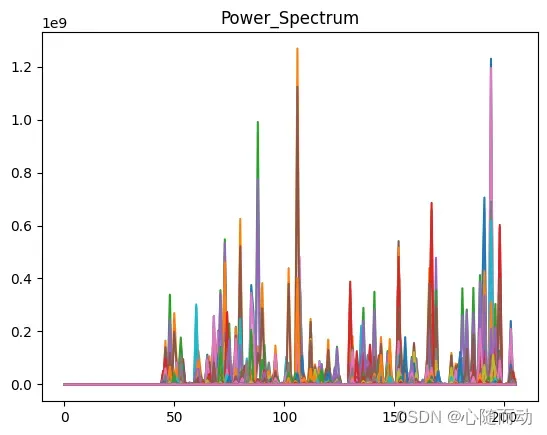
NFFT=512 mag_frames=np.absolute(np.fft.rfft(frames,NFFT)) pow_frames=((1.0/NFFT)*((mag_frames)**2)) log_pow_frames=logpowspec(pow_frames,NFFT,norm=1) #保留语音的前3.5秒 #signal=signal[0:int(3.5*sample_rate)] #信号预加重 #emphasized_signal=preemphasis(signal,coeff=0.95) #显示信号 plt.plot(mag_frames) plt.title("Mag_Spectrum") plt.plot(emphasized_signal) plt.show() plt.plot(pow_frames) plt.title("Power_Spectrum") plt.show() plt.plot(pow_frames) plt.title("Log_Power_Spectrum") plt.show()
运行上面的程序,就可以得到处理结果,下面展示原有的所有代码:
import numpy as np import matplotlib.pyplot as plt from python_speech_features.sigproc import * from python_speech_features import * from scipy.fftpack import dct import scipy.io.wavfile as wav sample_rate,signal=wav.read('./test.wav') pre_emphasis=0.95 emphasized_signal=numpy.append(signal[0],signal[1:]-pre_emphasis*signal[:-1]) #对信号进行短时分帧处理 frame_size=0.025 #设置帧长 frame_stride=0.1 #计算帧对应采样数(frame_length)以及步长对应采样数(frame_step) frame_length,frame_step=frame_size*sample_rate,frame_stride*sample_rate signal_length=len(emphasized_signal) #信号总采样数 frame_length=int(round(frame_length)) #帧采样数 frame_step=int(round(frame_step)) #num_frames为总帧数,确保我们至少有一个帧 num_frames=int(np.ceil(float(np.abs(signal_length-frame_length))/frame_step)) pad_signal_length=num_frames*frame_step+frame_length z=np.zeros((pad_signal_length-signal_length)) #填充信号以后确保所有的帧的采样数相等 pad_signal=np.append(emphasized_signal,z) indices=np.tile(np.arange(0,frame_length),(num_frames,1))+np.tile(np.arange(0,num_frames*frame_step,frame_step),(frame_length,1)).T frames=pad_signal[indices.astype(np.int32,copy=False)] NFFT=512 mag_frames=np.absolute(np.fft.rfft(frames,NFFT)) pow_frames=((1.0/NFFT)*((mag_frames)**2)) log_pow_frames=logpowspec(pow_frames,NFFT,norm=1) #保留语音的前3.5秒 #signal=signal[0:int(3.5*sample_rate)] #信号预加重 #emphasized_signal=preemphasis(signal,coeff=0.95) #显示信号 plt.plot(mag_frames) plt.title("Mag_Spectrum") plt.plot(emphasized_signal) plt.show() plt.plot(pow_frames) plt.title("Power_Spectrum") plt.show() plt.plot(log_pow_frames) plt.title("Log_Power_Spectrum") plt.show()
(a)幅度谱
(b)功率谱
(c)功率对数谱
音频文件使用不同,最终结果也会不同,大家自己使用自己的音频,注意音频格式为“.wav”
定义滤波器组
将信号通过一组梅尔刻度的三角形滤波器组,采用的滤波器为三角形滤波器,中心频率为f(m),m=1,2,3,“““`,M,M通常取22~26. 各f(m)之间的间隔随着m值的减少而减少。随着m值的增大而增大。如图:
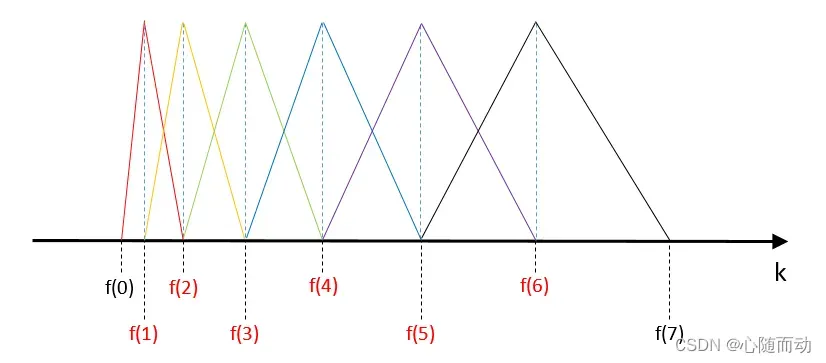
三角形滤波器的频率响应定义公式:4
对于其他的情况,例如,k<f(m-1)和k>=f(m+1)则为0,当k=f(m)时为1.

定义梅尔刻度的三角形滤波器组的示例代码为:
low_freq_MEL=0 #将频率转换为梅尔刻度 nfilt=40 #窗的数目 #计算m=2595*log10(1+f/700) high_freq_mel=(2595*np.log10(1+(sample_rate/2)/700)) mel_points=np.linspace(low_freq_MEL,high_freq_mel,nfilt+2) #梅尔刻度的均匀分布 #计算f=700(10**(m/2595)-1) hz_points=(700*(10**(mel_points/2595)-1)) bin=np.floor((NFFT+1)*hz_points/sample_rate) fbank=np.zeros((nfilt,int(np.floor(NFFT/2+1)))) #计算三角形滤波器频率响应 for m in range(1,nfilt+1): f_m_minus=int(bin[m-1]) #三角形滤波器左边频率f(m-1) f_m=int(bin[m]) #三角形滤波器中间频率fm f_m_plus=int(bin[m+1]) #三角形滤波器右边频率f(m-1) for k in range(f_m_minus,f_m): fbank[m-1,k]=(k-bin[m-1])/(bin[m+1]-bin[m]) plt.plot(fbank.T) plt.show()
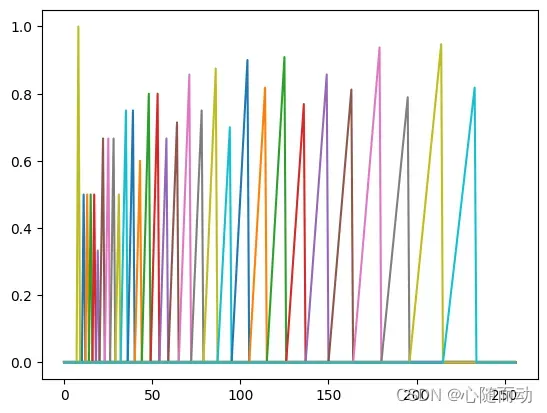
三角形滤波器有两个主要功能,其一,对频谱进行平滑并消除谐波的作用,突显原先语音的共振峰;其二,用以降低运算量。如图所示的滤波器组中的每个滤波器在中心频率处响应为1,并朝着0线性减少,直至达到响应为0的两个相邻滤波器的中心频率。
计算MFCC系数
如果计算出的滤波器组系数高度相关,则在某些机器学习算法中可能会存在问题。我们可用离散余弦变换对滤波器组系数进行去相关,并产生滤波器组的压缩表示。滤波器组输出的对数能量经离散余弦变换后,即可得到MFCC系数。示例代码如下:
import numpy as np import matplotlib.pyplot as plt from python_speech_features.sigproc import * from python_speech_features import * from scipy.fftpack import dct import scipy.io.wavfile as wav sample_rate,signal=wav.read('./test.wav') pre_emphasis=0.95 emphasized_signal=numpy.append(signal[0],signal[1:]-pre_emphasis*signal[:-1]) #对信号进行短时分帧处理 frame_size=0.025 #设置帧长 frame_stride=0.1 #计算帧对应采样数(frame_length)以及步长对应采样数(frame_step) frame_length,frame_step=frame_size*sample_rate,frame_stride*sample_rate signal_length=len(emphasized_signal) #信号总采样数 frame_length=int(round(frame_length)) #帧采样数 frame_step=int(round(frame_step)) #num_frames为总帧数,确保我们至少有一个帧 num_frames=int(np.ceil(float(np.abs(signal_length-frame_length))/frame_step)) pad_signal_length=num_frames*frame_step+frame_length z=np.zeros((pad_signal_length-signal_length)) #填充信号以后确保所有的帧的采样数相等 pad_signal=np.append(emphasized_signal,z) indices=np.tile(np.arange(0,frame_length),(num_frames,1))+np.tile(np.arange(0,num_frames*frame_step,frame_step),(frame_length,1)).T frames=pad_signal[indices.astype(np.int32,copy=False)] NFFT=512 mag_frames=np.absolute(np.fft.rfft(frames,NFFT)) pow_frames=((1.0/NFFT)*((mag_frames)**2)) log_pow_frames=logpowspec(pow_frames,NFFT,norm=1) #保留语音的前3.5秒 #signal=signal[0:int(3.5*sample_rate)] #信号预加重 #emphasized_signal=preemphasis(signal,coeff=0.95) #显示信号 ''' plt.plot(mag_frames) plt.title("Mag_Spectrum") plt.plot(emphasized_signal) plt.show() plt.plot(pow_frames) plt.title("Power_Spectrum") plt.show() plt.plot(log_pow_frames) plt.title("Log_Power_Spectrum") plt.show() ''' low_freq_MEL=0 #将频率转换为梅尔刻度 nfilt=40 #窗的数目 #计算m=2595*log10(1+f/700) high_freq_mel=(2595*np.log10(1+(sample_rate/2)/700)) mel_points=np.linspace(low_freq_MEL,high_freq_mel,nfilt+2) #梅尔刻度的均匀分布 #计算f=700(10**(m/2595)-1) hz_points=(700*(10**(mel_points/2595)-1)) bin=np.floor((NFFT+1)*hz_points/sample_rate) fbank=np.zeros((nfilt,int(np.floor(NFFT/2+1)))) #计算三角形滤波器频率响应 for m in range(1,nfilt+1): f_m_minus=int(bin[m-1]) #三角形滤波器左边频率f(m-1) f_m=int(bin[m]) #三角形滤波器中间频率fm f_m_plus=int(bin[m+1]) #三角形滤波器右边频率f(m-1) for k in range(f_m_minus,f_m): fbank[m-1,k]=(k-bin[m-1])/(bin[m+1]-bin[m]) plt.plot(fbank.T) plt.show() filter_banks=np.dot(pow_frames,fbank.T) filter_banks=np.where(filter_banks==0,np.finfo(float).eps,filter_banks) filter_banks=20*np.log10(filter_banks) num_ceps=12 #取12个系数 #通过DCT计算MFCC系数 mfcc=dct(filter_banks,type=2,axis=1,norm='ortho')[:,1:(num_ceps+1)] #对MFCC进行倒谱提升可以改善噪声信号中的语音识别 (nframes,ncoeff)=mfcc.shape n=np.arange(ncoeff) cep_lifter=22 #倒谱滤波系数,定义倒谱所用到的滤波器组内滤波器个数 lift=1+(cep_lifter/2)*np.sin(np.pi*n/cep_lifter) mfcc*=lift mfcc-=(np.mean(mfcc,axis=0)+1e-8) plt.imshow(np.flipud(mfcc.T),cmap=plt.cm.jet,aspect=0.2,extent=[0,mfcc.shape[0],0,mfcc.shape[1]]) #绘制MFCC热力图 plt.show()

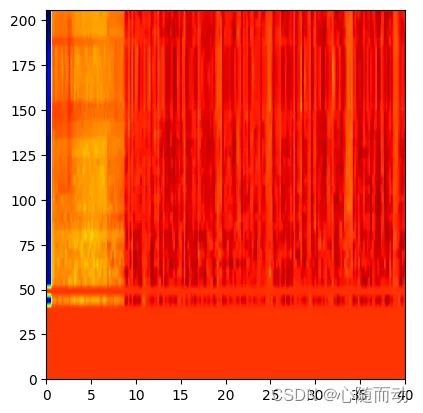
对MFCC进行如下的归一化操作,运行操作,其相应的热力图如下:
filter_banks-=(np.mean(filter_banks,axis=0)+1e-8) plt.imshow(np.flipud(filter_banks.T),cmap=plt.cm.jet,aspect=0.2,extent=[0,filter_banks.shape[1],0,filter_banks.shape[0]]) plt.show()
归一化的MFCC热力图
好了,本篇文章介绍就到此结束了,拜了个拜!

文章出处登录后可见!