系列文章目录
近红外光谱分析技术属于交叉领域,需要化学、计算机科学、生物科学等多领域的合作。为此,在(北京邮电大学杨辉华老师团队)指导下,近期准备开源传统的PLS,SVM,ANN,RF等经典算和SG,MSC,一阶导,二阶导等预处理以及GA等波长选择算法以及CNN、AE等最新深度学习算法,以帮助其他专业的更容易建立具有良好预测能力和鲁棒性的近红外光谱模型。
前言
NIRS是介于可见光和中红外光之间的电磁波,其波长范围为(1100∼2526 nm。 由于近红外光谱区与有机分子中含氢基团(OH、NH、CH、SH)振动的合频和 各级倍频的吸收区一致,通过扫描样品的近红外光谱,可以得到样品中有机分子含氢 基团的特征信息,常被作为获取样本信息的一种有效的载体。 基于NIRS的检测方法具有方便、高效、准确、成本低、可现场检测、不 破坏样品等优势,被广泛应用于各类检测领域。但 近红外光谱存在谱带宽、重叠较严重、吸收信号弱、信息解析复杂等问题,与常用的 化学分析方法不同,仅能作为一种间接测量方法,无法直接分析出被测样本的含量或 类别,它依赖于化学计量学方法,在样品待测属性值与近红外光谱数据之间建立一个 关联模型(或称校正模型,Calibration Model) ,再通过模型对未知样品的近红外光谱 进行预测来得到各性质成分的预测值。现有近红外建模方法主要为经典建模 (预处理+波长筛选进行特征降维和突出,再通过pls、svm算法进行建模)以及深度学习方法(端到端的建模,对预处理、波长选择等依赖性很低)本篇主要讲述基于python语言的光谱预处理方法,稍后更新matlab语言版本的光谱预处理方法,
一、预处理算法
# 最大最小值归一化
def MMS(data):
"""
:param data: raw spectrum data, shape (n_samples, n_features)
:return: data after MinMaxScaler :(n_samples, n_features)
"""
return MinMaxScaler().fit_transform(data)
# 标准化
def SS(data):
"""
:param data: raw spectrum data, shape (n_samples, n_features)
:return: data after StandScaler :(n_samples, n_features)
"""
return StandardScaler().fit_transform(data)
# 均值中心化
def CT(data):
"""
:param data: raw spectrum data, shape (n_samples, n_features)
:return: data after MeanScaler :(n_samples, n_features)
"""
for i in range(data.shape[0]):
MEAN = np.mean(data[i])
data[i] = data[i] - MEAN
return data
# 标准正态变换
def SNV(data):
"""
:param data: raw spectrum data, shape (n_samples, n_features)
:return: data after SNV :(n_samples, n_features)
"""
m = data.shape[0]
n = data.shape[1]
print(m, n) #
# 求标准差
data_std = np.std(data, axis=1) # 每条光谱的标准差
# 求平均值
data_average = np.mean(data, axis=1) # 每条光谱的平均值
# SNV计算
data_snv = [[((data[i][j] - data_average[i]) / data_std[i]) for j in range(n)] for i in range(m)]
return data_snv
# 移动平均平滑
def MA(data, WSZ=11):
"""
:param data: raw spectrum data, shape (n_samples, n_features)
:param WSZ: int
:return: data after MA :(n_samples, n_features)
"""
for i in range(data.shape[0]):
out0 = np.convolve(data[i], np.ones(WSZ, dtype=int), 'valid') / WSZ # WSZ是窗口宽度,是奇数
r = np.arange(1, WSZ - 1, 2)
start = np.cumsum(data[i, :WSZ - 1])[::2] / r
stop = (np.cumsum(data[i, :-WSZ:-1])[::2] / r)[::-1]
data[i] = np.concatenate((start, out0, stop))
return data
# Savitzky-Golay平滑滤波
def SG(data, w=11, p=2):
"""
:param data: raw spectrum data, shape (n_samples, n_features)
:param w: int
:param p: int
:return: data after SG :(n_samples, n_features)
"""
return signal.savgol_filter(data, w, p)
# 一阶导数
def D1(data):
"""
:param data: raw spectrum data, shape (n_samples, n_features)
:return: data after First derivative :(n_samples, n_features)
"""
n, p = data.shape
Di = np.ones((n, p - 1))
for i in range(n):
Di[i] = np.diff(data[i])
return Di
# 二阶导数
def D2(data):
"""
:param data: raw spectrum data, shape (n_samples, n_features)
:return: data after second derivative :(n_samples, n_features)
"""
data = deepcopy(data)
if isinstance(data, pd.DataFrame):
data = data.values
temp2 = (pd.DataFrame(data)).diff(axis=1)
temp3 = np.delete(temp2.values, 0, axis=1)
temp4 = (pd.DataFrame(temp3)).diff(axis=1)
spec_D2 = np.delete(temp4.values, 0, axis=1)
return spec_D2
# 趋势校正(DT)
def DT(data):
"""
:param data: raw spectrum data, shape (n_samples, n_features)
:return: data after DT :(n_samples, n_features)
"""
x = np.asarray(range(350, 2501), dtype=np.float32)
out = np.array(data)
l = LinearRegression()
for i in range(out.shape[0]):
l.fit(x.reshape(-1, 1), out[i].reshape(-1, 1))
k = l.coef_
b = l.intercept_
for j in range(out.shape[1]):
out[i][j] = out[i][j] - (j * k + b)
return out
# 多元散射校正
def MSC(data):
"""
:param data: raw spectrum data, shape (n_samples, n_features)
:return: data after MSC :(n_samples, n_features)
"""
n, p = data.shape
msc = np.ones((n, p))
for j in range(n):
mean = np.mean(data, axis=0)
# 线性拟合
for i in range(n):
y = data[i, :]
l = LinearRegression()
l.fit(mean.reshape(-1, 1), y.reshape(-1, 1))
k = l.coef_
b = l.intercept_
msc[i, :] = (y - b) / k
return msc
# 小波变换
def wave(data):
"""
:param data: raw spectrum data, shape (n_samples, n_features)
:return: data after wave :(n_samples, n_features)
"""
data = deepcopy(data)
if isinstance(data, pd.DataFrame):
data = data.values
def wave_(data):
w = pywt.Wavelet('db8') # 选用Daubechies8小波
maxlev = pywt.dwt_max_level(len(data), w.dec_len)
coeffs = pywt.wavedec(data, 'db8', level=maxlev)
threshold = 0.04
for i in range(1, len(coeffs)):
coeffs[i] = pywt.threshold(coeffs[i], threshold * max(coeffs[i]))
datarec = pywt.waverec(coeffs, 'db8')
return datarec
tmp = None
for i in range(data.shape[0]):
if (i == 0):
tmp = wave_(data[i])
else:
tmp = np.vstack((tmp, wave_(data[i])))
return tmp
代码如下(示例):
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
二.使用教程
1.搭建python环境
推荐基于anaconda安装python,参考安装如下:
基于anaconda安装python
2.引入库
import numpy as np
import matplotlib.pyplot as plt
from scipy import signal
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import MinMaxScaler, StandardScaler
3.读入数据、预处理以及展示
#载入数据
data_path = './/data//data.csv' #数据
xcol_path = './/data//xcol.csv' #波长
data = np.loadtxt(open(data_path, 'rb'), dtype=np.float64, delimiter=',', skiprows=0)
xcol = np.loadtxt(open(xcol_path, 'rb'), dtype=np.float64, delimiter=',', skiprows=0)
# 绘制MSC预处理后图片
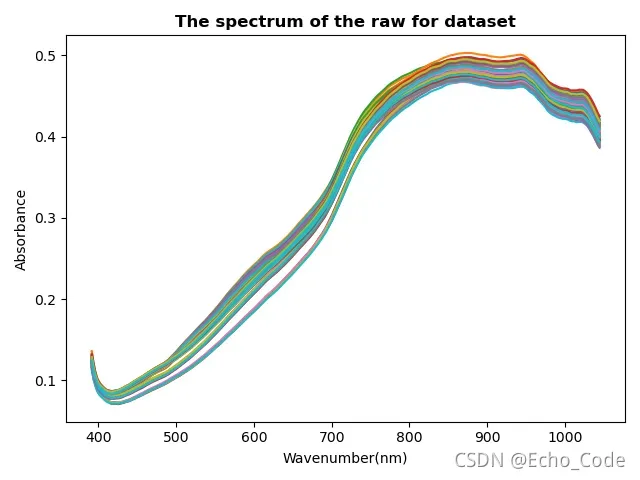
plt.figure(500)
x_col = xcol #数组逆序
y_col = np.transpose(data)
plt.plot(x_col, y_col)
plt.xlabel("Wavenumber(nm)")
plt.ylabel("Absorbance")
plt.title("The spectrum of the raw for dataset",fontweight= "semibold",fontsize='large') #记得改名字MSC
plt.show()
#数据预处理、可视化和保存
datareprocessing_path = './/data//dataMSC.csv' #波长
Data_Msc = MSC(data) #改这里的函数名就可以得到不同的预处理
# 绘制MSC预处理后图片
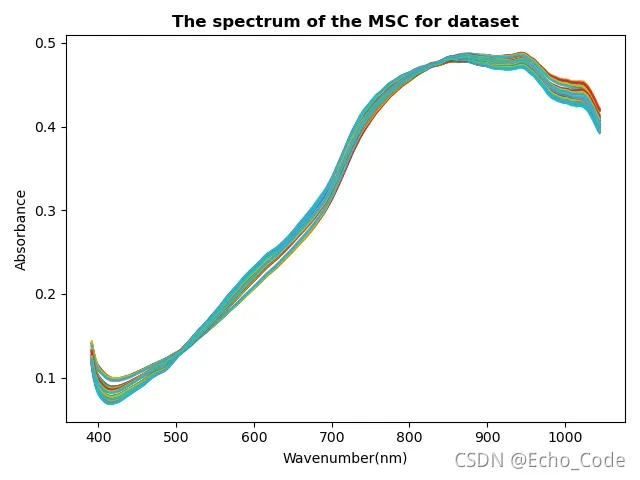
plt.figure(500)
x_col = xcol #数组逆序
y_col = np.transpose(Data_Msc)
plt.plot(x_col, y_col)
plt.xlabel("Wavenumber(nm)")
plt.ylabel("Absorbance")
plt.title("The spectrum of the MSC for dataset",fontweight= "semibold",fontsize='large') #记得改名字MSC
plt.show()
#保存预处理后的数据
np.savetxt(datareprocessing_path, Data_Msc, delimiter=',')
4.结果(以msc为例)
原始光谱
msc预处理后
总结
python代码参考湖南师范大学同学,完整代码可从获得GitHub仓库
代码仅供学术使用,如有问题,联系方式:QQ:1427950662,微信:Fu_siry
文章出处登录后可见!
已经登录?立即刷新