Stable Diffusion 是一种尖端的开源工具,用于从文本生成图像。 Stable Diffusion Web UI 通过 API 和交互式 UI 打开了许多这些功能。 我们将首先介绍如何使用此 API,然后设置一个示例,将其用作隐私保护微服务以从图像中删除人物。

推荐:用 NSDT场景设计器 快速搭建3D场景。
1、生成式AI简介
基于机器学习的数据生成器在去年发生了如此多的创新,你可以将 2022 年称为“生成 AI 年”。
我们有 DALL-E 2,这是来自 OpenAI 的文本到图像生成模型,它生成了宇航员骑马和狗穿着人衣服的惊人逼真的图像。 GitHub Copilot 是一款功能强大的代码完成工具,可以自动完成语句、编写文档并通过一条评论为您实现全部功能,已作为订阅服务向公众发布。
我们拥有 Dream Fields、Dream Fusion 和 Magic3D,这是一系列能够仅从文本生成带纹理的 3D 模型的开创性模型。 最后但同样重要的是,我们有 ChatGPT,这是当今不需要介绍的尖端人工智能聊天机器人。
这份清单几乎没有触及表面。 在像 DALL-E 2 这样的生成图像模型的世界中,我们还有 Midjourney、Google Imagen、StarryAI、WOMBO Dream、NightCafe、InvokeAI、Lexica Aperture、Dream Studio、Deforum……我想你明白了。 😉 📷 可以毫不夸张地说,生成式AI已经俘获了全世界的想象力。
2、Stable Diffusion
虽然许多流行的生成式 AI 工具(如 ChatGPT、GitHub Copilot 和 DALL-E 2)都是专有的和付费的,但开源社区并没有错过任何机会。 去年,LMU Munich、Runway 和 Stability AI 合作公开分享了 Stable Diffusion,这是一种强大而高效的文本到图像模型,足以在消费类硬件上运行。 这意味着任何拥有良好 GPU 和互联网连接的人都可以下载 Stable Diffusion 代码和模型权重,从而为世界带来低成本的图像生成。
3、Stable Diffusion Web UI
Stable Diffusion Web UI 是最流行的利用 Stable Diffusion 的工具之一,它在基于浏览器的交互式用户界面中公开了 Stable Diffusion 的各种设置和功能。 该项目的一个鲜为人知的功能是你可以将其用作 HTTP API,从而允许你从自己的应用程序请求图像。
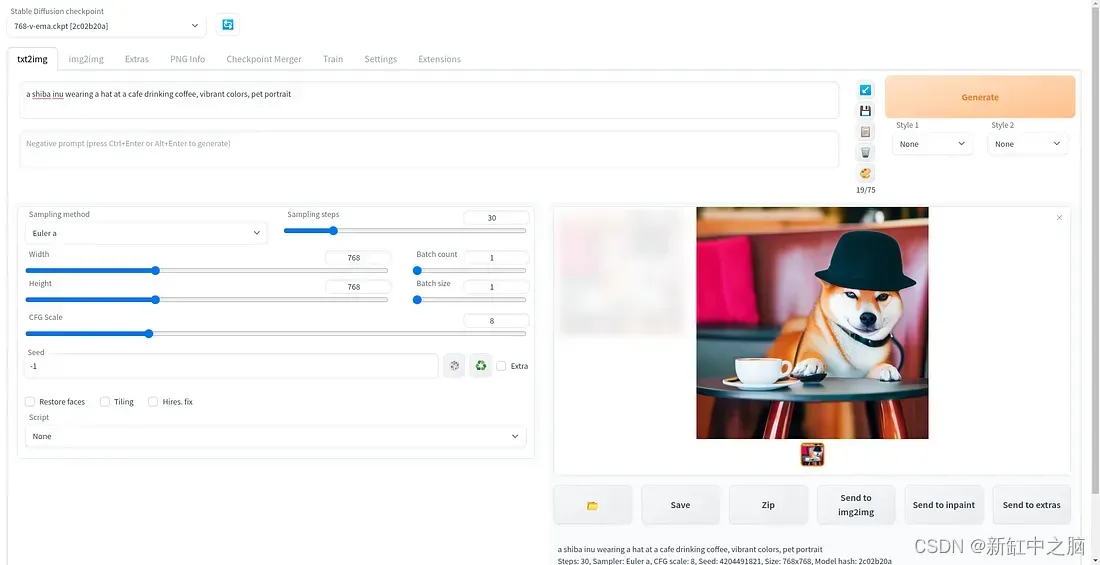
它具有大量功能,例如图像修复、图像扩展、调整大小、放大、变化等等。 项目 wiki 提供了所有功能的一个很好的概述。 此外,它还提供可扩展性脚本。
4、Stable Diffusion Web UI设置
在开始之前,请确保你的系统上有至少 8GB VRAM 的 GPU(最好是 NVIDIA,但也支持 AMD)。 这将确保你可以将模型加载到内存中。 接下来,需要将存储库克隆到你的系统(例如通过 HTTPS):
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
请按照系统的安装说明进行操作,因为它们可能与我的不同。 我安装了 Ubuntu 18.04 来设置它,但它也应该适用于 Windows 和 Apple Silicon。 这些说明将包括设置 Python 环境,因此请确保你设置的环境在稍后启动服务器时处于活动状态。
完成后,我们需要模型权重的副本。 我使用的是 Stable Diffusion 2.0,但现在也可以使用 Stable Diffusion 2.1。 无论选择哪个选项,请务必下载 stablediffusion 存储库的权重。 最后,将这些权重复制到 models/Stable-diffusion 文件夹,如下所示:
cp 768-v-ema.ckpt models/Stable-diffusion
现在应该准备好开始生成图像了! 要启动服务器,请从根目录执行以下命令(确保你设置的环境已激活):
python launch.py
服务器将需要一些时间来设置,因为它可能需要安装依赖、将模型权重加载到内存中以及检查嵌入等。 准备就绪后,应该会在终端中看到一条消息,如下所示:
Running on local URL: http://127.0.0.1:7860
用户界面是基于浏览器的,因此请在你喜欢的网络浏览器中导航到“127.0.0.1:7860”。如果它正常工作,它应该看起来像这样:
5、Stable Diffusion Web UI用法
现在应该准备好生成一些图像了! 继续并通过在“提示”字段中输入文本并单击“生成”来生成一些内容。 如果这是你第一次使用此 UI,请花点时间探索和了解它的一些功能和设置。 如果有任何问题,请参阅 wiki。 这些知识稍后在设计 API 时会派上用场。
我不会深入研究如何使用 Web UI,因为在我之前的许多人都这样做过。 但是,我将提供以下基本设置备忘单以供参考。
- 采样方法:采样算法。 这会极大地影响生成图像的内容和整体外观。 方法之间的执行时间和结果可能有很大差异。 最好先试验这个选项。
- 采样步数:图像生成过程中的去噪步数。 一些结果会随着步数的增加而发生巨大变化,而另一些结果会很快导致收益递减。 20-50 的值对于大多数采样器来说是理想的。
- 宽度、高度:输出图像尺寸。 对于 SD 2.0,768×768 是首选分辨率。 分辨率会影响生成的内容。
- CFG 量表:无分类器指导 (CFG) 量表。 增加它会增加提示对图像的影响程度。 较低的值会产生更具创意的结果。
- 去噪强度:确定允许原始图像的变化量。 值为 0.0 时不会发生任何变化。 值为 1.0 时会完全忽略原始图像。 从 0.4–0.6 之间的值开始通常是一个安全的选择。
- 种子:随机种子值。 当你想比较变化尽可能小的设置的效果时很有用。 如果喜欢特定的一代但想对其进行一些修改,请复制种子。
6、使用 Stable Diffusion 作为 API
Web UI 专为单个用户设计,非常适合作为交互式艺术工具来制作你自己的作品。 但是,如果我们想使用它作为引擎构建应用程序,那么我们将需要一个 API。 stable-diffusion-webui 项目的一个鲜为人知(且记录较少)的特性是它还有一个内置 API。 Web UI 是使用 Gradio 构建的,但还有一个 FastAPI 应用程序可以通过以下方式启动:
python launch.py --nowebui
这为我们提供了一个 API,可以公开我们在 Web UI 中拥有的许多功能。 我们可以发送带有我们的提示和参数的 POST 请求,并接收包含输出图像的响应。
7、创建Stable Diffusion微服务
例如,我们现在将设置一个简单的微服务,用于从照片中删除人物。 这有很多应用,例如保护个人隐私。 我们可以使用Stable Diffusion作为基本的隐私保护过滤器,它可以从照片中去除人物,而不会出现任何难看的马赛克或像素块。
请注意,这是一个基本设置; 它不包括加密、负载平衡、多租户、RBAC 或任何其他功能。 此设置可能不适用于生产环境,但它可用于在家庭或私人服务器上设置应用程序。
8、以API方式启动Stable Diffusion
以下说明将在 API 模式下使用服务器,因此请继续并使用 CTRL+C 暂时停止 Web UI。 使用 –nowebui 选项以 API 模式再次启动它:
python launch.py --nowebui
服务器准备好后应该打印如下内容:
INFO: Uvicorn running on http://127.0.0.1:7861 (Press CTRL+C to quit)
9、向 Stable Diffusion API 发送请求
我们要做的第一件事是演示如何向 API 发出请求。 我们希望向应用程序的 txt2img(即“文本到图像”)API 发送 POST 请求以简单地生成图像。
我们将使用 requests 包,所以如果你还没有安装它:
pip install requests
我们可以发送一个包含提示的请求作为一个简单的字符串。 服务器将返回一个图像作为 base64 编码的 PNG 文件,我们需要对其进行解码。 要解码 base64 图像,我们只需使用 base64.b64decode(b64_image)。 以下脚本应该是测试它所需的全部内容:
import json
import base64
import requests
def submit_post(url: str, data: dict):
"""
Submit a POST request to the given URL with the given data.
"""
return requests.post(url, data=json.dumps(data))
def save_encoded_image(b64_image: str, output_path: str):
"""
Save the given image to the given output path.
"""
with open(output_path, "wb") as image_file:
image_file.write(base64.b64decode(b64_image))
if __name__ == '__main__':
txt2img_url = 'http://127.0.0.1:7861/sdapi/v1/txt2img'
data = {'prompt': 'a dog wearing a hat'}
response = submit_post(txt2img_url, data)
save_encoded_image(response.json()['images'][0], 'dog.png')
将内容复制到文件并将其命名为 sample-request.py。 现在执行这个:
python sample-request.py
如果有效,它应该将图像的副本保存到文件 dog.png 中。 我的看起来像这个衣冠楚楚的家伙:

请记住,你的结果会与我的不同。 如果遇到问题,请仔细检查运行Stable Diffusion应用程序的终端的输出。 可能是服务器尚未完成设置。 如果您遇到“404 Not Found”之类的问题,请仔细检查 URL 是否输入正确并指向正确的地址(例如 127.0.0.1)。
10、设置图像掩码
如果到目前为止一切正常,那就太好了! 但是我们如何使用它来修改我们已有的图像呢? 为此,我们需要使用 img2img(即“图像到图像”)API。 此 API 使用稳定扩散来修改你提交的图像。 我们将使用修复功能:给定图像和遮罩,修复技术将尝试用稳定扩散生成的内容替换图像的遮罩部分。 遮罩充当权重,在原始图像和生成图像之间平滑插值,以将两者混合在一起。
我们将尝试使用我们可用的许多预训练计算机视觉模型之一来生成一个面具,而不是手工制作面具。 我们将使用模型输出的“人”类来生成掩码。 虽然对象检测模型可以工作,但我选择使用分割模型,以便您可以尝试使用密集掩码或边界框。
我们将需要一个示例图像来进行测试。 我们可以从 Internet 下载一个,但本着保护隐私(和版权)的精神,为什么不制作一个稳定传播的呢? 下面是我用提示“美丽的山景,一个女人从镜头前走开”生成的。

你可以下载这个,但我鼓励你尝试自己生成一个。 当然,你也可以使用真实照片。 以下是将来自 torchvision 的分割模型作为蒙版应用于此图像的最小代码。
import torch
from torchvision.models.segmentation import fcn_resnet50, FCN_ResNet50_Weights
from torchvision.io.image import read_image
from torchvision.utils import draw_segmentation_masks
import matplotlib.pyplot as plt
if __name__ == '__main__':
img_path = 'woman-on-trail.png'
# Load model
weights = FCN_ResNet50_Weights.DEFAULT
model = fcn_resnet50(weights=weights, progress=False)
model = model.eval()
# Load image
img = read_image(img_path)
# Run model
input_tform = weights.transforms(resize_size=None)
batch = torch.stack([input_tform(img)])
output = model(batch)['out']
# Apply softmax to outputs
sem_class_to_idx = {cls: idx for (idx, cls) in enumerate(weights.meta['categories'])}
normalized_mask = torch.nn.functional.softmax(output, dim=1)
# Show results
class_idx = 1
binary_masks = (normalized_mask.argmax(class_idx) == sem_class_to_idx['person'])
img_masked = draw_segmentation_masks(img, masks=binary_masks, alpha=0.7)
plt.imshow(img_masked.permute(1, 2, 0).numpy())
plt.show()
像以前一样,将其复制到名为 segment-person.py 的文件中。 使用以下代码执行代码:
python segment-person.py
生成的预测应如下所示:

我们现在拥有向 API 发出请求并预测边界框的机制。 现在我们可以开始构建我们的微服务了。
11、人物清除微服务
现在让我们转向我们的实际示例:从图像中删除人物。 微服务应执行以下操作:
- 读取多个输入参数
- 从文件加载图像
- 将类别为“person”的分割模型应用于图像以创建掩码
- 将图像和掩码转换为base64编码
- 向本地服务器的 img2img API 发送包含 base64 编码图像、base64 编码掩码、提示和任何参数的请求
- 解码并将输出图像保存为文件
由于我们已经分别介绍了所有这些步骤,因此已在此 GitHub Gist 中为您实施微服务。 现在下载脚本并使用以下命令在图像“woman-on-trail.png”(或您喜欢的任何图像)上执行它:
python inpaint-person.py woman-on-trail.png -W 1152 -H 768
-W 和 -H 分别表示所需的输出宽度和高度。 它将生成的图像保存为 inpaint-person.png,并将相应的蒙版保存为 mask_inpaint-person.png。 你的会有所不同,但这是我收到的输出:
嗯,不是我们想要的。 似乎人的大部分都还在,尤其是剪影。 我们可能需要遮盖更大的区域。 为此,让我们尝试将掩码转换为边界框。 我们可以使用 -B 标志来做到这一点。
`
python inpaint-person.py woman-on-trail.png -W 1152 -H 768 -B
我收到的输出是这样的:

这也不对! 混凝土柱不是我们期望在小径中间找到的东西。 也许引入提示将有助于将事情引向正确的方向。 我们使用 -p 标志在请求中添加提示“mountain scenery, landscape, trail”。 我们还使用 -D 32 扩大边界框以消除一些边缘效果,并使用 -b 16 模糊边界框以将掩码与背景混合一点。
python inpaint-person.py woman-on-trail.png \
-W 1152 -H 768 \
-b 16 -B -D 32 \
-p "mountain scenery, landscape, trail"
有了这个,我收到了以下输出:

现在看起来似乎不错! 继续尝试不同的图像、设置和提示,使其适合你的用例。 要查看此脚本可用的参数和提示的完整列表,请输入 python inpaint-person.py -h。
12、结束语
你的图像很可能与上面的图像看起来非常不同。 因为它是一个固有的随机过程,即使使用具有相同设置的稳定扩散也会产生截然不同的输出。 要了解所有功能和适当的提示设计,学习曲线相当陡峭,即使这样,结果也可能很挑剔。 使图像看起来完全符合您的喜好是非常困难的,需要反复试验。
为了帮助你完成任务,请记住以下提示:
- 在切换到 API 之前,使用 Web UI 找到适合你的用例的正确参数。
- 根据你的喜好微调图像时,依靠提示矩阵和 X/Y 绘图功能。 这些将帮助你快速探索参数搜索空间。
- 注意种子。 如果你喜欢特定的输出但想要对其进行迭代,请复制种子。
- 尝试使用不同的生成器,例如 Midjourney! 每个工具都略有不同。
- 使用 Lexica 等 Internet 资源作为灵感并找到好的提示。
- 使用设置菜单中的“使用生成参数在每个图像旁边创建一个文本文件”选项来跟踪你用于制作每个图像的提示和设置。
最重要的是,玩得开心!
原文链接:Stable Diffusion API — BimAnt
文章出处登录后可见!