

YOLOv5训练P R mAP等值为零
两种方法:关掉重新训练;更换训练环境
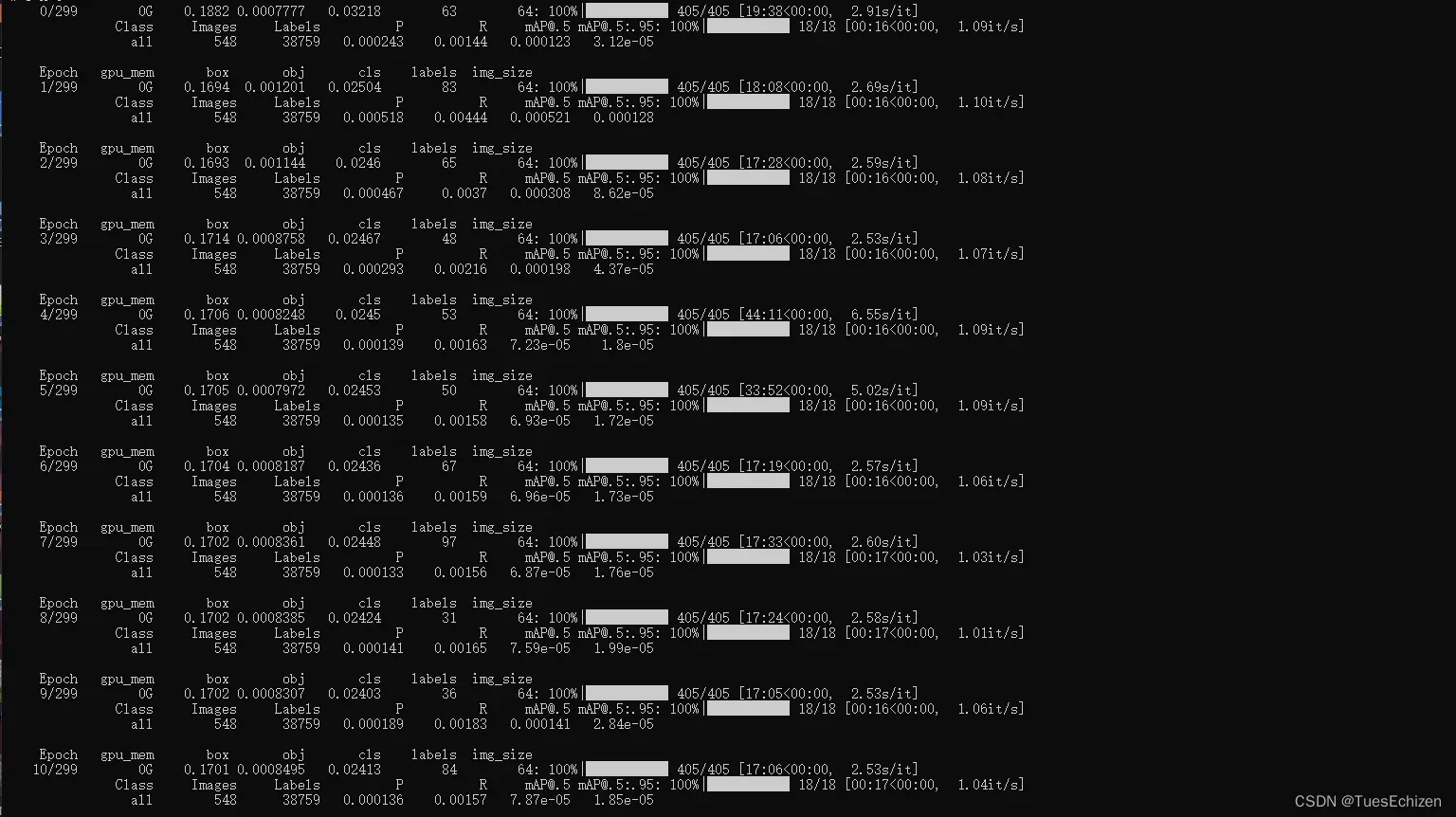

多版本CUDA(原10.1,新10.2)
安装过程参考
版本切换:将系统环境中的10.2相关路径移动到10.1相关路径的前面
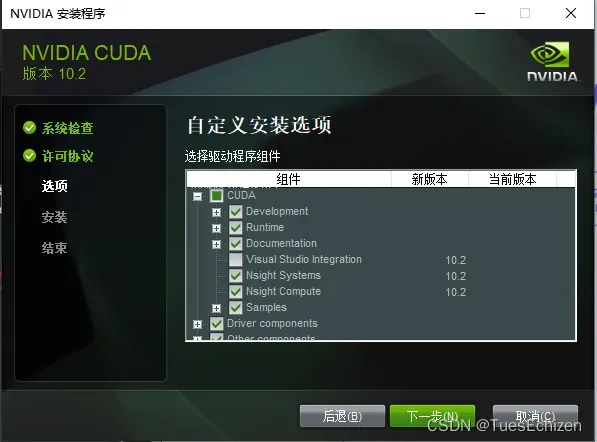

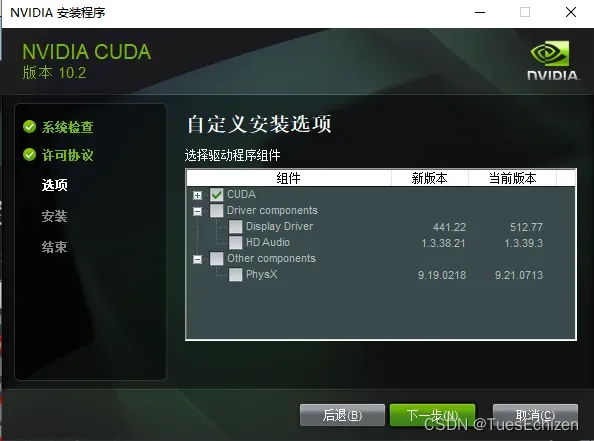
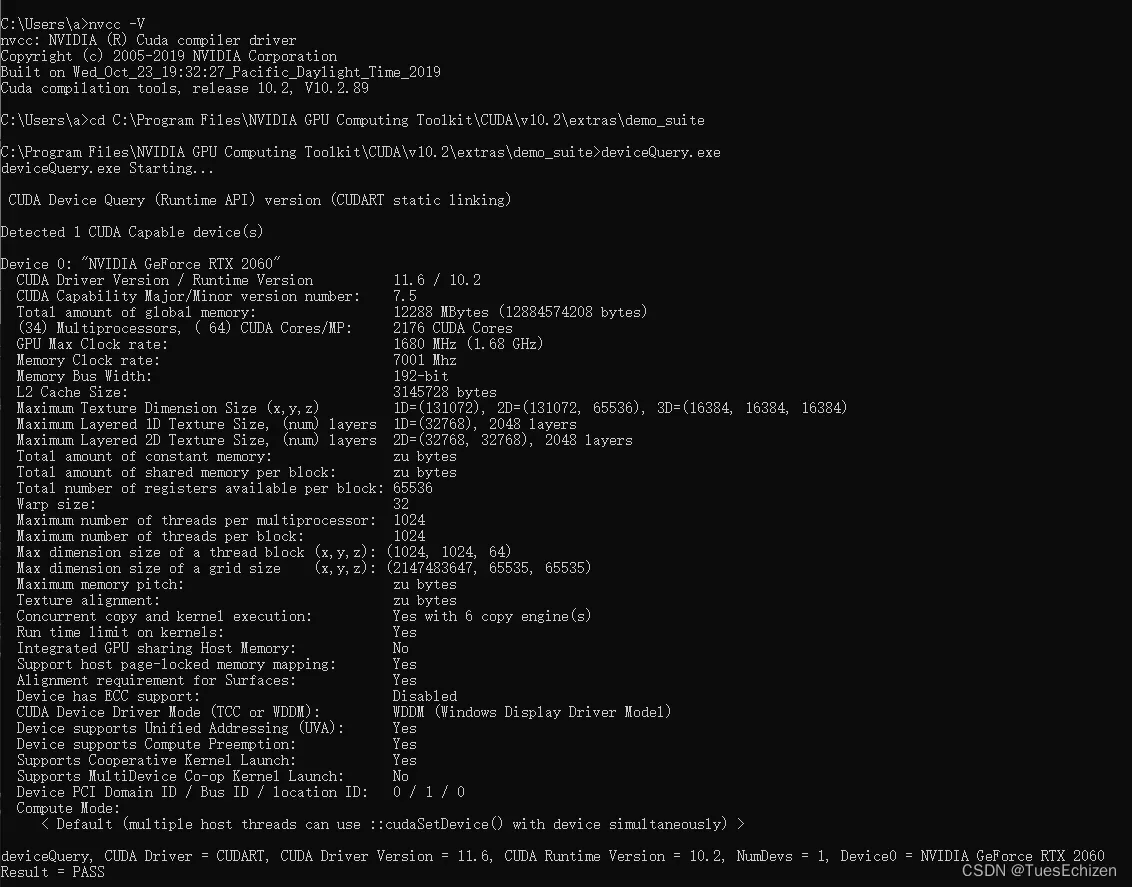


TensorFlow+CUDA+cuDNN版本传送门
torch
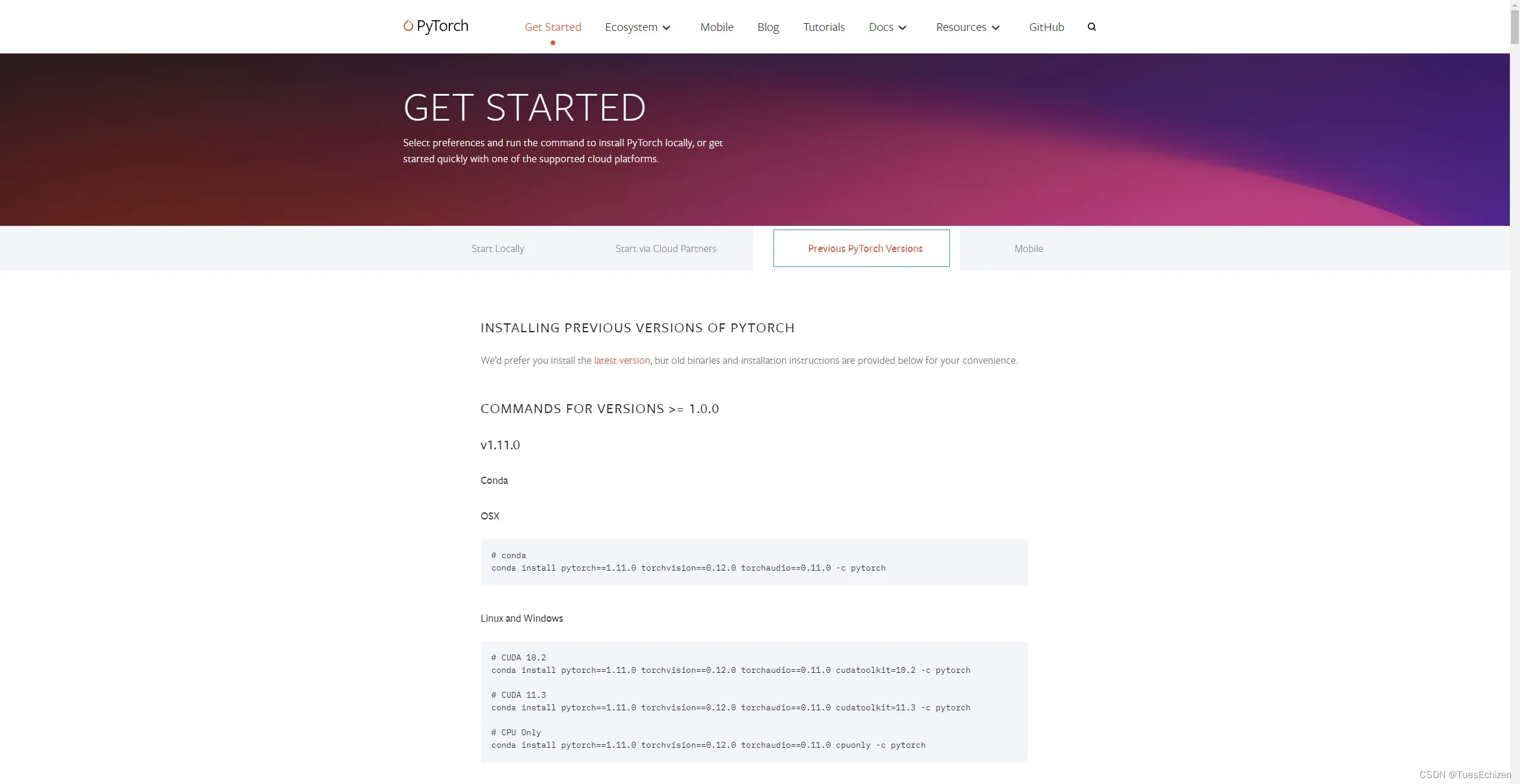
CUDA 10.2 版本安装命令,官方显示CUDA-10.2需要更换11.6.0:CUDA-10.2 PyTorch builds are no longer available for Windows, please use CUDA-11.6,实测远古10.2版本仍然可用Previous Versions
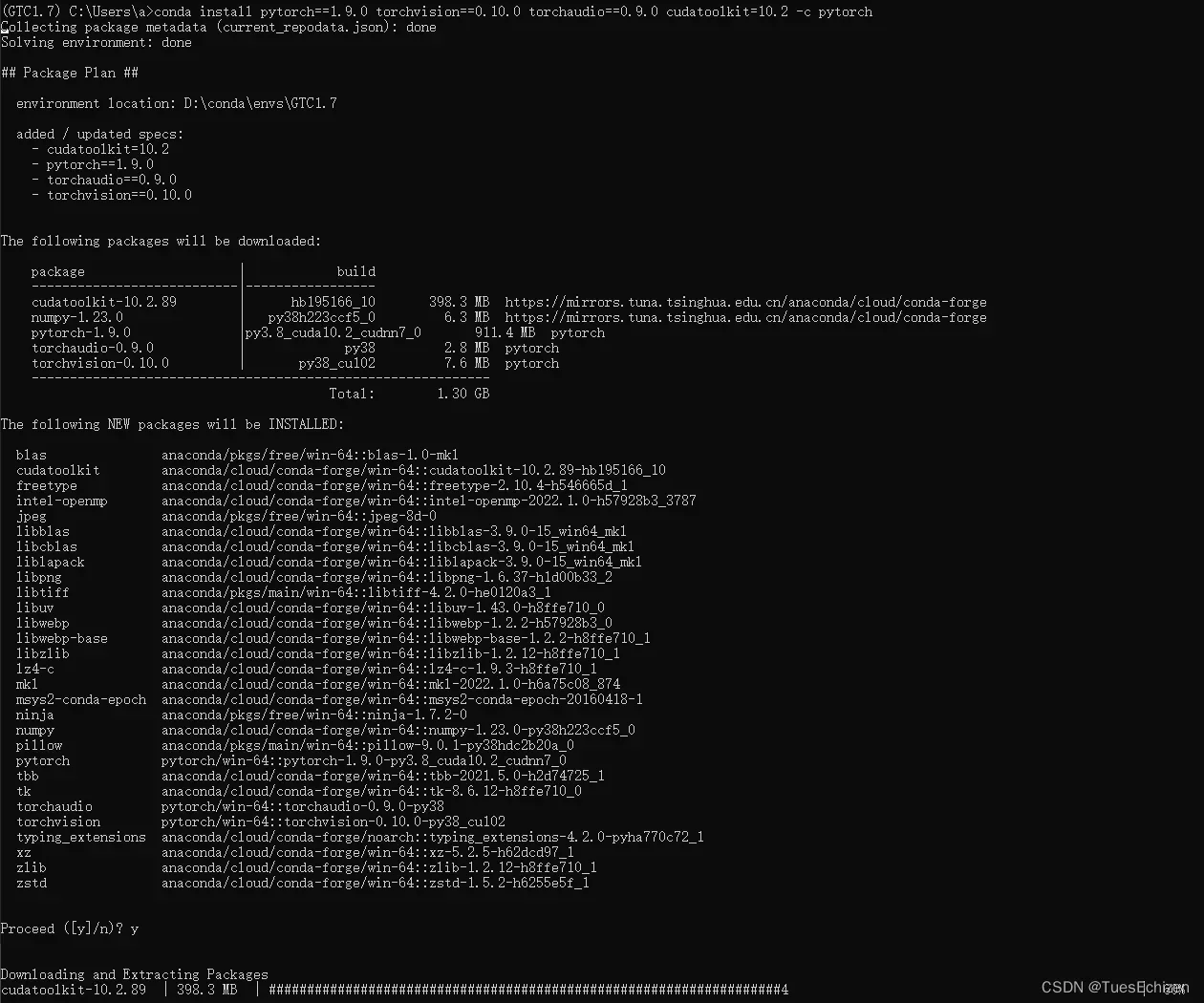
conda install pytorch==1.9.0 torchvision==0.10.0 torchaudio==0.9.0 cudatoolkit=10.2 -c pytorch -c conda-forge
# conda install pytorch==1.9.0 torchvision==0.10.0 torchaudio==0.9.0 cudatoolkit=11.6 -c pytorch -c conda-forge
# 加速
pip install torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html -i https://pypi.tuna.tsinghua.edu.cn/simple/ some-package --trusted-host mirrors.aliyun.com
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=11.1 -c pytorch -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/win-64/

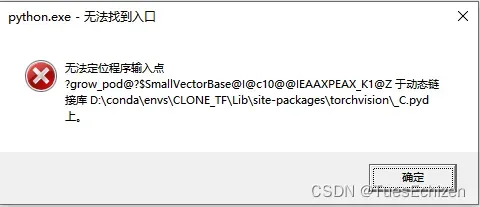
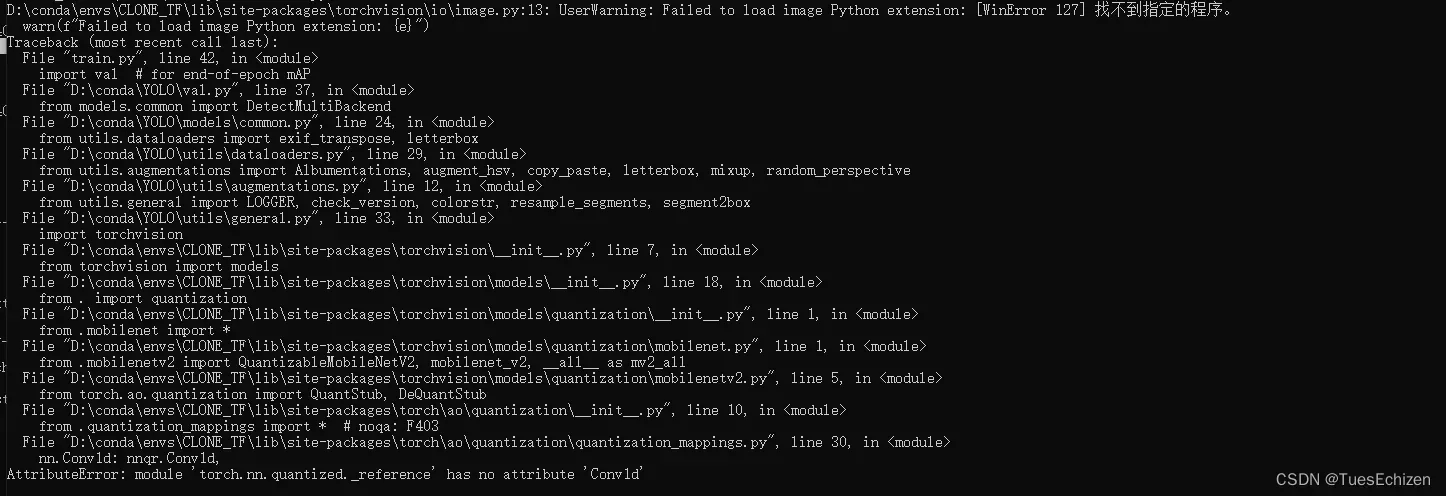



expected non-empty vector for x
YOLOv5 456c0e89 Python-3.8.0 torch-1.9.0 CUDA:0 (NVIDIA GeForce RTX 2060, 12288MiB)
hyperparameters: lr0=0.01, lrf=0.1, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.3, cls_pw=1.0, obj=0.7, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.9, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.1, copy_paste=0.1
Weights & Biases: run 'pip install wandb' to automatically track and visualize YOLOv5 runs (RECOMMENDED)
TensorBoard: Start with 'tensorboard --logdir runs\train', view at http://localhost:6006/
from n params module arguments
0 -1 1 8800 models.common.Conv [3, 80, 6, 2, 2]
1 -1 1 115520 models.common.Conv [80, 160, 3, 2]
2 -1 4 309120 models.common.C3 [160, 160, 4]
3 -1 1 461440 models.common.Conv [160, 320, 3, 2]
4 -1 8 2259200 models.common.C3 [320, 320, 8]
5 -1 1 1844480 models.common.Conv [320, 640, 3, 2]
6 -1 12 13125120 models.common.C3 [640, 640, 12]
7 -1 1 7375360 models.common.Conv [640, 1280, 3, 2]
8 -1 4 19676160 models.common.C3 [1280, 1280, 4]
9 -1 1 4099840 models.common.SPPF [1280, 1280, 5]
10 -1 1 820480 models.common.Conv [1280, 640, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 4 5332480 models.common.C3 [1280, 640, 4, False]
14 -1 1 205440 models.common.Conv [640, 320, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 4 1335040 models.common.C3 [640, 320, 4, False]
18 -1 1 922240 models.common.Conv [320, 320, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 4 4922880 models.common.C3 [640, 640, 4, False]
21 -1 1 3687680 models.common.Conv [640, 640, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 4 19676160 models.common.C3 [1280, 1280, 4, False]
24 [17, 20, 23] 1 107664 models.yolo.Detect [11, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [320, 640, 1280]]
Model summary: 567 layers, 86285104 parameters, 86285104 gradients
Transferred 745/745 items from runs\train\M5-13\weights\last.pt
AMP: checks passed
WARNING: --img-size 8 must be multiple of max stride 32, updating to 64
AutoBatch: Computing optimal batch size for --imgsz 64
AutoBatch: CUDA:0 (NVIDIA GeForce RTX 2060) 12.00G total, 0.69G reserved, 0.66G allocated, 10.65G free
Params GFLOPs GPU_mem (GB) forward (ms) backward (ms) input output
Unable to find a valid cuDNN algorithm to run convolution
Unable to find a valid cuDNN algorithm to run convolution
Unable to find a valid cuDNN algorithm to run convolution
CUDA out of memory. Tried to allocate 2.00 MiB (GPU 0; 12.00 GiB total capacity; 838.13 MiB already allocated; 9.33 GiB free; 866.00 MiB reserved in total by PyTorch)
Unable to find a valid cuDNN algorithm to run convolution
Traceback (most recent call last):
File "train.py", line 675, in <module>
main(opt)
File "train.py", line 570, in main
train(opt.hyp, opt, device, callbacks)
File "train.py", line 147, in train
batch_size = check_train_batch_size(model, imgsz, amp)
File "D:\conda\YOLO\utils\autobatch.py", line 18, in check_train_batch_size
return autobatch(deepcopy(model).train(), imgsz) # compute optimal batch size
File "D:\conda\YOLO\utils\autobatch.py", line 57, in autobatch
p = np.polyfit(batch_sizes[:len(y)], y, deg=1) # first degree polynomial fit
File "<__array_function__ internals>", line 180, in polyfit
File "D:\conda\envs\GTC1.7\lib\site-packages\numpy\lib\polynomial.py", line 638, in polyfit
raise TypeError("expected non-empty vector for x")
TypeError: expected non-empty vector for x
local variable ‘results’ referenced before assignment
results 进行初始化之后再进行操作
Traceback (most recent call last):
File "train.py", line 675, in <module>
main(opt)
File "train.py", line 570, in main
train(opt.hyp, opt, device, callbacks)
File "train.py", line 147, in train
batch_size = check_train_batch_size(model, imgsz, amp)
File "D:\conda\YOLO\utils\autobatch.py", line 18, in check_train_batch_size
return autobatch(deepcopy(model).train(), imgsz) # compute optimal batch size
File "D:\conda\YOLO\utils\autobatch.py", line 54, in autobatch
if results :
UnboundLocalError: local variable 'results' referenced before assignment
RuntimeError: CUDA out of memory. Tried to allocate 16.00 MiB (GPU 0; 12.00 GiB total capacity; 624.84 MiB already allocated; 9.56 GiB free; 654.00 MiB reserved in total by PyTorch)
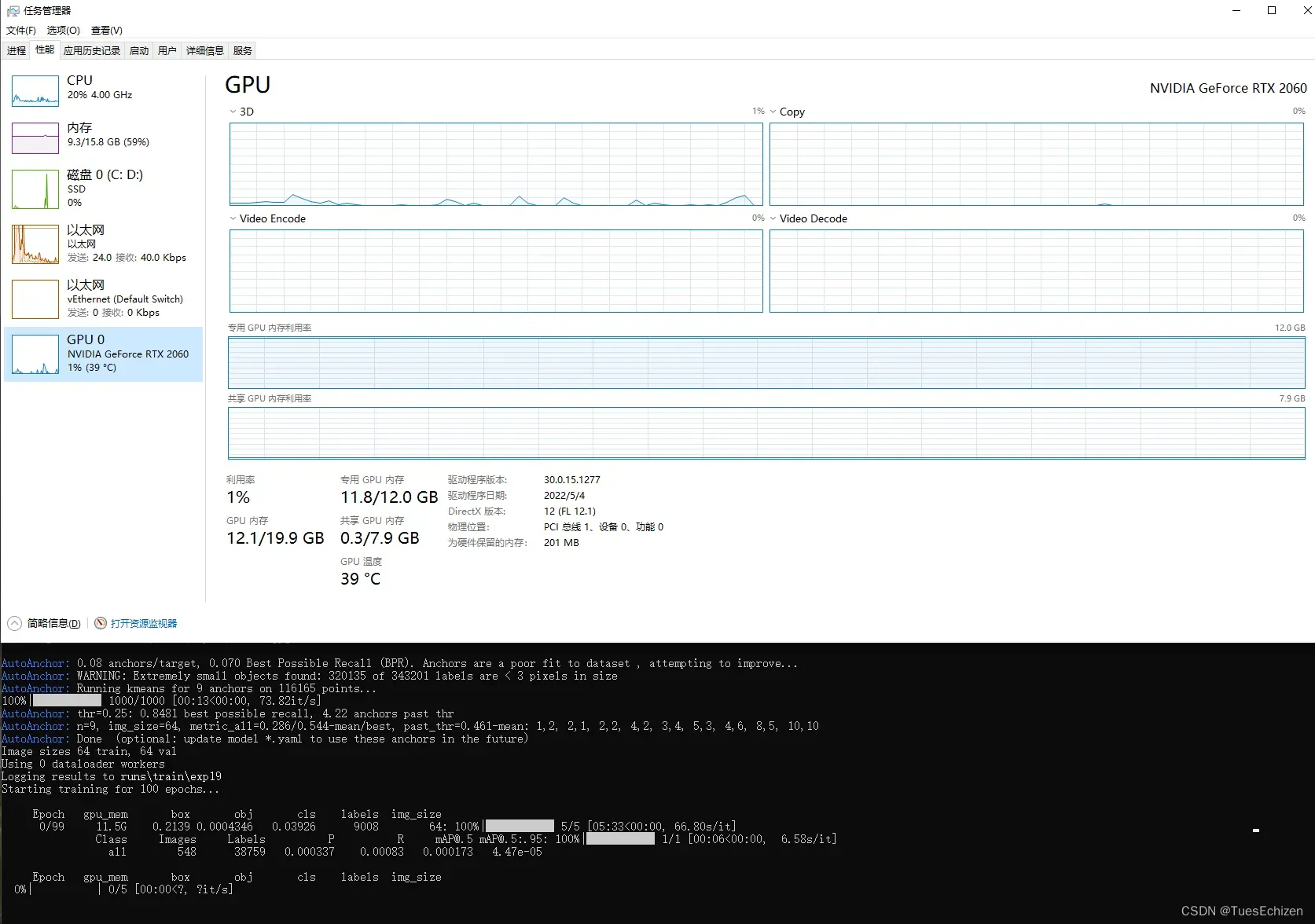

查看GPU使用率
Windows 10 : nvidia-smi -l n (实时刷新,n为时间间隔,单位秒s)
watch -n t -d nvidia-smi (实时刷新,t为时间间隔,单位秒s)
(看到能够用GPU训练的那一刻,开心的像个二傻子,吼吼吼)
别惹训练过程中GPU也会跳变嘛,求指点,安利看训练过程的工具GPU-Z
GPU-Z官方 国内源
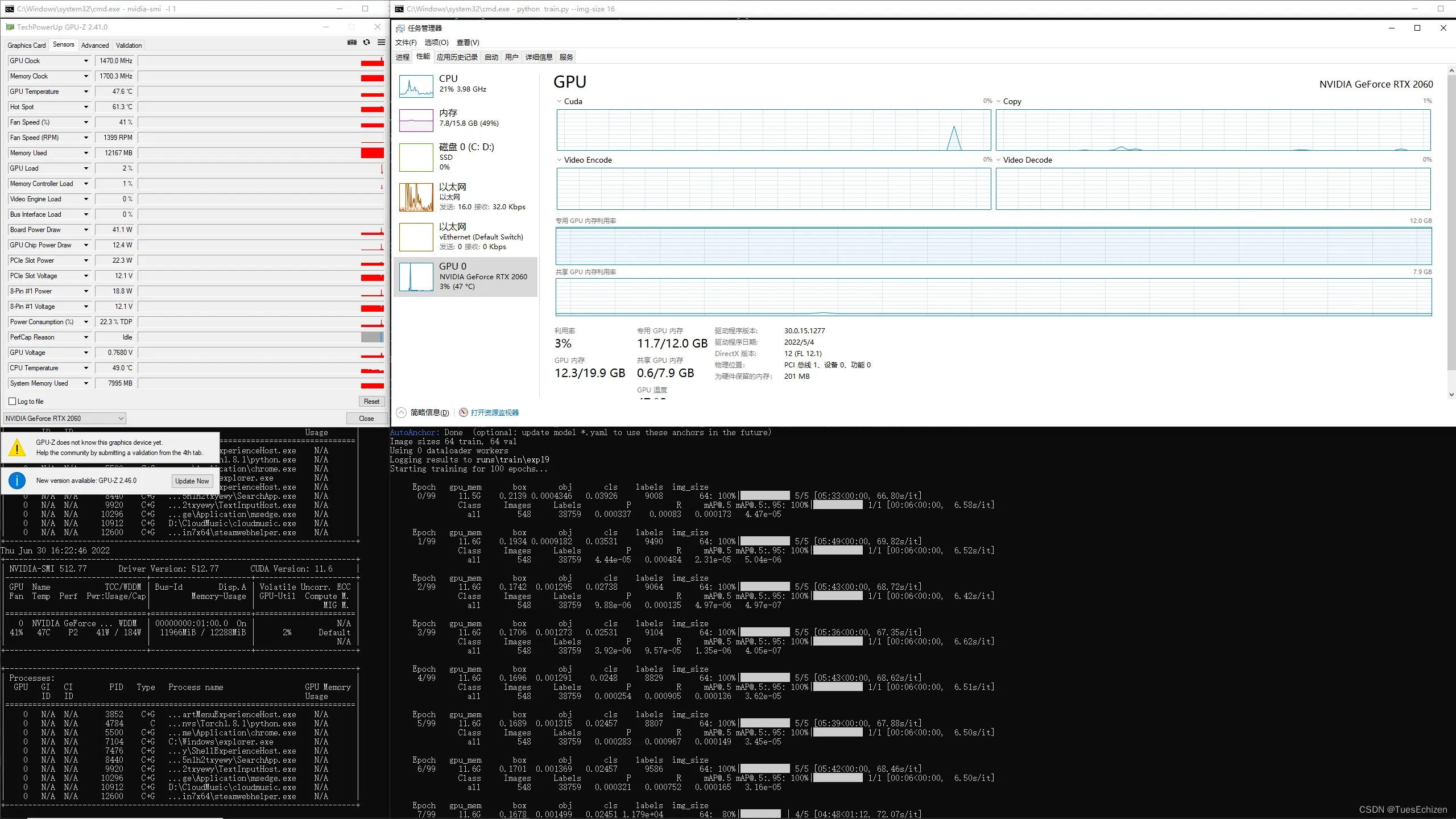

Fan :风扇转速
Temp :显卡温度
Perf :性能状态(PO->P12)
Pwr :能耗,使用量/总量
Busld :GPU总线
Disp.A :GPU显示是否已经初始化
Memory-Usage :显卡使用率
GPU-Util :GPU利用率
Compute M :计算模式
GPU利用率低
增大batch-size,设置多线程加载数据
torchvision.datasets.ImageFolder(
File "D:\conda\envs\TE\lib\site-packages\torchvision\datasets\folder.py", line 226, in __init__
super(ImageFolder, self).__init__(root, loader, IMG_EXTENSIONS if is_valid_file is None else None,
File "D:\conda\envs\TE\lib\site-packages\torchvision\datasets\folder.py", line 114, in __init__
raise RuntimeError(msg)
RuntimeError: Found 0 files in subfolders of: D:/Date/TEST/
Supported extensions are: .jpg,.jpeg,.png,.ppm,.bmp,.pgm,.tif,.tiff,.webp
DataLoader() 返回torch.Size([8, 3, 224, 224]) torch.Size([8])
torch.Size([8, 3, 224, 224]) # Batch,Channel,Width,Height
torch.Size([8]) # Batch
ValueError: optimizer got an empty parameter list
NotImplementedError
可能是某个函数没有对齐的原因(T:forward写成_forward)
TF 2.* 版本解决办法:升级 protoc >= 3.19.0
Traceback (most recent call last):
File "D:/conda/TF/im_main.py", line 1, in <module>
import tensorflow
File "D:\conda\envs\TF\lib\site-packages\tensorflow\__init__.py", line 41, in <module>
from tensorflow.python.tools import module_util as _module_util
File "D:\conda\envs\TF\lib\site-packages\tensorflow\python\__init__.py", line 40, in <module>
from tensorflow.python.eager import context
File "D:\conda\envs\TF\lib\site-packages\tensorflow\python\eager\context.py", line 32, in <module>
from tensorflow.core.framework import function_pb2
File "D:\conda\envs\TF\lib\site-packages\tensorflow\core\framework\function_pb2.py", line 16, in <module>
from tensorflow.core.framework import attr_value_pb2 as tensorflow_dot_core_dot_framework_dot_attr__value__pb2
File "D:\conda\envs\TF\lib\site-packages\tensorflow\core\framework\attr_value_pb2.py", line 16, in <module>
from tensorflow.core.framework import tensor_pb2 as tensorflow_dot_core_dot_framework_dot_tensor__pb2
File "D:\conda\envs\TF\lib\site-packages\tensorflow\core\framework\tensor_pb2.py", line 16, in <module>
from tensorflow.core.framework import resource_handle_pb2 as tensorflow_dot_core_dot_framework_dot_resource__handle__pb2
File "D:\conda\envs\TF\lib\site-packages\tensorflow\core\framework\resource_handle_pb2.py", line 16, in <module>
from tensorflow.core.framework import tensor_shape_pb2 as tensorflow_dot_core_dot_framework_dot_tensor__shape__pb2
File "D:\conda\envs\TF\lib\site-packages\tensorflow\core\framework\tensor_shape_pb2.py", line 36, in <module>
_descriptor.FieldDescriptor(
File "D:\conda\envs\TF\lib\site-packages\google\protobuf\descriptor.py", line 560, in __new__
_message.Message._CheckCalledFromGeneratedFile()
TypeError: Descriptors cannot not be created directly.
If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0.
If you cannot immediately regenerate your protos, some other possible workarounds are:
1. Downgrade the protobuf package to 3.20.x or lower.
2. Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower).
More information: https://developers.google.com/protocol-buffers/docs/news/2022-05-06#python-updates
TF 2.* 版本解决办法:
import tensorflow as tf
import tensorflow.keras
import numpy as np
import os
import sys
from tensorflow.keras.layers import Flatten , Dense , Dropout , Input
from tensorflow.keras.applications import VGG16
from tensorflow.keras.models import Model
from tensorflow.keras.models import load_model
from tensorflow.keras.models import model_from_yaml
2022-06-13 10:05:14.663841: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cudart64_101.dll
Traceback (most recent call last):
File "D:/conda/TF/im_main.py", line 2, in <module>
import keras
File "D:\conda\envs\TF\lib\site-packages\keras\__init__.py", line 24, in <module>
from keras import models
File "D:\conda\envs\TF\lib\site-packages\keras\models\__init__.py", line 18, in <module>
from keras.engine.functional import Functional
File "D:\conda\envs\TF\lib\site-packages\keras\engine\functional.py", line 23, in <module>
from keras import backend
File "D:\conda\envs\TF\lib\site-packages\keras\backend.py", line 39, in <module>
from tensorflow.python.eager.context import get_config
ImportError: cannot import name 'get_config' from 'tensorflow.python.eager.context' (D:\conda\envs\TF\lib\site-packages\tensorflow\python\eager\context.py)
2022-06-13 14:01:57.323214: W tensorflow/core/framework/op_kernel.cc:1744] OP_REQUIRES failed at cast_op.cc:124 : Unimplemented: Cast string to float is not supported
Traceback (most recent call last):
File "D:/conda/TF/im_main.py", line 49, in <module>
history = model.fit(
File "D:\conda\envs\TF\lib\site-packages\tensorflow\python\keras\engine\training.py", line 108, in _method_wrapper
return method(self, *args, **kwargs)
File "D:\conda\envs\TF\lib\site-packages\tensorflow\python\keras\engine\training.py", line 1098, in fit
tmp_logs = train_function(iterator)
File "D:\conda\envs\TF\lib\site-packages\tensorflow\python\eager\def_function.py", line 780, in __call__
result = self._call(*args, **kwds)
File "D:\conda\envs\TF\lib\site-packages\tensorflow\python\eager\def_function.py", line 840, in _call
return self._stateless_fn(*args, **kwds)
File "D:\conda\envs\TF\lib\site-packages\tensorflow\python\eager\function.py", line 2829, in __call__
return graph_function._filtered_call(args, kwargs) # pylint: disable=protected-access
File "D:\conda\envs\TF\lib\site-packages\tensorflow\python\eager\function.py", line 1843, in _filtered_call
return self._call_flat(
File "D:\conda\envs\TF\lib\site-packages\tensorflow\python\eager\function.py", line 1923, in _call_flat
return self._build_call_outputs(self._inference_function.call(
File "D:\conda\envs\TF\lib\site-packages\tensorflow\python\eager\function.py", line 545, in call
outputs = execute.execute(
File "D:\conda\envs\TF\lib\site-packages\tensorflow\python\eager\execute.py", line 59, in quick_execute
tensors = pywrap_tfe.TFE_Py_Execute(ctx._handle, device_name, op_name,
tensorflow.python.framework.errors_impl.UnimplementedError: Cast string to float is not supported
[[node binary_crossentropy/Cast (defined at /conda/TF/im_main.py:49) ]] [Op:__inference_train_function_1598]
Function call stack:
train_function
labels = np.ones_like(lists) ==> labels = np.ones_like(lists , dtype = int )
2022-06-13 14:40:17.548683: W tensorflow/core/framework/op_kernel.cc:1744] OP_REQUIRES failed at cast_op.cc:124 : Unimplemented: Cast string to float is not supported
Traceback (most recent call last):
File "D:/conda/TF/im_main.py", line 50, in <module>
history = model.fit(
File "D:\conda\envs\TF\lib\site-packages\tensorflow\python\keras\engine\training_v1.py", line 790, in fit
return func.fit(
File "D:\conda\envs\TF\lib\site-packages\tensorflow\python\keras\engine\training_arrays.py", line 649, in fit
return fit_loop(
File "D:\conda\envs\TF\lib\site-packages\tensorflow\python\keras\engine\training_arrays.py", line 297, in model_iteration
batch_outs = f(actual_inputs)
File "D:\conda\envs\TF\lib\site-packages\tensorflow\python\keras\backend.py", line 3822, in __call__
self._make_callable(feed_arrays, feed_symbols, symbol_vals, session)
File "D:\conda\envs\TF\lib\site-packages\tensorflow\python\keras\backend.py", line 3759, in _make_callable
callable_fn = session._make_callable_from_options(callable_opts)
File "D:\conda\envs\TF\lib\site-packages\tensorflow\python\client\session.py", line 1505, in _make_callable_from_options
return BaseSession._Callable(self, callable_options)
File "D:\conda\envs\TF\lib\site-packages\tensorflow\python\client\session.py", line 1459, in __init__
self._handle = tf_session.TF_SessionMakeCallable(
tensorflow.python.framework.errors_impl.UnimplementedError: Cast string to float is not supported
[[{{node Cast}}]]
RuntimeError: [enforce fail at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\c10\core\impl\alloc_cpu.cpp:81] data. DefaultCPUAllocator: not enough memory: you tried to allocate 3145728 bytes
解决办法
Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 116, in spawn_main
exitcode = _main(fd, parent_sentinel)
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 125, in _main
prepare(preparation_data)
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 236, in prepare
_fixup_main_from_path(data['init_main_from_path'])
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 287, in _fixup_main_from_path
main_content = runpy.run_path(main_path,
File "D:\conda\envs\Torch1.8.1\lib\runpy.py", line 262, in run_path
return _run_module_code(code, init_globals, run_name,
File "D:\conda\envs\Torch1.8.1\lib\runpy.py", line 95, in _run_module_code
_run_code(code, mod_globals, init_globals,
File "D:\conda\envs\Torch1.8.1\lib\runpy.py", line 85, in _run_code
exec(code, run_globals)
File "D:\conda\YOLO\train.py", line 26, in <module>
import torch
File "D:\conda\envs\Torch1.8.1\lib\site-packages\torch\__init__.py", line 123, in <module>
raise err
OSError: [WinError 1455] 页面文件太小,无法完成操作。 Error loading "D:\conda\envs\Torch1.8.1\lib\site-packages\torch\lib\caffe2_detectron_ops_gpu.dll" or one of its dependencies.
Traceback (most recent call last):
Traceback (most recent call last):
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "<string>", line 1, in <module>
File "<string>", line 1, in <module>
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 116, in spawn_main
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 116, in spawn_main
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 116, in spawn_main
exitcode = _main(fd, parent_sentinel)
exitcode = _main(fd, parent_sentinel)
exitcode = _main(fd, parent_sentinel)
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 125, in _main
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 125, in _main
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 125, in _main
prepare(preparation_data)
prepare(preparation_data)
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 236, in prepare
prepare(preparation_data)
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 236, in prepare
_fixup_main_from_path(data['init_main_from_path'])
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 236, in prepare
_fixup_main_from_path(data['init_main_from_path'])
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 287, in _fixup_main_from_path
_fixup_main_from_path(data['init_main_from_path'])
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 287, in _fixup_main_from_path
main_content = runpy.run_path(main_path,
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 287, in _fixup_main_from_path
main_content = runpy.run_path(main_path,
File "D:\conda\envs\Torch1.8.1\lib\runpy.py", line 262, in run_path
main_content = runpy.run_path(main_path,
File "D:\conda\envs\Torch1.8.1\lib\runpy.py", line 262, in run_path
return _run_module_code(code, init_globals, run_name,
File "D:\conda\envs\Torch1.8.1\lib\runpy.py", line 262, in run_path
return _run_module_code(code, init_globals, run_name,
File "D:\conda\envs\Torch1.8.1\lib\runpy.py", line 95, in _run_module_code
return _run_module_code(code, init_globals, run_name,
File "D:\conda\envs\Torch1.8.1\lib\runpy.py", line 95, in _run_module_code
_run_code(code, mod_globals, init_globals,
File "D:\conda\envs\Torch1.8.1\lib\runpy.py", line 95, in _run_module_code
_run_code(code, mod_globals, init_globals,
File "D:\conda\envs\Torch1.8.1\lib\runpy.py", line 85, in _run_code
_run_code(code, mod_globals, init_globals,
File "D:\conda\envs\Torch1.8.1\lib\runpy.py", line 85, in _run_code
exec(code, run_globals)
File "D:\conda\envs\Torch1.8.1\lib\runpy.py", line 85, in _run_code
exec(code, run_globals)
File "D:\conda\YOLO\train.py", line 26, in <module>
exec(code, run_globals)
File "D:\conda\YOLO\train.py", line 26, in <module>
import torch
File "D:\conda\YOLO\train.py", line 26, in <module>
File "D:\conda\envs\Torch1.8.1\lib\site-packages\torch\__init__.py", line 123, in <module>
import torch
raise err
import torch
File "D:\conda\envs\Torch1.8.1\lib\site-packages\torch\__init__.py", line 123, in <module>
OSError: [WinError 1455] 页面文件太小,无法完成操作。 Error loading "D:\conda\envs\Torch1.8.1\lib\site-packages\torch\lib\caffe2_detectron_ops_gpu.dll" or one of its dependencies.
File "D:\conda\envs\Torch1.8.1\lib\site-packages\torch\__init__.py", line 123, in <module>
raise err
raise err
OSError: [WinError 1455] 页面文件太小,无法完成操作。 Error loading "D:\conda\envs\Torch1.8.1\lib\site-packages\torch\lib\caffe2_detectron_ops_gpu.dll" or one of its dependencies.
OSError: [WinError 1455] 页面文件太小,无法完成操作。 Error loading "D:\conda\envs\Torch1.8.1\lib\site-packages\torch\lib\caffe2_detectron_ops_gpu.dll" or one of its dependencies.
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 116, in spawn_main
exitcode = _main(fd, parent_sentinel)
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 125, in _main
prepare(preparation_data)
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 236, in prepare
_fixup_main_from_path(data['init_main_from_path'])
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 287, in _fixup_main_from_path
main_content = runpy.run_path(main_path,
File "D:\conda\envs\Torch1.8.1\lib\runpy.py", line 262, in run_path
return _run_module_code(code, init_globals, run_name,
File "D:\conda\envs\Torch1.8.1\lib\runpy.py", line 95, in _run_module_code
_run_code(code, mod_globals, init_globals,
File "D:\conda\envs\Torch1.8.1\lib\runpy.py", line 85, in _run_code
exec(code, run_globals)
File "D:\conda\YOLO\train.py", line 26, in <module>
import torch
File "D:\conda\envs\Torch1.8.1\lib\site-packages\torch\__init__.py", line 123, in <module>
raise err
OSError: [WinError 1455] 页面文件太小,无法完成操作。 Error loading "D:\conda\envs\Torch1.8.1\lib\site-packages\torch\lib\caffe2_detectron_ops_gpu.dll" or one of its dependencies.
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 116, in spawn_main
Traceback (most recent call last):
exitcode = _main(fd, parent_sentinel)
File "<string>", line 1, in <module>
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 125, in _main
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 116, in spawn_main
prepare(preparation_data)
exitcode = _main(fd, parent_sentinel)
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 236, in prepare
Traceback (most recent call last):
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 125, in _main
_fixup_main_from_path(data['init_main_from_path'])
File "<string>", line 1, in <module>
prepare(preparation_data)
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 287, in _fixup_main_from_path
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 116, in spawn_main
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 236, in prepare
main_content = runpy.run_path(main_path,
File "D:\conda\envs\Torch1.8.1\lib\runpy.py", line 262, in run_path
return _run_module_code(code, init_globals, run_name,
exitcode = _main(fd, parent_sentinel)
_fixup_main_from_path(data['init_main_from_path'])
File "D:\conda\envs\Torch1.8.1\lib\runpy.py", line 95, in _run_module_code
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 125, in _main
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 287, in _fixup_main_from_path
_run_code(code, mod_globals, init_globals,
prepare(preparation_data)
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 236, in prepare
main_content = runpy.run_path(main_path,
File "D:\conda\envs\Torch1.8.1\lib\runpy.py", line 85, in _run_code
_fixup_main_from_path(data['init_main_from_path'])
File "D:\conda\envs\Torch1.8.1\lib\runpy.py", line 262, in run_path
exec(code, run_globals)
return _run_module_code(code, init_globals, run_name,
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\spawn.py", line 287, in _fixup_main_from_path
File "D:\conda\YOLO\train.py", line 26, in <module>
File "D:\conda\envs\Torch1.8.1\lib\runpy.py", line 95, in _run_module_code
main_content = runpy.run_path(main_path,
import torch
_run_code(code, mod_globals, init_globals,
File "D:\conda\envs\Torch1.8.1\lib\runpy.py", line 262, in run_path
File "D:\conda\envs\Torch1.8.1\lib\site-packages\torch\__init__.py", line 123, in <module>
File "D:\conda\envs\Torch1.8.1\lib\runpy.py", line 85, in _run_code
return _run_module_code(code, init_globals, run_name,
raise err
exec(code, run_globals)
File "D:\conda\envs\Torch1.8.1\lib\runpy.py", line 95, in _run_module_code
OSError: [WinError 1455] 页面文件太小,无法完成操作。 Error loading "D:\conda\envs\Torch1.8.1\lib\site-packages\torch\lib\caffe2_detectron_ops_gpu.dll" or one of its dependencies.
File "D:\conda\YOLO\train.py", line 26, in <module>
_run_code(code, mod_globals, init_globals,
import torch
File "D:\conda\envs\Torch1.8.1\lib\runpy.py", line 85, in _run_code
File "D:\conda\envs\Torch1.8.1\lib\site-packages\torch\__init__.py", line 123, in <module>
exec(code, run_globals)
raise err
File "D:\conda\YOLO\train.py", line 26, in <module>
OSError: [WinError 1455] 页面文件太小,无法完成操作。 Error loading "D:\conda\envs\Torch1.8.1\lib\site-packages\torch\lib\caffe2_detectron_ops_gpu.dll" or one of its dependencies.
import torch
File "D:\conda\envs\Torch1.8.1\lib\site-packages\torch\__init__.py", line 123, in <module>
raise err
OSError: [WinError 1455] 页面文件太小,无法完成操作。 Error loading "D:\conda\envs\Torch1.8.1\lib\site-packages\torch\lib\caffe2_detectron_ops_gpu.dll" or one of its dependencies.
train: Scanning 'D:\VisDrone\VisDrone2019-DET-train\labels' images and labels...: 0%| | 0/6471 [00:08<?, ?it/s]
Traceback (most recent call last):
File "D:\conda\YOLO\utils\dataloaders.py", line 450, in __init__
assert cache['hash'] == get_hash(self.label_files + self.im_files) # same hash
AssertionError
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\pool.py", line 848, in next
item = self._items.popleft()
IndexError: pop from an empty deque
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "train.py", line 677, in <module>
main(opt)
File "train.py", line 572, in main
train(opt.hyp, opt, device, callbacks)
File "train.py", line 224, in train
train_loader, dataset = create_dataloader(train_path,
File "D:\conda\YOLO\utils\dataloaders.py", line 114, in create_dataloader
dataset = LoadImagesAndLabels(
File "D:\conda\YOLO\utils\dataloaders.py", line 452, in __init__
cache, exists = self.cache_labels(cache_path, prefix), False # cache
File "D:\conda\YOLO\utils\dataloaders.py", line 543, in cache_labels
for im_file, lb, shape, segments, nm_f, nf_f, ne_f, nc_f, msg in pbar:
File "D:\conda\envs\Torch1.8.1\lib\site-packages\tqdm\std.py", line 1195, in __iter__
for obj in iterable:
File "D:\conda\envs\Torch1.8.1\lib\multiprocessing\pool.py", line 853, in next
self._cond.wait(timeout)
File "D:\conda\envs\Torch1.8.1\lib\threading.py", line 302, in wait
waiter.acquire()
KeyboardInterrupt
Traceback (most recent call last):
File "train.py", line 663, in <module>
main(opt)
File "train.py", line 558, in main
train(opt.hyp, opt, device, callbacks)
File "train.py", line 315, in train
for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------
File "D:\conda\envs\Torch1.8.1\lib\site-packages\tqdm\std.py", line 1195, in __iter__
for obj in iterable:
File "D:\conda\YOLO\utils\dataloaders.py", line 158, in __iter__
yield next(self.iterator)
File "D:\conda\envs\Torch1.8.1\lib\site-packages\torch\utils\data\dataloader.py", line 517, in __next__
data = self._next_data()
File "D:\conda\envs\Torch1.8.1\lib\site-packages\torch\utils\data\dataloader.py", line 557, in _next_data
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
File "D:\conda\envs\Torch1.8.1\lib\site-packages\torch\utils\data\_utils\fetch.py", line 44, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "D:\conda\envs\Torch1.8.1\lib\site-packages\torch\utils\data\_utils\fetch.py", line 44, in <listcomp>
data = [self.dataset[idx] for idx in possibly_batched_index]
File "D:\conda\YOLO\utils\dataloaders.py", line 587, in __getitem__
img, labels = self.load_mosaic(index)
File "D:\conda\YOLO\utils\dataloaders.py", line 687, in load_mosaic
img, _, (h, w) = self.load_image(index)
File "D:\conda\YOLO\utils\dataloaders.py", line 661, in load_image
im = cv2.imread(f) # BGR
File "D:\conda\YOLO\utils\general.py", line 999, in imread
return cv2.imdecode(np.fromfile(path, np.uint8), flags)
cv2.error: OpenCV(4.1.2) C:\projects\opencv-python\opencv\modules\core\src\alloc.cpp:73: error: (-4:Insufficient memory) Failed to allocate 9000000 bytes in function 'cv::OutOfMemoryError'
文章出处登录后可见!
已经登录?立即刷新