MATLAB深度学习(1) — 想要做好深度学习?数据集是第一步
- 创作目的
- 项目简介
- 本期重点—数据集构建
- 本文所使用数据集简介
- 用table来搭建训练集
- 总结
创作目的
大家好,这里是微信公众号—程飞谈在CSDN上开始做的一些新的尝试,因为我本身是智能建造专业,需要对深度学习有一定的认识,同时也希望更加深入的理解深度学习,以及创建和大家共同交流深度学习的平台,所以我打算做一期深度学习全流程的系列文章(顺便介绍一些我们组科研的思路)。
我打算基于我自己研究的一个课题,详细的介绍我们团队是如何使用MATLAB来完成整个深度学习的过程,希望更多的小伙伴可以加入“深度学习大家庭”,让我们共同进步吧!
项目简介
该项目的目标是想基于某些人的行走引起的楼板振动加速度作为数据,通过深度学习方案,来将这些人的身份进行识别。
该项目大致会分为5步:
- 数据集构建
- 网络搭建(可能会变换多种网络)
- 网络参数选取
- 训练,并基于训练结果调整
- 得出结论
当然,该项目是一个全新的课题,充满挑战,所以每一期可能解决的只是项目中的一个问题。对于深度学习方案真正应用到全新的环境中,这确实是一个挑战,但是我们悬着迎难而上!
本期重点—数据集构建
说到这里,我又想闲聊几句,通常深度学习方案更多的是采用Python去完成,对于MATLAB进行深度学习了解不够多,包括我自己也是这个样子,但是MATLAB在深度学习上也做了很多努力,我本人也是抱着去看看的心态,来使用MATLAB的深度学习方案。
言归正传
数据集是深度学习方案中非常重要的一环,数据集在很大程度影响该神经网络的最终最终表现。
但是我觉着人们的关注点可能也是更多关注于数据集的好坏,尤其是在学习深度学习的过程中,数据集大多是库中已经构建好的,所以不太关系数据集的构建。
但是,我个人感觉在好不好之前,数据集一定要可以做到能不能用,它的格式符不符合使用的标准,也是非常重要的一环,或者这是对于我们科研人员的一个很高的要求!
本文所使用数据集简介
正如上图所示,这是我通过数值模拟产生的数据,hz表示该人行走的频率,name表示这个人的名字,udd_all则表示所有人的引起楼板振动的加速度数据。
MATLAB深度学习对于数据的格式所谓是很挑剔,就像是十七八岁的小姑娘,看见自己喜欢男孩子,总是觉着他这里不好,那么也不好。所以构建数据集本身对于格式一定要搞清楚!
上图展示的是最原始的数据,本项目打算做的是卷积神经网络方案,卷积神经网络,更喜欢的是图片数据,对于图片数据的处理也是一门学问(就像p图一样)。但是本文做的是时间序列的分析,所以问题显得没有那么常规。
udd_all的数据类型是cell,matlab的cell就是一个大胃王,什么都可以往cell里面装,cell我使用起来最顺手的两点:
| 优点 | 描述 |
|---|---|
| 1 | 不像array一样有固定大小,可以随意扩展 |
| 2 | 内部的东西不管什么格式,也不管长度是否一致,都可以放 |
因此,cell就是储存原始数据的一个好手。
但是,卷积神经网络的的数据集可以就不一样,挑剔死了。
她要求 数据需要三种形态(报错的时候会提醒,我也是根据报错一步一步调整过来的),因为我们是不是图像数据,所以我们选择相对来说入门最简单的table!
用table来搭建训练集
- 首先导入木楼板数据
%% 导入木楼板数据
load mlb_data;
- 将字符串标签转化为整数标签
在pyhton的深度学习中,对于标签我们也是有讲究的,比如像是姓名这种字符串类型的数据,通常是不能作为标签来使用(这句话我不是特别确定(希望后续有知道的小伙伴可以交流)),但是如果将字符串类数据转化为整数,那么是一定可以的!
由于该项目就是字串类的数据,所以需要将标签转化为整数。
%% 初始化目标矩阵和标签
max_length = 10;
for i = 1:length(udd_all)
series = udd_all{i};
if length(series) > max_length
max_length = length(series);
end
end
Matrix = zeros(length(udd_all),max_length);
Label = zeros(length(udd_all),1);
%% 将标签从字符串转化为数字
names = {};
total = 1;
for i = 1:length(name)
if ismember(name{i},names) == false
names{total} = name{i};
total = total + 1;
end
end
for i = 1:length(name)
[bool,inx] = ismember(name{i},names);
Label(i) = inx;
end
(MATLAB中不好的代码习惯:使用length来代替size来获取数组长度,length是获取长宽中的大者,所以在使用length的时候一定要注意小心!)
3. 面对cell中每一条数据长度不一致该如何处理
我们先来看一下udd_all中的数据样子
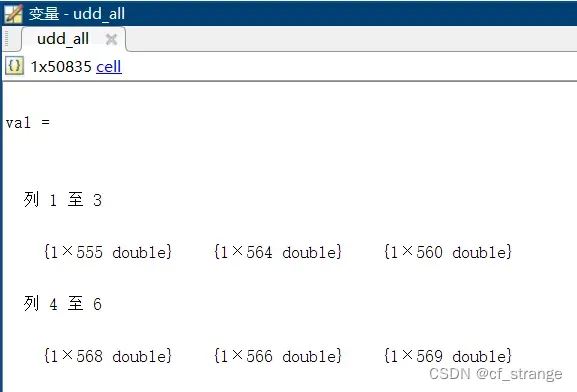
我们会发现,udd_all中的数据每一条长度都是不一样的,这该怎么处理呢?
😔!
这是一个令我非常头疼的事情,我也像把这个任务抛出来,大家和我一起思考。
我目前思考了两个方案,实践了一个方案。
方案1
补零! 虽然我说不出来为什么要使用补零,emmm,但是我导师说,遇到这种case,采用补零往往是可以的。
所以,有无小伙伴知道为什么可以直接补零希望可以不啬赐教,或者直接补零不可以,也是希望大家可以探讨的。
方案2
这是我自己像的一个方案(有一点想象的空间)。
采用插值填补数据,将数据长度填充到一样长。
但是这个方案,会遇到很多阻力,比如 在哪个位置增加数据,我觉着这是最难的一个问题,其他都好说!
所以,对于这个问题,我采用的方案是简单粗暴的补零大法。
(这个模块希望有了解的小伙伴可以提供一点建设性的意见)
%% 填充矩阵
for i = 1:length(udd_all)
series = udd_all{i};
label = name{i};
Matrix(i,1:length(series)) = series;
end
% 暂时完成数据集 特征部分的构建
最原始的数据集已经搭建好了。
但是这种状态下的数据集还是无法使用在 实战中,因为他还不符合挑剔的标准。
- 划分训练集和验证集
MATLAB的deep learning app确实在可视化编程上做的不错,但是对于时序序列想用CNN去做就不是那么友好。虽然deep learning app做到了划分数据集的功能,但是结果它本身没有提供划分数据集功能的函数,好在实现起来也不难。
%% 数据集分割
% 该数据集的主体部分是Matrix 和 Label
% 现在划分训练集和验证集
train_ratio = 0.7;
[height,width] = size(Matrix);
train_num = round(train_ratio*height);
rand_series = randperm(height);
train_series = rand_series(1:train_num);
val_series = rand_series(train_num+1:end);
Xtrain = Matrix(train_series,:);
ytrain = Label(train_series);
yTr = categorical(ytrain);
Xval = Matrix(val_series,:);
yval = Label(val_series);
yVal = categorical(yval);
想必你已经发现了一个细节的地方,对于yTr和yVal,我都做了一个categorical的操作。
这就是MATLAB数据集要求的地方,对于标签,一定要是标签(categorical)这种数据类型。同时注意这里是n*1,n行1列。对于矩阵该转置的时候就要转置。
- 元胞化X
先上代码
%% 元胞化
XTr = cell(length(Xtrain),1);
for i = 1:length(Xtrain)
XTr{i} = Xtrain(i,:);
end
XVal = cell(length(Xval),1);
for i = 1:length(Xval)
XVal{i} = Xval(i,:);
end
这也是MATLAB数据集的要求,它要求 必须和标签中的行列一致,所以就需要用cell将其进行打包。
所以在这里我也萌生了 你说要求是这个样子,那我可不可以做的元胞长度不一样呢?
这个问题的答案,我暂时也不知晓,不过我最近会做一下这个试验,来确定这件事情。
以上4,5两点中其实就反映了MATLAB对于数据集的挑剔点,虽然不难,但是不了解的话,蛮搞心态的。
6. 最后一步,table登场
%% 构成表格
Train = table(XTr,yTr);
Val = table(XVal,yVal);
至此,我们就顺利的完成了数据集的构建!(当然一些数据分析工作,可能在科研过程中也会添加进去,而且会很重要)
总结
MATLAB构建数据集最重要的两点就是:
- 标签标签化
- 数据元胞化
这算是对于我多次失败的精炼总结。同时在该篇文章中,我留下了一些问题,希望有小伙伴可以发表自己的建议。希望大家会觉着这篇文章有用,同时我会继续更新本栏目。
继续加油!
文章出处登录后可见!