AI作画——使用stable-diffusion生成图片
- 0. 简介
- 1. 注册并登录huggingface
- 2. 下载模型
- 3. 生成
0. 简介
自从DallE问世以来,AI绘画越来越收到关注,从最初只能画出某些特征,到越来越逼近真实图片,并且可以利用prompt来指导生成图片的风格。
前不久,stable-diffusion的v1-4版本终于开源,本文主要面向不熟悉huggingface的同学,介绍一下stable-diffusion如何使用(非常简单)。
1. 注册并登录huggingface
直接打开compvis的stable-diffusion:
https://huggingface.co/CompVis/stable-diffusion-v1-4
然后,去找它的模型,想给它下载下来,但是进入下载界面,会显示404。没关系,如果没注册过huggingface,需要先注册一个账号,一分钟搞定。
然后回到model card,有一个用户协议,点击接受:
2. 下载模型
在切回模型文件,发现就可以下载了:
点击每个文件后边的小箭头,就可以下载了,把所有下载的文件扔到一个文件夹里,你可以把这个文件夹命名为stable_diffusion,注意里边的这些文件夹的名称也要与项目里保持一致。
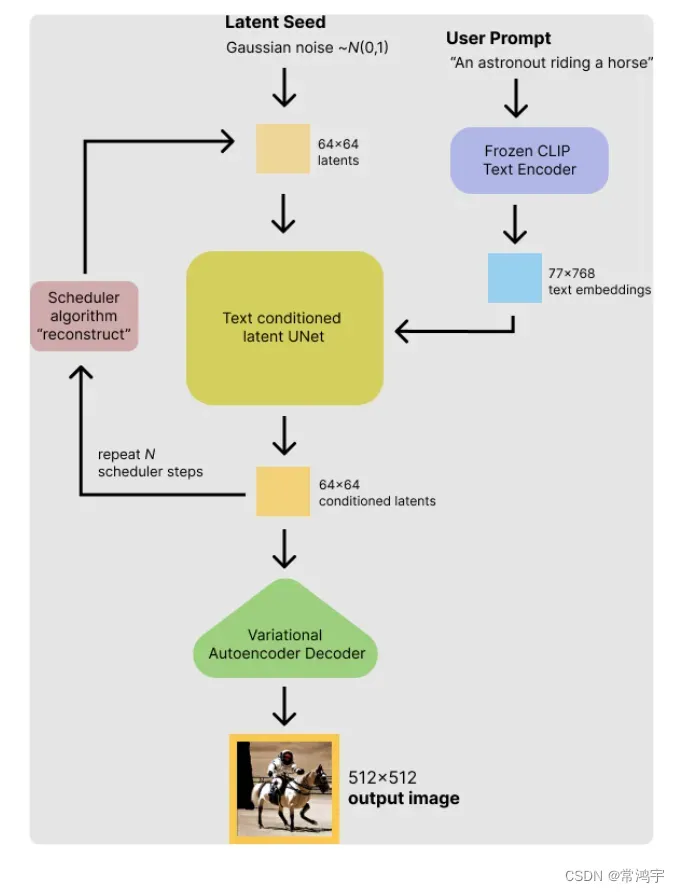
其实在这里我们也可以大概看到整个模型的基本结构:
- 一个自编码器VAE:用于重构模型(所以在使用的时候只调用了它的解码器);
- 一个U型网络;
- 一个Clip:用于对输入的文本进行编码;
- 还有一个safty checker暂时不太清楚是做什么用的。
官方文档里对模型结构的整体介绍如下:
由于模型我目前也不是很熟,就不多介绍了,怕讲错了。直接进入下一个环节,生成。
3. 生成
首先安装一下环境依赖:
pip install transformers
pip install diffusers
在配置好环境之后,模型的调用非常方便:
import torch
from diffusers import StableDiffusionPipeline
然后建立模型,这里的模型路径可以选择之前下载的所有文件存放的路径。
pipe = StableDiffusionPipeline.from_pretrained('xxxxxx/huggingface/stable-diffusion-v1-4', use_auth_token=True)
# cpu会很慢所以最好在GPU上运行,大概需要10G显存
pipe.to('cuda:0')
输入一句话,直接调用这个类,就可以生成了,生成的图片是PIL格式,可以直接保存。
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt, guidance_scale=7.5)["sample"][0]
image.save("test_1.png")

然后看一下这个类调用方法可以传入的参数都有什么:
help(pipe.__call__)
# __call__(prompt: Union[str, List[str]], height: Union[int, NoneType] = 512, width: Union[int, NoneType] = 512, num_inference_steps: Union[int, NoneType] = 50, guidance_scale: Union[float, NoneType] = 7.5, eta: Union[float, NoneType] = 0.0, generator: Union[torch._C.Generator, NoneType] = None, output_type: Union[str, NoneType] = 'pil', **kwargs)
查看官方文档可知:
| 参数 | 含义 | 默认值 |
|---|---|---|
| height | 生成图片的高度 | 512 |
| width | 生成图片的宽度 | 512 |
| num_inference_steps | 预测步数 | 50 |
| guidance_scale | 指导度 | 7.5 |
| generator | 生成器 | None |
| output_type | 输出的类型 | pil |
其中,预测的步数,一般来说步数越大,图片效果越好,但是耗时就越长(调用的时候那个tqdm条就是步数);
guidance_scale,用来控制生成的一个参数,暂时不太了解,官方说设置为7.5-8效果最好。感兴趣的话可以参考:https://arxiv.org/abs/2207.12598
关于生成器参数,主要可以用来生成VAE模型的初始潜在噪声,由于VAE的初始化是采样出来的,具有随机性,所以如果想确保生成的图片一样的话,可以设置seed:
import torch
generator = torch.Generator("cuda").manual_seed(1024)
image = pipe(prompt, generator=generator)["sample"][0]
本文就先介绍到这里,后续如果有更多好玩的text-to-image模型,可能会继续介绍。
文章出处登录后可见!