Transformer原文解读与细节复现
导读
在Transformer出现以前,深度学习的基础主流模型可分为卷积神经网络CNN、循环神经网络RNN、图对抗神经网络GAN。而Transformer的横空出世,吸引了越来越多的研究者的关注:Transformer不仅在NLP领域取得了耀眼的成绩,近年来甚至一度屠榜CV领域的各大比赛,热度超前。所以,基于之前对Transformer的研究与理解,更基于对新技术的好奇与渴求,接下来的几篇文章我会从最经典的Transformer结构出发,沿着NLP和CV两大主线,为大家讲解几篇影响力巨大的paper。
前言
Transformer是google的研究团队在2017年发表的Attention Is All You Need中使用的模型,经过这些年的大量的工业使用和论文验证,在深度学习领域已经占据重要地位。接下来我会顺着论文中的逻辑,来介绍、解释Transformer的输入输出和网络结构。
原文链接:Attention Is All You Need
Abstract
现在主流的序列转录模型主要基于是复杂的循环结构的RNN和CNN架构,通过其中的编码器Encoder和解码器Decoder来实现。而本文提出的Transformer完全摒弃了之前的循环和卷积操作,完全基于注意力机制,拥有更强的并行能力,训练效率也得到较高提升。
Intro
之前提到过,在Transformer提出以前,主流的NLP模型包括RNN、LSTM、GRU等,这些模型是有以下缺点:
- 难以并行
- 时序中过早的信息容易被丢弃
- 内存开销大
主要原因如下:由于这些网络都是由前往后一步步计算的,当前的状态不仅依赖当前的输入,也依赖于前一个状态的输出。即对于网络中的第个t状态,与前t-1个状态都有关,使得网络必须一步一步计算;当较为重要的信息在较早的时序中进入网络时,多次传播过程中可能保留很少甚至被丢弃;从另一角度来考虑,即使重要的信息没有被丢弃,而是随着网络继续传递,那么势必会造成内存的冗余,导致开销过大。 其网络流程图如下图所示。
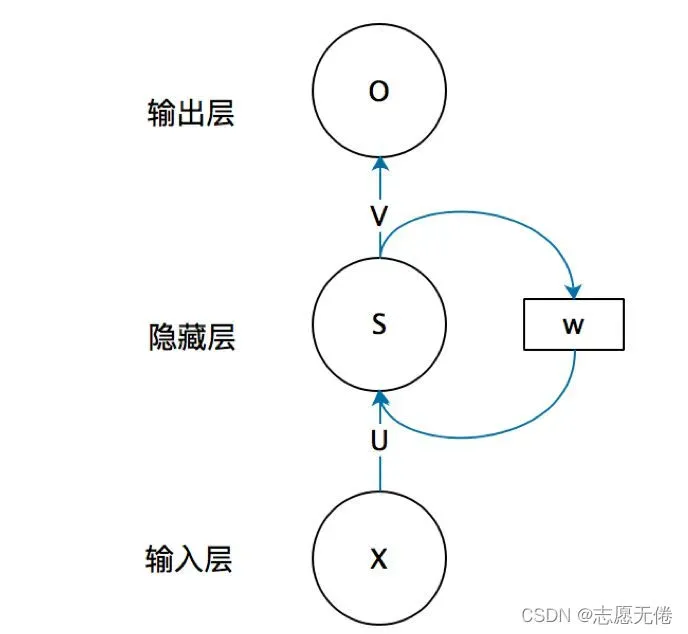
所以,作者团队因势利导,引出了本文纯attention、高并行、高效率的Transformer网络结构。原文中是这样说的:
In this work we propose the Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output.
Related Work
multi-head
在CNN中,我们会使用多个channel来表达不同的特征模式,Transformer的多头注意力与多通道有相类似的地方,就是通过不同的head抽取数据的不同特征模式。
self-attention
自注意,或者说内部注意,是一种将单个序列的不同位置联系起来以计算序列的表示形式的注意机制。自注意力机制在阅读理解、抽象摘要、文本蕴涵和学习任务独立的句子表征等任务中都得到了成功的应用,具体的内部细节在后续章节中介绍。
Model
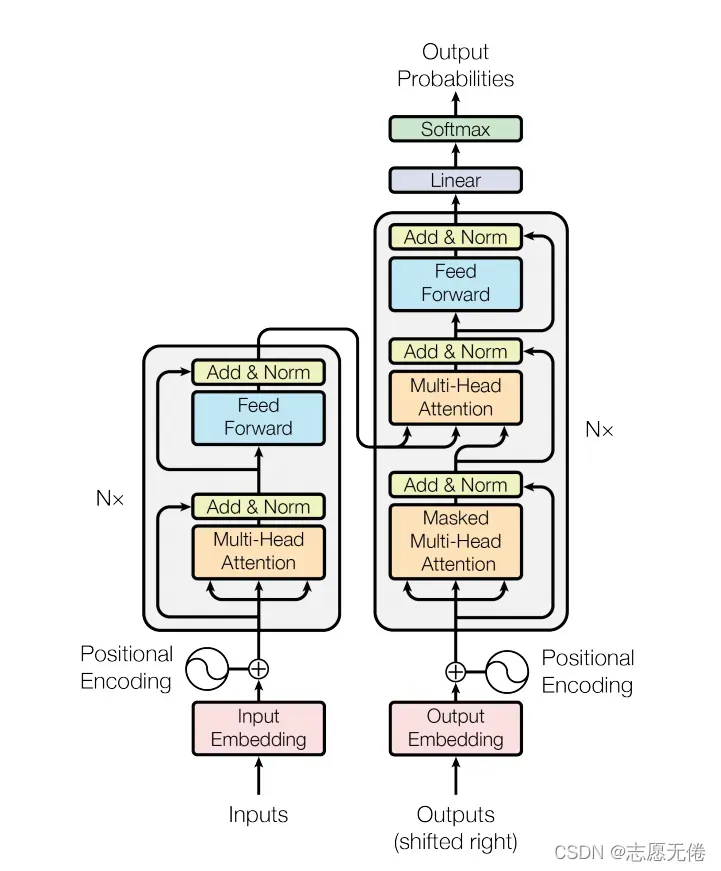
Transformer的模型分为encoder和decoder两部分,即编码器和解码器两部分。对于原始输入(x1,x2,…,xn),编码器将其转化为机器可理解的向量(z1,z2,…,zn),解码器将编码器的输出作为输入,进而生成最终的解码结果(y1,y2,…,yn)。其模型结构如下图所示:
输入
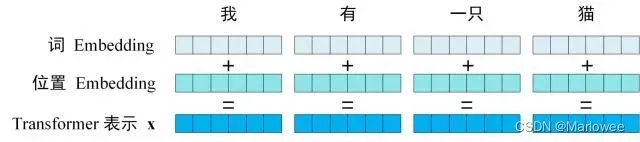
首先,我们来看看编码器与解码器的输入部分。
Transformer 中单词的输入表示 x由单词 Embedding 和位置 Embedding (Positional Encoding) 相加得到。其中,单词的 Embedding 有很多种方式可以获取,例如可以采用 Word2Vec、Glove 等算法预训练得到,也可以在 Transformer 中训练得到;位置 Embedding 表示单词出现在句子中的位置,因为 Transformer 不采用 RNN 的结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于 NLP 来说非常重要。所以 Transformer 中使用位置 Embedding 保存单词在序列中的相对或绝对位置。位置 Embedding 用 PE表示,PE 的维度与单词 Embedding 是一样的。PE 可以通过训练得到,也可以使用某种公式计算得到。在 Transformer 中采用了后者,计算公式如下:
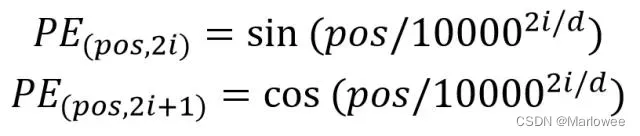
其中,pos 表示单词在句子中的位置,d 表示 PE的维度 (与词 Embedding 一样),2i 表示偶数的维度,2i+1 表示奇数维度 (即 2i≤d, 2i+1≤d)。使用这种公式计算 PE 有以下的好处:
- 使 PE 能够适应比训练集里面所有句子更长的句子,假设训练集里面最长的句子是有 20 个单词,突然来了一个长度为 21 的句子,则使用公式计算的方法可以计算出第 21 位的 Embedding。
- 可以让模型容易地计算出相对位置,对于固定长度的间距 k,PE(pos+k) 可以用 PE(pos) 计算得到。因为 Sin(A+B) = Sin(A)Cos(B) + Cos(A)Sin(B), Cos(A+B) = Cos(A)Cos(B) – Sin(A)Sin(B)。
Multi-attention(self attention)
结构
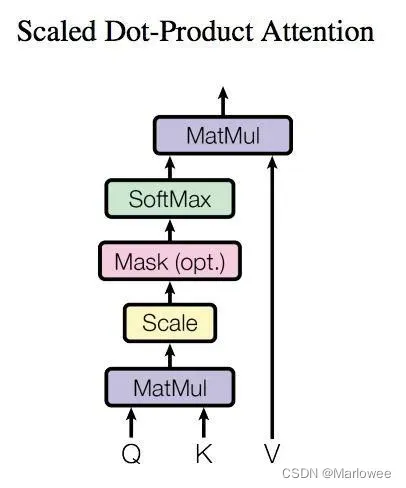
上图是 Self-Attention 的结构,在计算的时候需要用到矩阵Q(查询),K(键值),V(值)。在实际中,Self-Attention 接收的是输入(单词的表示向量x组成的矩阵X) 或者上一个 Encoder block 的输出。而Q,K,V正是通过 Self-Attention 的输入进行线性变换得到的。
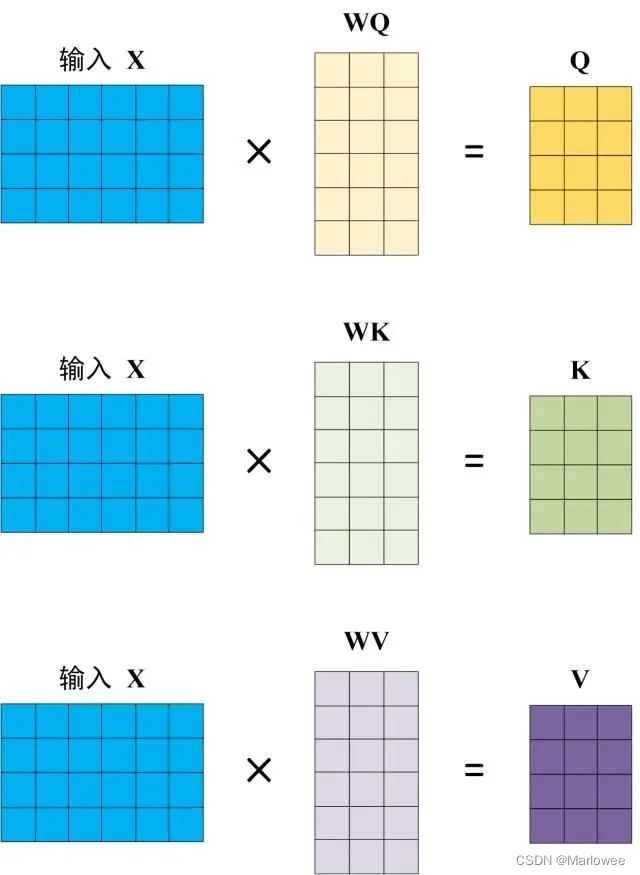
Q, K, V 的计算
Self-Attention 的输入用矩阵X进行表示,则可以使用线性变阵矩阵WQ,WK,WV计算得到Q,K,V。计算如下图所示,注意 X, Q, K, V 的每一行都表示一个单词。
Self-Attention 的输出
得到矩阵 Q, K, V之后就可以计算出 Self-Attention 的输出了,计算的公式如下:

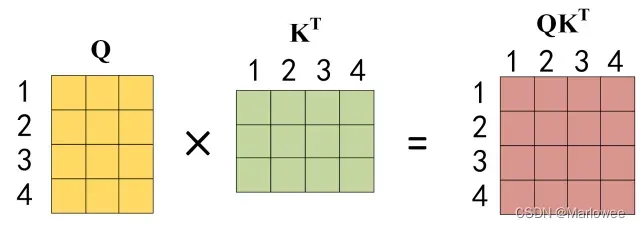
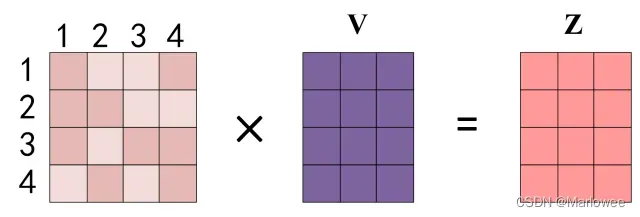
公式中计算矩阵Q和K每一行向量的内积,为了防止内积过大,因此除以 dk的平方根。Q乘以K的转置后,得到的矩阵行列数都为 n,n 为句子单词数,这个矩阵可以表示单词之间的 attention 强度。下图为Q乘以 KT ,1234 表示的是句子中的单词。
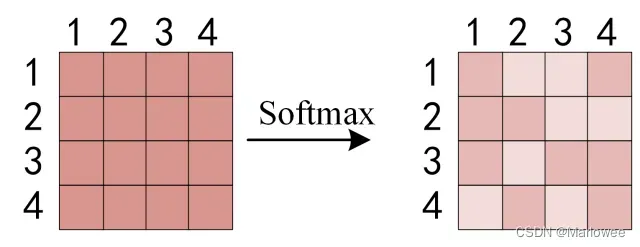
得到[公式] 之后,使用 Softmax 计算每一个单词对于其他单词的 attention 系数,公式中的 Softmax 是对矩阵的每一行进行 Softmax,即每一行的和都变为 1.
得到 Softmax 矩阵之后可以和V相乘,得到最终的输出Z。
Multi-Head Attention
在上一步,我们已经知道怎么通过 Self-Attention 计算得到输出矩阵 Z,而 Multi-Head Attention 是由多个 Self-Attention 组合形成的,下图是论文中 Multi-Head Attention 的结构图。
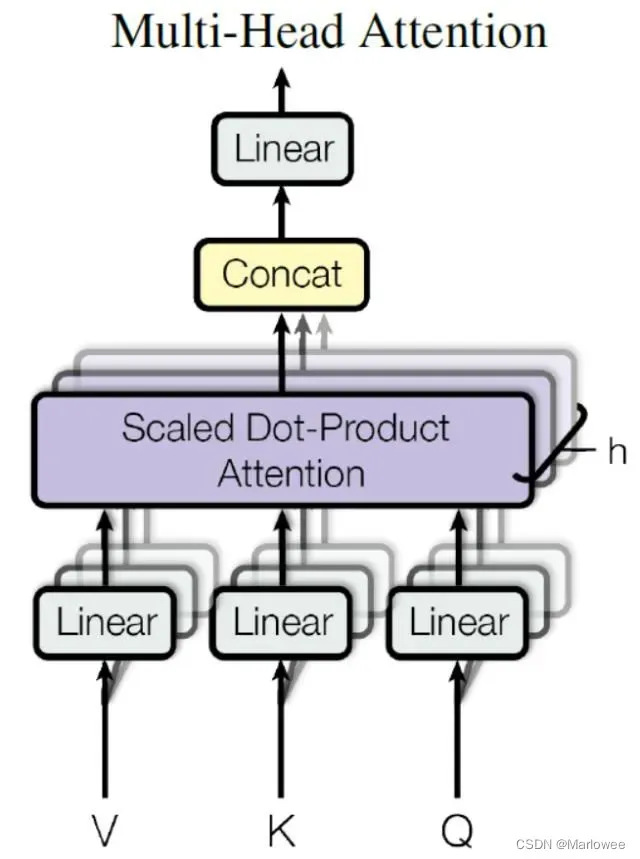
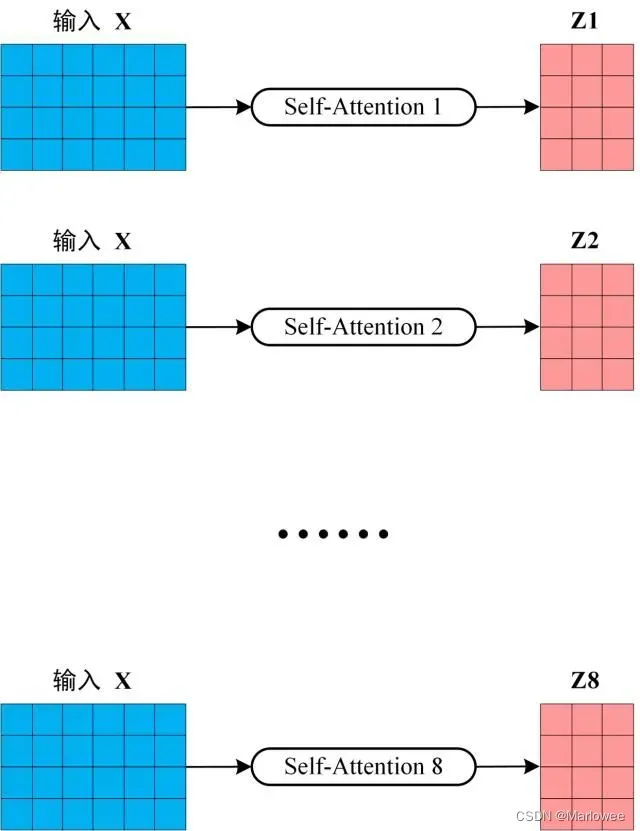
从上图可以看到 Multi-Head Attention 包含多个 Self-Attention 层,首先将输入X分别传递到 h 个不同的 Self-Attention 中,计算得到 h 个输出矩阵Z。下图是 h=8 时候的情况,此时会得到 8 个输出矩阵Z。
文章出处登录后可见!