Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
video-to-video
修改文本内容,生成新的视频。

Abstract
由于T2I的成功,近日T2V的方法在大量的T2I的数据集中加入fine-turning.我们试图给出一个One-Shot Video Generation。
1、产生图像与动词对齐。
2、扩展文本到图像的模型,同时生产多张图片。
作者提出Turn a video的方法,高效的fine-turn翻译成2D的扩散模型,通过文本生成视频。改变元素、背景或者风格的转换。
Introduction

让模型具有One-Shot的能力。
原模型:缺乏连贯性,动作、背景不连贯。不符合对视频生成的要求。
新模型:增加了Self-Attention(由空间相似性驱动,而不是像素的位置),增加了连贯性,主体一致性
预训练文本-视频,由3×3扩展到1×3×3
具有结构相似性。
寄存量呈平方式增加(过大),
提出Sparse-Causal Attention(SC-Attn)
对于因果Attentiion的变形,稀疏版本。
该方法可以回归生成任意长度的视频帧。
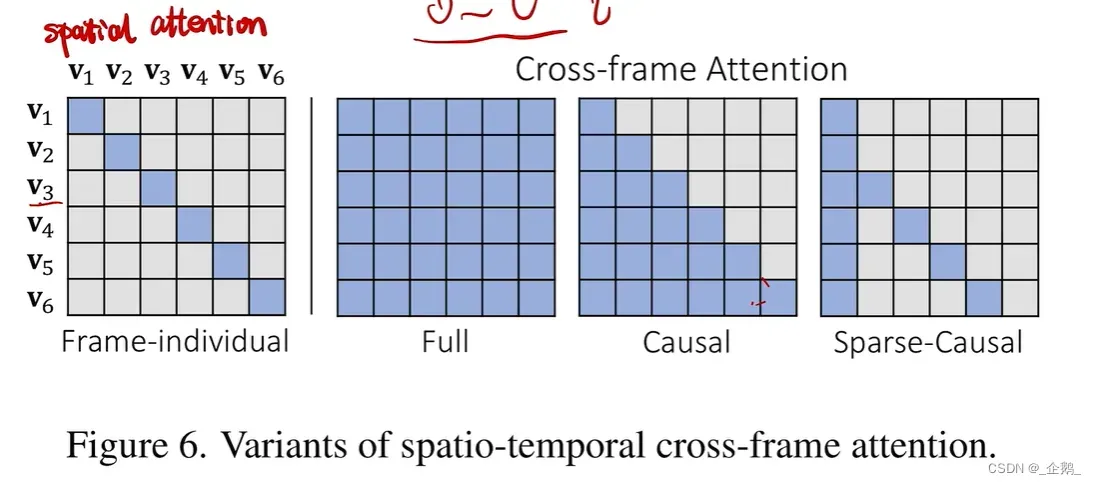
Sparse-Causal是Causal的稀疏版
上:膨胀成文本到视频
下:新的文本,生成对应视频(动作不变)
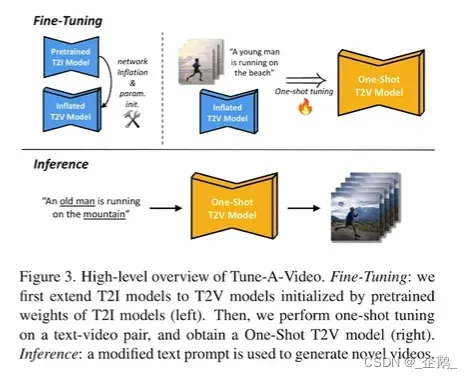
pipeline
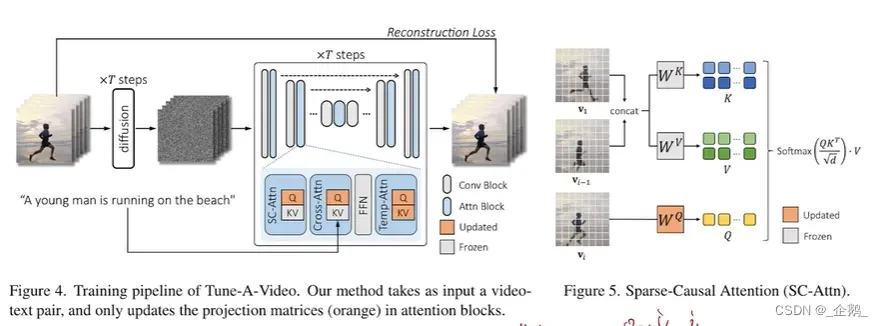 diffusion U-NET模型,下方attention模型,修改为Sparse-Causal Attention。
diffusion U-NET模型,下方attention模型,修改为Sparse-Causal Attention。
concat
投影到矩阵。
Method
Diffusion Models
Latent Diffusion Model
One-shot Video Generation
生成相同语义信息。
无法生成连续的动作
动作词语需要一致
Our Tune-A-Video
“膨胀”
2D的convolution
3×3
1×3×3(frame层转移到batch,依然是2D)
attention block
①a spatial self-attention
②a cross attention
One-Shot Turning
![]()
KEY和VALUE由前一帧推断出
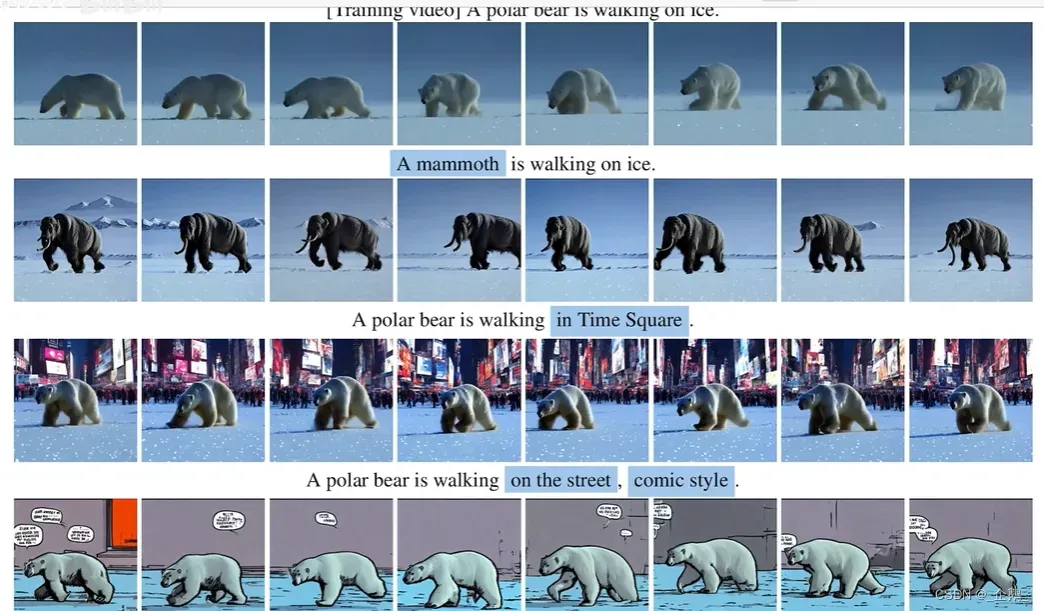
应用场景:元素修改,背景替换,风格迁移
Experiment
消融实验

文章出处登录后可见!
已经登录?立即刷新