

目的:
对原始数据的商品金额进行区间划分,统计各个区间的订单数
解决思路:
分箱使用pd.cut()
pd.cut(x,bins,right=True,labels=None,retbins=False,precision=3,include_lowest=False,duplicates=’raise’)
x : 一维数组
bins :整数,标量序列或者间隔索引,是进行分组的依据,
如果填入整数n,则表示将x中的数值分成等宽的n份(即每一组内的最大值与最小值之差约相等);
如果是标量序列,序列中的数值表示用来分档的分界值
如果是间隔索引,“ bins”的间隔索引必须不重叠
right :布尔值,默认为True表示包含最右侧的数值
当“ right = True”(默认值)时,则“ bins”=[1、2、3、4]表示(1,2],(2,3],(3,4]
当bins是一个间隔索引时,该参数被忽略。
labels : 数组或布尔值,可选.指定分箱的标签
如果是数组,长度要与分箱个数一致,比如“ bins”=[1、2、3、4]表示(1,2],(2,3],(3,4]一共3个区间,则labels的长度也就是标签的个数也要是3
如果为False,则仅返回分箱的整数指示符,即x中的数据在第几个箱子里
当bins是间隔索引时,将忽略此参数
retbins: 是否显示分箱的分界值。默认为False,当bins取整数时可以设置retbins=True以显示分界值,得到划分后的区间
precision:整数,默认3,存储和显示分箱标签的精度。
include_lowest:布尔值,表示区间的左边是开还是闭,默认为false,也就是不包含区间左边。
duplicates:如果分箱临界值不唯一,则引发ValueError或丢弃非唯一
可视化统计,使用pd.pivot_table()
具体代码:
1、获取数据
df = pd.read_excel('新建 XLSX 工作表.xlsx',sheet_name= 'Sheet1') #读取数据进入Python程序
data = df[['订单号','付款时间','订单金额','商品名称','产品规格','商品数量','商品金额']] # 选择需用用到的数据列
print(data.head()) # 打印数据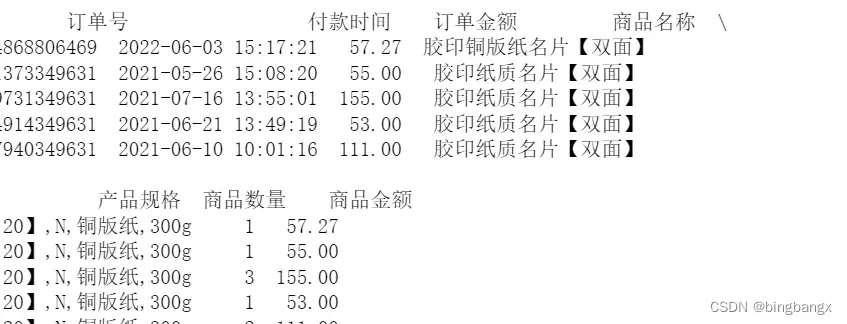

2、分箱处理
# 定义金额区间
je_cut =[0,10,50,100,150,200,500,100000]
je_label = ['0-10','10-50','50-100','100-150','150-200','200-500','500以上'] #给金额区间设置标签
data['金额区间'] = pd.cut(data['商品金额'],bins=je_cut,labels= je_label)
print(data)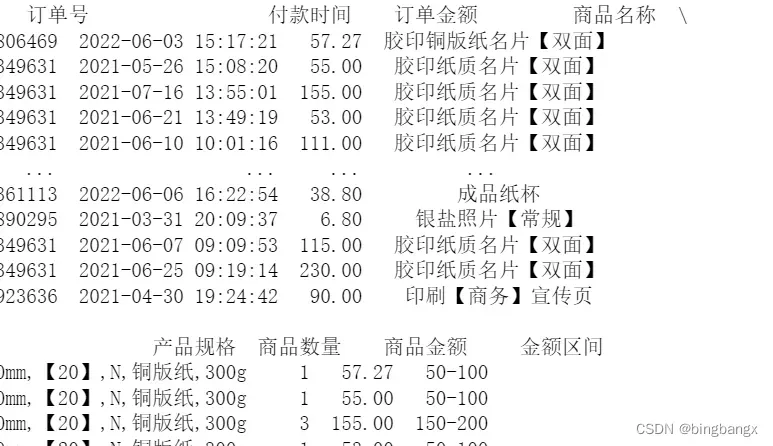

3、统计分析
Data = pd.pivot_table(data,values = ['订单号'],index = ['金额区间'],aggfunc = {'订单号':lambda x: len(x.dropna().unique())}
,fill_value =0).reset_index(drop = False) # fill_value = 0是用来填充缺失值、空值
Data = Data.rename(columns ={'订单号':'订单数'}) # 修改列名
print(Data)

至此,我们已经完成了数据的分箱统计需求~~~~~~
文章出处登录后可见!