

目录
注:如果您需要本文的数据集,请私信我的csdn账户
一.一元线性回归
1.1 引子
现有数据:(1,3),(3,5),(4,7),(5,8),请根据这4个坐标求出y与x的函数关系。
废话不多说,我们直接开整:
1.绘制散点图
import matplotlib.pyplot as plt
X = [[1], [3], [4], [5]]
Y = [3, 5, 7, 8]
plt.scatter(X, Y)
plt.show()

2.搭建模型并预测(预测3个自变量对应的因变量)
from sklearn.linear_model import LinearRegression
regr = LinearRegression()
regr.fit(X,Y)
y = regr.predict([[2], [2.3], [5.2]]) #3个自变量
print(y)得到的结果:
| 4.14285714 | 4.52857143 | 8.25714286 |
3.模型可视化
plt.scatter(X, Y)
plt.plot(X, regr.predict(X))
plt.show()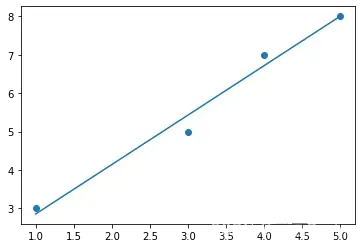
4.线性回归方程:y = ax+b
print('a:' + str(regr.coef_[0]))
print('b:' + str(regr.intercept_))得到的回归方程:y = 1.29x+1.57
1.2 求解系数a和截距b的方法:最小二乘法
假设线性回归模型的拟合方程为y = ax+b。为了衡量实际值与预测值的接近程度,我们使用残差平方和(两者差值的平方和)进行衡量。


拟合的目的是为了让残差平方和尽可能地小,则应对残差平方和进行求导(对a和b分别进行求导),导数为0时,该残差平方和取得极值。
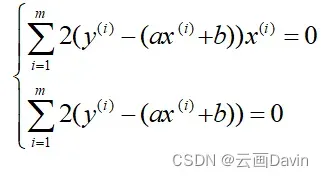

将所有(x,y)的代入上式即可求得a和b的值。
1.3 案例解决
现有某公司员工收入情况的数据(某公司员工收入.xlsx),自变量为工作时间,因变量为年收入,根据数据求出一元线性回归方程。
1.绘制散点图
import pandas as pd
from matplotlib import pyplot as plt
df = pd.read_excel('某公司员工收入.xlsx')
df.head()
X = df[['工作时间']]
Y = df['年收入']
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.scatter(X,Y)
plt.xlabel('工作时间')
plt.ylabel('年收入')
plt.show()

2.模型搭建
from sklearn.linear_model import LinearRegression
regr = LinearRegression()
regr.fit(X,Y)3.模型可视化
plt.scatter(X,Y)
plt.plot(X, regr.predict(X), color='red') # color='red'设置为红色
plt.xlabel('工作时间')
plt.ylabel('年收入')
plt.show()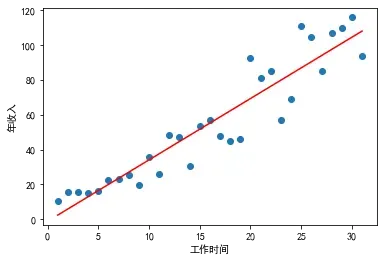

4.求出a与b的值
print('a:' + str(regr.coef_[0]))
print('b:' + str(regr.intercept_))得到结果:y = 3.5202x-1.1071
1.4 模型检验
以下主要从两方面来检验模型的好坏:R-squared(R方)、Adj.R-squared(Adjusted R方)。R-squared、Adj.R-squared的取值范围为[0,1],它们的值越接近1,说明模型的拟合程度越高。
import statsmodels.api as sm
X2 = sm.add_constant(X)
est = sm.OLS(Y,X2).fit()
print(est.summary())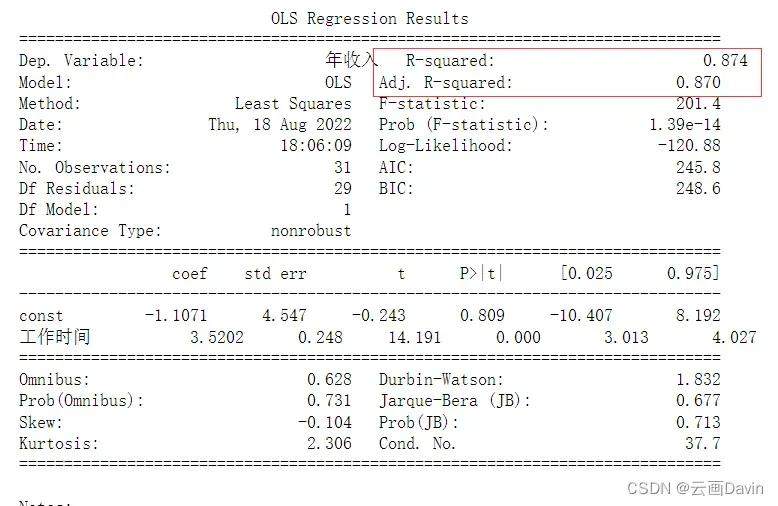

由图可知,R-squared、Adj.R-squared的值分别为0.874、0.870,说明模型拟合程度较高。
完整代码
#读取数据
import pandas as pd
from matplotlib import pyplot as plt
df = pd.read_excel('某公司员工收入.xlsx')
df.head()
X = df[['工作时间']]
Y = df['年收入']
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.scatter(X,Y)
plt.xlabel('工作时间')
plt.ylabel('年收入')
plt.show()
#模型搭建
from sklearn.linear_model import LinearRegression
regr = LinearRegression()
regr.fit(X,Y)
#模型可视化
plt.scatter(X,Y)
plt.plot(X, regr.predict(X), color='red') # color='red'设置为红色
plt.xlabel('工作时间')
plt.ylabel('年收入')
plt.show()
#结果
print('系数a为:' + str(regr.coef_[0]))
print('截距b为:' + str(regr.intercept_))
#模型检验
import statsmodels.api as sm
X2 = sm.add_constant(X)
est = sm.OLS(Y,X2).fit()
print(est.summary())二.多元线性回归
2.1 式子
多元线性回归模型的表示方式:y = k0 + k1*x1 + k2*x2 + … +kn*xn。其中,x1、x2、x3…为不同的特征变量,k1、k2、k3…为系数,k0为常数项。
2.2 核心代码
多元线性回归模型的核心代码与一元线性回归模型相同:
from sklearn.linear_model import LinearRegression
regr = LinearRegression()
regr.fit(X,Y)2.3 案例解决
已有数据集企业综合实力.xlsx,特征变量有4个,因变量为企业的综合实力,现通过该数据集求出多元线性回归模型。
1.读取数据
import pandas as pd
df = pd.read_excel('企业综合实力.xlsx')
df.head() # 显示前5行数据
X = df[['指标1', '指标2', '指标3', '指标4']]
Y = df['综合实力']2.模型搭建
from sklearn.linear_model import LinearRegression
regr = LinearRegression()
regr.fit(X,Y)3.方程构建
regr.coef_
print('各系数为:' + str(regr.coef_))
print('常数项系数k0为:' + str(regr.intercept_))4.模型检验
import statsmodels.api as sm # 引入线性回归模型评估相关库
X2 = sm.add_constant(X)
est = sm.OLS(Y, X2).fit()
est.summary()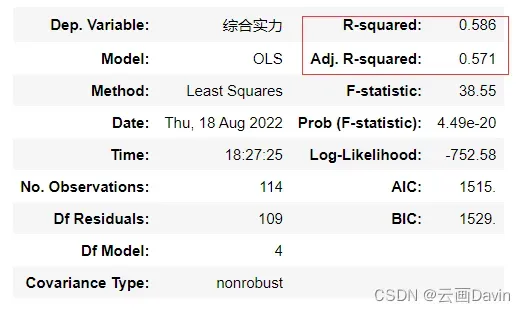

由检验结果知,R-squared、Adj.R-squared的值分别为0.586和0.571,拟合效果一般。
完整代码
#数据读取
import pandas as pd
df = pd.read_excel('企业综合实力.xlsx')
df.head() # 显示前5行数据
X = df[['指标1', '指标2', '指标3', '指标4']]
Y = df['综合实力']
#模型搭建
from sklearn.linear_model import LinearRegression
regr = LinearRegression()
regr.fit(X,Y)
#方程构建
regr.coef_
print('各系数为:' + str(regr.coef_))
print('常数项系数k0为:' + str(regr.intercept_))
#模型检验
import statsmodels.api as sm # 引入线性回归模型评估相关库
X2 = sm.add_constant(X)
est = sm.OLS(Y, X2).fit()
est.summary()文章出处登录后可见!