使用冻结图层进行迁移学习
本文介绍如何在迁移学习时冻结 YOLOv5 🚀 层。迁移学习是一种有用的方法,可以在新数据上快速重新训练模型,而无需重新训练整个网络。相反,部分初始权重被冻结在适当的位置,其余的权重用于计算损失并由优化程序更新。与正常训练相比,这需要更少的资源,并允许更快的训练时间,尽管它也可能导致最终训练的准确性降低
开始之前
克隆此存储库并安装要求.txt依赖项,包括 Python>=3.8 和 PyTorch>=1.7。
$ git clone https://github.com/ultralytics/yolov5 # clone repo
$ cd yolov5
$ pip install wandb -qr requirements.txt # install requirements.txt
冻结骨干网
在训练开始之前,通过将其梯度设置为零,将与 train.py 中的列表匹配的所有图层都将冻结。https://github.com/ultralytics/yolov5/blob/58f8ba771e3712b525ca93a1ee66bc2b2df2092f/train.py
#L83-L90freeze
查看模块名称列表:
for k, v in model.named_parameters():
print(k)
# Output
model.0.conv.conv.weight
model.0.conv.bn.weight
model.0.conv.bn.bias
model.1.conv.weight
model.1.bn.weight
model.1.bn.bias
model.2.cv1.conv.weight
model.2.cv1.bn.weight
...
model.23.m.0.cv2.bn.weight
model.23.m.0.cv2.bn.bias
model.24.m.0.weight
model.24.m.0.bias
model.24.m.1.weight
model.24.m.1.bias
model.24.m.2.weight
model.24.m.2.bias
查看模型体系结构,我们可以看到模型主干是第 0-9 层:
https://github.com/ultralytics/yolov5/blob/58f8ba771e3712b525ca93a1ee66bc2b2df2092f/models/yolov5s.yaml #L12-L48
因此,我们将冻结列表定义为包含名称中带有“model.0.” – “model.9.”的所有模块,然后我们开始训练。
freeze = ['model.%s.' % x for x in range(10)] # parameter names to freeze (full or partial)
冻结所有图层
为了冻结除检测()中最终输出卷积层之外的完整模型,我们将冻结列表设置为包含名称中带有“model.0.” – “model.23.”的所有模块,然后开始训练。
freeze = ['model.%s.' % x for x in range(24)] # parameter names to freeze (full or partial)
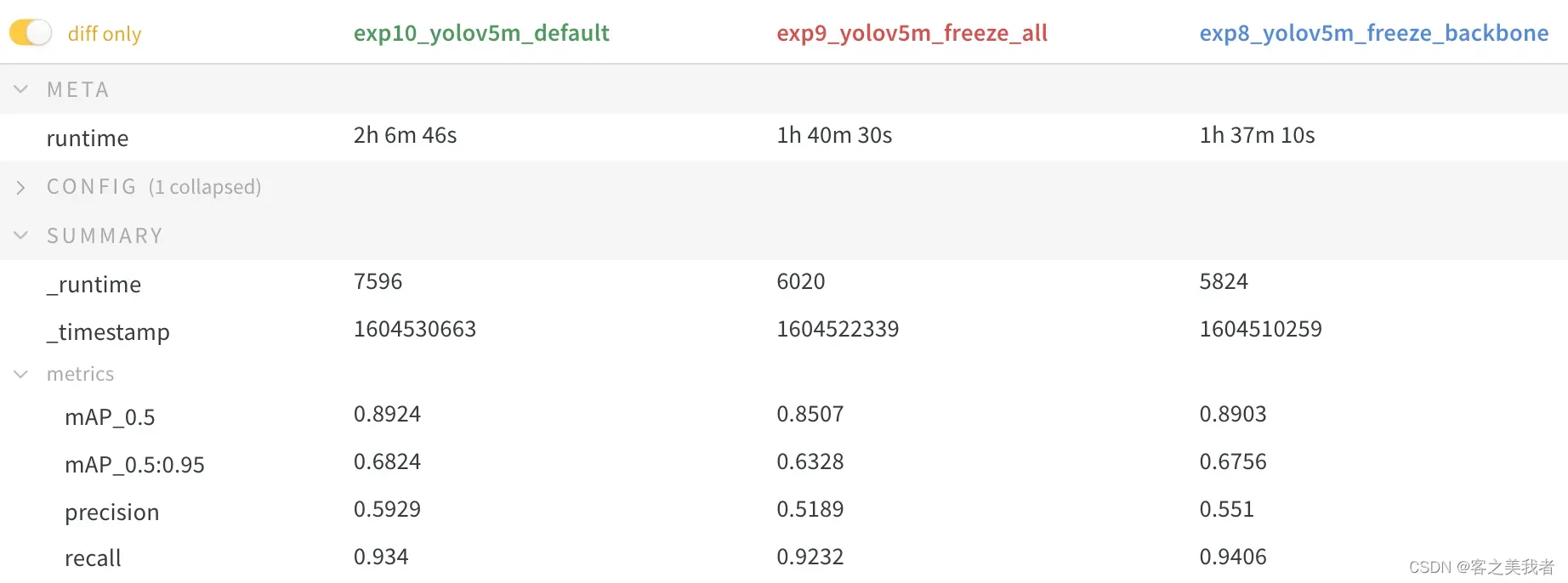
结果
我们在上述两种情况下都对VOC进行了YOLOv5m训练,以及默认模型(无冻结),从官方COCO预训练开始。所有运行的训练命令为:–weights yolov5m.pt
$ train.py --batch 48 --weights yolov5m.pt --data voc.yaml --epochs 50 --cache --img 512 --hyp hyp.finetune.yaml
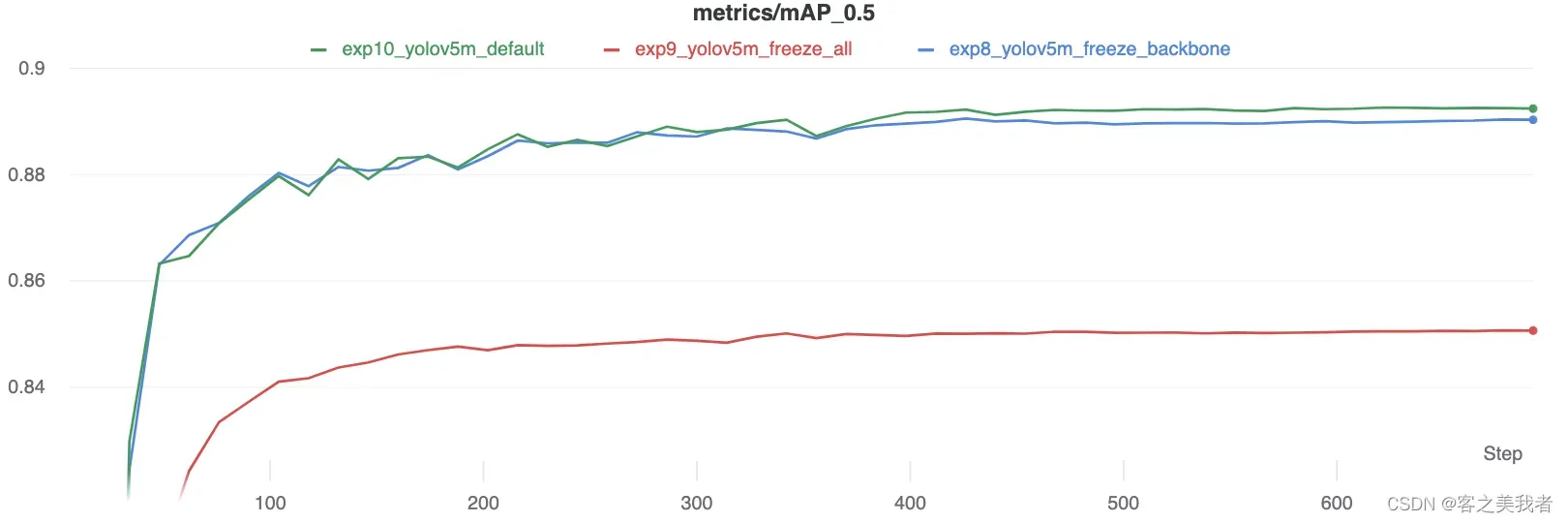
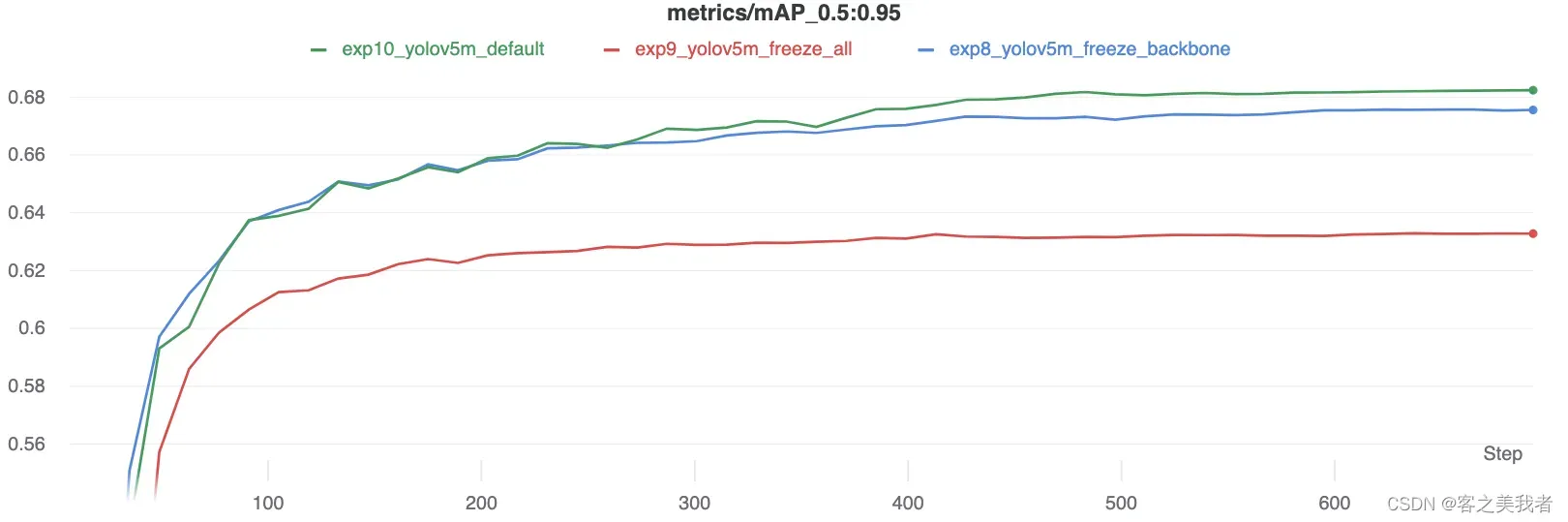
精度比较
结果表明,冻结可以加快训练速度,但会略微降低最终准确性。完整的W&B运行报告可以在此链接中找到:https://wandb.ai/glenn-jocher/yolov5_tutorial_freeze/reports/Freezing-Layers-in-YOLOv5–VmlldzozMDk3NTg
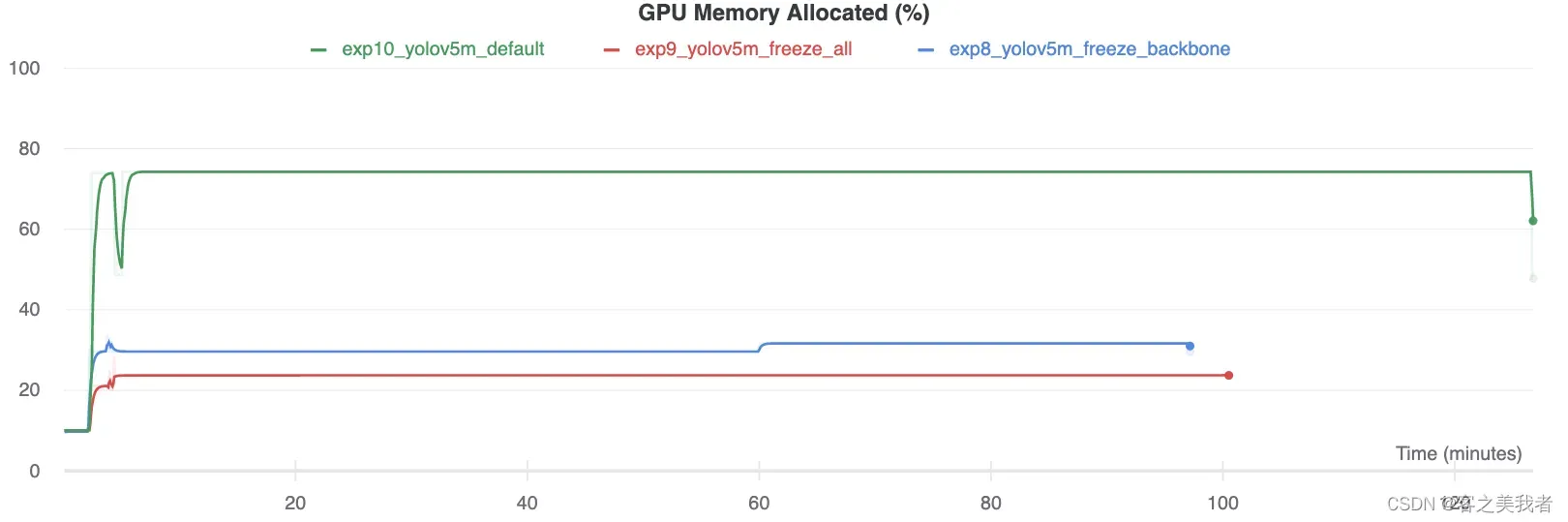
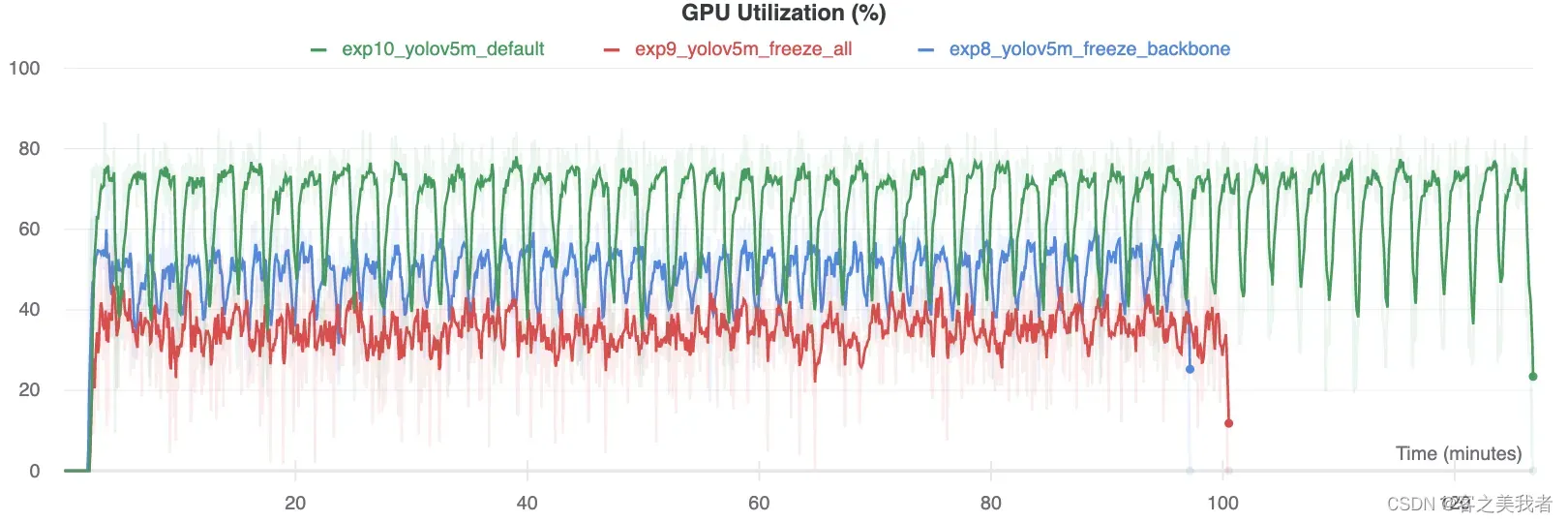
显卡利用率比较
有趣的是,冻结的模块越多,训练所需的GPU内存就越少,GPU利用率也就越低。这表明较大的模型或以较大的图像大小训练的模型可能会受益于冻结以更快地训练。
参考官网地址
文章出处登录后可见!