前段时间我刚自己完成了一个目标检测数据集的制作,得到voc格式的数据之后再转coco,在这里记录下我的一些经验,帮助大家更好地学习,少走弯路!!欢迎留言~ 欢迎点赞~阅读本博文将节约你n多多多时间!代码中含有较多注释,基本用法也在代码中写明,请注意看哦!
目录
- 1 从视频数据中获得图片数据(可选)
- 2 标注工具的使用:labelImg
- 3 使用数据增强扩充数据集(可选)
- 4 VOC格式转CoCo格式
- 4.1 检查所生成的xml文件
- 4.2 按比例划分数据集为训练集、验证集、测试集+voc2coco+自动移动图片到对应目录(一步到位!)
- 4.2.1 图片和xml文件批量重命名(可选)
- 4.2.2 数据集格式转换
- 5 常见问题(常用工具代码)
- 5.1 计算文件夹下的文件数量
- 5.2 去除voc格式的单身文件(只有图片没有xml或只有xml没有图片)
- 5.3 统计数据集内的标注数量
- 5.3.1 从xml文件中统计(VOC格式)
- 5.3.2 从json文件中统计(CoCo格式)
本篇博文所使用到的代码已经上传github https://github.com/little-spoon/voc2coco.git
1 从视频数据中获得图片数据(可选)
- 如果你的原始数据是视频,需要将视频处理成图片,可以使用
cut_fps.py:
import cv2
import os
'''
cut_fps.py
你可能需要修改的变量:
path: 视频路径
path_to_save: 截取图片保存的路径
frameRate: 帧数截取间隔
注意:
1. 修改路径请不要忘记添加最后一个/
2. 请不要把保存图片的文件夹放在视频所在文件夹下
3. 如果视频时长大于10分钟,代码可能失效,需要把长视频切成短视频后使用,可以使用接下来的cut_video.py
'''
path = "E:/myvideo/"
path_to_save = "E:/save/"
files = os.listdir(path)
cap = cv2.VideoCapture(path + files[0])
for i in range(len(files)):
files[i] = files[i][:-4] # 这是为了仅获得视频的名称,去掉.mp4
print("获取视频名称列表:", files)
c = 1
frameRate = 125 # 帧数截取间隔(每隔125帧截取一帧)
num_video = 0
while (True):
ret, frame = cap.read()
if ret:
if (c % frameRate == 0):
print("开始截取视频第:" + str(c) + " 帧")
cv2.imwrite(path_to_save + files[num_video] + "_" + str(c) + '.jpg', frame) # 这里是将截取的图像保存在path_to_save
c += 1
cv2.waitKey(0)
else:
print("第" + str(num_video + 1) + "个视频所有帧都已经保存完成")
if num_video == len(files) - 1:
break
else:
num_video += 1
next_file = path + files[num_video] + ".mp4"
cap = cv2.VideoCapture(next_file)
c = 1
cap.release()
效果如下:
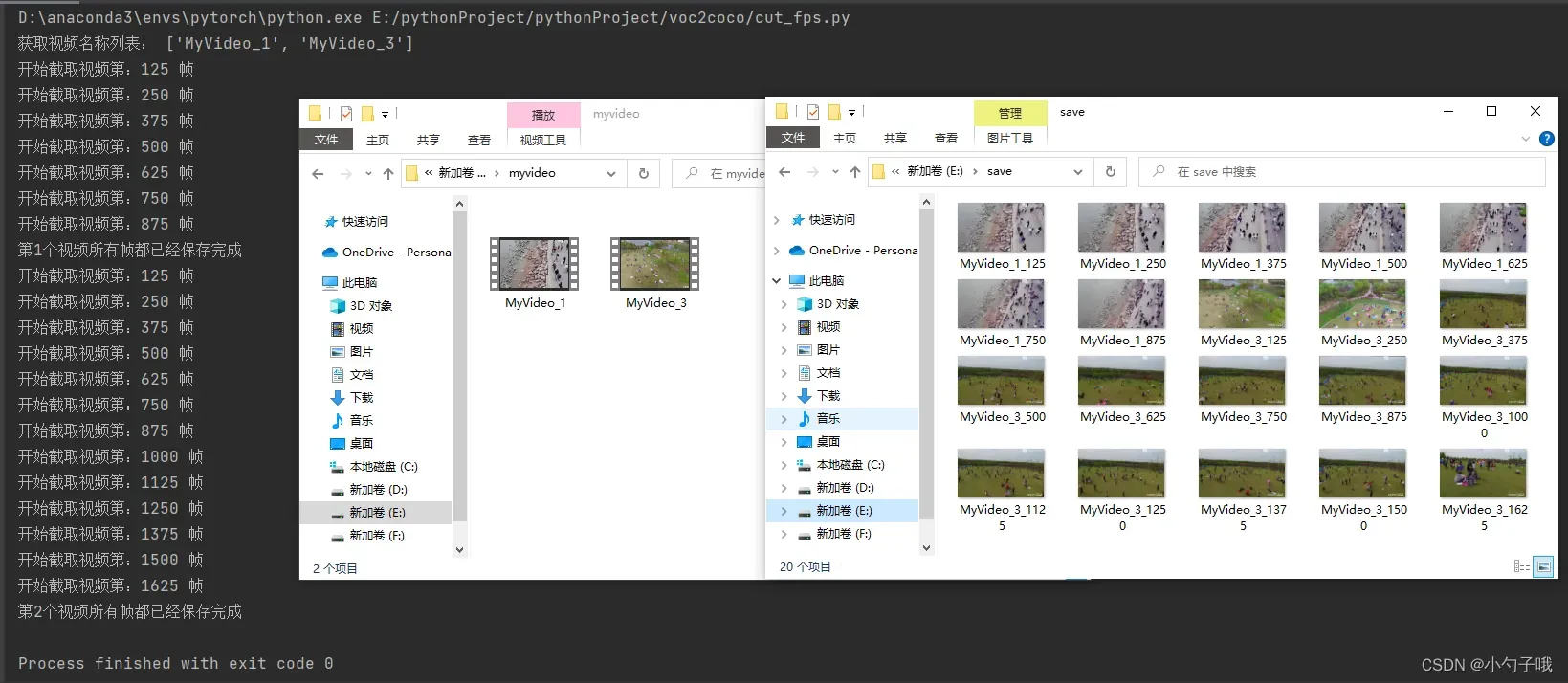
- 长视频切成短视频,你可以使用剪辑软件,或者
cut_video.py:
import numpy as np
import cv2
import os
import time
'''
cut_video.py
你需要修改的变量:
video: 视频路径
video_to_save: 截取图片保存前缀
size: 视频分辨率
MID_HOUR,MID_MIN,MID_SECOND: 从视频中间切割时间的 时 分 秒
END_HOUR,END_MIN,END_SECOND: 结束切割时间的 时 分 秒
注意:
1. 请不要把保存切割视频的文件夹放在原视频所在文件夹下
2. 由于可能每个视频的时长不一样,这份代码一次只能处理一个视频,如果需要批量处理,请参考cut_fps.py进行修改
'''
# 将视频切割成更小的视频
START_HOUR = 0
START_MIN = 0
START_SECOND = 0
START_TIME = START_HOUR * 3600 + START_MIN * 60 + START_SECOND # 设置开始时间(单位秒)
MID_HOUR = 0
MID_MIN = 0
MID_SECOND = 15
MID_TIME = MID_HOUR * 3600 + MID_MIN * 60 + MID_SECOND # 设置切割位置时间(单位秒)
END_HOUR = 0
END_MIN = 0
END_SECOND = 38
END_TIME = END_HOUR * 3600 + END_MIN * 60 + END_SECOND # 设置结束时间(单位秒)
video = "E:/myvideo/MyVideo_1.mp4"
video_to_save="E:/save/MyVideo_1" # 不需要加上.mp4,在后面保存的时候会加上
cap = cv2.VideoCapture(video)
FPS = cap.get(cv2.CAP_PROP_FPS)
print(FPS)
size = (1280, 720)
print(size)
TOTAL_FRAME = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) # 获取视频总帧数
frameToStart = START_TIME * FPS # 开始帧 = 开始时间*帧率
print(frameToStart)
frametoMid = MID_TIME * FPS # 中间帧 = 结束时间*帧率
print(frametoMid)
frametoStop = END_TIME * FPS # 结束帧 = 结束时间*帧率
print(frametoStop)
videoWriter = cv2.VideoWriter(video_to_save+"a.mp4", cv2.VideoWriter_fourcc('m', 'p', '4', 'v'),
FPS, size)
videoWriter2 = cv2.VideoWriter(video_to_save+"b.mp4", cv2.VideoWriter_fourcc('m', 'p', '4', 'v'),
FPS, size)
COUNT = 0
while True:
success, frame = cap.read()
if success:
COUNT += 1
if COUNT <= frametoMid and COUNT > frameToStart: # 选取起始帧
print('correct= ', COUNT)
videoWriter.write(frame)
elif COUNT <= frametoStop and COUNT > frametoMid:
videoWriter2.write(frame)
if COUNT > frametoStop:
print("结束")
break
print('end')
效果如下:
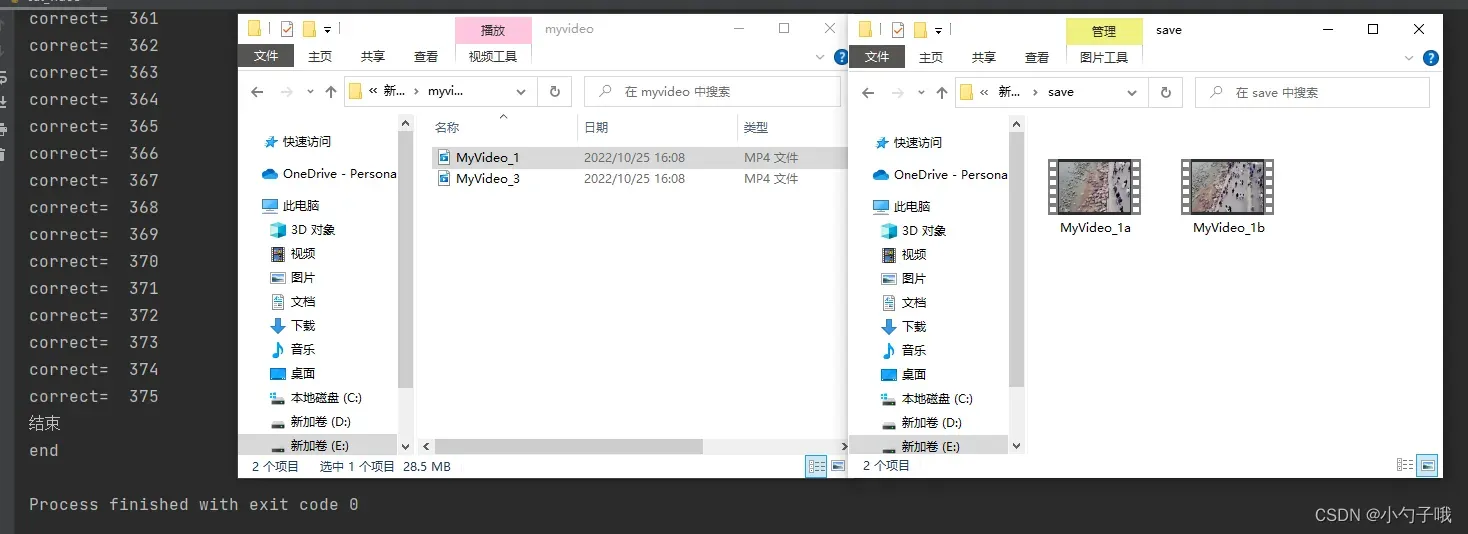
2 标注工具的使用:labelImg
请参考博文,按照这篇博文的步骤进行操作:LabelImg(目标检测标注工具)的安装与使用教程
3 使用数据增强扩充数据集(可选)
请参考博文:LabelImg,LabelMe工具标注后的图片数据增强
在完成标注后使用这篇博文的方法进行数据增强,会同时得到增强后的图片和xml文件!
但是我发现这篇博文所生成的xml有一些会有问题,例如xmin>xmax,请参考4.1节进行修正。同时,在数据增强后请再次使用labelImg查看标注是否有错误。
4 VOC格式转CoCo格式
4.1 检查所生成的xml文件
在标注完所有图片后,需要对生成的xml文件内容进行检查,使用checkxml.py
# coding=utf-8
import os
from xml.etree.ElementTree import ElementTree, Element
'''
checkxml.py
你需要修改的变量:
url: xml文件的目录路径
如果有错误的xml文件,根据具体情况来操作:
xmin<=0 or ymin<=0 : 小于0就手动去掉有问题的整个object,等于0就改成1
xmin>=max or ymin>=ymax: 大于就用本代码中注释的那一段进行修改,等于就手动去掉有问题的整个object
'''
def read_xml(in_path):
'''''读取并解析xml文件
in_path: xml路径
return: ElementTree'''
tree = ElementTree()
tree.parse(in_path)
return tree
def check():
url = "E:/annotations/" # 修改成annotations的目录
i = 0
list_error = []
for item in os.listdir(url):
tree = read_xml(url + "/" + item)
root = tree.getroot()
object = root.findall("object")
size = root.find("size")
width = int(size.find("width").text)
height = int(size.find("height").text)
if object == None:
print(item)
continue
for it in object:
bndbox = it.find("bndbox")
if bndbox == None:
print("bndbox == None")
print(item)
xmin = int(bndbox.find("xmin").text)
xmax = int(bndbox.find("xmax").text)
ymin = int(bndbox.find("ymin").text)
ymax = int(bndbox.find("ymax").text)
if xmin <= 0 or xmin >= xmax or ymin <= 0 or ymin >= ymax:
# 本段注释的代码用于把xmin\xmax, ymin\ymax互换,以及把为0的xmin\ymin改成1,一般来说用不到
# if xmin >= xmax:
# temp = xmin
# bndbox.find("xmin").text = str(xmax)
# bndbox.find("xmax").text = str(temp)
# if ymin >= ymax:
# temp = ymin
# bndbox.find("ymin").text = str(ymax)
# bndbox.find("ymax").text = str(temp)
# if xmin == 0:
# bndbox.find("xmin").text = str(1)
# if ymin == 0:
# bndbox.find("ymin").text = str(1)
# tree.write("E:/annotations_update/"+item)
print("xmin <= 0 or xmin >= xmax or ymin <=0 or ymin >= ymax", xmin, ymin) # 定位到出错的具体位置,在xml中搜索xmin或ymin的具体数据即可
print(item)
list_error.append(item)
i += 1
if xmax > width or ymax > height:
print("xmax > width or ymax> height",xmin,ymax)
print(item)
list_error.append(item)
i += 1
print(list(set(list_error)))
print(len(list(set(list_error))))
if __name__ == '__main__':
check()
4.2 按比例划分数据集为训练集、验证集、测试集+voc2coco+自动移动图片到对应目录(一步到位!)
4.2.1 图片和xml文件批量重命名(可选)
使用rename.py对图片和xml文件夹批量重命名,我这里是在他们原本的名称后面加入四位数字编号,在之后的voc转coco的过程中就会用这四位编号来作为图片的id。
# 用于批量重命名文件名,在文件名后面加上0000~9999的编号
import os
source_dir='E:/myvideo/' # 原路径
dest_dir='E:/myvideo/'# 重命名后的存放路径
f=os.listdir(source_dir)
for i in range(len(f)):
os.rename((source_dir+f[i]),(dest_dir + f[i][:-4]+ f'{i:04}' + '.jpg'))# 如果是重命名图片就是.jpg,重命名xml图片需要改成.xml
print(dest_dir + f[i][:-4]+ f'{i:04}' + '.jpg')
print("done")
效果如下:
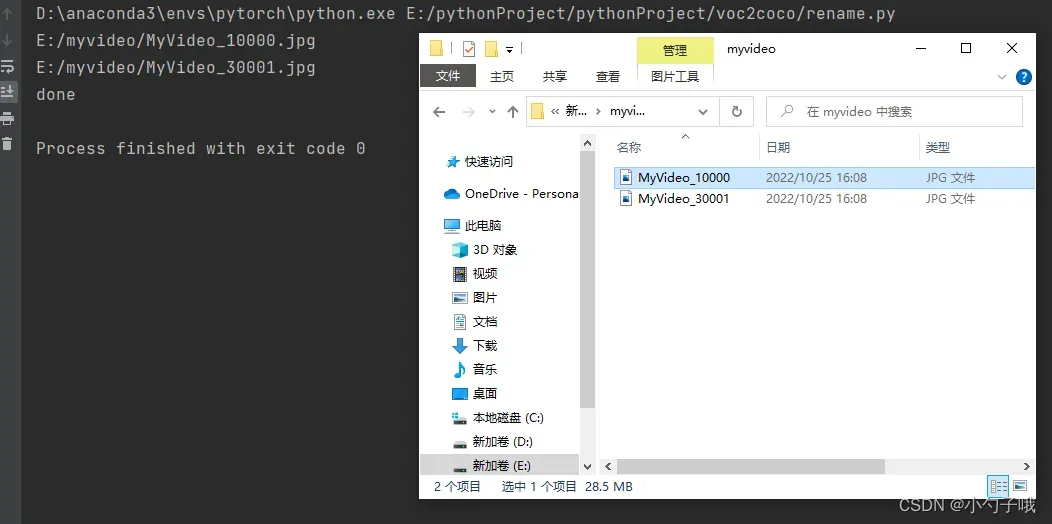
4.2.2 数据集格式转换
使用convert.py来进行数据集格式转换,同时完成训练验证测试集的划分,以及相应图片的移动。这里请保证一对图片和xml文件,他们的文件名称是完全相同的。
# coding:utf-8
# pip install lxml
# 参考博客链接为:https://blog.csdn.net/weixin_43878078/article/details/120578830
"""
convert.py
1. 建议按照以下层次放置数据集文件和本代码:
|--MyDataset_voc
|--Annotations
|--0001.xml
|...
|--JPEGImages
|--0001.jpg
|...
|--convert.py
|--MyDataset_coco 新建文件夹,用于存放转换后的图片和json文件
|--train 新建文件夹,用于存放训练集图片
|--val 新建文件夹,用于存放验证集图片
|--test 新建文件夹,用于存放测试集图片
如果你不是按照以上层次放置数据集,请自行修改对应文件的路径。
2. 在JPEFImages和Annotations中分别放入全部的图片和xml文件
3. 设置训练集、验证集、测试集比例
train_ratio = 0.8
val_ratio = 0.1
4. 修改类别 classes
"""
import os
import glob
import json
import shutil
import numpy as np
import xml.etree.ElementTree as ET
START_BOUNDING_BOX_ID = 1
def get(root, name):
return root.findall(name)
def get_and_check(root, name, length):
vars = root.findall(name)
if len(vars) == 0:
raise NotImplementedError('Can not find %s in %s.' % (name, root.tag))
if length > 0 and len(vars) != length:
raise NotImplementedError('The size of %s is supposed to be %d, but is %d.' % (name, length, len(vars)))
if length == 1:
vars = vars[0]
return vars
def convert(xml_list, json_file):
json_dict = {"info": ['none'], "license": ['none'], "images": [], "annotations": [], "categories": []}
categories = pre_define_categories.copy()
bnd_id = START_BOUNDING_BOX_ID
all_categories = {}
for index, line in enumerate(xml_list):
# print("Processing %s"%(line))
xml_f = line
tree = ET.parse(xml_f)
root = tree.getroot()
filename = os.path.basename(xml_f)[:-4] + ".jpg"
image_id = filename.split('.')[0][-4:] # 图片的后四位
# print('filename is {}'.format(image_id))
size = get_and_check(root, 'size', 1)
width = int(get_and_check(size, 'width', 1).text)
height = int(get_and_check(size, 'height', 1).text)
image = {'file_name': filename, 'height': height, 'width': width, 'id': image_id}
json_dict['images'].append(image)
## Cruuently we do not support segmentation
# segmented = get_and_check(root, 'segmented', 1).text
# assert segmented == '0'
for obj in get(root, 'object'):
category = get_and_check(obj, 'name', 1).text
if category in all_categories:
all_categories[category] += 1
else:
all_categories[category] = 1
if category not in categories:
if only_care_pre_define_categories:
continue
new_id = len(categories) + 1
print(
"[warning] category '{}' not in 'pre_define_categories'({}), create new id: {} automatically".format(
category, pre_define_categories, new_id))
categories[category] = new_id
category_id = categories[category]
bndbox = get_and_check(obj, 'bndbox', 1)
xmin = int(float(get_and_check(bndbox, 'xmin', 1).text))
ymin = int(float(get_and_check(bndbox, 'ymin', 1).text))
xmax = int(float(get_and_check(bndbox, 'xmax', 1).text))
ymax = int(float(get_and_check(bndbox, 'ymax', 1).text))
assert (xmax > xmin), "xmax <= xmin, {}".format(line)
assert (ymax > ymin), "ymax <= ymin, {}".format(line)
o_width = abs(xmax - xmin)
o_height = abs(ymax - ymin)
ann = {'area': o_width * o_height, 'iscrowd': 0, 'image_id':
image_id, 'bbox': [xmin, ymin, o_width, o_height],
'category_id': category_id, 'id': bnd_id, 'ignore': 0,
'segmentation': []}
json_dict['annotations'].append(ann)
bnd_id = bnd_id + 1
for cate, cid in categories.items():
cat = {'supercategory': 'person', 'id': cid, 'name': cate}
json_dict['categories'].append(cat)
json_fp = open(json_file, 'w')
json_str = json.dumps(json_dict)
json_fp.write(json_str)
json_fp.close()
print("------------create {} done--------------".format(json_file))
print("find {} categories: {} -->>> your pre_define_categories {}: {}".format(len(all_categories),
all_categories.keys(),
len(pre_define_categories),
pre_define_categories.keys()))
print("category: id --> {}".format(categories))
print(categories.keys())
print(categories.values())
if __name__ == '__main__':
# xml标注文件夹
xml_dir = './Annotations'
# 训练数据的josn文件
save_json_train = '../MyDataset_coco/train.json'
# 验证数据的josn文件
save_json_val = '../MyDataset_coco/val.json'
# 测试数据的test文件
save_json_test = '../MyDataset_coco/test.json'
# 类别,如果是多个类别,往classes中添加类别名字即可,比如['dog', 'person', 'cat']
classes = []
pre_define_categories = {}
for i, cls in enumerate(classes):
pre_define_categories[cls] = i + 1
print("pre_define_categories", pre_define_categories)
only_care_pre_define_categories = True
# 训练数据集比例,当这两个都填0的时候,测试集(test_ratio)就是1了
train_ratio = 0.8
val_ratio = 0.1
print('xml_dir is {}'.format(xml_dir))
xml_list = glob.glob(xml_dir + "/*.xml")
images_list = glob.glob("./JPEGImages/*.jpg")
xml_list = np.sort(xml_list)
np.random.seed(100)
np.random.shuffle(xml_list)
train_num = int(len(xml_list) * train_ratio)
val_num = int(len(xml_list) * val_ratio)
print('训练样本数目是 {}'.format(train_num))
print('验证样本数目是 {}'.format(val_num))
print('测试样本数目是 {}'.format(len(xml_list) - train_num - val_num))
xml_list_val = xml_list[:val_num]
print("xml_list_val,", xml_list_val)
xml_list_train = xml_list[val_num:train_num + val_num]
print("xml_list_train,", xml_list_train)
xml_list_test = xml_list[train_num + val_num:]
print("xml_list_test,", xml_list_test)
# 移动对应图片到对应的文件夹
val_name_list = []
train_name_list = []
test_name_list = []
val_name_list2 = []
train_name_list2 = []
test_name_list2 = []
for name in xml_list_val:
val_name_list.append(name[14:]) # 根据你的目录,你可能需要修改这里的数字,建议按照默认方式放置
for i in range(len(val_name_list)):
val_name_list[i] = val_name_list[i][:-4] # 剪掉后四个元素,也就是.xml,得到图片的名称
for name in xml_list_train:
train_name_list.append(name[14:]) # 根据你的目录,你可能需要修改这里的数字,建议按照默认方式放置
for i in range(len(train_name_list)):
train_name_list[i] = train_name_list[i][:-4] # 剪掉后四个元素,也就是.xml,得到图片的名称
for name in xml_list_test:
test_name_list.append(name[14:]) # 根据你的目录,你可能需要修改这里的数字,建议按照默认方式放置
for i in range(len(test_name_list)):
test_name_list[i] = test_name_list[i][:-4] # 剪掉后四个元素,也就是.xml,得到图片的名称
images_root_dir = "./JPEGImages/"
images_name_list = os.listdir(images_root_dir)
for i in range(len(images_name_list)):
images_name_list[i] = images_name_list[i][:-4]
print("images_name_list", images_name_list)
for images_name in images_name_list:
for val_name in val_name_list:
if images_name == val_name:
val_name_list2.append(images_name)
source_path = images_root_dir + images_name + ".jpg"
des_path = "../MyDataset_coco/val/" + val_name + ".jpg"
shutil.move(source_path, des_path)
for train_name in train_name_list:
if images_name == train_name:
train_name_list2.append(images_name)
source_path = images_root_dir + images_name + ".jpg"
des_path = "../MyDataset_coco/train/" + train_name + ".jpg"
shutil.move(source_path, des_path)
for test_name in test_name_list:
if images_name == test_name:
test_name_list2.append(images_name)
source_path = images_root_dir + images_name + ".jpg"
des_path = "../MyDataset_coco/test/" + test_name + ".jpg"
shutil.move(source_path, des_path)
print("val_pic,", val_name_list2)
print("train_pic,", train_name_list2)
print("test_pic,", test_name_list2)
# 对训练数据集对应的xml进行coco转换
convert(xml_list_train, save_json_train)
# 对验证数据集的xml进行coco转换
convert(xml_list_val, save_json_val)
# 对测试数据集的xml进行coco转换
convert(xml_list_test, save_json_test)
效果如下:
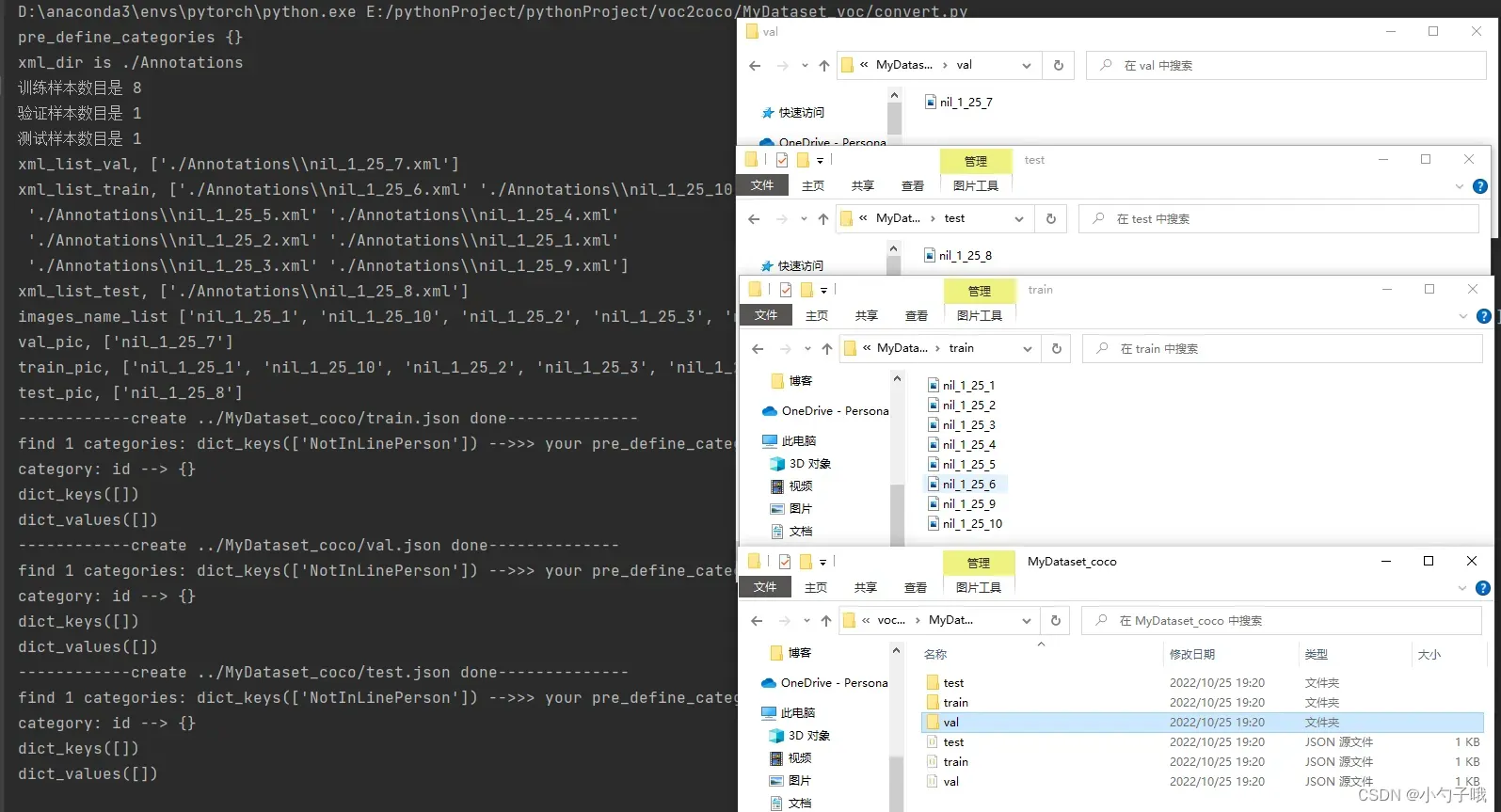
5 常见问题(常用工具代码)
5.1 计算文件夹下的文件数量
使用countfile.py对文件夹下的文件进行计数
import os
path = "./annotations" # 要计数的文件夹路径
count = 0
for file in os.listdir(path): # file 表示的是文件名
count = count + 1
print(count)
5.2 去除voc格式的单身文件(只有图片没有xml或只有xml没有图片)
使用check_single.py清理图片和xml文件,需要把图片和xml文件放置在同一个文件夹下,如果有报错可以尝试多次运行,直到每次运行的结果一致,dele为空。
"""
https://blog.csdn.net/gusui7202/article/details/83239142
"""
import os
import os.path
h = 0
a = ''
b = ''
dele = []
pathh = "E:/annotations_and_images/" # 把图片和xml文件放到同一个文件夹下进行清理
# dele.remove(1)
for filenames in os.walk(pathh):
# for dirpath,dirnames,filenames in os.walk(path)三元组,dirpath为搜索目录,dirnames(list),为搜索目录下所有文件夹,filenames(list)为搜索目录下所有文件,这里用法其实很不好,filenames其实就是这个三元组,然后再将第三个提取出来,代码可读性太差了。
filenames = list(filenames)
filenames = filenames[2]
for filename in filenames:
print(filename)
if h == 0: # 如果第一次检索到这个名字则放到a里面
a = filename
h = 1
elif h == 1: # 这是第二次检索了,h=1说明已经存储了一个文件名在a中,然后读取了下一个文件名,然后判断是否一样。这个程序的Bug就是pic和label must put together.而且要贴在一起。
print(filename)
b = filename
if a[0:a.rfind('.', 1)] == b[0:b.rfind('.',1)]: # 这里用了rfind来给出名字,然后比较,rfind找出字符最后一次出现的位置。这里.前面就是文字,而切片【a:b】不计b。
h = 0
# print(filename)
else:
h = 1
dele.append(a)
a = b
else:
print("wa1")
print("dele")
print(dele)
for file in dele:
print("进入")
os.remove(pathh + file)
print("remove" + file + " is OK!")
# 再循环一次看看有没有遗漏的单身文件
for filenames in os.walk(pathh):
filenames = list(filenames)
filenames = filenames[2]
for filename in filenames:
print(filename)
if h == 0:
a = filename
h = 1
elif h == 1:
print(filename)
b = filename
if a[0:a.rfind('.', 1)] == b[0:b.rfind('.', 1)]:
h = 0
print(filename)
else:
h = 1
dele.append(a)
a = b
else:
print("wa1")
print("dele")
print(dele)
# 清除单身的xml或者jpg 在Windows运行
for file in dele:
print("进入")
os.remove(pathh + file)
print("remove" + file + " is OK!")
5.3 统计数据集内的标注数量
5.3.1 从xml文件中统计(VOC格式)
使用count_label_xml.py计算xml文件中每一类有多少个标注。
# -*- coding:utf-8 -*-
# https://blog.csdn.net/gusui7202/article/details/86583444
import os
import xml.etree.ElementTree as ET
from PIL import Image
'''count_label_xml.py'''
def parse_obj(xml_path, filename):
tree = ET.parse(xml_path + filename)
objects = []
for obj in tree.findall('object'):
obj_struct = {}
obj_struct['name'] = obj.find('name').text
objects.append(obj_struct)
return objects
def read_image(image_path, filename):
im = Image.open(image_path + filename)
W = im.size[0]
H = im.size[1]
area = W * H
im_info = [W, H, area]
return im_info
if __name__ == '__main__':
xml_path = 'E:/annotations/' # 存放xml文件的路径
filenamess = os.listdir(xml_path)
filenames = []
for name in filenamess:
name = name.replace('.xml', '')
filenames.append(name)
recs = {}
obs_shape = {}
classnames = []
num_objs = {}
obj_avg = {}
for i, name in enumerate(filenames):
recs[name] = parse_obj(xml_path, name + '.xml')
for name in filenames:
for object in recs[name]:
if object['name'] not in num_objs.keys():
num_objs[object['name']] = 1
else:
num_objs[object['name']] += 1
if object['name'] not in classnames:
classnames.append(object['name'])
for name in classnames:
print('{}:{}个'.format(name, num_objs[name])) # 将输入每一类的标注数量
print('信息统计算完毕。')
5.3.2 从json文件中统计(CoCo格式)
使用count_label_json.py从json文件中统计每一类标注的数量。
from pycocotools.coco import COCO
annFile ='E:/annotations/train.json' # 要统计的json文件
# initialize COCO api for instance annotations
coco_train = COCO(annFile)
# display COCO categories and supercategories
# 显示所有类别
cats = coco_train.loadCats(coco_train.getCatIds())
cat_nms = [cat['name'] for cat in cats]
print('COCO categories:\n{}'.format('\n'.join(cat_nms)) + '\n')
for catId in coco_train.getCatIds():
imgId=coco_train.getImgIds(catIds=catId)
annId=coco_train.getAnnIds(catIds=catId)
print("{:<6} {:<6d} {:<10d}".format(catId,len(imgId),len(annId)))
print("NUM_categories: " + str(len(coco_train.dataset['categories'])))
print("NUM_images: " + str(len(coco_train.dataset['images'])))
print("NUM_annotations: " + str(len(coco_train.dataset['annotations'])))
如果还有其他想知道的欢迎在评论区提问讨论!!欢迎点赞o( ̄▽ ̄)d~~
文章出处登录后可见!