NLL损失在NLP中含义 :
在自然语言处理中,通常用于分类任务,例如语言模型、情感分类等。NLL损失全称为Negative Log-Likelihood Loss,其含义是负对数似然损失。
在NLP任务中,我们通常将文本数据表示为一个序列,例如单词序列或字符序列(一句话就是一个序列【sequence】)。对于分类任务,我们需要将每个序列映射到一个类别标签。因此,我们需要一个模型,能够将输入序列映射到输出标签。
在模型训练期间,我们需要最小化模型预测结果和真实标签之间的差异,以使模型的预测结果更加接近真实结果,使用NLL损失可以帮助我们实现这一点。
具体来说,对于一个输入序列 x 和真实标签 y,我们可以使用模型预测的标签分布  和真实标签 y 的对数概率来计算NLL损失,计算公式就是右半部分:
和真实标签 y 的对数概率来计算NLL损失,计算公式就是右半部分:
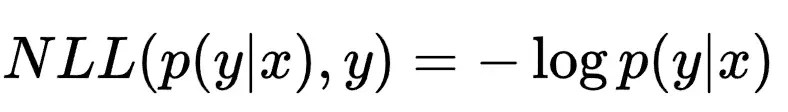
NLL损失的含义是:如果我们的模型的预测结果 越接近真实标签 y ,那么  的值就越小。
的值就越小。
在模型训练期间,我们使用NLL损失来计算每个样本的损失值,并通过反向传播算法更新模型参数以最小化总体NLL损失。这样可以帮助我们训练出更好的模型,使其在测试数据上的表现更好。
损失函数一:
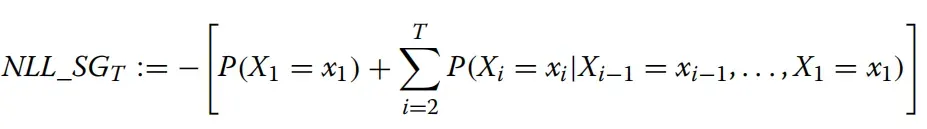
- 在该损失函数中,
 表示在第 i 个时间步中的随机变量,其取值可以是词汇表中的任何一个token。
表示在第 i 个时间步中的随机变量,其取值可以是词汇表中的任何一个token。 -
 表示在第 i 个时间步中选择的token。因此,
表示在第 i 个时间步中选择的token。因此, 表示在给定前面所有token的情况下,模型选择 作为下一个token的概率。
表示在给定前面所有token的情况下,模型选择 作为下一个token的概率。 - 在训练中,使用了“Teacher’s forcing”(老师强制)的方法,该方法在训练阶段中,将前一个时间步的真实token作为当前时间步的输入,以帮助模型正确学习语法。因此,在训练期间,可以通过提供正确的输入来帮助模型生成下一个正确的token序列,从而减少损失函数的值。
总之,这个损失函数的目的是通过最小化模型的预测值与真实token序列之间的差异来训练语言模型。在训练过程中,通过“Teacher’s forcing”方法,模型可以更好地学习语法和语义规则,提高模型在生成下一个token时的准确性和流畅性。
损失函数二:
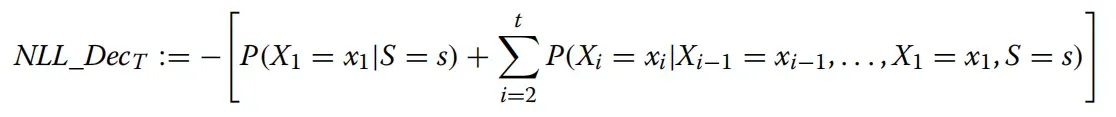
- 表示在第 i 个时间步中生成的随机变量,取值为词汇表中的任意一个token。
- 表示在第 i 个时间步中选择的token。
- S 表示输入序列。
 表示在给定输入序列 s 和前面所有token的情况下,模型选择 作为下一个token的概率。
表示在给定输入序列 s 和前面所有token的情况下,模型选择 作为下一个token的概率。 是一个负对数似然损失函数,它的目的是最小化模型预测的token序列与真实token序列之间的差异,使得生成的token序列更接近真实的标记序列。
是一个负对数似然损失函数,它的目的是最小化模型预测的token序列与真实token序列之间的差异,使得生成的token序列更接近真实的标记序列。
具体来说,该损失函数的第一项是第一个时间步的损失,表示在给定输入序列 s 的情况下,模型生成第一个标记  的概率与真实标记的概率之间的差异。第二项是从第二个时间步开始的损失项,表示在给定输入序列和前面的标记的情况下,模型生成第 i 个标记 的概率与真实标记的概率之间的差异。
的概率与真实标记的概率之间的差异。第二项是从第二个时间步开始的损失项,表示在给定输入序列和前面的标记的情况下,模型生成第 i 个标记 的概率与真实标记的概率之间的差异。
总之,该损失函数的目的是通过最小化模型预测的标记序列与真实标记序列之间的差异来训练生成模型,使其在给定输入序列的情况下能够生成符合语言规则和语义的标记序列。通过优化该损失函数,可以提高生成模型的生成准确性和流畅性。
将上面的损失函数写成NLL损失的样式:
假设  是给定的序列,S 是上下文,
是给定的序列,S 是上下文, 是可能的值,
是可能的值, 是给定先前历史和上下文 S=s 条件下,预测 为 的概率。
是给定先前历史和上下文 S=s 条件下,预测 为 的概率。
则  可以表示为:
可以表示为:
![NLL_Dec_T = - log left[ Pleft(X_{1}=x_{1} mid S=sright) prod_{i=2}^{t} Pleft(X_{i}=x_{i} mid X_{i-1}=x_{i-1}, ldots, X_{1}=x_{1}, S=sright) right]](https://aitechtogether.com/wp-content/uploads/2023/04/gif-186.gif%20%3D%20-%20%5Clog%20%5Cleft%5B%20P%5Cleft%28X_%7B1%7D%3Dx_%7B1%7D%20%5Cmid%20S%3Ds%5Cright%29%20%5Cprod_%7Bi%3D2%7D%5E%7Bt%7D%20P%5Cleft%28X_%7Bi%7D%3Dx_%7Bi%7D%20%5Cmid%20X_%7Bi-1%7D%3Dx_%7Bi-1%7D%2C%20%5Cldots%2C%20X_%7B1%7D%3Dx_%7B1%7D%2C%20S%3Ds%5Cright%29%20%5Cright%5D)

其中第一项是条件概率  的负对数,第二项是从第二个时刻开始的条件概率
的负对数,第二项是从第二个时刻开始的条件概率  的负对数之和。
的负对数之和。
文章出处登录后可见!