上周我有幸参加了由中国图像图形学会和合合信息共同举办的CSIG企业行活动。
这次活动邀请了多位来自图像描述与视觉问答、图文公式识别、自然语言处理、生成式视觉等领域的学者,他们分享了各自的研究成果和经验,并与现场观众进行了深入的交流和探讨。干货多多,感悟多多,在这里分享此次的收获给大家。
一、活动介绍
✍中国图像图形学学会(China Society of Image and Graphics,CSIG)成立于1990年,是经国家民政部批准成立的国家一级学会,是中国科学技术协会的正式团体会员。它是致力于推进图像图形学领域学科建设、技术研究和学术交流的专业学会。中国图象图形学学会的宗旨是团结广大图象图形科技工作者,积极开展图象图形基础理论和高新技术的研究,促进该学科技术的发展和在国民经济各个领域的推广应用。此次的CSIG企业行-走进合合信息就是学会的重要交流研讨形式之一。
本次活动以“图文智能处理与多场景应用技术展望”为主题,聚集了来自全国知名高校和合合信息技术团队的学者和工程师,一同分享图像文档处理领域的最新研究成果和实践经验。
在当天,来自上海交通大学、厦门大学、复旦大学、中国科学技术大学等知名学府的学者和合合信息技术团队的工程师的分享探讨了图像文档处理中的结构建模、底层视觉技术、跨媒体数据协同应用、生成式人工智能及对话式大型语言模型等多个领域的研究进展和实践成果,下面我选取并总结了会上我最感兴趣,也是当前最热点的几个话题的部分内容,分享给大家:
二、🎉生成式人工智能和元宇宙
2.1、生成式人工智能——未来的战略技术
杨小康教授在现场强调了生成式人工智能的重要性,他指出,生成式人工智能是通过机器学习方法从数据中学习特征,进而生成全新的、原创的数据,预计到2025,生成式人工智能产生的数据将占据人类全部数据的10%。
当生成式数据超过80%的时候,人类是否全面进入元宇宙成为了一个非常值得深思的问题,元宇宙需要生成式人工智能来构建,通过生成式人工智能所生成的数据,元宇宙才能不断地演化和发展。生成式人工智能的发展将推动元宇宙的发展和进化,而元宇宙的不断演化和发展也将进一步促进生成式人工智能技术的创新与进步,两者相互促进、相互依存。这也预示着未来的科技发展将朝着更加智能化、更加普惠化的方向前进。
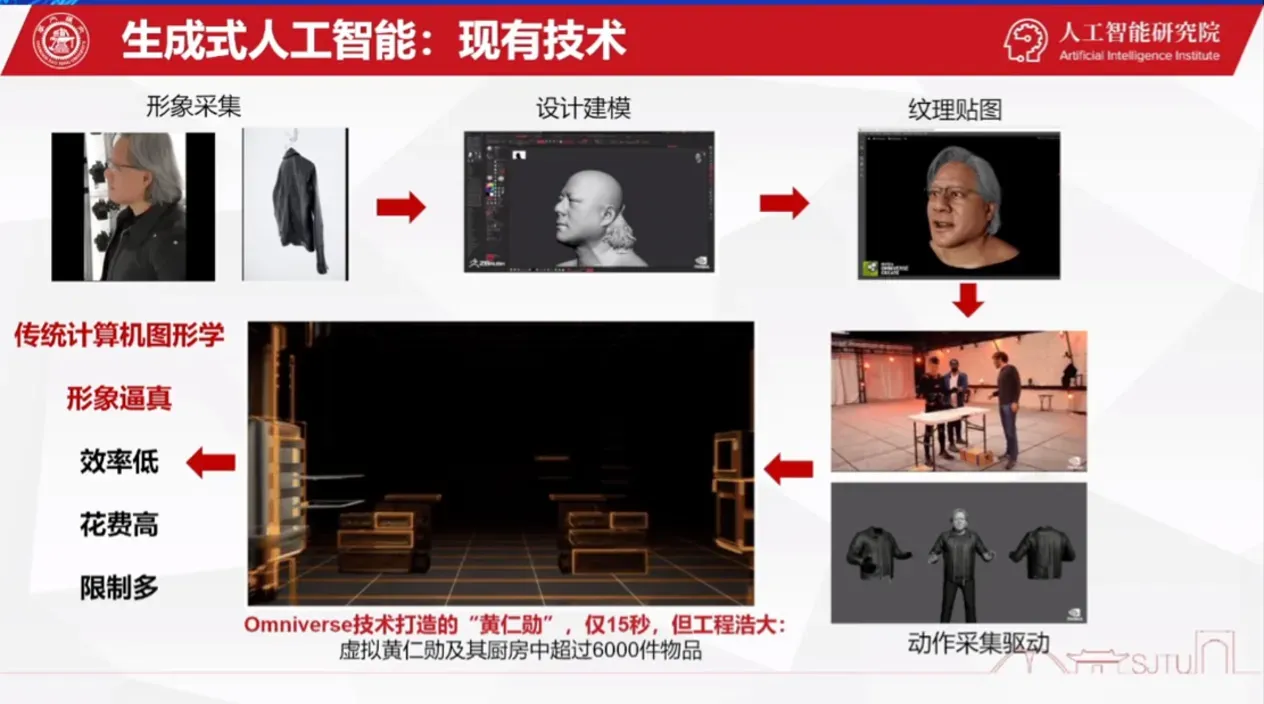
2.2、生成式世界模型
生成式世界模型是一种基于人工智能的技术,其核心思想是让计算机从输入数据中学习,从而构建出一个全新的、可以被操作的虚拟世界。
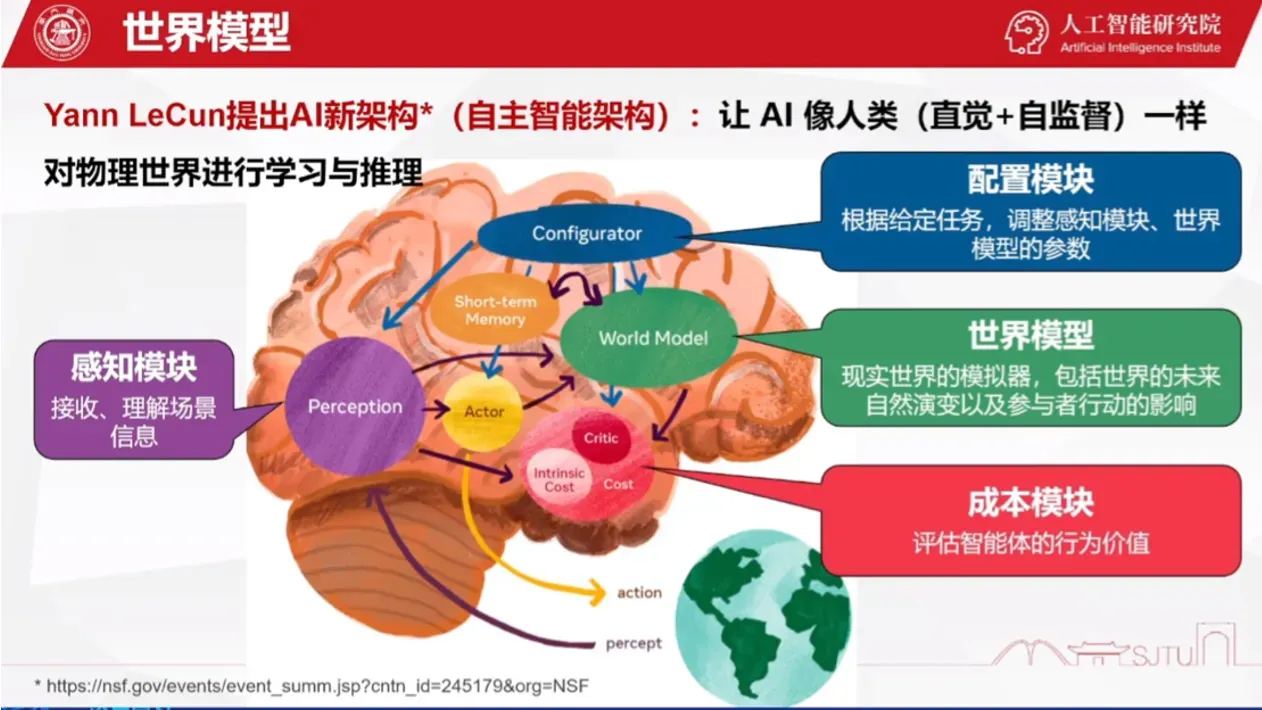
生成式世界模型通过学习大量数据中的规律和模式,可以生成全新的、原创的数据,并以此构建出一个与真实世界类似的虚拟世界。这个虚拟世界中的每个元素都是由计算机自主创造的,并且可以被操作、改变、扩展。与传统的计算机模拟不同,生成式世界模型所创造的虚拟世界具有更高的逼真度和互动性,能够提供更加真实的体验。
2.3、生成式虚拟数字人
生成式虚拟数字人是指利用生成式人工智能技术,从真实的人类数据中学习,生成一个虚拟的数字化人类形象,其外貌、言谈举止和行为模式等方面均与真实的人类相似度极高。生成式虚拟数字人的应用领域非常广泛,包括电影、游戏、社交网络、虚拟现实、远程教育、在线客服等诸多领域。
杨教授为我们介绍了许多生成式虚拟数字人的应用。其中包括3D人脸重建、高拟真的表情可驱动数字人技术、语音驱动个性化数字人技术、跨模态驱动等等。
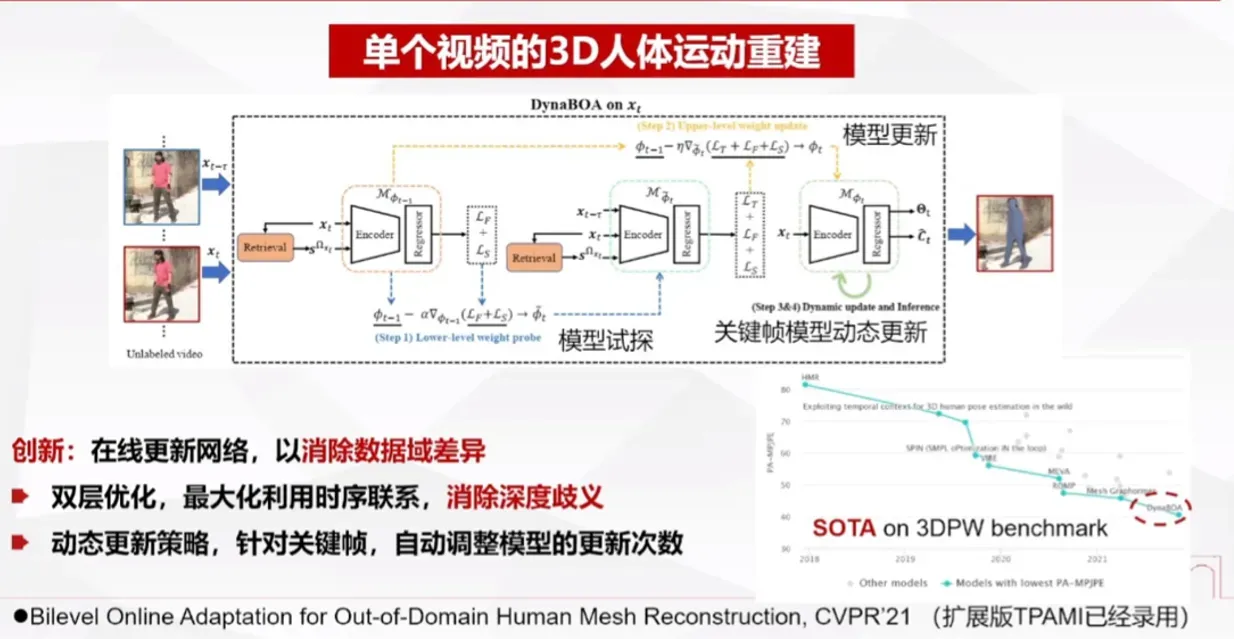
总的来说,生成式虚拟数字人作为生成式人工智能技术的一种应用,将在各个领域发挥越来越重要的作用,未来,随着技术的不断进步和应用场景的不断拓展,生成式虚拟数字人的应用将会更加广泛,也将会呈现出越来越高的技术水平和越来越强的应用能力。
2.4、想法1:生成式人工智能+艺术
这让我联想到目前火热的Midjourney和Dalle等AI作画工具。
绘画艺术是几千年文化的结晶,但是大多数成功的艺术家都有自己独特的绘画风格,利用人工智能研究和模仿这种绘画风格的独特性和绘画技巧,将艺术大师的名画的画风迁移到普通的图片也是一个非常有趣的应用。
利用神经网络进行风格转移,可以实现多种艺术风格的融合。一方面可以实现图像的二次开发,表现出更好的艺术效果。另一方面,可以为设计师提供全新的艺术视角和设计灵感。
目前,基于深度学习的风格迁移主要采用经典的网络结构VGG-Net。
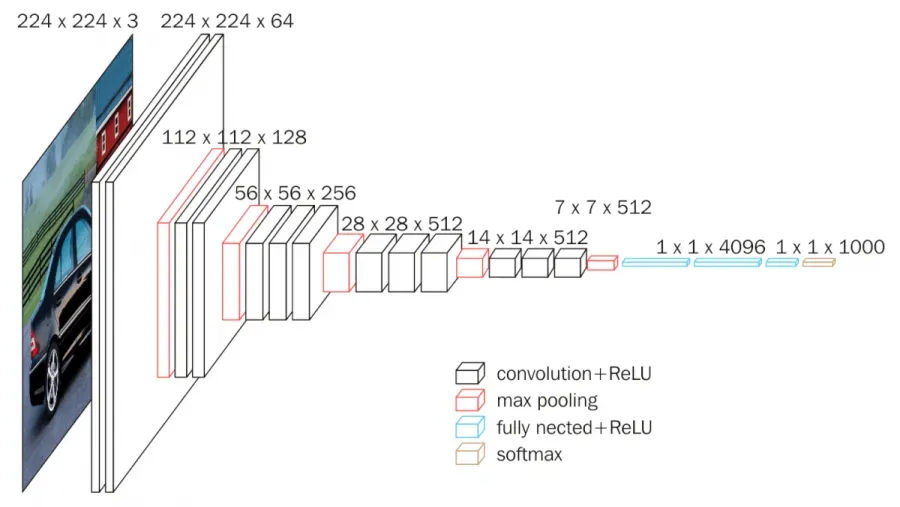
VGG16模型是牛津大学的K.Simonyan和A.Zisserman在论文“Very Deep Convolutional Networks for Large-Scale Image Recognition”中提出的卷积神经网络模型,模型首先输入一个224 x 224像素大小的RGB图像时,经过一系列卷积层,这些卷积层使用非常小的滤波器大小(3×3)以捕捉像素周围的左/右、上/下和中心的特征,在其中一个卷积层配置中,使用1×1的滤波器来进行线性转换,卷积的步幅为1个像素,这样输入图像的填充方式使得在卷积后保留空间分辨率。随后最大池化层用于进一步降低图像的空间维度。
在卷积层和池化层之后,作者还设计了三个全连接层,这些层的结构在所有网络中都相同。前两个全连接层都有4096个节点,第三个全连接层有1000个节点,用于输出1000个类别的概率分布。最后一层是softmax层,用于将全连接层的输出转换为概率值。所有的隐藏层都使用ReLU激活函数,但不包含局部响应归一化(LRN)。
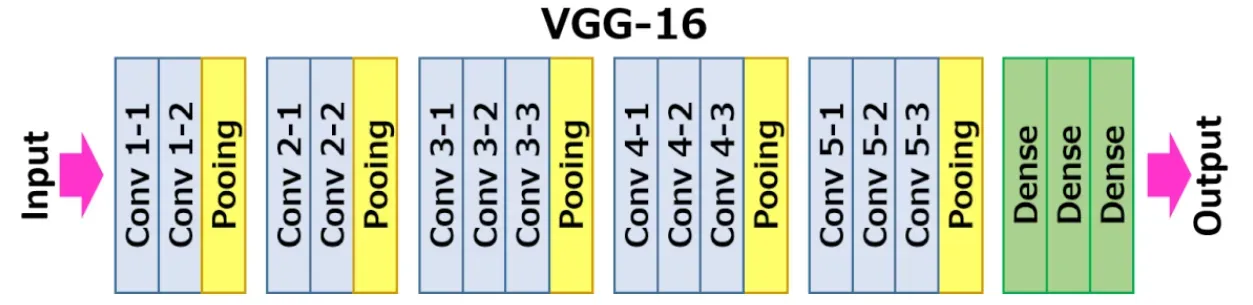
总的来说,VGG16,模型通过用多个 3×3 内核大小的过滤器一个接一个地替换大内核的过滤器(第一和第二卷积层中分别为 11 和 5)来对 AlexNet 进行改进,使得模型具有出色的特征提取能力和较高的精度。
三、✨大型语言模型(类ChatGPT)的关键技术和实现
3.1、ChatGPT的三个关键技术
邱锡鹏教授为我们介绍了目前火热的类ChatGPT的大型语言模型,虽然目前ChatGPT技术细节和模型参数尚未开源,但是它已经展现出惊人的能力,呈现了普适人工智能助手的广阔研究和应用前景。其中,情景学习、思维链和指令学习是其三个最为突出的特点:
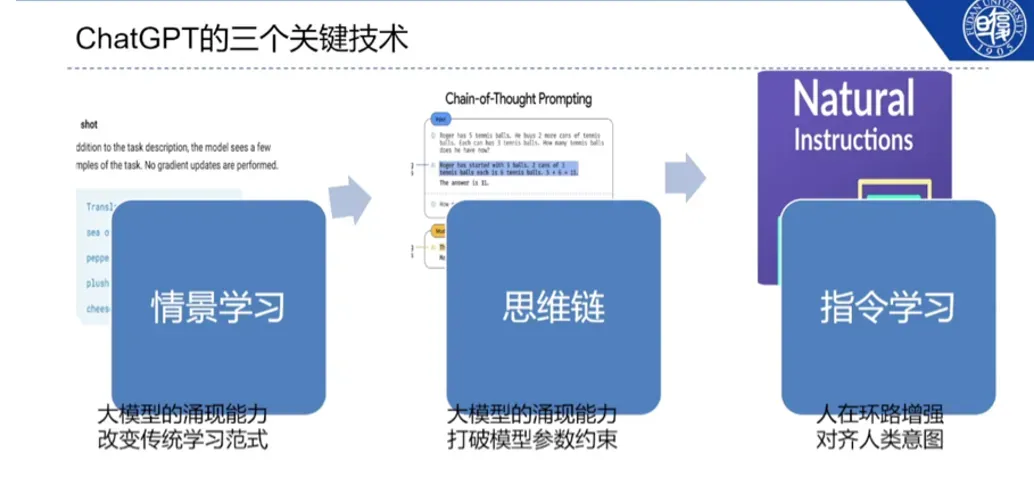
情景学习:这是ChatGPT的核心能力之一,它能够从文本中学习出不同上下文之间的关联性,进而在新的情景下产生合理的回复。这种能力不仅需要对语义和逻辑有着深入的理解,还需要对语言的常识和背景知识有所了解。通过对大量数据的训练,ChatGPT能够逐渐提升其情景学习的能力,实现更为自然、准确的对话。
思维链:ChatGPT可以通过建立思维链来理解问题,即将一个问题分解成一系列相关的子问题,并在不同的阶段中进行回答。这种能力使得ChatGPT可以更加深入地理解问题,从而提供更为准确的答案。
指令学习:ChatGPT的另一个重要能力是它可以从指令式的文本中学习出对应的行为,并将其转化为相应的操作。这种能力对于语音助手、机器人等领域具有重要的应用价值。例如,当用户发出“帮我用js代码解决下面这个问题”的指令时,ChatGPT可以理解该指令的含义并将其转化为输出相应的代码,实现与用户的交互。同样,ChatGPT也能够通过大量的数据训练提升其指令学习的能力,进而实现更为准确和智能的指令执行。
3.2、暗知识的理解和应用
ChatGPT只是对话式人工智能领域的一个开始,随着技术的不断发展,人工智能将会更好地理解并应用“暗知识”,即无法直接通过文本获得的知识,比如人类的观察和经验。此外,跨模态学习也是人工智能未来发展的重要方向,通过让机器从多种感知模态(如视觉、听觉、触觉)中进行学习和交互,可以更好地模拟人类的认知过程,实现更加智能化和精准化的应用。

3.3、想法2:任务导向型对话系统+Excel、PPT、PS
ChatGPT的下一步发展一方面可能是多模态的运用,另一方面则是任务导向型对话系统。面向任务的对话(TOD)通常被分解为三个子任务:
对话状态跟踪(DST),用于跟踪用户的信念状态;
对话政策学习(POL),用于决定采取何种系统行动;
自然语言生成(NLG),用于生成对话响应
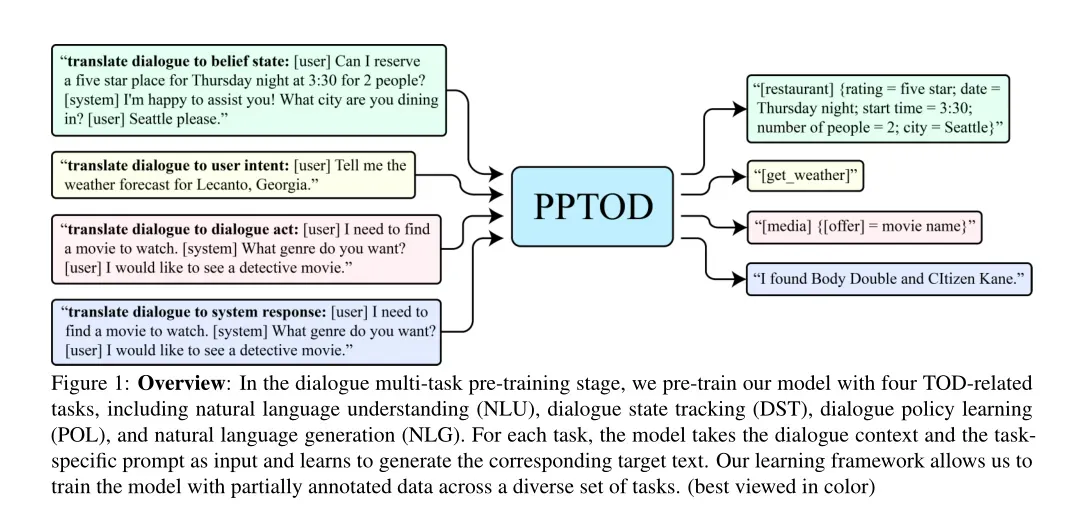
PPTOD模型将不同的对话模块(例如DST、POL和NLG)集成到一个统一的模型中。受上下文内学习概念(Brown et al, 2020)的激励,作者将特定于任务的自然语言指令(称为提示)插入对话上下文作为模型输入来引导模型解决不同的TOD子任务,这种方式上不同子任务的代数是解耦的,使得模型具有更大的灵活性,另外作者还使用T5对由部分注释数据组成的异构对话语料库进行了预训练。
在此基础上,使用任务导向型对话系统操纵Excel、PPT、PS等工具进行任务协作是一个非常值得开发的思路。对于Excel这类数据处理软件,任务导向型对话系统可以通过识别和理解用户输入的数据,自动完成数据处理、图表绘制等操作。对于PPT这类演示软件,任务导向型对话系统可以通过理解用户输入的要求,自动调整PPT页面布局、插入图片、添加动画,使得PPT制作过程变得更加简单和快捷。对于PS这类图像处理软件,任务导向型对话系统可以通过理解用户输入的要求,自动完成图像裁剪、调色、修图等操作,使得图像处理变得更加简单和高效。
四、🎊复杂跨媒体数据协同分析与应用
4.1、视觉–>语言跨媒体分析研究
接下来纪荣嵘教授的主题报告是复杂跨媒体数据协同分析与应用,这也是和文本生成图像的方向息息相关。
视觉-语言跨媒体分析研究是计算机视觉(CV)领域的重要研究方向之一,它将图像和视频中的视觉信息与自然语言中的语义信息相结合,通过计算机算法进行跨媒体的分析和理解。该领域的研究目标是建立视觉与语言之间的联系,实现计算机对图像、视频、语音等多模态数据的深入理解和处理,从而推进人工智能的发展和应用。在视觉-语言跨媒体分析研究中,深度学习技术和生成式模型被广泛应用,例如图文匹配、看图说话、视觉问答、听文作图和指向检测等,为实现智能化应用和人机交互提供了有力支撑。

4.2、语言–>视觉跨媒体分析研究
语言-视觉跨媒体分析研究致力于将自然语言和视觉信息进行融合,实现对多模态数据的分析和理解。例如,通过将图像与相应的文字描述相结合,可以构建图像标注系统,从而提高图像检索的效率。此外,在机器翻译方面,语言–>视觉跨媒体分析研究可以将图像作为上下文信息,辅助翻译系统进行翻译,提高翻译质量。近年来,随着深度学习技术的不断发展,语言–>视觉跨媒体分析研究取得了很大的进展,并在图像检索、机器翻译、视频理解等领域得到了广泛的应用。
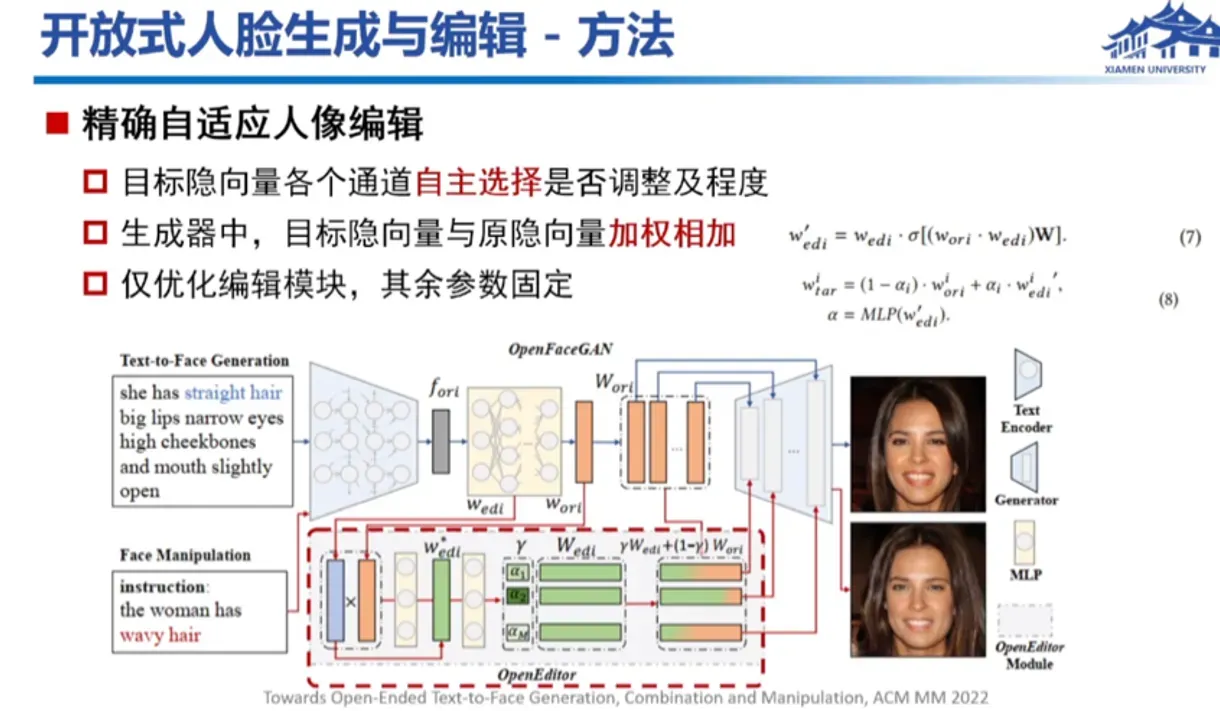
开放式人脸生成与编辑是计算机视觉领域中的一个重要研究方向,它利用生成式人工智能技术和深度学习算法,从少量样本或者甚至仅仅是一张人脸照片中,生成具有高度可信度和多样性的人脸图像。这项技术的应用非常广泛,比如可以应用在人脸识别、虚拟试衣、虚拟现实、游戏开发、电影特效等领域。
通过利用生成式人工智能技术和深度学习算法,可以实现对人脸图像的各种属性进行编辑,比如年龄、性别、肤色、头发、胡子、表情等等。这项技术可以为虚拟试衣、电影特效等领域带来更多的可能性,也为医学领域中的面部重建等提供了新的思路和方法。
4.3、想法3:生成性NeRF+3D视觉生成
信息在现实世界中以各种形式存在,多模态信息之间的有效交互和融合对于计算机视觉和深度学习研究中多模态数据的创建和感知起着关键作用。
神经辐射场(NeRF)通过使用神经网络定义隐式场景表示,实现了令人印象深刻的新视图合成性能。特别是,NeRF采用全连接神经网络,将空间位置(x,y,z)和相应的观察方向(θ,φ))作为输入,将体积密度和相应的发射辐射作为输出。
基于此,FENeRF提出了一种3D感知生成器,可以生成视图一致且可本地编辑的肖像图像。FENeRF使用两个解耦的潜在代码在具有共享几何结构的空间对齐的3D体积中生成相应的面部语义和纹理。得益于这种底层3D表示,Feneff可以联合渲染边界对齐的图像和语义掩模,并使用语义掩模通过GAN逆映射编辑3D体积。
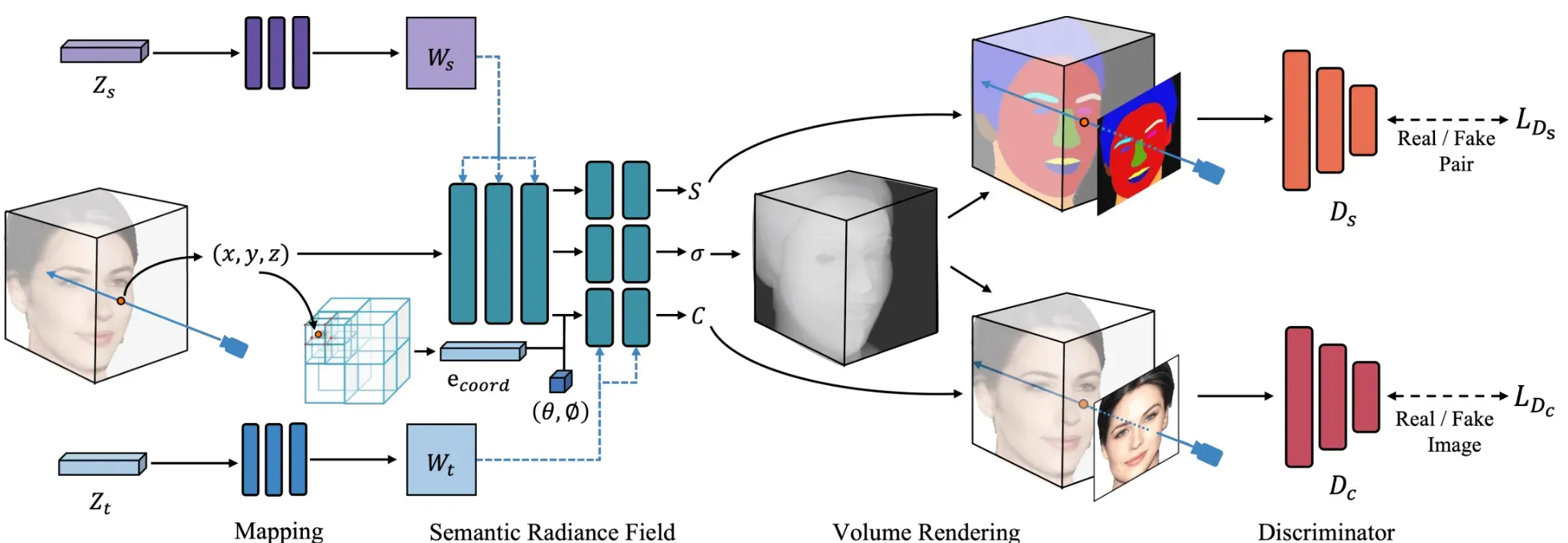
当前的生成性NeRF模型(如StyleNeRF、EG3D)能够从一组未定位的2D图像中建模具有简单几何体(如人脸、汽车)的场景,就像无条件GAN(如Stylgan)的训练一样。然而,当前生成的NERF在具有复杂几何变化的数据集上依然表现不佳,例如DeepFashion和ImageNet。一种可能的解决方案是提供场景的更多先验知识,例如,通过现成的重建模型获得先验场景几何,为生成性人体建模提供骨架先验。
五、🔅文档图像处理中的底层视觉
5.1、文档图像视觉技术难题——摩尔纹
底层视觉技术一直是计算机视觉领域的重要研究方向之一。现实中非常容易出现且难以解决的一个问题就是:摩尔纹,如下是一个非常常见的摩尔纹出现场景。

而在复杂环境下,摩尔纹图案的频率分布通常会变得非常复杂。这是因为在非均匀的接触表面上,摩尔纹的频率取决于表面形貌和压力分布的复杂度。在某些区域,摩尔纹可能会出现非常密集的频率分布,而在其他区域则可能很稀疏。
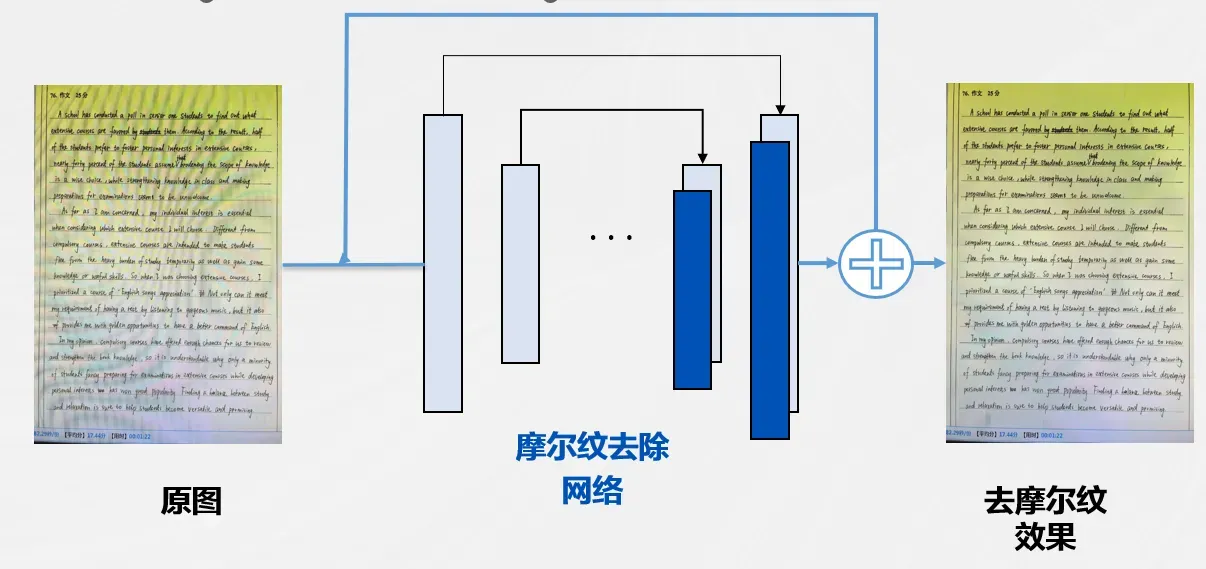
此外,摩尔纹图案的颜色通道大小也可能不平衡。由于干涉条纹的颜色通常是由光波长决定的,因此当接触表面在不同位置上的形貌和压力分布发生变化时,摩尔纹的颜色通道大小也会发生变化。这可能导致在某些区域中,摩尔纹的某些颜色通道比其他颜色通道更强,从而使摩尔纹的外观变得非常不平衡。因此,在解决摩尔纹问题时,需要综合考虑多种因素,以获得最佳的结果。
5.2、底层视觉技术
在这个领域,合合信息图像算法研发总监郭丰俊博士分享了他的研究成果。他指出,底层视觉技术在处理文档时,经常会遇到摩尔纹这类的一些典型问题,如形变、模糊、阴影遮盖、背景杂乱等。为了解决这些问题,合合信息技术团队一直致力于智能图像处理技术模块、融合技术典型应用、图像安全领域等领域的研究。

合合信息在智能文字识别、图像处理、自然语言处理(NLP)、知识图谱、大数据挖掘等技术研究上深耕多年。基于自主研发的领先的智能文字识别及商业大数据核心技术,还为全球C端用户和多元行业B端客户提供身份证、票据数字化、PS篡改检测、切边增强、曲面矫正、阴影处理、印章检测等智能图像处理产品及服务。
5.3、想法4:OCR+智能手写体试卷批改
OCR(Optical Character Recognition,光学字符识别)技术和智能手写体识别技术在试卷批改领域具有广阔的应用前景,传统的试卷批改需要老师手动阅卷、判分,费时费力且易出错。如果利用OCR和智能手写体识别技术可以自动识别试卷上的文字和手写内容,可以明显提高批改效率和准确性。但是与传统OCR不同,手写体的复杂度更高,且存在个体差异,因此需要更加先进的识别算法和更大的训练数据集,这也是一个可值得深究的方向。
最后
最后,除了听取合合信息图像算法研发总监郭丰俊博士的分享,我还有幸参观了合合信息的公司展厅。展厅里陈列着多个智能文档处理的应用案例,包括文档扫描、文字识别、图像矫正、鼎文识别等。这些应用案例非常吸引人,特别是当我亲眼看见文档扫描后的图像被瞬间矫正成为清晰、整齐的文本内容时,不禁感叹技术的奇妙。同时,展厅内的小姐姐热情地为我介绍了合合信息的丰富研究成果,以及合合信息在这一领域所做的研究工作。

作为一名观众,我深感震撼🙋。这些学者们不仅在自己的领域里深耕细作,而且还能够跨界探索,将不同领域的知识和技术融合,创造出更加出色的研究成果。可以说此次活动是一次知识盛宴,也是一次交流和学习的机会。
文章出处登录后可见!