


通过这篇博客,你将清晰的明白什么是过拟合、正则化、惩罚函数。这个专栏名为白话机器学习中数学学习笔记,主要是用来分享一下我在 机器学习中的学习笔记及一些感悟,也希望对你的学习有帮助哦!感兴趣的小伙伴欢迎私信或者评论区留言!这一篇就更新一下《 白话机器学习中的数学——过拟合、正则化与惩罚函数》
文章目录
一、过拟合
之前我们提到过的模型只能拟合训练数据的状态被称为过拟合,英文是 overfitting。记得在学习回归的时候,过度增加函数 fθ(x)的次数会导致过拟合。过拟合不止在回归时出现,在分类时也经常发生,我们要时常留意它。
避免过拟合有以下方法:
- 增加全部训练数据的数量
- 使用简单的模型
- 正则化
首先,重要的是增加全部训练数据的数量。之前我也讲过,机器学习是从数据中学习的,所以数据最重要。另外,使用更简单的模型也有助于防止过拟合。
二、正则化
2.1 正则化的方法
还记得我们在讲解回归的时候提到的目标函数吗?
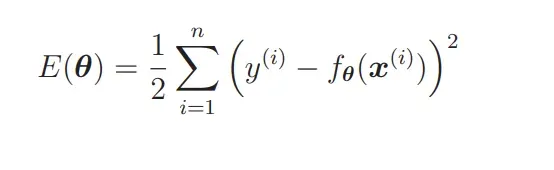
我们要向这个目标函数增加下面这样的正则化项:
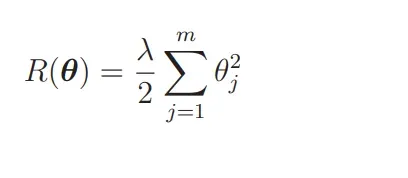
那么现在的
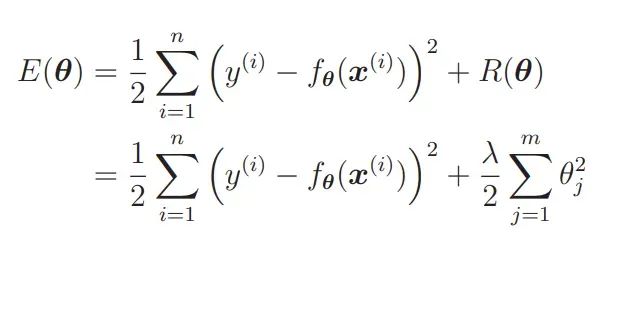




2.2 正则化的效果
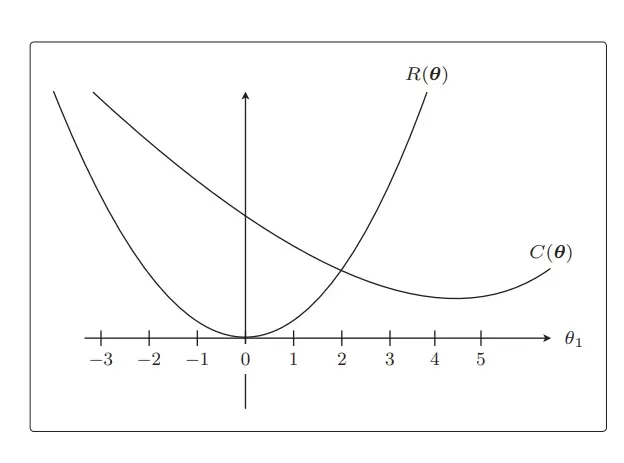
光看表达式可能不容易理解。我们结合图来想象一下吧:首先把目标函数分成两个部分。
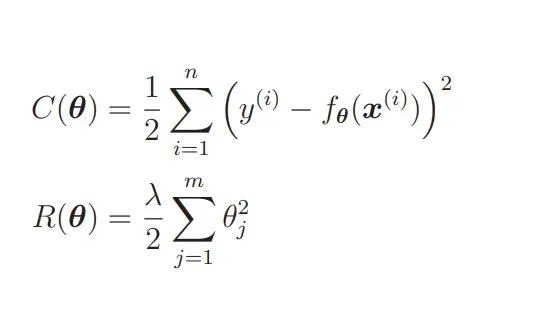
C(θ) 是本来就有的目标函数项,R(θ) 是正则化项。 C(θ) 和 R(θ) 相加之后就是新的目标函数,所以我们实际地把这两个函数的图形画出来,加起来看看。不过参数太多就画不出图来了,所以这里我们只关注 θ1。而且为了更加易懂,先不考虑 λ。
我们先从C(θ) 开始画起,不用太在意形状是否精确。在讲回归的时候,我们说过这个目
标函数开口向上,还记得吗?所以,我们假设它的形状是这样的:

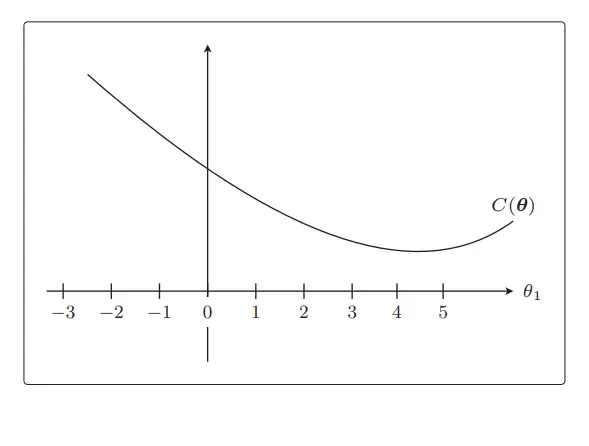
从图中马上就可以看出最小值在哪里,是在θ1 = 4.5 附近。
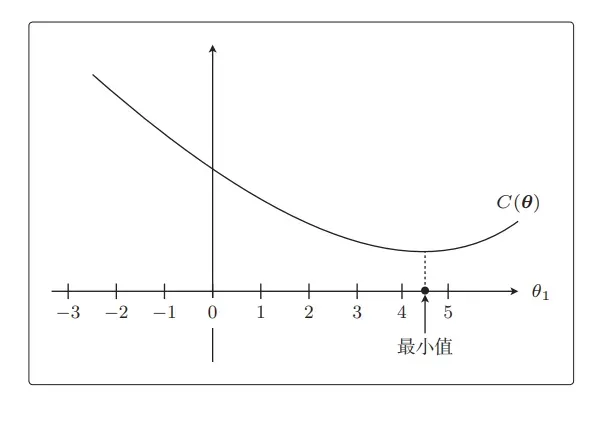
从这个目标函数在没有正则化项时的形状来看,θ1 = 4.5 附近是最小值。接下来是 R(θ),它就相当于




三、惩罚函数
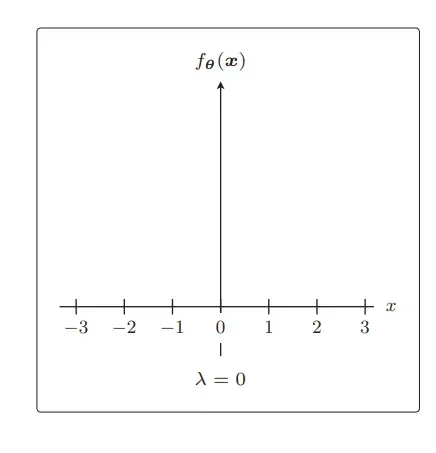
为了防止参数的影响过大,在训练时要对参数施加一些惩罚。比如上面提到的 λ,可以控制正则化惩罚的强度。
比如令 λ = 0,那就相当于不使用正则化


文章出处登录后可见!