简单介绍深度强化学习的基本概念,常见算法、流程及其分类(持续更新中),方便大家更好的理解、应用强化学习算法,更好地解决各自领域面临的前沿问题。欢迎大家留言讨论,共同进步。
(PS:如果仅关注算法实现,可直接阅读第3和4部分内容。)
1. 强化学习
Reinforcement Learning (RL):强化学习
强化学习属于机器学习的一种,不同于监督学习和无监督学习,通过智能体与环境的不断交互(即采取动作),进而获得奖励,从而不断优化自身动作策略,以期待最大化其长期收益(奖励之和)。强化学习特别适合序贯决策问题(涉及一系列有序的决策问题)。
在实际应用中,针对某些任务,我们往往无法给每个数据或者状态贴上准确的标签,但是能够知道或评估当前情况或数据是好还是坏,可以采用强化学习来处理。例如,下围棋(Go),星际争霸II(Starcraft II),等游戏。
1.1 强化学习的定义
Agent interacts with its surroundings known as the environment. Agent will get a reward from the environemnt once it takes an action in the current enrivonment. Meanwhile, the environment evolves to the next state. The goal of the agent is to maximize its total reward (the Return) in the long run.
智能体与环境的不断交互(即在给定状态采取动作),进而获得奖励,此时环境从一个状态转移到下一个状态。智能体通过不断优化自身动作策略,以期待最大化其长期回报或收益(奖励之和)。
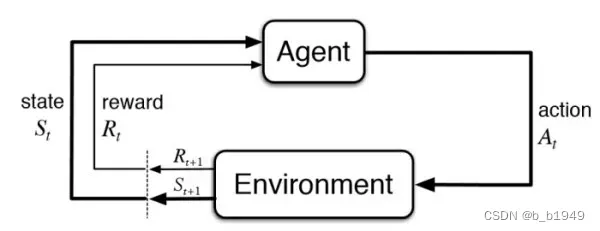
1.2 强化学习的相关概念
(1)状态 State (S): agent’s observation of its environment;
(2)动作 Action (A): the approaches that agent interacts with the environment;
(3)奖励 Reward ( ): the bonus that agent get once it takes an action in the environment at the given time step
.
回报(Return)为Agent所获得的奖励之和。
(4)转移概率 Transistion Probability ( P ): the transition possibility that environment evolves from one state to another.
环境从一个状态转移到另一个状态,可以是确定性转移过程,例如,,也可以是随机性转移过程,例如
。
(5)折扣因子 Discount factor ( ): to measure the importance of future reward to agent at the current state.
(6)轨迹(Trajectory)是一系列的状态、动作、和奖励,可以表述为:
用轨迹来记录Agent如何和环境交互。轨迹的初始状态是从起始状态分布中随机采样得到的。一条轨迹有时候也称为片段(Episode)或者回合,是一个从初始状态(Initial State,例如游戏的开局)到最终状态(Terminal State,如游戏中死亡或者胜利)的序列。
(7)探索-利用的折中(Exploration-Exploitation Tradeoff)
这里,探索是指Agent通过与环境的交互来获取更多的信息,而利用是指使用当前已知信息来使得Agent的表现达到最佳,例如,贪心(greedy)策略。同一时间,只能二者选一。因此,如何平衡探索和利用二者,以实现长期回报(Long-term Return)最大,是强化学习中非常重要的问题。
因此,可以用(S,A,P,R, )来描述强化学习过程。
1.3 强化学习的数学建模
(1)马尔可夫过程 (Markov Process,MP)是一个具备马尔可夫性质的离散随机过程。
马尔可夫性质是指下一状态 只取决于当前状态
.
可以用有限状态集合和状态转移矩阵
表示MP过程为
.
(2)马尔可夫奖励过程 (Markov Reward Process,MRP)
为了能够刻画环境对Agent的反馈奖励,马尔可夫奖励过程将上述MP从扩展到了
。这里,
表示奖励函数,而
表示奖励折扣因子。
回报(Return)是Agent在一个轨迹上的累计奖励。折扣化回报定义如下:
价值函数(Value Function)是Agent在状态
的期望回报(Expected Return)。
(3)马尔可夫决策过程 (Markov Decision Process,MDP)
MDP被广泛应用于经济、控制论、排队论、机器人、网络分析等诸多领域。
马尔可夫决策过程的立即奖励(Reward,)与状态和动作有关。MDP可以用
来刻画。
表示有限的动作集合,此时,立即奖励变为
策略(Policy)用来刻画Agent根据环境观测采取动作的方式。Policy是从一个状态和动作
到动作概率分布
的映射,
表示在状态
下,采取动作
的概率。
期望回报(Expected Return)是指在一个给定策略下所有可能轨迹的回报的期望值,可以表示为:
这里,表示给定初始状态分布布
和策略
,马尔可夫决策过程中一个
步长的轨迹
的发生概率,如下:
强化学习优化问题通关过优化方法来提升策略,以最大化期望回报。最优策略可以表示为
给定一个策略,价值函数
,即给定状态下的期望回报,可以表示为
在MDP中,给定一个动作,就有动作价值函数(Action-Value Function),是基于状态和动作的期望回报。其定义如下:
根据上述定义,可以得到:
2. 深度强化学习
Deep Learning + Reinforcement Learning = Deep Reinforcement Learning (DRL)
深度学习DL有很强的抽象和表示能力,特别适合建模RL中的值函数,例如:动作价值函数。
二者结合,极大地拓展了RL的应用范围。
3. 常见深度强化学习算法
深度强化学习的算法比较多,常见的有:DQN,DDPG,PPO,TRPO,A3C,SAC 等等。
(后续补充各个算法简要流程)
3.1 Deep Q-Networks (DQN)
DQN网路将Q-Learning和深度学习结合起来,并引入了两种新颖的技术来解决以往采用神经网络等非线性函数逼近器表示动作价值函数所产生的不稳定性问题:
技术:经验回放缓存(Replay Buffer):将Agent获得的经验存入缓存中,然后从该缓存中均匀采用(也可考虑基于优先级采样)小批量样本用于Q-Learning的更新;
技术:目标网络(Target Network):引入独立的网络,用来代替所需的Q网络来生成Q-Learning的目标,进一步提高神经网络稳定性。
这里,技术能够提高样本使用效率,降低样本间相关性,平滑学习过程;技术
能够是目标值不受最新参数的影响,大大较少发散和震荡。
通过在Atari 中多种游戏上进行测试,该DQN算法表现出了优异的性能。
DQN算法具体描述如下:
1. 超参数:回放缓存容量,奖励折扣因子
,目标网络更新延迟步长
;
2. 输入:回放缓存,初始化动作价值函数网络
、目标网络
$;
3. 初始化目标网络参数
:
;
4. for do
5. 初始化环境;
6. 初始化状态为
;
7. for
do
8. 以概率
选择一个随机动作
;否则,选择动作
;
9. 执行动作
得到奖励
,观察到下一个状态
;
10. 存储状态转移样本
到
;
11. 从缓存
中随机采样
个状态转移
;
12. 设置
;
13. 通过最小化损失函数更新网络
:
14.
;
15. 每
步,对目标网络
进行同步:
16.
;
17. end for
18. end for
注意:这里随机动作选择概率一般是随着迭代Episode和Time Step的增加,而逐渐降低,目的是降低随机策略的影响,逐步提高Q网络对Agent动作选择的影响。
该算法中,Line 14 具体更新方式如下:
其中,集合中为minibatch的
个
经验样本集合,
表示一次梯度迭代中的迭代步长。
参考文献:
[1] V. Mnih et al., “Human-level control through deep reinforcement learning,” Nature, vol. 518, no. 7540, pp. 529–533, Feb. 2015.
3.2 Deep Deterministic Policy Gradient(DDPG)
DDPG算法可以看作Deterministic Policy Gradient(DPG)算法和深度神经网络的结合,是对上述深度Q网络(DQN)在连续动作空间的扩展。
DDPG同时建立Q值函数(Critic)和策略函数(Actor)。这里,Critic与DQN相同,采用TD方法进行更新;而Actor利用Critic的估计,通过策略梯度方法进行更新。
DDPG算法具体描述如下:
1. 超参数:软更新因子 ,奖励折扣因子
;
2. 输入:回放缓存,初始化critic网络
、actor网络
、
3. 目标网络
、
;
4. 初始化目标网络参数
和
:
5.
,
;
6. for do
7. 初始化随机过程
,用于给动作添加探索;
8. 初始化状态为
;
9. for
do
10. 选择动作
;
11. 执行动作
得到奖励
,观察到下一个状态
;
12. 存储状态转移样本
到
;
13. 从缓存
中随机采样
个状态转移
;
14. 设置
;
15. 通过最小化损失函数更新Critic网络:
16. ;
13. 通过采样的策略梯度来更新Actor网络:
14.
;
15. 更新目标网络:
16.
,
17.
;
18. end for
19. end for
原论文中采用Ornstein-Uhlenbeck过程(O-U过程)作为添加噪声项,也可以采用时间不相关的零均值高斯噪声(相关实践表明,其效果也很好)。
参考文献:
[1] Lillicrap, Timothy P., et al. “Continuous control with deep reinforcement learning”,arXiv preprint, 2015, online: https://arxiv.org/pdf/1509.02971.pdf
3.3 Proximal Policy Optimization(PPO)
PPO算法是对信赖域策略优化算法(Trust Region Policy Optimization,TRPO)的一个改进,用一个更简单有效的方法来强制策略与
相似。
具体来说,TRPO中的优化问题如下:
而PPO算法直接优化上述问题的正则版本,即:
这里,为正则化系数,对应TRPO优化问题中的每一个
,都存在一个相应的
,使得上述两个优化问题有相同的解。然而,
的值依赖于
,因此,在PPO中,需要使用一个可动态调整的
。具体来说有两种方法:
(1)通过检验KL散度值来决定是增大还是减小,该版本的PPO算法称为PPO-Penalty;
(2)直接截断用于策略梯度的目标函数,从而得到更保守的更新,该方法称为PPO-Clip。
PPO-Clip算法具体描述如下:
1. 超参数:截断因子,子迭代次数
;
2. 输入:初始化策略参数 、初始价值参数
;
3. for do
4. 在环境中执行策略
,并保存轨迹集
;
5. 计算将得到的奖励
;
6. 基于当前的价值函数
,计算优势函数
(使用任何估计优势的方法);
7. for
do
8.
;
9. 采用Adam随机梯度上升算法最大化PPO-Clip的目标函数来更新策略:
10.
;
11. end for
12. for
do
13. 采用梯度下降法最小化均方误差来学习价值函数:
14.
;
15. end for
16. end for
其中,
这里,表示将
截断在
中。
参考文献:
[1] Schulman, J. , et al. “Proximal Policy Optimization Algorithms”,arXiv preprint, 2017, online: https://arxiv.org/pdf/1707.06347.pdf
[2] Schulman J, Levine S, Abbeel P, et al. “Trust region policy optimization”, International conference on machine learning. PMLR, 2015: 1889-1897, online: http://proceedings.mlr.press/v37/schulman15.pdf
4. 深度强化学习算法分类
深度强化学习算法的分类标准很多,常见的分类方式和具体类别概述如下:
4.1 根据Agent训练与测试所采用的策略是否一致
4.1.1 off-policy (离轨策略、离线策略)
Agent在训练(产生数据)时所使用的策略 与 agent测试(方法评估与提升)时所用的策略
不一致。
例如,在DQN算法中,训练时,通常采用策略;而在测试性能或者实际使用时,采用
策略。
常见算法有:DDPG,TD3,Q-learning,DQN等。
4.1.2 on-policy (同轨策略、在线策略)
Agent在训练时(产生数据)所使用的策略与其测试(方法评估与提升)时使用的策略为同一个策略。
常见算法有:Sarsa,Policy Gradient,TRPO,PPO,A3C等。
4.2 策略优化的方式不同
4.2.1 Value-based algorithms(基于价值的算法)
基于价值的方法通常意味着对动作价值函数的优化,最优策略通过选取该函数
最大值所对应的动作,即
,这里,
由函数近似误差导致。
基于价值的算法具有采样效率相对较高,值函数估计方差小,不易陷入局部最优等优点,缺点是通常不能处理连续动作空间问题,最终策略通常为确定性策略。
常见算法有 Q-learning,DQN,Double DQN,等,适用于 Discrete action space。其中,DQN算法是基于state-action function 来进行选择最优action的。
4.2.2 Policy-based algorithms(基于策略的算法)
基于策略的方法直接对策略进行优化,通关对策略迭代更新,实现累计奖励(回报)最大化。其具有策略参数化简单、收敛速度快的优点,而且适用于连续或者高维动作空间。
策略梯度方法(Policy Gradient Method,PGM)是一类直接针对期望回报通过梯度下降(Gradient Descent,针对最小化问题)进行策略优化的强化学习方法。其不需要在动作空间中求解价值最大化的优化问题,从而比较适用于 continuous and high-Dimension action space,也可以自然地对随机策略进行建模。
PGM方法通过梯度上升的方法直接在神经网络的参数上优化Agent的策略。
根据相关理论,期望回报关于参数
的梯度可以表示为:
当时,上式可以表示为:
在实际中,经常去掉,从而避免过分强调轨迹早期状态的问题。
上述方法往往对梯度的估计有较大的方法(奖励的随机性可能对轨迹长度L呈指数级增长)。为此,常用的方法是引进一个基准函数
,仅是状态
的函数。可将上述梯度修改为:
常见的PGM算法有REINFORCE,PG,PPO,TRPO 等。
4.2.3 Actor-Critic algorithms (演员-评论家方法)
Actor-Critic方法结合了上述基于价值的方法和基于策略的方法,利用基于价值的方法学习Q值函数或状态价值函数V来提高采样效率(Critic),并利用基于策略的方法学习策略函数(Actor),从而适用于连续或高维动作空间。其缺点也继承了二者的缺点,例如,Critic存在过估计问题,而Actor存在探索不足的问题等。
常见算法有 DDPG, A3C,TD3,SAC,等,适用于 continuous and high-Dimension action space,
4.3 参数更新的方式不同
Parameters updating methods
4.3.1 Monte Carlo method(蒙特卡罗方法)
蒙特卡罗方法:必须等待一条轨迹生成(真实值)后才能更新。
常见算法有:Policy Gradient,TRPO,PPO等。
4.3.2 Temporal Difference method(时间差分方法)
时间差分方法:在每一步动作执行都可以通过自举法(Bootstrapping)(估计值)及时更新。
常见算法有:DDPG,Q-learning,DQN等。
文章出处登录后可见!