入门小菜鸟,希望像做笔记记录自己学的东西,也希望能帮助到同样入门的人,更希望大佬们帮忙纠错啦~侵权立删。
✨完整代码在我的github上,有需要的朋友可以康康✨
https://github.com/tt-s-t/Deep-Learning.git
目录
一、GoogLeNet网络的背景
二、GooLeNet网络结构
1、Inception模块
2、辅助分类器
3、GooLeNet网络
三、GooLeNet的亮点
1、引入Inception结构
2、使用1×1的卷积核进行降维映射处理
3、添加两个辅助分类器帮助训练
4、使用全局平均池化
5、1*n和n*1卷积核并联代替n*n卷积核
四、GooLeNet代码实现
一、GoogLeNet网络的背景
想要更好的预测效果,就要从网络深度和网络宽度两个角度出发增加网络的复杂度。
但这个思路有两个较为明显的问题:
首先,更复杂的网络意味着更多的参数,也很容易过拟合;
其次,更复杂的网络会消耗更多的计算资源,而且卷积核个数设计不合理,导致了卷积核中参数没有被完全利用(多数权重都趋近0)时,会造成大量计算资源的浪费。
因此GoogLeNet在专注于加深网络结构的同时,引入了新的基本结构——Inception模块,以增加网络的宽度。GoogLeNet一共22层,没有全连接层,在2014年的ImageNet图像识别挑战赛中获得了冠军。
二、GooLeNet网络结构
1、Inception模块
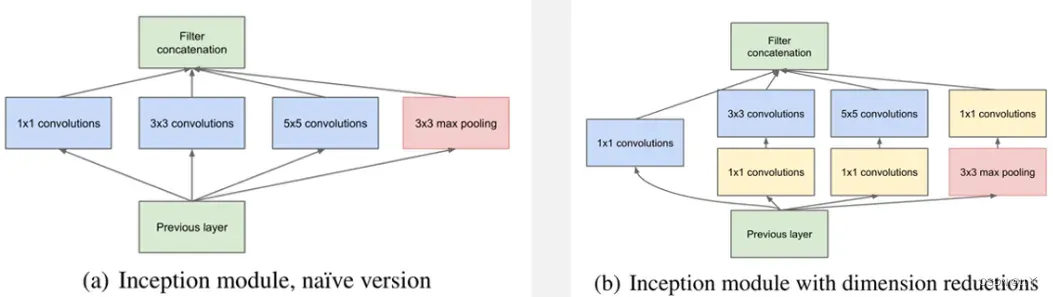
Inception模块的基本组成结构有四个:1×1卷积,3×3卷积,5×5卷积,3×3最大池化。
最后再对四个成分运算结果进行通道上组合。
这就是Naive Inception(上图a)的核心思想:利用不同大小的卷积核实现不同尺度的感知,最后进行融合,可以得到图像更好的表征(即探索特征图上不同邻域内的“相关性”)。
Note:每个分支得到的特征矩阵高和宽必须相同。
但Naive Inception有两个缺点:
(1)所有卷积层直接和前一层输入的数据对接,所以卷积层中的计算量会很大(一变四);
(2)在这个单元中使用的最大池化层保留了输入数据的特征图的深度,所以在最后进行合并后总输出的特征图的深度一定会增加,这样增加了该单元之后的网络结构的计算量。
所以多加使用了1×1 卷积核主要目的是进行压缩降维,减少参数量(即上图b),从而让网络更深、更宽,更好的提取特征,这种思想也称为Pointwise Conv(逐点卷积),简称PW。
压缩降维:通过卷积层的输出通道数来调整这很好理解;
减少参数量:假设输入通道数为Cin,原本是直接要使用输出通道数为Cout的N*N卷积层来进行卷积,那么所需参数量为Cin*Cout*N*N;如果加上输出通道数为k的1*1卷积核的话,所需参数量为:Cin*k+N*N*Cout*k,只要k足够小就能使参数量大幅度下降了。
2、辅助分类器
因为神经网络的中间层也具有很强的识别能力,因此GooLeNet在一些中间层中添加了含有多层的分类器。
GoogLeNet中共增加了两个辅助的softmax分支。
网络结构如下图所示(其中的红圈圈就是辅助的分类器)
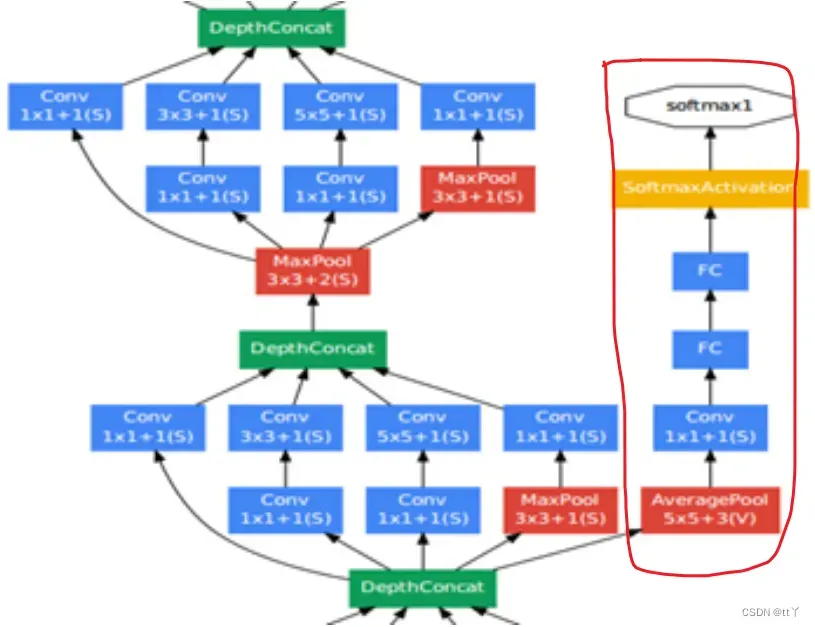
作用:
(1)为了避免梯度消失,用于向前传导梯度(反向传播时如果有一层求导为0,链式求导结果则为0)—— 最主要的原因;
(2)将中间某一层输出用作分类,起到模型融合作用(最终的分类结果以及这两个辅助分类器的结果(辅助分类按一个较小的权重加到最终分类结果中)一同决判出最终训练得到的分类结果)。但实际测试时,这两个辅助softmax分支会被去掉(因为辅助的主要原因是为了向前传导梯度,因此训练完后就没有价值了,理应扔掉)。
(3)正则化作用:
在后续的研究中,Google团队研究人员发现辅助分类器在训练早期并没有改善收敛:在两个模型达到高精度之前,两种网络的训练进度看起来几乎相同;接近训练结束,有辅助分支的网络才开始超越没有任何分支的网络的准确性,达到了更高的稳定水平,因此辅助分类器更多的还是起到了一个正则化的作用(防止过拟合)。
3、GooLeNet网络
这是最初GooLeNet论文中展示的网络参数

以下展示的是torchvision.models.GoogLeNet()的网络结构:
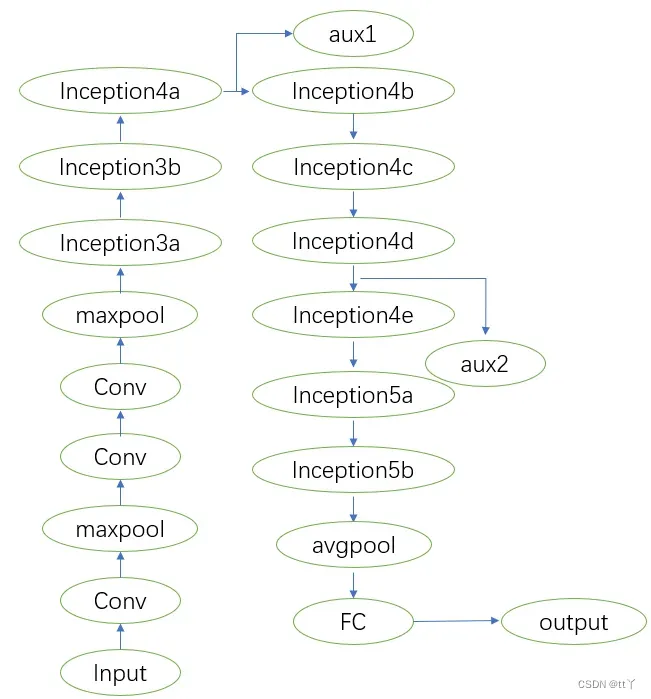
其中Inception发生变化,将5*5卷积核部分也替换成了3*3卷积。
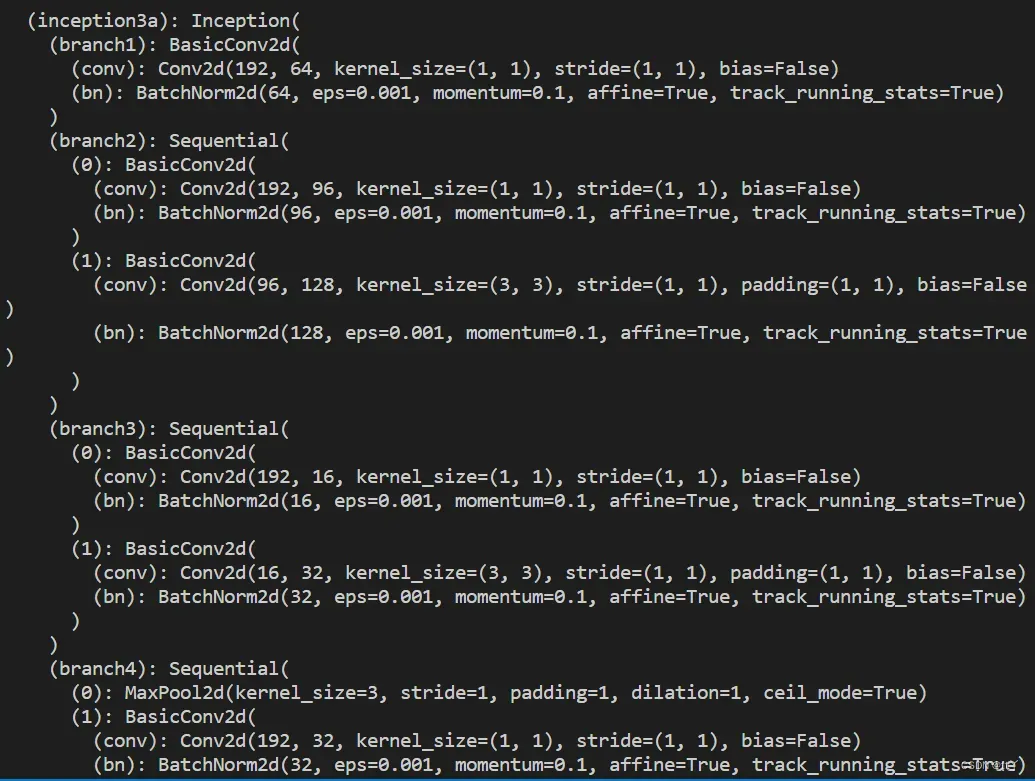
以下展示Inception3a:
![]()
三、GooLeNet的亮点
1、引入Inception结构
引入的Inception融合了不同尺度的特征信息,能得到更好的特征表征。
更意味着提高准确率,不一定需要堆叠更深的层或者增加神经元个数等,可以转向研究更稀疏但是更精密的结构同样可以达到很好的效果。
2、使用1×1的卷积核进行降维映射处理
降低了维度也减少了参数量(NiN是用于代替全连接层)。
3、添加两个辅助分类器帮助训练
避免梯度消失,用于向前传导梯度,也有一定的正则化效果,防止过拟合。
4、使用全局平均池化
用全局平均池化代替全连接层大大减少了参数量(与NiN一致)
5、1*n和n*1卷积核并联代替n*n卷积核
在InceptionV3中,在不改变感受野同时减少参数的情况下,采用1*n和n*1的卷积核并联来代替InceptionV1-V2中n*n的卷积核(发掘特征图的高的特征,以及特征图的宽的特征)。
这种方法在大维度的特征图上表现不好,在特征图12-20维度上表现好,若这种叠加的不对称分解卷积走高维路线,则更易训练(深层网络适合)。
降低了计算量和减少了参数量。
四、GooLeNet代码实现
完整代码可以在我的github上看https://github.com/tt-s-t/Deep-Learning.git
在里面的GooLeNet文件夹中,分有调用torchvision.module.goolenet()实现的和自行搭建实现的
这里展示模型搭建代码
import torch
import torch.nn as nn
import torch.nn.functional as F
#conv+ReLU
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
#前部
class Front(nn.Module):
def __init__(self):
super(Front, self).__init__()
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2,ceil_mode=True)
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2,ceil_mode=True)
def forward(self,input):
#输入:(N,3,224,224)
x = self.conv1(input)#(N,64,112,112)
x = self.maxpool1(x)#(N,64,56,56)
x = self.conv2(x)#(N,64,56,56)
x = self.conv3(x)#(N,192,56,56)
x = self.maxpool2(x)#(N,192,28,28)
return x
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3_1_1, ch3x3_1, ch3x3_2_1, ch3x3_2, pool_ch):
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3_1_1, kernel_size=1),
BasicConv2d(ch3x3_1_1, ch3x3_1, kernel_size=3, padding=1)
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch3x3_2_1, kernel_size=1),
BasicConv2d(ch3x3_2_1, ch3x3_2, kernel_size=3, padding=1)
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_ch, kernel_size=1)
)
def forward(self, x):
#输入(N,Cin,Hin,Win)
branch1 = self.branch1(x)#(N,C1,Hin,Win)
branch2 = self.branch2(x)#(N,C2,Hin,Win)
branch3 = self.branch3(x)#(N,C3,Hin,Win)
branch4 = self.branch4(x)#(N,C4,Hin,Win)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1)#(N,C1+C2+C3+C4,Hin,Win)
#辅助分类器
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = BasicConv2d(in_channels, 128, kernel_size=1)
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x):
# 输入:aux1:(N,512,14,14), aux2: (N,528,14,14)
x = self.averagePool(x)# aux1:(N,512,4,4), aux2: (N,528,4,4)
x = self.conv(x)# (N,128,4,4)
x = torch.flatten(x, 1)# (N,2048)
x = F.dropout(x, 0.5, training=self.training)
x = F.relu(self.fc1(x))# (N,1024)
x = F.dropout(x, 0.5, training=self.training)
x = self.fc2(x)# (N,num_classes)
return x
# GooLeNet网络主体
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000, aux_logits=True):
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits
self.front = Front()
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2,ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(3, stride=2,ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(1024, num_classes)
def forward(self, x):
#输入:(N,3,224,224)
x = self.front(x)#(N,192,28,28)
x = self.inception3a(x)#(N,256,28,28)
x = self.inception3b(x)#(N,480,28,28)
x = self.maxpool3(x)#(N,480,14,14)
x = self.inception4a(x)#(N,512,14,14)
if self.training and self.aux_logits:
aux1 = self.aux1(x)
x = self.inception4b(x)#(N,512,14,14)
x = self.inception4c(x)#(N,512,14,14)
x = self.inception4d(x)#(N,528,14,14)
if self.training and self.aux_logits:
aux2 = self.aux2(x)
x = self.inception4e(x)#(N,832,14,14)
x = self.maxpool4(x)#(N,832,7,7)
x = self.inception5a(x)#(N,832,7,7)
x = self.inception5b(x)#(N,1024,7,7)
x = self.avgpool(x)#(N,1024,1,1)
x = torch.flatten(x, 1)#(N,1024)
x = self.dropout(x)
x = self.fc(x)#(N,num_classes)
if self.training and self.aux_logits:
return x, aux2, aux1
return x欢迎大家在评论区批评指正,谢谢~
文章出处登录后可见!