欢迎关注【youcans的GPT学习笔记】原创作品,火热更新中
微软 GPT-4 测试报告(1)总体介绍
微软 GPT-4 测试报告(2)多模态与跨学科能力
微软 GPT-4 测试报告(3)GPT4 的编程能力
【GPT4】微软 GPT-4 测试报告(3)GPT4 的编程能力
- 3. 代码生成(Coding)
- 3.1 从指令到代码(From instructions to code)
- 3.1.1 编程的挑战(Coding challenges)
- 3.1.2 真实的编程场景(Real world scenarios)
- 3.2 理解现有的代码(Understanding existing code)
- 3.2.1 逆向工程汇编代码
- 3.2.2 代码执行的推理
- 3.2.3 执行Python代码
- 3.2.4 执行伪代码
微软研究院最新发布的论文 「 人工智能的火花:GPT-4 的早期实验 」 ,公布了对 GPT-4 进行的全面测试,结论是:GPT-4 可以被视为 通用人工智能(AGI)的早期版本。
本文介绍第三部分:GPT4 的编程能力。前两部分参见:
微软 GPT-4 测试报告(1)总体介绍
微软 GPT-4 测试报告(2)多模态与跨学科
3. 代码生成(Coding)
在本节中,我们展示了 GPT-4 能够以非常高的水平编程,无论是根据指令编写代码还是理解现有代码。
-
GPT-4 可以处理广泛的编程任务,从编程挑战到现实世界的应用,从低级汇编到高级框架,从简单的数据结构到复杂的程序,如游戏。
-
GPT-4 还可以对代码执行进行推理,模拟指令的效果,并用自然语言解释结果。
-
GPT-4 甚至可以执行伪代码,这需要解释在任何编程语言中都无效的非正式和模糊的表达。
根据目前的情况,我们认为 GPT-4 在编写只依赖于现有公共库的特定程序方面具有很高的熟练度,这与普通软件工程师的能力相仿。
更重要的是,它可以同时为工程师和非熟练用户赋能,因为它使编写、编辑和理解程序变得容易。
我们也承认,GPT-4 在编码方面还不完美,因为它有时会产生语法无效或语义不正确的代码,特别是对于更长或更复杂的程序。GPT-4 有时也无法理解或遵循指令,或产生与预期功能或风格不匹配的代码。在认识到这一点后,我们还指出,GPT-4 能够通过与人类的提示或编译/运行程序时的错误提示来改进其代码 (例如,3.2节中迭代地细化绘图,和 5.1节中的例子)。
重要声明:如引言中所述,我们的实验是在 GPT-4 的早期版本上运行的。在 GPT-4 的最终版本上,总体趋势保持不变,但所有定量结果都会有所不同。我们在这里提供的数字仅供参考,详细结果参见 OpenAI 的技术报告。
3.1 从指令到代码(From instructions to code)
3.1.1 编程的挑战(Coding challenges)
衡量编码能力的一种常见方法是提出需要实现特定功能或算法的编码挑战。
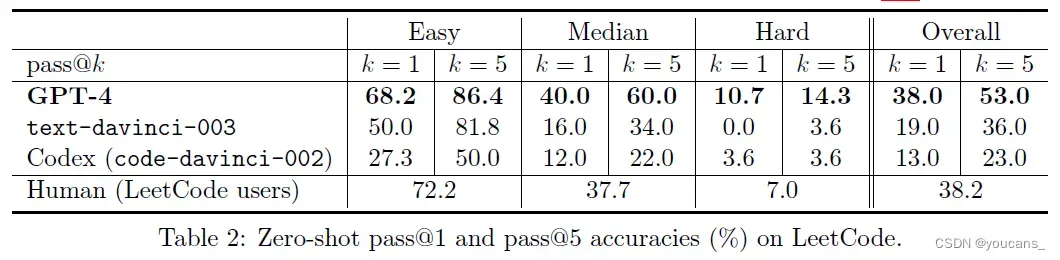
我们首先在HumanEval 上对 GPT-4 进行基准测试,该数据集由 164 个编码问题组成,测试了编程逻辑和熟练程度的各个方面。如表1 所示,GPT-4 的表现优于其他 LLMs,包括 text-davincit-003 (ChatGPT的基础模型) 和其他专门在code、code-davinci-002 和 CODEGEN-16B [NPH+22]上训练的模型。
| Model | GPT-4 | text-davinci-003 | Codex(code-davinci-002) | CODEGEN-16B |
|---|---|---|---|---|
| Accuracy | 82% | 65% | 39% | 30% |
虽然与之前的模型相比,GPT-4 的准确性有了很大的提高,但这可能是因为 GPT-4 在预训练期间看到并记忆了部分(或全部)人类评估。
为了考虑到这种可能性,我们还在LeetCode上对其进行了评估,这是一个很受欢迎的软件工程面试平台,在这个平台上不断发布和更新新的问题。我们在介绍中使用了图1.5 中的 LeetCode,GPT-4 通过了各大科技公司模拟面试的所有阶段。
我们构建了一个测试基准,包含 2022年10月8日之后发布的 100个 LeetCode 问题,这是在 GPT-4 的预训练期之后新出的问题。如图3.1中的示例所示,我们将问题说明粘贴到提示符中,让 GPT-4 编写一个 python 函数,并使用官方的 LeetCode online judge 来检查正确性。在表2中展示了结果,我们根据 LeetCode 竞赛结果将 GPT-4 与其他模型以及人类的表现进行了比较(所有问题都失败的用户不包括在内)。我们报告了pass@1和pass@5准确率,分别衡量了模型在第一次或前五次尝试中是否产生了正确的解决方案。GPT-4 的表现明显优于其他模型,并与人类的表现相媲美(我们在附录C.1中测量)。

下面是 GPT-4 使用动态规划解决 LeetCode 问题的例子。由于全面的注释,GPT-4 的解决方案也具有更好的可读性。
class Solution(object):
def numberOfPaths(self, grid, k):
"""
:type grid: List[List[int]]
:type k: int
:rtype: int
"""
# Define MOD as 10**9 + 7
MOD = 10**9 + 7
# Get the dimensions of the grid
m = len(grid)
n = len(grid[0])
# Initialize a 3D dp array with all zeros
# dp[i][j][value] represents the number of paths where the sum of the elements on the path has a remainder of value when divided by k
dp = [[[0] * k for _ in range(n)] for _ in range(m)]
# Base case: the first cell has only one path and its value is grid[0][0] % k
dp[0][0][grid[0][0] % k] = 1
# Loop through the grid
for i in range(m):
for j in range(n):
# Skip the first cell
if i == 0 and j == 0:
continue
# Loop through all possible remainders
for value in range(k):
# The number of paths to the current cell with the current remainder is equal to the sum of:
# - The number of paths to the top cell with the previous remainder
# - The number of paths to the left cell with the previous remainder
# The previous remainder is equal to the current remainder minus the current value, plus k if it is negative
prev = (value - grid[i][j]) % k
if i > 0:
dp[i][j][value] += dp[i - 1][j][prev]
if j > 0:
dp[i][j][value] += dp[i][j - 1][prev]
# Take the modulo to avoid overflow
dp[i][j][value] %= MOD
# Return the number of paths to the bottom right cell with a remainder of 0
return dp[m - 1][n - 1][0]
3.1.2 真实的编程场景(Real world scenarios)
编程挑战可以评估算法和数据结构的技能。然而,它们往往无法捕捉到现实世界编程任务的全部复杂性和多样性,这需要专业的领域知识、创造力,以及对多个组件和库的集成,以及更改现有代码的能力。
为了评估 GPT-4 在真实环境下的编程能力,我们设计了端到端的真实的编程挑战,这些挑战与数据可视化、LATEX编程、前端开发和深度学习相关,每一项都需要不同的专业技能。
对于每一个任务,我们都要求 GPT-4 用合适的语言和框架编写代码编写。在少数情况下,我们还会在代码编写完后更改涉及规范,并要求 GPT-4 进行更新。
数据可视化
在图3.2中,我们要求 GPT-4 和 ChatGPT 从表2的 LATEX 代码中提取数据,并根据与用户的对话在 Python 中生成一个图。之后,我们要求这两个模型对生成的图执行各种操作。虽然两个模型都正确地提取了数据(这不是一个容易的任务,因为必须从多列中推断出),但ChatGPT始终没能产生符合要求的绘图。相比之下,GPT-4 会恰当地响应所有用户请求,将数据处理为正确的格式,并调整可视化。在附录C.2中,我们包含了另一个GPT-4可视化 IMDb数据集的例子。
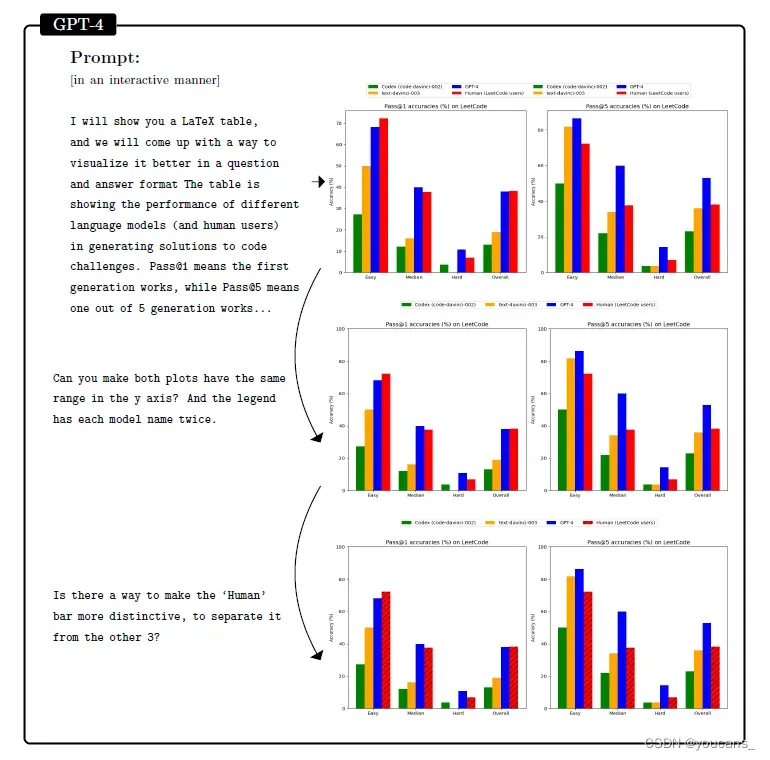
如图所示,GPT-4 将LATEX表(即表2)中的数据可视化。GPT-4还生成了这个图的格式。我们询问了模型如何在LATEX中绘制箭头连接图形,GPT-4用我们在这里采用的布局和箭头生成了一个工作的 Tikz 片段。
前端/游戏开发
在图3.3中,我们要求 GPT-4 用JavaScript在HTML中写一个3D游戏,使用非常高级的规范。
GPT-4以零样本的方式生成一个符合所有要求的工作游戏。在3D游戏中,GPT-4甚至能够解读“防御者化身正在试图阻挡敌人”的含义:防御者代码具有逻辑,因此它将自己定位在玩家和敌人之间。相比之下,ChatGPT的回应则是“我是一个AI语言模型,我可以为你提供如何用JavaScript在HTML中创建3D游戏的指导,但我自己不会写代码或创建游戏。用JavaScript在HTML中创建3D游戏,需要大量的编程知识和经验。这不是一项可以快速或轻松完成的任务。它需要大量的时间和精力来开发所有必要的功能,如3D图形、物理、用户输入和AI……”。我们在附录C中给出了更多关于前端(图形用户界面)和游戏开发的例子。

如图3.3 所示, GPT-4 用 JavaScript开发了一个复杂的3D HTML游戏。
深度学习
编写深度学习的代码需要数学、统计学的知识,并且熟悉PyTorch、TensorFlow、Keras 等框架和库。
在图3.4中,我们要求 GPT-4 和 ChatGPT 编写一个自定义优化器模块,这是一项即使对人类的深度学习专家来说也可能具有挑战性的而且容易出错的任务。我们给这些模型一个自然语言描述,其中包括一系列特殊操作,例如应用 SVD,在 top-k 和 top-2k 特征值处对矩阵进行频谱截断,使用top-2k截断矩阵的 F-norm 范数对top-k截断矩阵进行归一化,应用动量和权重衰减。这些指令并没有完整的详细说明,例如,“在Gk上应用动量”需要“深度学习常识”。需要注意的是,这个特定的优化器在文献或互联网上并不存在,因此模型无法记住它,必须正确地组合概念才能产生代码。
虽然两种模型都能生成语法上有效的代码,但只有GPT-4 的代码在语义上是正确的,并且与指令匹配。相比之下,ChatGPT在应用动量(用红色突出显示)时犯了一个错误,这是一个非常复杂的任务,需要将移动平均值存储到一个单独的状态缓冲区中并从中读取。

GPT-4 生成的深度学习代码:
def step(self):
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
grad = p.grad.data
# reshape grad to 2D
grad_2d = grad.reshape(-1, group['d_dim'])
# SVD decomposition
U, S, V = torch.svd(grad_2d)
# keep top k singular vectors
G_k = U[:, :group['k']] @ torch.diag(S[:group['k']]) @
V[:, :group['k']].T
# keep top 2k singular vectors
G_2k = U[:, :2*group['k']] @ torch.diag(S[:2*group['k']]) @ V[:, :2*group['k']].T
# normalize G_k
G_k /= torch.norm(G_2k, p=2)
# truncate G_k
threshold = torch.quantile(torch.abs(G_k),
group['alpha'])
G_k[torch.abs(G_k) < threshold] = 0
# apply momentum
if 'momentum_buffer' not in group:
group['momentum_buffer'] = torch.zeros_like(G_k)
group['momentum_buffer'] = group['momentum'] * group['momentum_buffer'] + G_k
# update parameters
p.data.add_(-group['lr'] * group['momentum_buffer'])
# apply weight decay
if group['weight_decay'] != 0:
p.data.add_(-group['weight_decay'] * group['lr'],p.data)
LATEX 接口
用 LATEX 书写对于计算机科学家和数学家来说是一项重要的练习,但它的学习曲线并不平坦。它的语法严格,而且没有一个好的调试器,即使是专家也会犯恼人的错误,要花好几个小时才能解决。
GPT-4 可以利用它的大师级别的 LATEX编码技巧,这大大简化了过程,具有作为新一代LATEX编译器的潜力,可以处理不精确的自然语言描述。在图3.5中,我们要求GPT-4将一段用混合了自然语言的半严格(有bug)的LATEX代码编写的代码片段转换为精确的LATEX命令,可以一次性编译并忠实于要求。相比之下,ChatGPT生成的代码片段会因为使用#和\color等错误而无法编译。

如图3.5所示,GPT-4 将半严格的排版指令翻译成可运行的 LATEX 片段。对于GPT-4,我们呈现了最终的图形,而ChatGPT生成的结果编译时发生错误。
3.2 理解现有的代码(Understanding existing code)
前面的例子已经表明,GPT-4 可以从指令中编写代码,即使指令是模糊的,不完整的,或需要领域知识。它
们还表明,GPT-4可以响应后续请求,根据指令修改自己的代码。
然而,编码的另一个重要方面是理解和推理他人编写的现有代码的能力,这些代码可能是复杂的,晦涩的,或记录不佳的。为了测试这一点,我们提出了各种问题,这些问题需要阅读、解释或执行不同语言和范式编写的代码。
3.2.1 逆向工程汇编代码
逆向工程是软件安全性的一项基本测试,它相当于在以机器可读(即二进制)表示的 CPU 指令的可执行程序中搜索有用信息。这是一项具有挑战性的任务,需要理解汇编语言的语法、语义和约定,以及处理器和操作系统的体系结构和行为。
我们让GPT-4对一个二进制可执行文件(代码是用C编写的)执行渗透测试,该文件需要密码才能运行。我们通过一种聊天格式来做到这一点,GPT-4告诉用户要运行哪些命令,用户用结果来响应。我们还在5.1节中展示了GPT-4能够独立运行shell,但这种聊天模式也提供了它解释每个步骤的好处。
GPT-4检查文件格式和元数据,用“objdump”和“radare2”等工具对代码进行反汇编,用“gdb”和“ltrace”调试代码,用打补丁、挂接、反编译等技术对其进行逆向工程。在这个过程中,GPT-4从汇编代码中计算出密码与从一个简单的数学公式推导出的哈希值进行比较。然后,GPT-4编写一个python程序,尝试不同的数字组合,直到找到与哈希值匹配的数字组合,从而破解密码(附录C.6给出了一个简短的日志)。
ChatGPT拒绝这样做,理由是这样做是非法的和不道德的,即使逆向工程是一种确保软件安全的常见做法。
此外,除了编程之外,GPT-4在利用现有工具方面也表现出了全面的熟练程度,我们将在5.1节中详细讨论。
3.2.2 代码执行的推理
在图3.6的例子中,我们让 GPT-4 和 ChatGPT 预测并解释打印两个 structure的大小的 C程序的输出。GPT-4正确地解释了根据编译器使用的对齐规则,输出可能会有所不同,并给出了一个使用 4字节对齐的可能输出示例。
ChatGPT忽略了对齐问题,给出了错误的输出,还对不影响结构大小的成员顺序做出了错误的陈述。
GPT-4 对这段代码的解释如下:
在内存中实现和对齐结构的方式有所不同,因此确切的输出可能会因编译器、平台和使用的选项而异。然而,可能的一种输出是:
Size of x: 12 bytes
Size of y: 8 bytes
此输出假设编译器对结构使用4字节对齐方式,这意味着每个结构成员从结构的开头开始的偏移量是4字节的倍数。这可能会导致一些填充字节在成员之间或之后插入以保持对齐。例如,在x中,a之后可能会有3个填充字节,c之后也可能会有3个填充字节,而在y中可能根本没有填充。结构的大小是其成员大小和任何填充字节的总和。
ChatGPT 对这段代码的解释如下:
Size of x: 8 bytes Size of y: 8 bytes
这段代码的输出将是两个结构体的大小,以字节为单位。在C语言中,结构体的大小是其所有成员大小的总和。在这种情况下,mystruct A 的大小为一个char 的大小加上一个int 的大小再加上另一个char 的大小,即1 + 4 + 1 = 8 字节。
同样,mystruct B 的大小也是8 字节。这意味着两个结构体将被分配相同数量的内存。请注意,在结构体中声明成员的顺序不会影响其大小。

3.2.3 执行Python代码
理解现有代码的最终测试是要求模型直接执行它。
在图3.7中,我们看到 GPT-4 能够执行并不简单的 Python代码。它必须跟踪几个变量(包括一个嵌套循环和一个字典)并处理递归。它通过编写中间步骤和注释来详细解释执行过程。
需要注意的是,GPT-4并不是在Python解释器上运行代码,而是用自然语言模拟代码。这需要对代码有高度的理解和推理能力,以及清楚地传达结果的能力。
相比之下,ChatGPT 错误地声明 “DP(3,4)的结果没有在给定的代码中指定”,随后又说“从代码中无法明确函数的预期输出是什么,因为没有提供函数正在解决的具体问题。” ChatGPT并没有模拟完整的执行过程,而是说明了哪些函数会被调用。
输入的 Python 代码如下。
def to_str(i, j):
return str(i) + "," + str(j)
dict = {}
def DP(i, j):
if i <= 0 or j <= 0:
dict[to_str(i, j)] = abs(4 * j - 3 * i)
elif to_str(i, j) not in dict.keys():
arr = []
for ir in range(i):
for jr in range(j):
arr.append(DP(ir, jr))
dict[to_str(i, j)] = max(arr)
return dict[to_str(i, j)]

3.2.4 执行伪代码
编译和执行用编程语言编写的代码很容易,但这也要求严格遵守语法和语义。编译器无法处理模糊或非正式的表达,或自然语言对功能的描述。
相比之下,我们要求GPT-4执行图3.8中复杂的伪代码,注意到它能够执行并解释每一步(包括递归)。ChatGPT是不能执行的,尽管它看起来能够解释每一行代码。在下面的例子中,GPT-4正确地解释了合并数组函数(merge array function)的非正式描述,该函数将两个数组合并为一个包含缺失元素的数组。它还理解了以粗略方式定义的递归函数rec。
值得注意的是,GPT-4 直接执行代码,而不需要将其翻译成其他定义良好的编程语言。这证明了AGI模型作为一种用自然语言编程的新工具的潜力,这可能会彻底改变我们未来的编码方式。

为了获得另一个关于GPT-4如何维持代码状态的初步评估,在附录C.7中,我们用数百个多个长度的随机采样输入,在GPT-4上以零样本的方式运行用于大数乘法的图标伪代码。代码要求GPT-4更新并记住大量步骤的数组状态。我们观察到,尽管GPT-4被训练为(非精确)自然语言模型,但在超过50次更新后,它几乎可以正确地保存代码的状态。
【本节完,以下章节内容待续】
- 数学能力
- 与世界交互
- 与人类交互
- 判别力
- GPT4 的局限性
- 社会影响
- 结论与对未来展望
版权声明:
youcans@xupt 作品,转载必须标注原文链接:
【微软 GPT-4 测试报告(3)GPT4 的编程能力】:https://blog.csdn.net/youcans/category_12244543.html
本文使用了 GPT 辅助进行翻译,作者进行了全面和认真的修正。
Copyright 2022 youcans, XUPT
Crated:2023-3-25
参考资料:
【GPT-4 微软研究报告】:
Sparks of Artificial General Intelligence: Early experiments with GPT-4, by Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, et al.
下载地址:https://arxiv.org/pdf/2303.12712.pdf
文章出处登录后可见!