


GigaGAN是Adobe和卡内基梅隆大学学者们提出的一种新的GAN架构,作者设计了一种新的GAN架构,推理速度、合成高分辨率、扩展性都极其有优势,其证明GAN仍然是文本生成图像的可行选择之一。
文章链接:https://arxiv.org/abs/2303.05511
项目地址:https://mingukkang.github.io/GigaGAN/

一、原文摘要
最近,文字-图像合成技术的成功已经席卷全球,激发了大众的想象力。从技术的角度来看,它也标志着设计生成图像模型所青睐的架构的巨大变化。GANs曾经是事实上的选择,有StyleGAN这样的技术。随着DALL·e2的出现,自回归和扩散模型一夜之间成为大规模生成模型的新标准。这种快速的转变提出了一个基本问题:我们能否扩大GANs的规模,从像LAION这样的大型数据集中受益?我们发现,随意增加StyleGAN架构的容量很快就会变得不稳定。我们介绍了一种新的GAN架构GigaGAN,它远远超过了这一限制,证明了GAN是文本到图像合成的可行选择。GigaGAN有三大优势。首先,它的推理速度快了几个数量级,合成一张512px的图像只需要0.13秒。其次,它可以在3.66秒内合成高分辨率图像,例如1600万像素的图像。最后,GigaGAN支持各种潜在空间编辑应用程序,如潜在插值、样式混合和矢量算术操作。
二、为什么提出GigaGAN?
最近发布的模型如DALL·E 2、Imagen、Parti和Stable Diffusion开创了图像生成的新时代,实现了前所未有的图像质量和模型灵活性。目前占主导地位的扩散模型和自回归模型都依赖于迭代推理,然而众所周知,迭代推理是一把双刃剑,虽然迭代方法可以实现简单目标的稳定训练,但在推理过程中会产生很高的计算成本。
而生成对抗网络只需通过单次向前传递生成图像,相较而言非常高效,其在建模单个或多个对象类方面表现出色,但在扩大规模时会经常遇见模式崩溃,在扩展到复杂的数据集或者更加开放的世界,仍然具有挑战性。
于是,作者提出了一系列问题:
- GANs能否继续扩大规模,并可能从这些复杂资源中受益,还是已经停滞不前?
- 是什么阻止了它们进一步扩大,我们能克服这些障碍吗?
在这些问题的基础上,作者首先研究分析了StyleGAN的关键问题,其次重新引入了多尺度训练,找到了一种改进图像-文本对齐和生成输出的低频细节的新方案——GigaGAN,与扩散和自回归模型相比,GigaGAN有三个主要的实际优势:
- 推理速度快,在0.13秒内生成512*512像素的图像。
- 能合成超高清图像,可以在3.66秒内合成4k分辨率的超高分辨率图像。
- 可控图像合成应用,被赋予了一个可控的、潜在的向量空间,可以用于充分研究的可控图像合成应用,例如风格混合、prompt插值和prompt混合。
三、GigaGAN
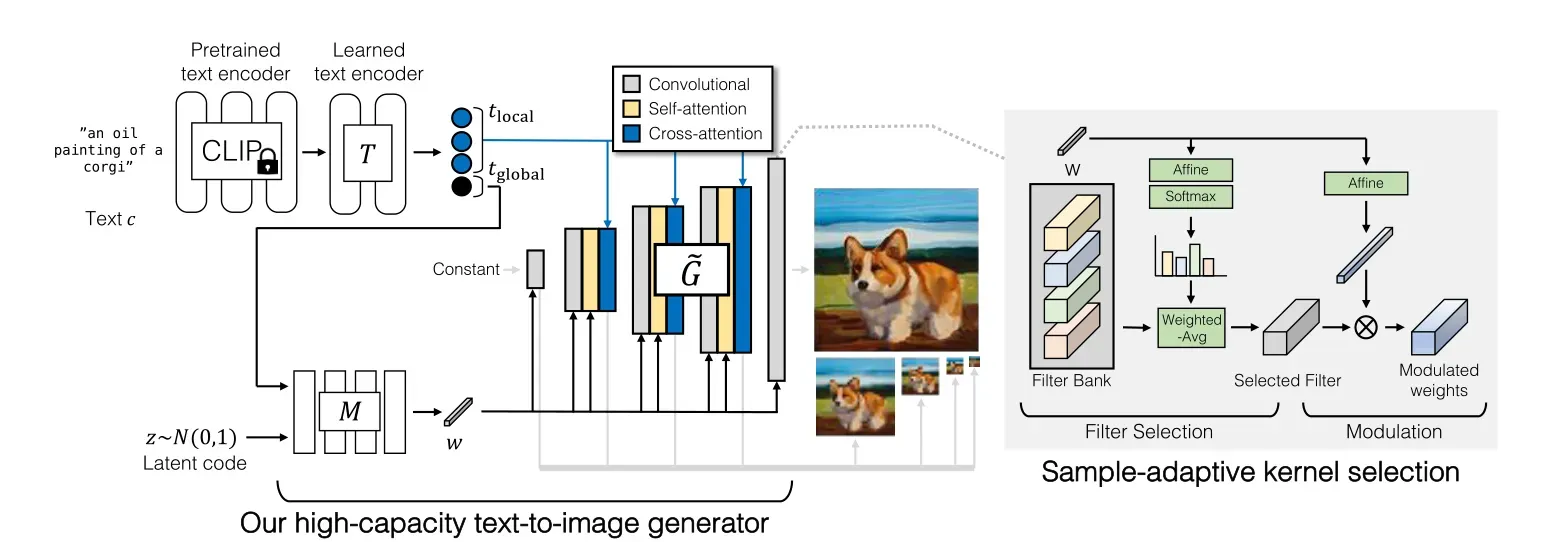
3.1、模型框架
GigaGAN模型框架如上图所示,首先,作者使用预训练的CLIP模型和预训练的文本编码器T提取文本嵌入。然后使用交叉注意力将本地文本描述符提供给生成器,全局文本描述符和潜在代码z一起被馈送到样式映射网络M以生成样式向量w(StyleGAN的方法)。样式向量w输入形成样本自适应核选择帮助调节主生成器。右侧显示样本自适应核选择的具体过程。

3.2、前导知识
3.2.1、基线模型:StyleGAN。
GigaGAN架构基于StyleGAN2的条件版本,由两个网络组成

3.2.2、 样本自适应核选择
为了处理互联网图像的高度多样化分布,文章提出了一种有效的方法来增强卷积核的表达能力,即基于文本条件处理实时创建卷积核,如下图所示
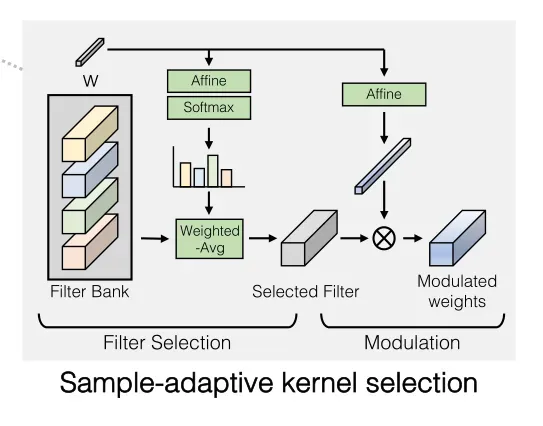

Filter Selection:这个方案中首先实例化了一组N个过滤器(图中叫Filter Bank):
然后在StyleGAN2的正则卷积管道中使用该滤波器再经过一层仿射变换
在高层次上,基于softmax的加权可以被视为基于输入条件的可微滤波器选择过程。此外,由于滤波器选择过程只在每一层执行一次,选择过程比实际的卷积快得多。
卷积滤波器在每个样本中动态变化,其与动态卷积的想法相同,但不同之处在于文章显式实例化了一个更大的滤波器组,并基于StyleGAN的w-空间条件下的单独路径选择权重。
3.2.3、将注意力与卷积交织
建立这种长期关系的一种方法就是使用注意力层。BigGAN, GANformer和ViTGAN都将注意力层与卷积主干集成在一起来提高性能,但是如果简单地给StyleGAN添加注意层往往会导致训练崩溃。这是由于鉴别器的Lipschitz连续性在稳定训练中发挥了关键作用,作者使用L2-distance代替点积作为注意对数来促进Lipschitz连续性,类似于ViTGAN
为了进一步提高性能,作者发现匹配StyleGAN的架构细节是至关重要的。例如均衡学习率和从单位正态分布初始化权重。作者缩小L2距离对数以大致匹配初始化时的单位正态分布,并减少来自注意层的剩余增益。另外通过绑定键和查询矩阵,并应用权重衰减来进一步提高稳定性。
在综合网络G中,注意层与每个卷积块交错,利用样式向量w作为额外的标记。在每个注意块上,我们添加了一个单独的交叉注意机制
3.3、生成器设计
3.3.1、文本和潜在空间条件映射
强大的语言模型对于产生强大的结果必不可少。作者对输入提示符进行标记化以产生条件向量
与原来的StyleGAN不同,模型既使用基于文本的样式代码w来调制合成网络eG,又使用词嵌入tlocal作为交叉注意的特征:
3.3.2、网络
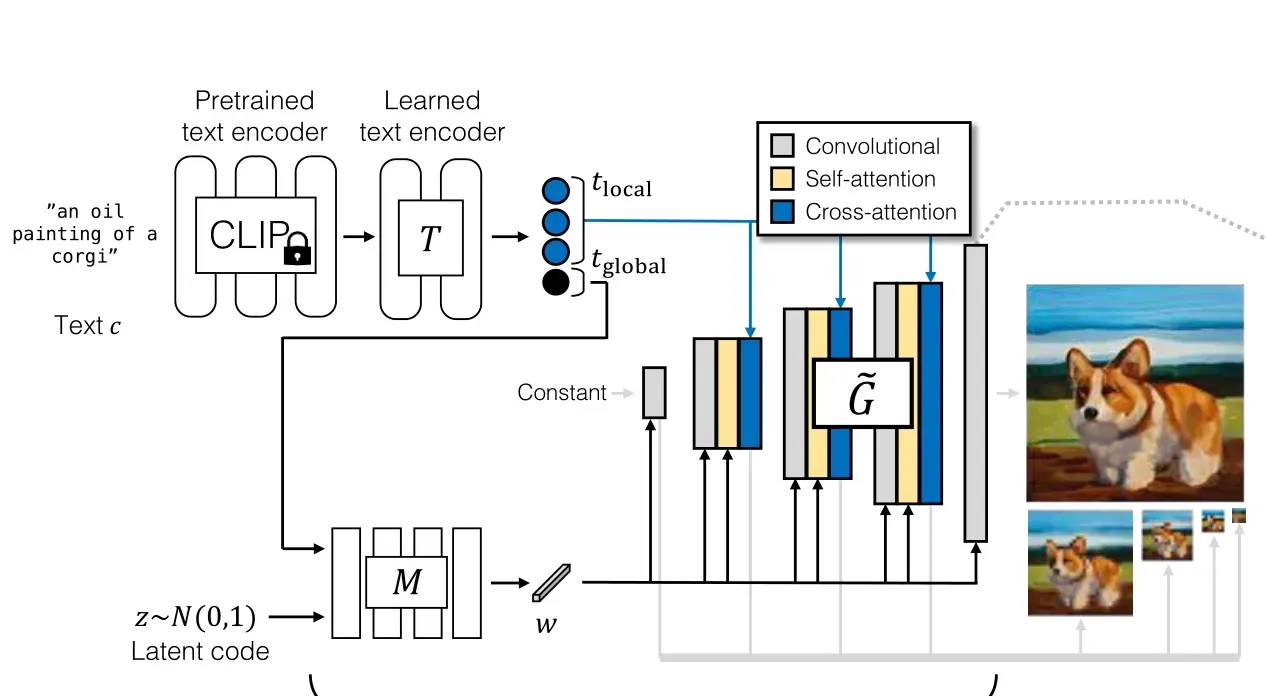

上图表示了生成器网络结构,灰色为卷积,黄色为自注意力层,蓝色为交叉注意力层,合成网络的具体过程用公式表述如下:
其中g’xa、g’attn和g’adaconv表示交叉注意、自我注意和权重(反)调制层的第l层。
3.4、鉴别器设计
鉴别器由图像处理和文本处理两个分支组成。文本分支处理与生成器类似的文本。图像分支接收一个图像金字塔,并对每个图像尺度进行独立预测。此外,预测是在下采样层的所有后续尺度上进行的,使其成为一个多尺度输入,多尺度输出(MS-I/O)鉴别器。
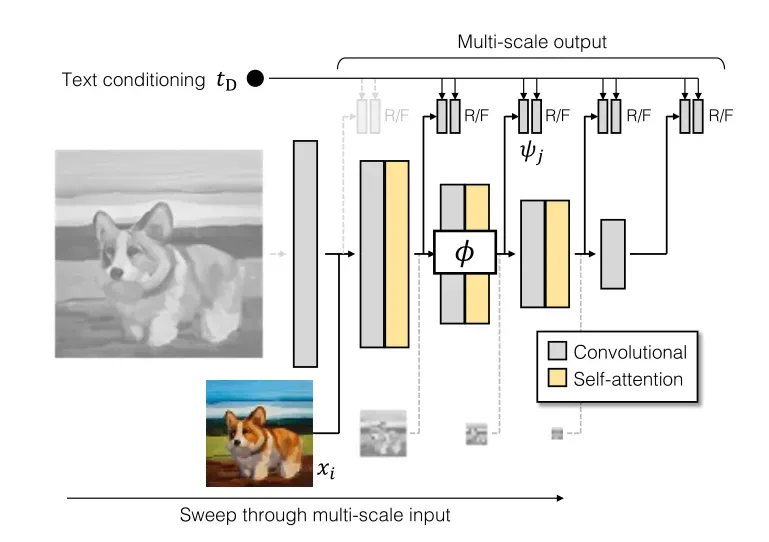

3.4.1、文本处理
首先,为了将条件作用合并到鉴别器中,首先从文本c中提取文本描述符
3.4.2、多尺度图像处理
多尺度图像处理中,随着模型大小的增加,鉴别器网络的依赖于高分辨率层,早期低分辨率层变得不活跃。于是作者重新设计了模型架构,以提供跨多个尺度的训练信号。
为了在不同尺度上提取特征,作者定义了特征
3.5、损失函数
3.5.1、多尺度输入,多尺度输出对抗损失
总的来说,我们的训练目标包括鉴别器损失,以及我们提出的匹配损失,以鼓励鉴别器考虑条件:
其中VGAN为标准的非饱和GAN损耗,为了计算鉴别器输出,我们训练预测器ψ,它使用文本特征
将
3.5.2、Matching-aware损失
前面的GAN项测量图像x与条件c的匹配程度,以及x看起来有多逼真,而不考虑条件。然而,在早期的训练中,当伪影很明显时,鉴别器严重依赖于做出独立于条件反射的决定,并且在考虑后来的条件反射时犹豫不决。
为了强制判别器加入条件,我们将x与一个随机的、独立采样的条件c匹配,并将它们表示为一个假对:
其中(x, c)和c分别从pdata中采样。这种损失之前已经在文本到图像的GAN作品中研究过,除了我们发现对G生成的图像以及真实图像x强制Matchingaware损失,会导致性能的明显提高
3.5.3、CLIP对比损失
3.5.4、视觉辅助对抗性损失
综上所述,模型构建了一个附加的鉴别器,使用CLIP模型作为主干,称为视觉辅助GAN。我们冻结CLIP图像编码器,从中间层提取特征,并通过3 × 3 conv层的简单网络进行处理,从而进行真实/虚假预测。还通过调制结合了条件作用,如公式7所示。为了稳定训练,我们还添加了一个固定的随机投影层,正如投影GAN所提出的那样。称之为视觉辅助对抗性损失
最终损失函数为:
四、实验
作者做了大量且全面的实验,看论文附录也很丰富。这里简单展示部分实验结果,具体请看原文。
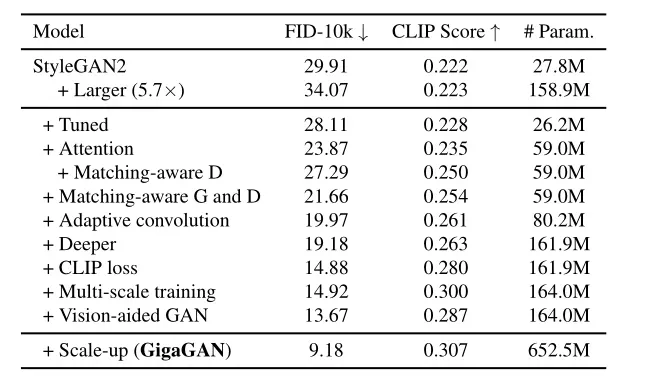
4.1、消融实验

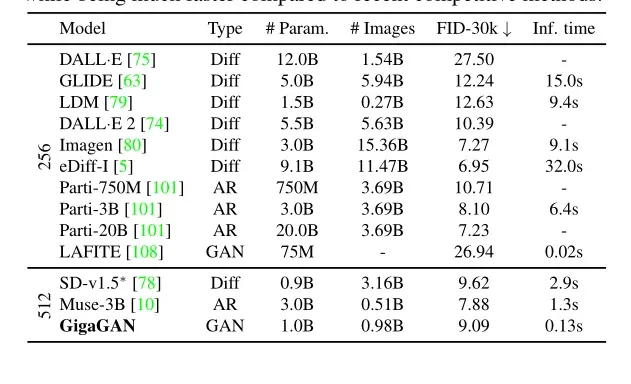
4.2、文本生成图像定量对比

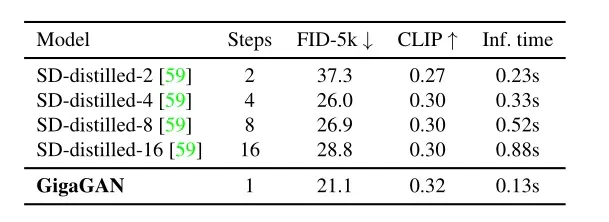
4.3、与distilled diffusion models的对比

4.4、视觉效果




五、总结
GigaGAN架构为大规模生成模型开辟了一个全新的设计空间,并带回了关键的编辑功能,这些功能在向自回归和扩散模型过渡时变得具有挑战性。其已经测试的能力远远超出了用新方法可能实现的能力,并通过使用类似资源训练的自回归和扩散模型实现了具有竞争力的视觉质量,同时速度快了几个数量级,并实现了潜在的插值和程式化。
💡 最后
我们已经建立了🏤T2I研学社群,如果你还有其他疑问或者对🎓文本生成图像很感兴趣,可以私信我加入社群。
📝 加入社群 抱团学习:中杯可乐多加冰-深度学习T2I研习群
🔥 限时免费订阅:文本生成图像T2I专栏
🎉 支持我:点赞👍+收藏⭐️+留言📝
文章出处登录后可见!