引言
笔者Ultra-Fast-Lane-Detection专栏链接🔗导航:
- 【Lane】 Ultra-Fast-Lane-Detection 复现
- 【Lane】Ultra-Fast-Lane-Detection(1)自定义数据集训练
- 【Lane】Ultra-Fast-Lane-Detection(2)自定义模型测试
车道线检测源码复现以及训练自己的数据集
源码地址:https://github.com/cfzd/Ultra-Fast-Lane-Detection
论文地址:https://arxiv.org/abs/2004.11757
1 环境搭建
conda create -n lane python=3.7
conda activate lane # 激活环境
conda install pytorch torchvision cudatoolkit=10.1 -c pytorch
# 参考官网:https://pytorch.org/get-started/locally/
pip install -r requirements.txt
2 下载项目源码
若在服务器上可以用指令下载,否则直接在网址中下载
git clone https://github.com/cfzd/Ultra-Fast-Lane-Detection
3 下载开源数据集
笔者下载了Tusimple数据集,链接如下:
Tusimple

上图显示的可以都下载下来
开源数据集准备
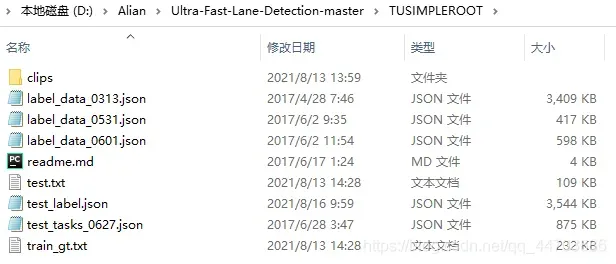
在源码根目录中新建文件夹TUSIMPLEROOT,将上述的压缩包解压后放入文件夹中。
$TUSIMPLEROOT
|──clips
|──label_data_0313.json
|──label_data_0531.json
|──label_data_0601.json
|──test_tasks_0627.json
|──test_label.json
|──readme.md
对于Tusimple,没有提供分段注释,因此我们需要从json注释生成分段。
python scripts/convert_tusimple.py --root $TUSIMPLEROOT
$TUSIMPLEROOT代表你自己创建的文件夹TUSIMPLEROOT的路径。通过这一步将会产生上图中的两个.txt文件
4 测试源码
下载预训练模型,放在源码根目录下,如下图
百度网盘链接,提取码:bghd
4.1 执行test.py
python test.py configs/tusimple.py --test_model tusimple_18.pth --test_work_dir ./tmp
运行上述指令,在根目录文件夹下终端显示如下:

并在根目录文件夹下新建tmp文件夹,文件夹下内容如下:

4.2 执行demo.py
python demo.py configs/tusimple.py --test_model tusimple_18.pth
运行上述指令,在根目录文件夹下终端显示如下:

并在终端生成test.avi(将检测结果整合成视频文件)
4.3 demo.py 自定义修改
(1)测试自己的视频文件
复制demo.py文件并重命名为demo_video.py,代码做如下修改:
"""
2021.08.16
author:alian
function:
Ultra-Fast-Lane-Detection 测试视频文件并保存结果为视频
"""
import torch, os
import cv2
from model.model import parsingNet
from utils.common import merge_config
from utils.dist_utils import dist_print
import torch
import scipy.special, tqdm
import numpy as np
import torchvision.transforms as transforms
from data.dataset import LaneTestDataset
from data.constant import culane_row_anchor, tusimple_row_anchor
if __name__ == "__main__":
torch.backends.cudnn.benchmark = True
args, cfg = merge_config()
dist_print('start testing...')
assert cfg.backbone in ['18', '34', '50', '101', '152', '50next', '101next', '50wide', '101wide']
if cfg.dataset == 'CULane':
cls_num_per_lane = 18
elif cfg.dataset == 'Tusimple':
cls_num_per_lane = 56
else:
raise NotImplementedError
net = parsingNet(pretrained=False, backbone=cfg.backbone, cls_dim=(cfg.griding_num + 1, cls_num_per_lane, 4),
use_aux=False).cuda() # we dont need auxiliary segmentation in testing
state_dict = torch.load(cfg.test_model, map_location='cpu')['model']
compatible_state_dict = {}
for k, v in state_dict.items():
if 'module.' in k:
compatible_state_dict[k[7:]] = v
else:
compatible_state_dict[k] = v
net.load_state_dict(compatible_state_dict, strict=False)
net.eval()
img_transforms = transforms.Compose([
# transforms.CenterCrop((590,1640)),
transforms.Resize((288, 800)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
cap = cv2.VideoCapture("******.avi") # 读取视频文件
fourcc = cv2.VideoWriter_fourcc(*'MJPG')
rval, frame = cap.read()
frame = frame[490:1080, 0:1640, :]
vout = cv2.VideoWriter('output.avi', fourcc, 30.0, (frame.shape[1], frame.shape[0])) # 结果保存
print("w= {},h = {}".format(cap.get(3), cap.get(4)))
from PIL import Image
print('加载CUDA是否成功:', torch.cuda.is_available())
while 1:
rval, frame = cap.read()
if rval == False:
break
frame = frame[490:1080, 0:1640, :]
img = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
img_ = Image.fromarray(img)
imgs = img_transforms(img_)
imgs = imgs.unsqueeze(0)
imgs = imgs.cuda()
with torch.no_grad():
out = net(imgs)
col_sample = np.linspace(0, 800 - 1, cfg.griding_num)
col_sample_w = col_sample[1] - col_sample[0]
out_j = out[0].data.cpu().numpy()
out_j = out_j[:, ::-1, :]
prob = scipy.special.softmax(out_j[:-1, :, :], axis=0)
idx = np.arange(cfg.griding_num) + 1
idx = idx.reshape(-1, 1, 1)
loc = np.sum(prob * idx, axis=0)
out_j = np.argmax(out_j, axis=0)
loc[out_j == cfg.griding_num] = 0
out_j = loc
for i in range(out_j.shape[1]):
if np.sum(out_j[:, i] != 0) > 2:
for k in range(out_j.shape[0]):
if out_j[k, i] > 0:
ppp = (
int(out_j[k, i] * col_sample_w * frame.shape[1] / 800) - 1, int(frame.shape[0] - k * 20) - 1)
cv2.circle(frame, ppp, 5, (0, 255, 0), -1)
vout.write(frame)
vout.release()
在终端执行指令:
python demo_video.py configs/tusimple.py --test_model tusimple_18.pth
在根目录下生成output.avi测试结果文件
(2)测试自己的图片文件夹并保存检测结果图
复制demo.py并重命名为demo_custom.py,代码修改如下:
"""
2021.08.16
author:alian
function: 测试自己的数据集,并保存成检测结果图
"""
import torch, os, cv2
from model.model import parsingNet
from utils.common import merge_config
from utils.dist_utils import dist_print
import torch
import scipy.special, tqdm
import numpy as np
import torchvision.transforms as transforms
from data.dataset import LaneTestDataset
from data.constant import culane_row_anchor, tusimple_row_anchor
# 指定测试的配置信息
backbone = '18' # 骨干网络
dataset = '11' # 数据集类型
griding_num = 100 # 网格数
# test_model = 'tusimple_18.pth' # 预训练模型路径 tusimple_18.pth
test_model = r'D:\Alian\Ultra-Fast-Lane-Detection-master\log\20210812_201601_lr_4e-04_b_32\ep099.pth' # 自训练模型路径
# data_root = r'D:\Alian\Ultra-Fast-Lane-Detection-master\TUSIMPLEROOT' # 开源数据集测试路径
data_root = r'D:\Alian\Ultra-Fast-Lane-Detection-master\test_img\test' # 自定义测试路径
data_save = r'D:\Alian\Ultra-Fast-Lane-Detection-master\test_img\out' # 保存检测结果图路径
import torch
from PIL import Image
import os
import numpy as np
import cv2
import glob
def loader_func(path):
return Image.open(path)
class TestDataset(torch.utils.data.Dataset):
def __init__(self, path, img_transform=None):
super(TestDataset, self).__init__()
self.path = path
self.img_transform = img_transform
# self.list:储存测试图片的相对路径 clips/0601/1494452577507766671/20.jpg\n
def __getitem__(self, index):
name = glob.glob('%s/*.jpg'%self.path)[index]
img = loader_func(name)
if self.img_transform is not None:
img = self.img_transform(img)
return img, name
def __len__(self):
return len(self.list)
if __name__ == "__main__":
torch.backends.cudnn.benchmark = True # 加速
# args, cfg = merge_config() # 用终端指定配置信息
dist_print('start testing...')
assert backbone in ['18', '34', '50', '101', '152', '50next', '101next', '50wide', '101wide']
if dataset == 'CULane':
cls_num_per_lane = 18
elif dataset == 'Tusimple':
cls_num_per_lane = 56
else:
# raise NotImplementedError
cls_num_per_lane = 56
net = parsingNet(pretrained=False, backbone=backbone, cls_dim=(griding_num + 1, cls_num_per_lane, 4),
use_aux=False).cuda() # we dont need auxiliary segmentation in testing
state_dict = torch.load(test_model, map_location='cpu')['model']
compatible_state_dict = {}
for k, v in state_dict.items():
if 'module.' in k:
compatible_state_dict[k[7:]] = v
else:
compatible_state_dict[k] = v
net.load_state_dict(compatible_state_dict, strict=False)
net.eval()
# 图像格式统一:(288, 800),图像张量,归一化
img_transforms = transforms.Compose([
transforms.Resize((288, 800)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
if dataset == 'CULane':
splits = ['test0_normal.txt', 'test1_crowd.txt', 'test2_hlight.txt', 'test3_shadow.txt', 'test4_noline.txt', 'test5_arrow.txt', 'test6_curve.txt', 'test7_cross.txt', 'test8_night.txt']
datasets = [LaneTestDataset(data_root,os.path.join(data_root, 'list/test_split/'+split),img_transform = img_transforms) for split in splits]
img_w, img_h = 1640, 590
row_anchor = culane_row_anchor
elif dataset == 'Tusimple':
splits = ['test.txt']
datasets = [LaneTestDataset(data_root,os.path.join(data_root, split),img_transform = img_transforms) for split in splits]
img_w, img_h = 1280, 720
row_anchor = tusimple_row_anchor
else: # 自定义数据集
# raise NotImplementedError
datasets = TestDataset(data_root, img_transform=img_transforms)
img_w, img_h = 1280, 720
row_anchor = tusimple_row_anchor
for dataset in zip(datasets): # splits:图片列表 datasets:统一格式之后的数据集
loader = torch.utils.data.DataLoader(dataset, batch_size=1, shuffle = False, num_workers=1) # 加载数据集
# fourcc = cv2.VideoWriter_fourcc(*'MJPG')
# print(split[:-3]+'avi')
# vout = cv2.VideoWriter(split[:-3]+'avi', fourcc, 30.0, (img_w, img_h)) # 保存结果为视频文件
for i, data in enumerate(tqdm.tqdm(loader)): # 进度条显示进度
imgs, names = data # imgs:图像张量,图像相对路径:
imgs = imgs.cuda() # 使用GPU
with torch.no_grad(): # 测试代码不计算梯度
out = net(imgs) # 模型预测 输出张量:[1,101,56,4]
col_sample = np.linspace(0, 800 - 1, griding_num)
col_sample_w = col_sample[1] - col_sample[0]
out_j = out[0].data.cpu().numpy() # 数据类型转换成numpy [101,56,4]
out_j = out_j[:, ::-1, :] # 将第二维度倒着取[101,56,4]
prob = scipy.special.softmax(out_j[:-1, :, :], axis=0) # [100,56,4]softmax 计算(概率映射到0-1之间且沿着维度0概率总和=1)
idx = np.arange(griding_num) + 1 # 产生 1-100
idx = idx.reshape(-1, 1, 1) # [100,1,1]
loc = np.sum(prob * idx, axis=0) # [56,4]
out_j = np.argmax(out_j, axis=0) # 返回最大值的索引
loc[out_j == griding_num] = 0 # 若最大值的索引=griding_num,归零
out_j = loc # [56,4]
# import pdb; pdb.set_trace()
vis = cv2.imread(os.path.join(data_root,names[0])) # 读取图像 [720,1280,3]
for i in range(out_j.shape[1]): # 遍历列
if np.sum(out_j[:, i] != 0) > 2: # 非0单元格的数量大于2
sum1 = np.sum(out_j[:, i] != 0)
for k in range(out_j.shape[0]): # 遍历行
if out_j[k, i] > 0:
ppp = (int(out_j[k, i] * col_sample_w * img_w / 800) - 1, int(img_h * (row_anchor[cls_num_per_lane-1-k]/288)) - 1 )
cv2.circle(vis,ppp,5,(0,255,0),-1)
# 保存检测结果图
cv2.imwrite(os.path.join(data_save,os.path.basename(names[0])),vis)
# 保存视频结果(注释掉)
# vout.write(vis)
#
# vout.release()
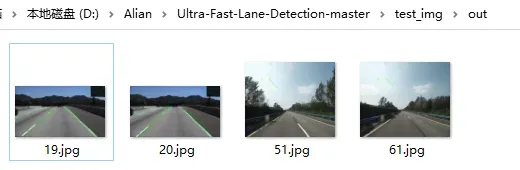
测试结果图保存在D:\Alian\Ultra-Fast-Lane-Detection-master\test_img\out文件夹下,但是预训练模型在笔者自定义的数据集测试结果并不理想,还是重新训练自己的数据集可能结果会更加理想。
5 训练自定义数据库
5.1 数据集准备
用labelme完成数据标注得到原始图片以及对应的标注文件.json(这里笔者不做过多的赘述),分别放在两个文件夹下:
![]()
生成实例掩膜图像,即开源数据中黑黑的什么也看不到的图像,代码如下:
"""
2021.8.16
author:alian
function:
根据labelme标注的文件生成实例掩膜
"""
import argparse
import glob
import json
import os
import os.path as ops
import cv2
import numpy as np
def init_args():
"""
:return:
"""
parser = argparse.ArgumentParser()
parser.add_argument('--img_dir', type=str, help='The origin path of image')
parser.add_argument('--json_dir', type=str, help='The origin path of json')
return parser.parse_args()
# 获得原始图像(.png),二值化图像以及实例分割图像
def process_json_file(img_path, json_path, instance_dst_dir):
"""
:param img_path:
:param ori_dst_dir:
:param binary_dst_dir:
:param instance_dst_dir:
:return:
"""
assert ops.exists(img_path), '{:s} not exist'.format(img_path)
image = cv2.imread(img_path, cv2.IMREAD_COLOR)
binary_image = np.zeros([image.shape[0], image.shape[1]], np.uint8)
instance_image = np.zeros([image.shape[0], image.shape[1]], np.uint8)
with open(json_path, 'r',encoding='utf8') as file:
info_dict = json.load(file)
for ind,info in enumerate(info_dict['shapes']):
contours = info['points']
contours = np.array(contours,dtype=int)
# 绘制多边形
cv2.fillPoly(binary_image, [contours], (255, 255, 255))
cv2.fillPoly(instance_image, [contours], (ind, ind, ind)) # * 50 + 20
instance_image_path = img_path.replace(os.path.dirname(img_path),instance_dst_dir)
cv2.imwrite(instance_image_path.replace('.jpg','.png'), instance_image) # 实例分割图像
# 训练库构建
def process_tusimple_dataset(src_dir,json_dir):
"""
:param src_dir:
:return:
"""
traing_folder_path = ops.join(os.path.dirname(src_dir), 'training')
os.makedirs(traing_folder_path, exist_ok=True)
gt_instance_dir = ops.join(traing_folder_path, 'label')
os.makedirs(gt_instance_dir, exist_ok=True)
for img_path in glob.glob('{:s}/*.jpg'.format(src_dir)):
json_path = img_path.replace(src_dir,json_dir).replace('.jpg','.json')
process_json_file(img_path, json_path, gt_instance_dir)
return
if __name__ == '__main__':
args = init_args()
# 方法1:在终端指定配置信息
# process_tusimple_dataset(args.img_dir,args.json_dir) # 在终端指定配置信息
# 方法2:直接在代码中输入
img_dir = r'./pic' # 原始图片路径
json_dir = r'./json' # 标注文件路径
process_tusimple_dataset(img_dir,json_dir)
5.2 开始训练
打开./data/dataset.py在最后加入如下代码,类ClsDataset用来生成加载自定义数据集
# 加载自定义的数据集
class ClsDataset(torch.utils.data.Dataset):
def __init__(self, path, img_transform=None, target_transform=None, simu_transform=None, griding_num=50,
load_name=False,
row_anchor=None, use_aux=False, segment_transform=None, num_lanes=4):
super(ClsDataset, self).__init__()
self.img_transform = img_transform
self.target_transform = target_transform
self.segment_transform = segment_transform
self.simu_transform = simu_transform
self.path = path
self.griding_num = griding_num
self.load_name = load_name
self.use_aux = use_aux
self.num_lanes = num_lanes
self.row_anchor = row_anchor
self.row_anchor.sort()
def __getitem__(self, index): # 获得图像数组
labels = glob.glob('%s/label/*.png'%self.path)
label_path = labels[index]
label = loader_func(label_path)
imgs = glob.glob('%s/pic/*.jpg'%self.path)
img_path = imgs[index]
img = loader_func(img_path) # 读取图像
if self.simu_transform is not None:
img, label = self.simu_transform(img, label)
lane_pts = self._get_index(label)
# get the coordinates of lanes at row anchors
w, h = img.size
cls_label = self._grid_pts(lane_pts, self.griding_num, w)
# make the coordinates to classification label
if self.use_aux:
assert self.segment_transform is not None
seg_label = self.segment_transform(label)
if self.img_transform is not None:
img = self.img_transform(img)
if self.use_aux:
return img, cls_label, seg_label
if self.load_name:
return img, cls_label, img_name
return img, cls_label
def __len__(self):
return len(glob.glob('%s/label/*.png'%self.path))
def _grid_pts(self, pts, num_cols, w): # 获得网格数
# pts : numlane,n,2
num_lane, n, n2 = pts.shape
col_sample = np.linspace(0, w - 1, num_cols)
assert n2 == 2
to_pts = np.zeros((n, num_lane))
for i in range(num_lane):
pti = pts[i, :, 1]
to_pts[:, i] = np.asarray(
[int(pt // (col_sample[1] - col_sample[0])) if pt != -1 else num_cols for pt in pti])
return to_pts.astype(int)
def _get_index(self, label):
w, h = label.size
if h != 288:
scale_f = lambda x: int((x * 1.0 / 288) * h)
sample_tmp = list(map(scale_f, self.row_anchor))
all_idx = np.zeros((self.num_lanes, len(sample_tmp), 2))
for i, r in enumerate(sample_tmp):
label_r = np.asarray(label)[int(round(r))]
for lane_idx in range(1, self.num_lanes + 1):
pos = np.where(label_r == lane_idx)[0]
if len(pos) == 0:
all_idx[lane_idx - 1, i, 0] = r
all_idx[lane_idx - 1, i, 1] = -1
continue
pos = np.mean(pos)
all_idx[lane_idx - 1, i, 0] = r
all_idx[lane_idx - 1, i, 1] = pos
# data augmentation: extend the lane to the boundary of image
all_idx_cp = all_idx.copy()
for i in range(self.num_lanes):
if np.all(all_idx_cp[i, :, 1] == -1):
continue
# if there is no lane
valid = all_idx_cp[i, :, 1] != -1
# get all valid lane points' index
valid_idx = all_idx_cp[i, valid, :]
# get all valid lane points
if valid_idx[-1, 0] == all_idx_cp[0, -1, 0]:
# if the last valid lane point's y-coordinate is already the last y-coordinate of all rows
# this means this lane has reached the bottom boundary of the image
# so we skip
continue
if len(valid_idx) < 6:
continue
# if the lane is too short to extend
valid_idx_half = valid_idx[len(valid_idx) // 2:, :]
p = np.polyfit(valid_idx_half[:, 0], valid_idx_half[:, 1], deg=1)
start_line = valid_idx_half[-1, 0]
pos = find_start_pos(all_idx_cp[i, :, 0], start_line) + 1
fitted = np.polyval(p, all_idx_cp[i, pos:, 0])
fitted = np.array([-1 if y < 0 or y > w - 1 else y for y in fitted])
assert np.all(all_idx_cp[i, pos:, 1] == -1)
all_idx_cp[i, pos:, 1] = fitted
if -1 in all_idx[:, :, 0]:
pdb.set_trace()
return all_idx_cp # [4,56,2]
打开./data/dataloder.py,修改else:如下:
if dataset == 'CULane':
train_dataset = LaneClsDataset(data_root,
os.path.join(data_root, 'list/train_gt.txt'),
img_transform=img_transform, target_transform=target_transform,
simu_transform = simu_transform,
segment_transform=segment_transform,
row_anchor = culane_row_anchor,
griding_num=griding_num, use_aux=use_aux, num_lanes = num_lanes)
cls_num_per_lane = 18
elif dataset == 'Tusimple':
train_dataset = LaneClsDataset(data_root,
os.path.join(data_root, 'train_gt.txt'),
img_transform=img_transform, target_transform=target_transform,
simu_transform = simu_transform,
griding_num=griding_num,
row_anchor = tusimple_row_anchor,
segment_transform=segment_transform,use_aux=use_aux, num_lanes = num_lanes)
cls_num_per_lane = 56
else: # 自定义数据集
# raise NotImplementedError
train_dataset = ClsDataset(data_root,
img_transform=img_transform, target_transform=target_transform,
simu_transform=simu_transform,
griding_num=griding_num,
row_anchor=tusimple_row_anchor,
segment_transform=segment_transform, use_aux=use_aux, num_lanes=num_lanes)
cls_num_per_lane = 56
打开配置文件./configs/tusimple.py,修改配置信息如下:
# DATA
# dataset= 'Tusimple' # 开源数据集
dataset= 'realway' # 自定义数据集
# data_root = 'D:/Alian/Ultra-Fast-Lane-Detection-master/TUSIMPLEROOT/' # 开源数据集
data_root = 'D:/Alian/Ultra-Fast-Lane-Detection-master/realway/' # 自定义
# TRAIN
epoch = 100
batch_size = 32
optimizer = 'Adam' #['SGD','Adam']
# learning_rate = 0.1
learning_rate = 4e-4
weight_decay = 1e-4
momentum = 0.9
scheduler = 'cos' #['multi', 'cos']
# steps = [50,75]
gamma = 0.1
warmup = 'linear'
warmup_iters = 100
# NETWORK
backbone = '18'
griding_num = 100
use_aux = True
# LOSS
sim_loss_w = 1.0
shp_loss_w = 0.0
# EXP
note = ''
log_path = 'D:/Alian/Ultra-Fast-Lane-Detection-master/log/' # 模型保存路径
# FINETUNE or RESUME MODEL PATH
finetune = None
resume = None
# TEST
test_model = None
test_work_dir = None
num_lanes = 4
在终端输入训练指令:
python train.py configs/tusimple.py
笔者遇到的报错:
Traceback (most recent call last):
File "train.py", line 152, in <module>
train(net, train_loader, loss_dict, optimizer, scheduler,logger, epoch, metric_dict, cfg.use_aux)
File "train.py", line 68, in train
loss = calc_loss(loss_dict, results, logger, global_step) # 构建损失函数
File "train.py", line 49, in calc_loss
logger.add_scalar('loss/'+loss_dict['name'][i], loss_cur, global_step)
File "D:\Alian\Ultra-Fast-Lane-Detection-master\utils\dist_utils.py", line 142, in add_scalar
super(DistSummaryWriter, self).add_scalar(*args, **kwargs)
File "D:\Anaconda3\envs\lane\lib\site-packages\torch\utils\tensorboard\writer.py", line 345, in add_scalar
scalar(tag, scalar_value), global_step, walltime)
File "D:\Anaconda3\envs\lane\lib\site-packages\torch\utils\tensorboard\summary.py", line 247, in scalar
scalar = make_np(scalar)
File "D:\Anaconda3\envs\lane\lib\site-packages\torch\utils\tensorboard\_convert_np.py", line 23, in make_np
return _prepare_pytorch(x)
File "D:\Anaconda3\envs\lane\lib\site-packages\torch\utils\tensorboard\_convert_np.py", line 31, in _prepare_pytorch
x = x.cpu().numpy()
RuntimeError: CUDA error: device-side assert triggered
0%| | 0/32 [00:19<?, ?it/s]
上述错误是由于数据集的类别数与指定的类别数不一致导致的,解决方法:
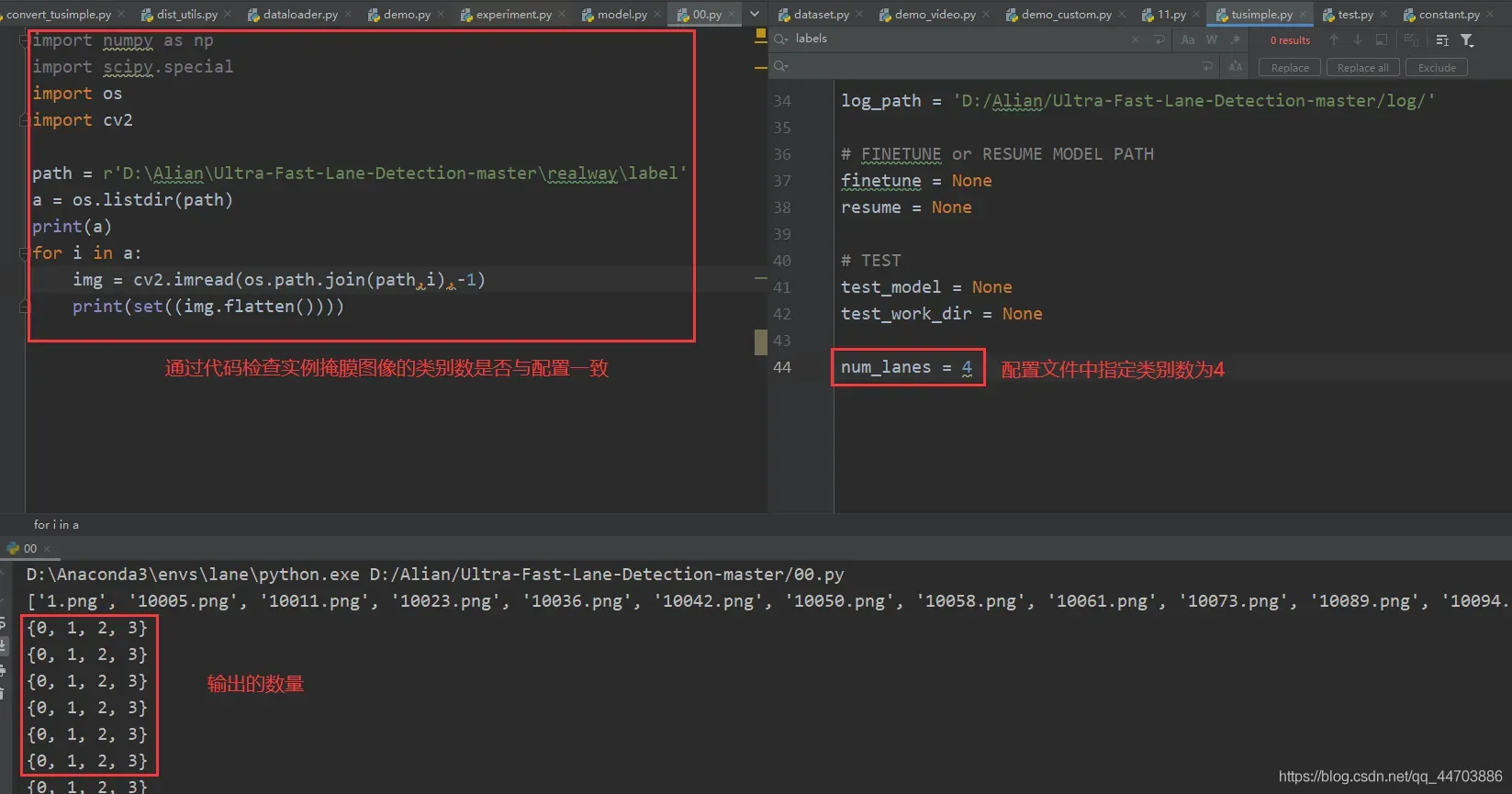
上述的检查代码如下:
import os
import cv2
path = r'D:\Alian\Ultra-Fast-Lane-Detection-master\realway\label' # 生成的实例掩膜图像路径,即漆黑什么也看不见的图像
a = os.listdir(path)
print(a)
for i in a:
img = cv2.imread(os.path.join(path,i),-1)
print(set((img.flatten())))
成功训练在终端显示如下:
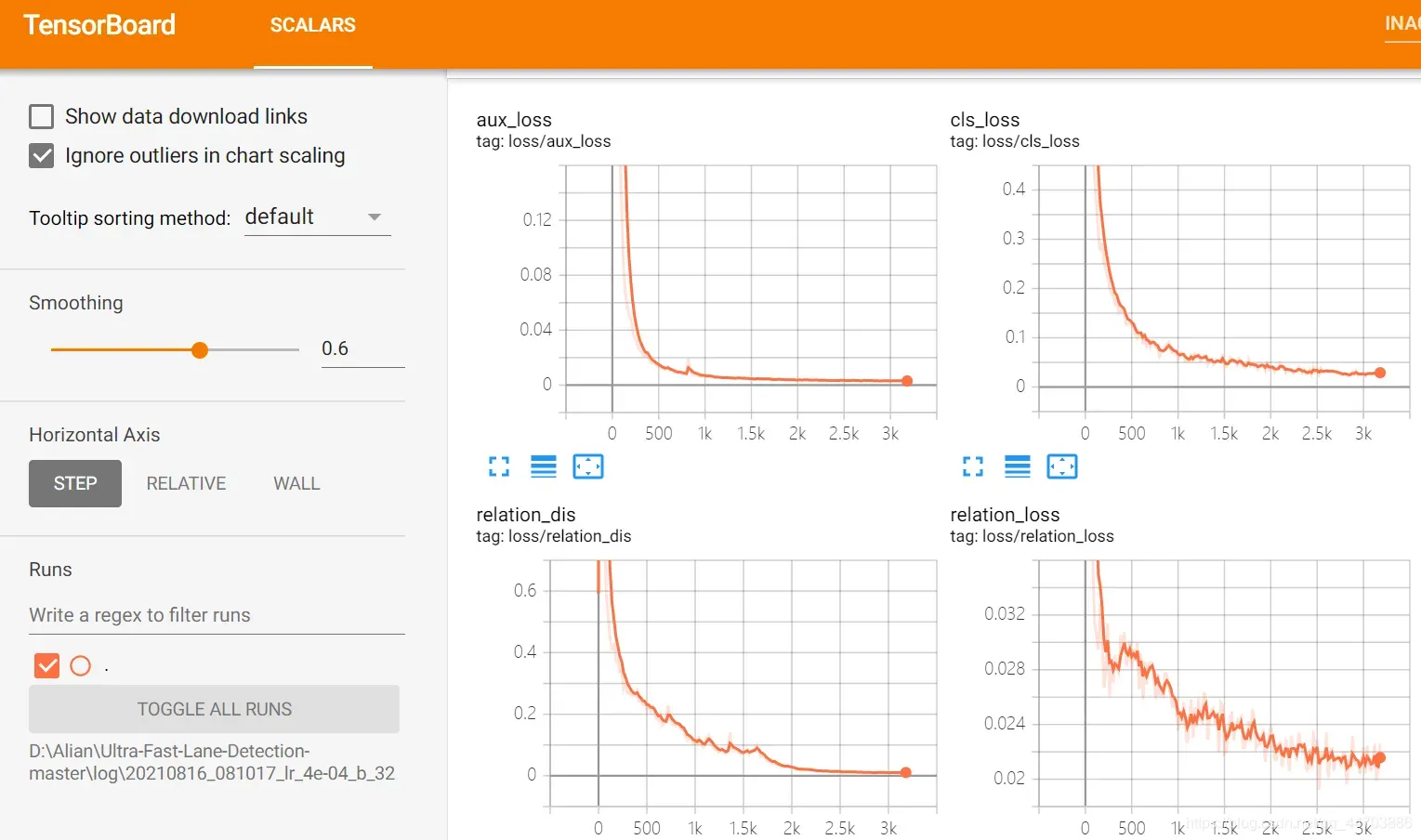
5.3 可视化训练过程
tensorboard --logdir=D:\Alian\Ultra-Fast-Lane-Detection-master\log\20210816_081017_lr_4e-04_b_32 # events.out.tfevents保存路径
后记
综上基本就实现了Ultra-Fast-Lane-Detection 的复现
文章出处登录后可见!