

文章目录
- CIFAR10数据集准备、加载
- 搭建神经网络
- 损失函数和优化器
- 训练集
- 测试集
- 关于argmax:
- 使用tensorboard可视化训练过程。
- 完整代码(训练集+测试集):
- 程序结果:
- 验证集
- 完整代码(验证集):
CIFAR10数据集准备、加载
解释一下里面的参数 root=数据放在哪。 train=是否为训练集 。 download=是否去网上下载。
里面的那个 transform 就是转换数据类型为Tensor类型。
准备一个测试集 一个训练集 自动从网上下载好。 大概160MB左右。图片大小是32*32的RGB格式。
train_data = torchvision.datasets.CIFAR10(root='../data', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root='../data', train=False, transform=torchvision.transforms.ToTensor(),
download=True)
然后我们加载数据集,使用DataLoader。
设置 mini-batch为64.
然后再看一下训练集和测试集的数据集个数。
# DataLoader加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
print("训练集的长度:{}".format(len(train_data)))
print("测试集的长度:{}".format(len(test_data)))
搭建神经网络
使用网上给的图片搭建神经网络,下图。
使用Sequential组合的方法写每个网络。
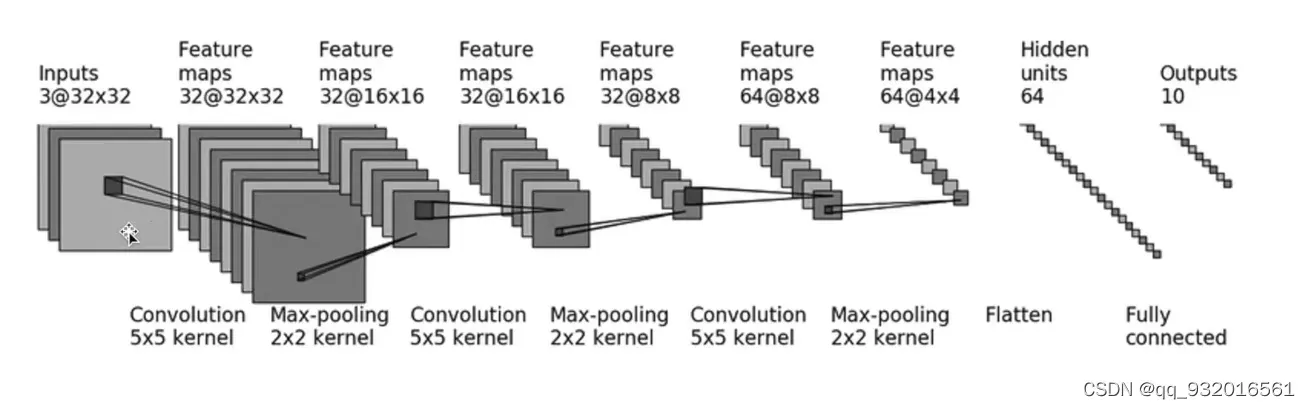

# 搭建神经网络
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10),
)
def forward(self, x):
x = self.model(x)
return x
损失函数和优化器
使用交叉熵做为损失函数,并且放到GPU上一会做训练。
# 损失函数
loss = nn.CrossEntropyLoss().cuda()
# 优化器
optimizer = torch.optim.SGD(model.parameters(),lr=0.01,)
训练集
这里的训练集开头有一个 model.train() 就是训练集循环开头写这个。也可以不写,不过规范要写上。
model.train() # 也可以不写,规范的话是写,用来表明训练步骤
for data in train_dataloader:
# 数据分开 一个是图片数据,一个是真实值
imgs,targets = data
imgs = imgs.cuda() # 放到GPU上一会训练用
targets = targets.cuda()
# 拿到预测值
output = model(imgs)
# 计算损失值
loss_in = loss(output,targets)
# 优化开始~ ~ 先梯度清零
optimizer.zero_grad()
# 反向传播+更新
loss_in.backward()
optimizer.step()
测试集
也和上面一样。测试集前面加了一句 model.eval() 就是表明这是测试集,也可以不写,规范就写上。
这里我们使用了accurate记录当前正确的个数。然后除以总个数就是正确率了。
accurate = 0
model.eval() # 也可以不写,规范的话就写,用来表明是测试步骤
with torch.no_grad():
for data in test_dataloader:
# 这里的每一次循环 都是一个minibatch 一次for循环里面有64个数据。
imgs , targets = data
imgs = imgs.cuda()
targets = targets.cuda()
output = model(imgs)
loss_in = loss(output,targets)
sum_loss += loss_in
accurate += (output.argmax(1) == targets).sum()
其中的 sum() 就是 计算其中每一个概率是否和我们的targets,即真实值相等,sum() 将batch里面64个数据的判断结果相加。
关于argmax:
这里的output.argmax(1) 就是求output 在 axis=1方向上的最大值,返回其索引。
可以打印输出看一下output的值,由于这是在for循环里面的output所以output肯定就是我们设置的batch的大小 一共64个。每一个都应该是有10个数据组成的一维数组,这十个数代表十个分类的概率。
我们打印看一下:
找到最大值是1.2819,然后返回他的索引值5。
[-0.98575, 0.32747, 0.52469, 1.0626, 0.09937, 1.2819, 0.7109, -0.34366, -1.4924, -1.4262]
使用tensorboard可视化训练过程。
使用SummaryWriter:
#添加tensorboard可视化数据
writer = SummaryWriter('../logs_tensorboard')
在训练集里添加:
if num_time % 100 == 0:
writer.add_scalar('看一下训练集损失值',loss_in.item(),num_time)
在测试集里添加:
writer.add_scalar('看一下测试集损失',sum_loss,i)
writer.add_scalar('看一下当前测试集正确率',accurate/len(test_data)*100,i)
i +=1
别忘了 writer.close() 关闭tensorboard。
最后使用 torch.save保存训练结果。
完整代码(训练集+测试集):
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root='../data', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root='../data', train=False, transform=torchvision.transforms.ToTensor(),
download=True)
print("训练集的长度:{}".format(len(train_data)))
print("测试集的长度:{}".format(len(test_data)))
# DataLoader加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 搭建神经网络
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10),
)
def forward(self, x):
x = self.model(x)
return x
# 创建网络模型
model = Model().cuda()
#添加tensorboard可视化数据
writer = SummaryWriter('../logs_tensorboard')
# 损失函数
loss = nn.CrossEntropyLoss().cuda()
# 优化器
optimizer = torch.optim.SGD(model.parameters(),lr=0.01,)
i = 1 # 用于绘制测试集的tensorboard
# 开始循环训练
for epoch in range(30):
num_time = 0 # 记录看看每轮有多少次训练
print('开始第{}轮训练'.format(epoch+1))
model.train() # 也可以不写,规范的话是写,用来表明训练步骤
for data in train_dataloader:
# 数据分开 一个是图片数据,一个是真实值
imgs,targets = data
imgs = imgs.cuda()
targets = targets.cuda()
# 拿到预测值
output = model(imgs)
# 计算损失值
loss_in = loss(output,targets)
# 优化开始~ ~ 先梯度清零
optimizer.zero_grad()
# 反向传播+更新
loss_in.backward()
optimizer.step()
num_time +=1
if num_time % 100 == 0:
writer.add_scalar('看一下训练集损失值',loss_in.item(),num_time)
sum_loss = 0 # 记录总体损失值
# 每轮训练完成跑一下测试数据看看情况
accurate = 0
model.eval() # 也可以不写,规范的话就写,用来表明是测试步骤
with torch.no_grad():
for data in test_dataloader:
# 这里的每一次循环 都是一个minibatch 一次for循环里面有64个数据。
imgs , targets = data
imgs = imgs.cuda()
targets = targets.cuda()
output = model(imgs)
loss_in = loss(output,targets)
sum_loss += loss_in
print('这里是output',output)
accurate += (output.argmax(1) == targets).sum()
print('第{}轮测试集的正确率:{:.2f}%'.format(epoch+1,accurate/len(test_data)*100))
writer.add_scalar('看一下测试集损失',sum_loss,i)
writer.add_scalar('看一下当前测试集正确率',accurate/len(test_data)*100,i)
i +=1
torch.save(model,'../model_pytorch/model_{}.pth'.format(epoch+1))
print("第{}轮模型训练数据已保存".format(epoch+1))
writer.close()
程序结果:
可以看到训练30轮之后的正确率逼近64%。
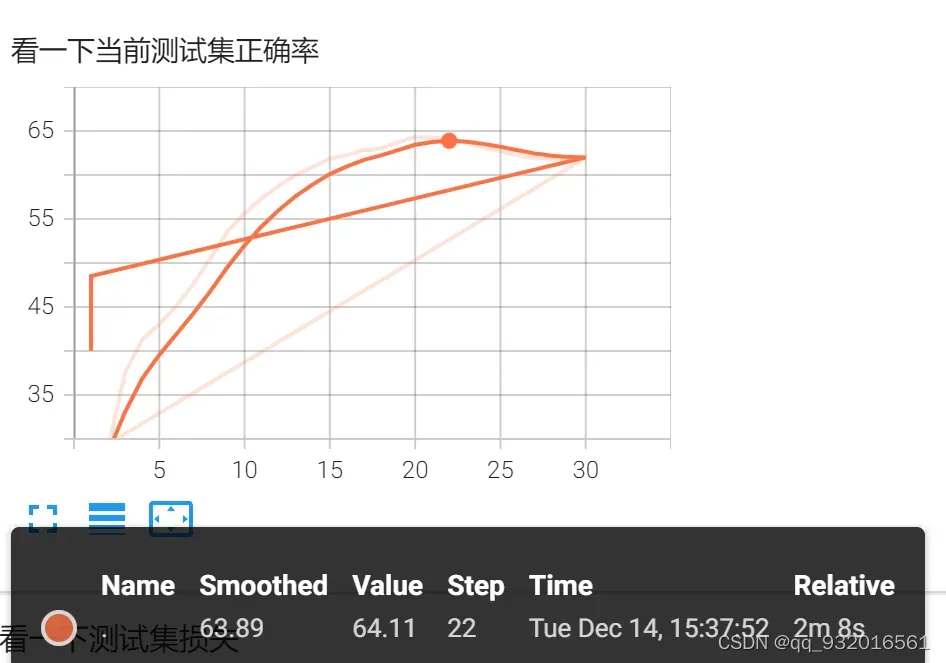

也可以看到每次训练的模型数据都保存了起来,方便后面验证。

验证集
本次使用图片:
首先PIL方法导入图片。image = Image.open('../data/plane.png')

这里其实可以看一下图片格式数据:
# print(image) #<PIL.PngImagePlugin.PngImageFile image mode=RGBA size=719x719 at 0x1BB943224C0>
可以看到 是 RGBA的格式 并且图片尺寸是719 * 719的。
我们需要转换成 RGB格式 大小是32 * 32的。
转换成RGB格式:
image = image.convert('RGB')
然后使用Compose组合改变数据类型:
先变成32*32 再变成tensor类型数据。
# 定义 Compose
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()])
# 放入我们要改变的数据
image = transform(image)
放入我们要验证的数据:
这里使用了 torch.no_grad() 表示 后面的过程不需要梯度等优化数据。
with torch.no_grad():
image = image.cuda()
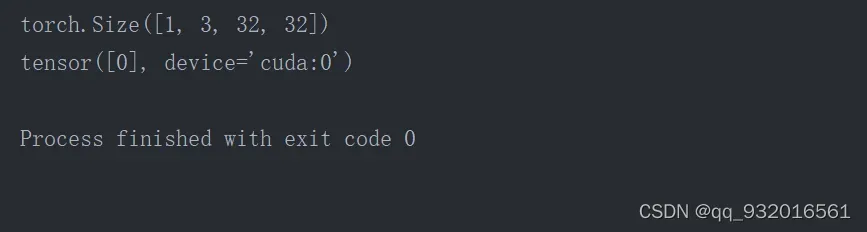
output = model(image)
print(output.argmax(1))
可以看到输出结果。表示验证结果是第0个类型。
我们可以调试看一下CIFAR10的数据集数字对应的图片是什么图片。
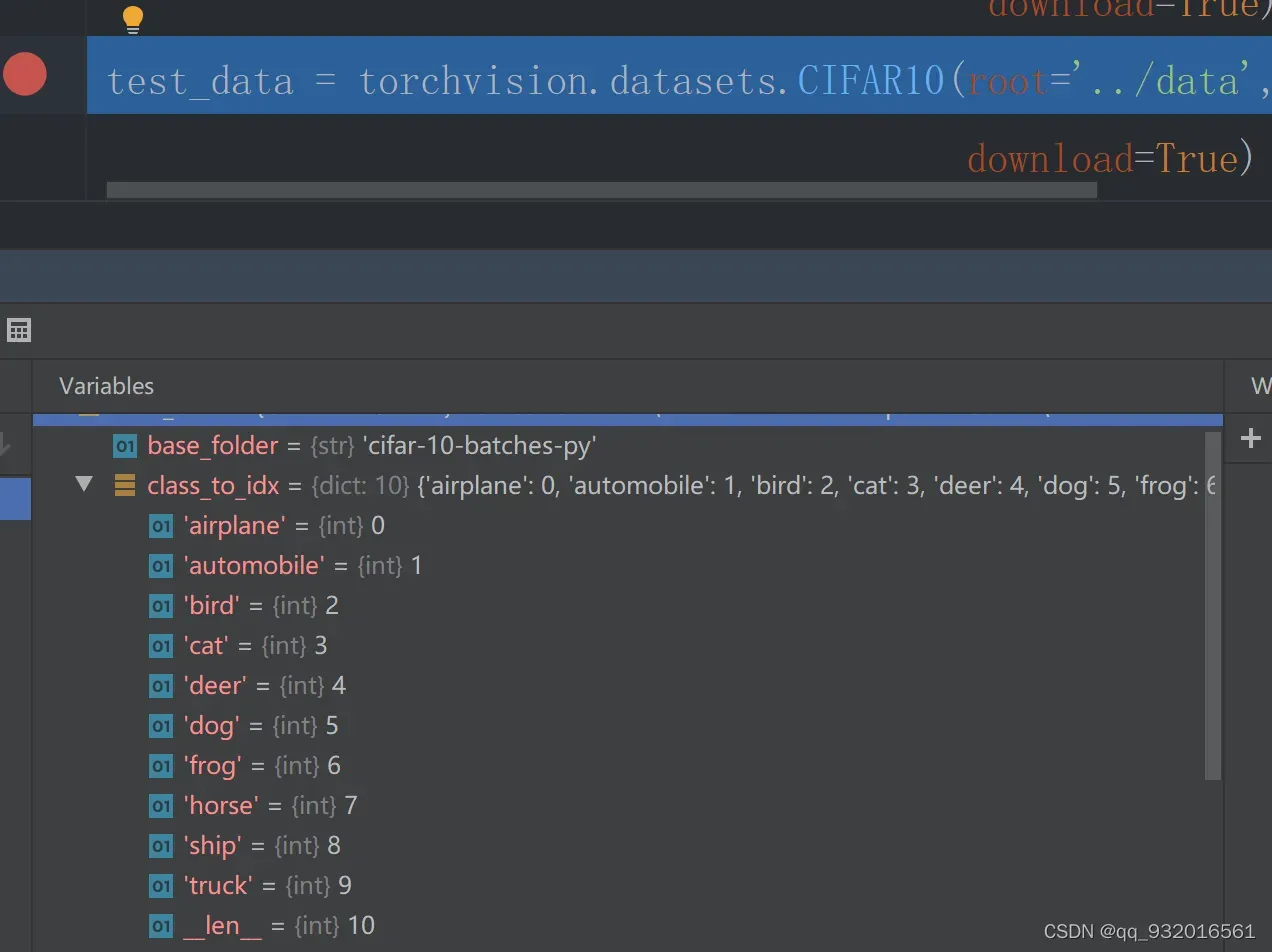
显然第0个就是代表飞机。验证成功。


后面我们又换了一个猫的图片,然后验证出来是5号dog,验证出错了。毕竟正确率只有64%。
我训练了30轮,用笔记本的GPU跑的,1650的GPU,那风扇咔咔转,最近梯子用不了了,就不上云了。
完整代码(验证集):
import torchvision
from torch import nn
import torch
from PIL import Image
# 把这个模型拿过来 防止模型加载的时候报错
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10),
)
def forward(self, x):
x = self.model(x)
return x
image = Image.open('../data/plane.png')
# print(image) #<PIL.PngImagePlugin.PngImageFile image mode=RGBA size=719x719 at 0x1BB943224C0>
# 这里可以看到输出是ARGB类型,四通道,而我们的训练模式都是三通道的。
# 所以这里使转换成RGB三通道的格式
image = image.convert('RGB')
# 使用Compose组合改变数据类型,先变成32*32的 然后在变成tensor类型
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()])
image = transform(image)
model = torch.load('../model_pytorch/model_30.pth') # 这里面输出的话就是保存的各种参数。
image = torch.reshape(image,(1,3,32,32))
print(image.shape)
model.eval()
with torch.no_grad():
image = image.cuda()
output = model(image)
print(output.argmax(1))
这里有个小坑。使用save保存的网络模型,加载的时候必须吧网络模型类定义也写出来,不然会直接报错。
还有一个字典形式保存模型的方法那个就不用再写一遍定义,不过字典这个方法不是很熟。
文章出处登录后可见!