基于深度学习的映前票房预测模型(Cross&Dense网络结构模型),该模型通过影片基本信息如:电影类型、影片制式、档期和电影的主创阵容和IP特征等信息对上映影片的票房进行预测。
本篇采用451部电影作为训练模型,最后再在194部影片上进行测试,模型的绝对精度为55%,相对精度为92%。该模型在使用相同的特征的情况下好于SVM、随机森林等算法。上升了至少5%。同时还对模型进行了超参调优工作,通过实验发现:当模型的批大小为128,学习率设置为0.001,迭代次数设置为150,多任务调节权重为0.4的时候预测效果最好。通过该模型对映前票房的成功预测将对影片的制作发行和放映有着重要的指导意义。
01、数据探索
选取2013—2016年在国内上映的影片。票房过小的影片一方面研究价值较低,另一方面存在着严重的特征缺失的问题,所以只筛选了票房超过一千万的影片作为研究对象,最终经过筛选最后共有645部。从互联网上采集了电影的特征(类型、播放制式、上映时间、主创人员信息、发行放映信息和网络口碑等数据),这些数据主要来自于豆瓣网、时光网和猫眼电影专业版和微博电影。这些特征包括连续数据和离散的类别数据。
从图1中可以发现,电影票房收入相差比价大,大部分电影的票房集中在1千万到5亿这个范围内,极少数电影可以超过10亿票房。票房数据的偏度为3.71,峰度为21,因此要研究的票房数据偏离正态分布,呈现出右偏态,同时也可以发现该数据峰度值远大于0,分布比较陡峭,如表1所示。
表1 连续变量统计表
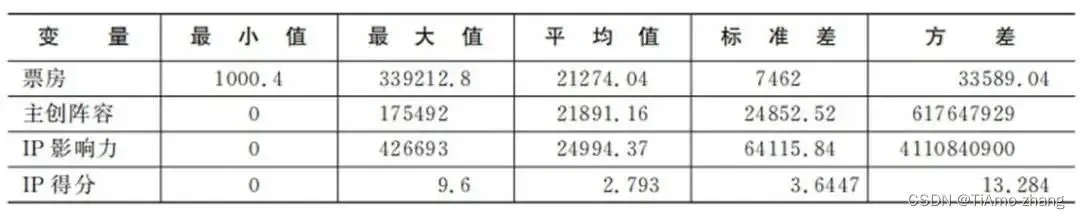
■ 图1 票房直方图
1●连续变量
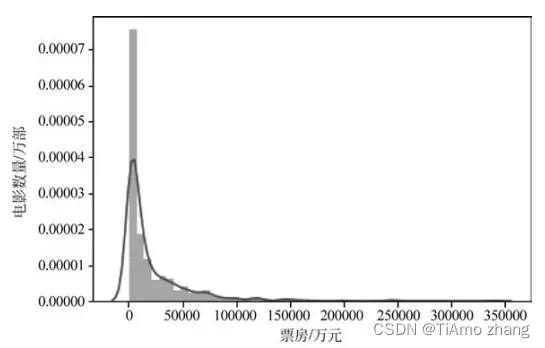
如图2所示,分析连续变量和票房的关系可以发现采集的连续变量和票房之间没有明显的线性关系,这也是票房预测一直没有取得特别精确的原因之一,同时采集了2015年和2016年的微博指数数据,使用全部数据进行建模时存在缺失值过多,使用两年数据建模时性能较低情况,所以最后舍弃。
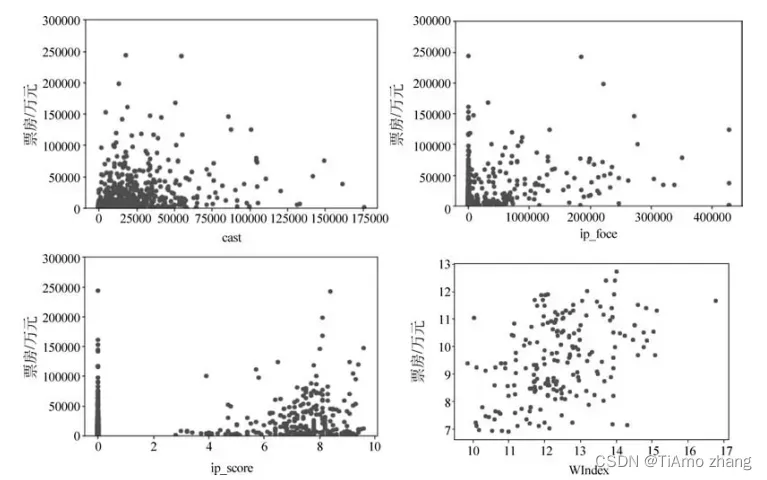
■ 图2 连续特征与票房关系散点图
2●离散特征
各个离散变量和票房之间的箱型图可以直观地展示这些变量和票房的关系,为了便于画图,对票房数据进行取对数处理。其中表2展示了电影类型、电影制式等特征,图3给出了票房的箱型图。
表2 样本中各类型影片占比及平均票房表
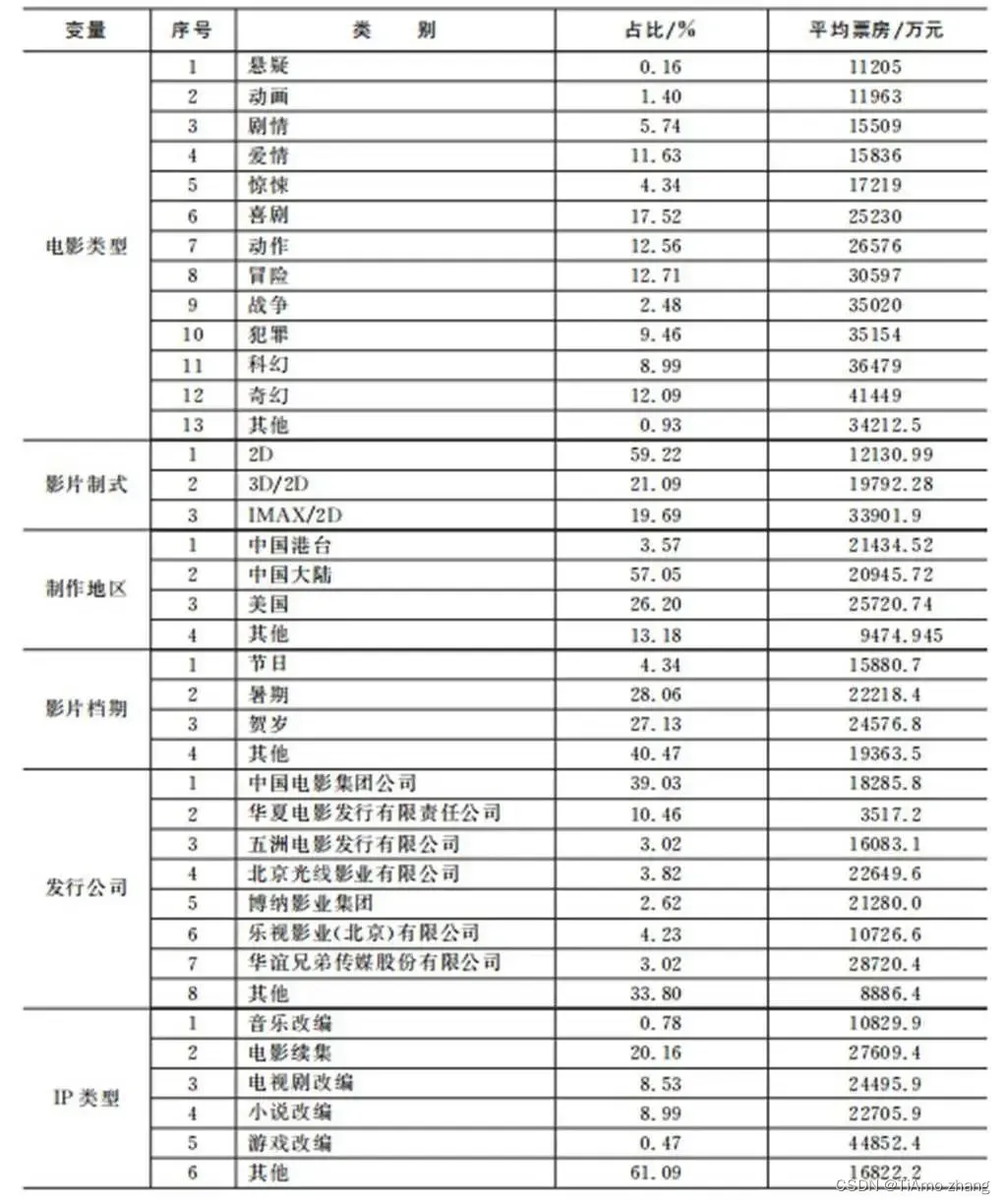
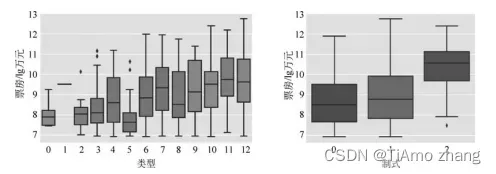
■ 图3 离散特征和票房箱型图
02、模型设计
为了获得一个有效的票房预测模型,将连续的票房值进行了离散化处理。基于实际需求和模型构建要求将票房离散化成为4个区域,如表3所示。
表3 电源票房分区表
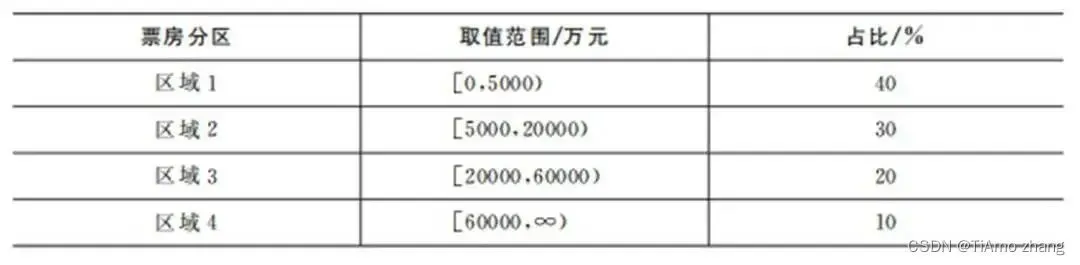
图4 为基于深度学习的电影票房预测模型框架
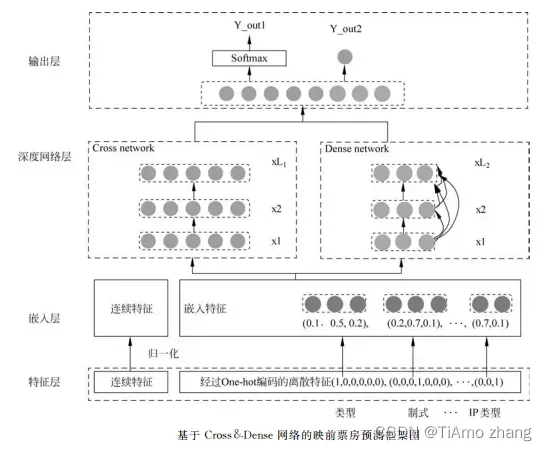
■ 图4 基于 Cross&Dense 网络的映前票房预测框架图
1●特征层
由于连续特征中各个特征有着不同的量纲和量纲单位,即取值范围存在巨大的差异,例如网络口碑取值范围是[0,10],而主创阵容的取值范围为[0,175492]。这种情况会影响网络训练的精度效率,所以在特征层对连续特征做了归一化处理,使各个特征处于同一个数级。使用标准归一化方法处理后的特征服从标准正太分布,特征的取值范围为[-1,1]:

其中,μ为该特征的均值,δ为该特征的标准差。
对于离散特征进行了one-hot编码。
2●嵌入层
在嵌入层对经过编码的离散特征进行了嵌入计算,具体的处理细节如表4所示。
表4 嵌入层参数设置表

3●深度网络层
电影票房模型使用的深层网路的结构细节如下:深度网络使用了3层,其中每层的神经单元数为50、25和10。稠密跳接网络的深度为4,每层增加的神经元个数都设置为50。同时为了防止模型过拟合使用了dropout技术,dropout的参数本文设置为0.3。
4●输出层
多任务学习是一个在机器学习领域很早就被提出的技术,之前常被应用于决策树、随机森林和神经网络中。它是一种归纳转移的方法,使用包含在相关任务的训练数据中的信息来改善泛化能力,使用并行学习但用分享特征表示,每个任务学习到的特征表达和知识可以帮助更好地学习其他任务[35]。随着深度学习技术的发展,多任务学习技术也成了一个研究的热点。为了提高预测准确率,针对电影票房预测这一问题,对上文中提出的预测框架进行了进一步的改进,引入了多任务学习技术。
(1)任务一:预测电影票房属于每个区域的概率;
(2)任务二:预测票房的实际值。框架中具体的实现方式是,在输出层输出两个预测结果:Y_out1通过softmax层输出多分类的预测结果,损失函数使用常用的多类的对数损失(对应于keras中的categorical_crossentropy);Y_out2通过一层神经网络输出票房的预测值,该预测值为连续的实数对应于票房的真实值,损失函数使用平均绝对值误差(对应于keras中的mean_absolute_error)。
其中,softmax是一种常用于多分类的方法

softmax层输出为该影片属于每一个类的概率,输出为4个类别,所以Y_out1向量表示有y=1、y=2、y=3和y=4的概率,概率最大的那个类别为最终的预测结果。Y_out2输出的预测值和用来训练的票房真实值,采取了取对数的运算,使得模型更优。因此,在输出层这两个输出共享下面的网络和这些网络表征的特征和知识。在训练阶段,设计的模型最小化这两个损失的加权和

其中,参数γ被用来调节两项损失函数的权重。
03、实例验证
1●票房预测分类性能指标
针对多分类问题,研究人员常用混淆矩阵和根据混淆矩阵得到的绝对精度(Bingo)和相对精度(1-Away)来分析分类器的性能优劣。绝对精度准确预测到实际类别的影片个数占整个实际类别影片总数的比率。相对精度准确预测到对应的区间(相邻类别)的影片个数占整个实际类别影片总数的比率。
2●超参数调优
本实验对以下参数进行了分析、实验调优,这些参数包括批大小、学习率、迭代次数及γ。同时以下部分都用箱线图的方式展示,每个实验都重复20次,以保证实验结果的可信。将实验数据以7∶3的比例,随机分成了测试集和训练集,其中训练集共有451部电影,测试集共有194部电影。同时使用了箱形图来展示实验结果,箱形图又称为盒须图或箱线图,可以展示多次实验的统计结果,也可以展示多次实验结果的最大值、最小值、两个四分位数和中位数。
(1)批大小调优:在模型训练时,在每个迭代中,模型的参数需要在每批数据处理结束后进行更新。参数的更新基于每批数据的平均误差,所以每批数据的数据量大小对模型的训练有重要的影响。如图5所示,通过实验可以发现,随着批大小的增加,训练得到的模型在测试集上的预测分类效果越来越好。当批大小为128时模型取得了最好的效果,之后随着批大小的增加模型效果下降。
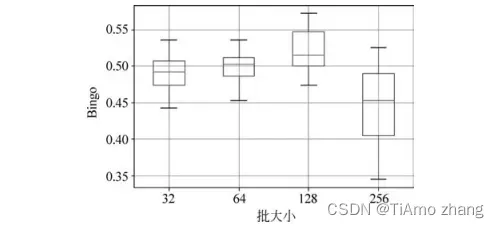
■ 图5 批大小对模型效果的影响(迭代次数=200,学习率=0.001,γ=0)
(2)学习率调优:在模型训练时,学习率对参数的更新速度有重要的影响,如图6所示,随着学习率的减小,训练得到的模型在测试集上的预测分类结果越好。
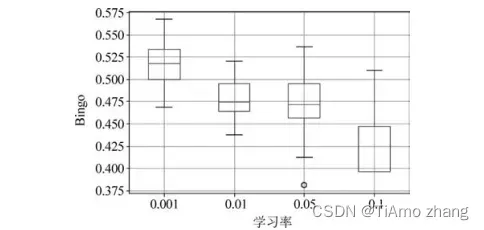
■ 图6 学习率对模型效果的影响(批大小=128,迭代次数=200,γ=0)
(3)迭代次数调优:如图7所示,随着迭代次数的增加,训练得到的模型在测试集上的预测精度越来越高,当迭代次数为150时,预测分类效果最好,之后当迭代次数为200时预测准确率降低。
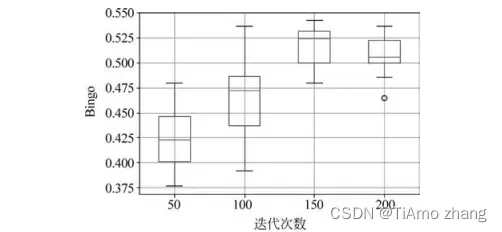
■ 图7 迭代次数对模型效果的影响(批大小=128,学习率=0.001,γ=0)
(4)γ调优:在模型训练时,γ影响着多任务学习中两个损失函数的权重。如图8所示,随着γ的增加,模型的预测能力逐渐提高,在0.4时模型获得最好的预测效果,然后模型预测效果逐渐降低。当取值0时,模型预测分类效果明显降低,这是由于模型只考虑回归的损失函数。
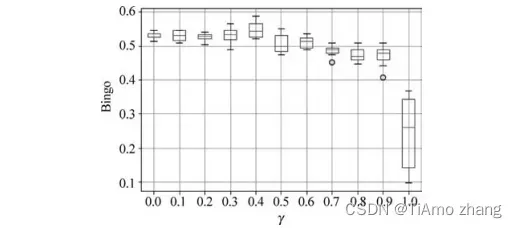
■ 图8 γ对模型效果的影响(批大小=128,迭代次数=150,学习率=0.001)
3●票房预测分类结果及分析
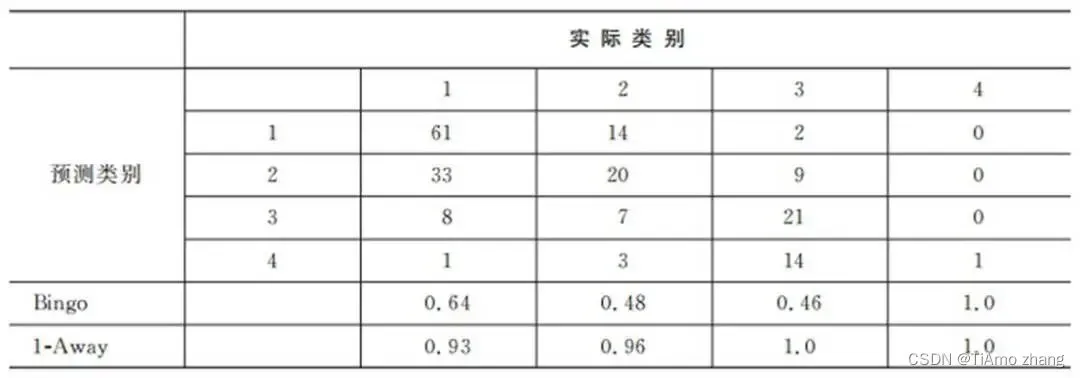
对模型的超参数做了如下设置:学习率设置为0.001,批大小为128,迭代次数为150,γ为0.4。表5为实验票房分类预测效果的混淆矩阵,实验结果表明该预测模型的绝对精度还需要提高,但是相对精度较高。
表5 票房预测分类结果混淆矩阵表
为了说明模型的有效性,进一步将模型与现有的几种算法SVM、决策树CART、随机森林算法进行了对比,先使用训练集对模型进行了训练,然后在测试集上计算了每种算法的准确率。其中SVM、决策树和随机森林使用了Python程序库sklearn中的程序实现的。SVM中参数选择为C=1.0,cache_size=200。决策树选择树的最大深度为5,随机森林选择树的子树的数量为20,树的深度为10。DNN算法采用多层全连接网络,该网络由4层神经网络构成,每层的神经单元数为100、50、25和20,激活函数使用Relu函数。
具体的实验结果如表6所示,为了试验的可靠性,每个算法都经过20次试验然后取其平均值作为最后的预测效果。
表6 电源票房数据集上几种算法预测效果表
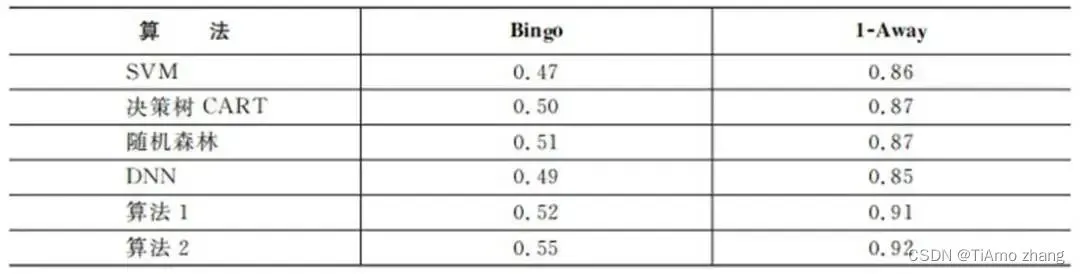
如表6所示,通过实验可以发现,该算法更加能够充分利用特征中的信息,同时新的框架相对于普通的DNN网络,更加适用于离散类别特征数据,能够提升3%,也证明了这种框架可以更好地将深度学习应用于含有离散类别数据的分析中。同时,将多任务学习引入之后,回归和分类结果可以共享下层网络的参数和提出的特征和知识,能够有效地提高预测分类的效果,在本实验中提高了3%。
文章出处登录后可见!