

大家好,今天我们用python分析下周杰伦歌曲。为了尽量完整地呈现从原始数据到可视化的过程,接下来我们会先简单讲解数据的预处理过程,即如何将 JSON 数据转化为Excel 格式,以及如何对周杰伦的歌曲进行分词。
本案例中的歌词数据来自中文歌词数据库,这个数据库提供了华语歌手的歌曲及歌词信息,数据以 JSON 格式存储。
数据预处理指的是将原始数据处理成我们希望的格式,并提取出我们需要的信息。
在本案例中,我们需要先从数据库中筛选出演唱者为周杰伦的歌曲,然后获得这些歌曲的歌词,并将它们存储到纯文本文档(.txt 格式)中,以下提供两种方法。
第一种方法,先把 JSON 文件转换为 Excel 可以打开的 .csv 文件或 .xlsx 文件格式。这可以借助一些在线的转换工具完成(如 JSON to CSV Converter)。一般而言,只需将文件拖入这些工具,选择好转换格式类型,即可转换完成。接着,我们便可以在 Excel 中打开该数据,然后单击“数据→筛选”命令,选择歌手为“周杰伦”的歌曲。之后,选中它们的歌词,并将其粘贴到纯文本文档中。
第二种方法,通过 Python 进行数据预处理。首先,需要引入 JSON 库(未安装者通过 pip install json 安装)。
import json然后,读取我们下载的 JSON 文件,存储在名为 data 的变量中。
with open(‘ lyrics.json’ , ‘ r’ ) as f:
data = json.load(f)接着,遍历 data 中的每一项,找出“歌手”=“周杰伦”的数据项,存到data_zjl 中。
data_zjl = [item for item in data if item[‘ singer’ ]==’ 周杰伦’ ]
print(len(data_zjl))建立一个空列表 zjl_lyrics,用于存储歌词。遍历 data_zjl 中的每一首歌,将它们的歌词存到 zjl_lyrics 中。
Zjl_lyrics = []
for song in data_zjl:
zjl_lyrics = zjl_lyrics + song[‘ lyric’ ]最后将 zjl_lyrics 写入一个新的 .txt 文件。
with open(“ zjl_lyrics.txt” , “ w” ) as outfifile:
outfifile.write(“ \n” .join(zjl_lyrics))通过这几行代码,我们就获得了周杰伦所有歌曲的歌词数据(见图1)。以这个 .txt 文件为基础,我们便可以进行词频统计了。

以下附上一种在 Python 中分词的方法。首先引入 jieba 库(安装 :pip install jieba)、pandas 库(安装 :pip install pandas)、用于频次统计的 Counter 库,以及表单工具,代码如下:
import jieba
import jieba.analyse
import pandas as pd
from collections import Counter事先准备好一个中文的停用词表(.txt 文件,里面包含一些常见的、需要过滤的中文标点和虚词,可在网上下载),代码如下:
with open(‘ chinese_stop_words.txt’ ) as f:
stopwords = [line.strip() for line in f.readlines()]打开歌词文件,利用 jieba 库进行分词。分词之后,删除停用词、去除无用的符号等。用 Counter 库对清洗干净的词语进行频次统计。然后将统计结果用 pandas库转换为数据表单,存储为 Excel 文件,代码如下:
fifile = open(“ zjl_lyrics.txt” ).read()
words = jieba.lcut(fifile, cut_all=False, use_paddle=True)
words = [w for w in words if w not in stopwords]
words = [w.strip() for w in words]
words = [w for w in words if w != ‘ ’ ]
words_fifilter = [w for w in words if len(w) > 1]
df = pd.DataFrame.from_dict(Counter(words_fifilter), orient=’ index’ ).
reset_index()
df = df.rename(columns={‘ index’ :’ words’ , 0:’ count’ })
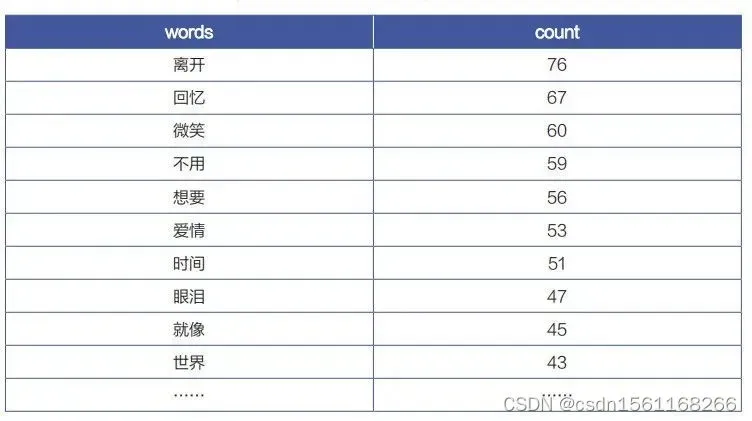
df.to_excel(“ 周杰伦分词结果 .xlsx” )由此,如下表所示,我们便获得了分词后的单词及词频。使用这个文档,我们就可以开始制作可视化了。

由于是文本类数据,我们首先想到的可视化形式可能是文字云。如果你使用 Python,则可以直接基于刚才的分析结果,调用wordcloud库绘制文字云,代码如下:
from wordcloud import WordCloud
# 注 :这里需要引入一个中文字体,否则会乱码
wc = WordCloud(font_path = ‘ Alibaba-PuHuiTi-Regular.ttf’ ,
background_color=” white” ,
max_words = 2000)
wc.generate(‘ ‘ .join(words_fifilter))
import matplotlib.pyplot as plt
plt.imshow(wc)
plt.fifigure(fifigsize=(12,10), dpi = 300)
plt.axis(“ off” )
plt.show()绘制结果如图所示:


不过,在代码工具内绘制文字云,进行定制化设计相对比较复杂。因此,也可以借助一些在线工具帮助我们实现更好的可视化效果。下面,我们以微词云为例进行演示。
进入微词云界面后,首先单击“导入单词”,进行数据导入。选择“从 Excel 中导入关键词”,然后上传我们刚才得到的包含单词和词频的 Excel 文档(需要注意的是,微词云目前对上传的 Excel 文件格式有一定要求,比如,列名必须叫“单词”和“词频”才能识别,详见其页面指引),即可生成文字云。
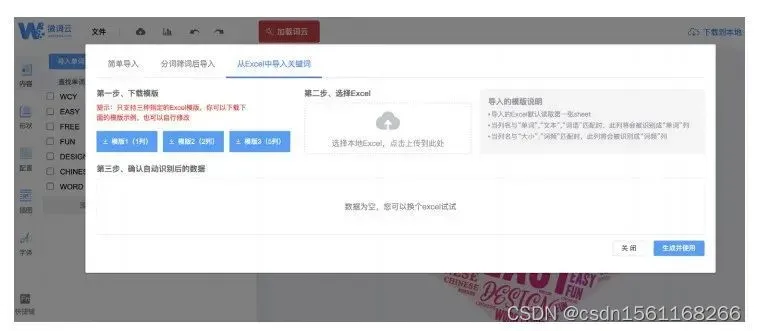

可以看到,微词云的页面上还有另外两种导入数据的选项。其中,“简单导入”支持用户输入用逗号隔开的单词。“分词筛词后导入”则支持用户粘贴长文本,然后由系统自动进行分词和词性判别。换句话说,如果你有一个文档文件,也可以直接粘贴进微词云进行分词。
接下来我们用周杰伦的歌词文档来尝试一下。选择“分词筛词后导入”,然后将之前的 .txt 格式的文档粘贴进微词云。之后,单击“开始分词”,软件就会自动把词语切割出来,并按词性归类,结果如下图所示。
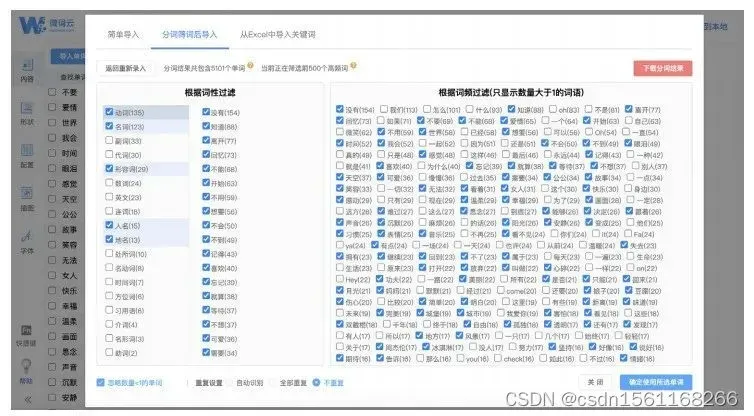

可以看到,所有的词语被按照动词、名词、形容词、人名等归类。词语后面的括号标注了词频。同时,微词云还自动帮我们把高频的词汇勾选出来。我们也可以根据个人需求,在这个界面中进一步编辑,例如只显示名词、只显示动词等,然后单击“确定使用所选单词”按钮,即可生成词云。
之后,我们可以在“配置”栏中编辑词云的显示方式。其中,“计算模式”指的是字体的大小是否严格与词频匹配,因此我们选择“严格比例”。另外,我们还可以更改文字的颜色,以及文字云中单词的数量等。在本案例中,我们把单词数量调整到 200。调整完毕后,单击右上角的“下载到本地”按钮即可。
![]()

当然,虽然词云在视觉上比较有趣,但在展示数据上却不一定清晰。因此,我们也可以使用其他的图表来进行可视化。比如,可以用圆面积来展示最高频的词汇。
以上,我们讲解了使用 Python 分词和使用在线工具分词的两种方法,大家可以根据本案例进行学习。
文章出处登录后可见!