

目录
介绍
步骤
观察网页内容:
方法一:直接使用pandas的.read_html方法读取表格:
方法二:使用request请求数据并解析:
总结:
介绍
假期进行一些爬虫的小练习,其中第一个设计到了网页表格的爬取。
用request请求得到数据之后直接xpath或者bs4进行解析就可以。
步骤
观察网页内容:
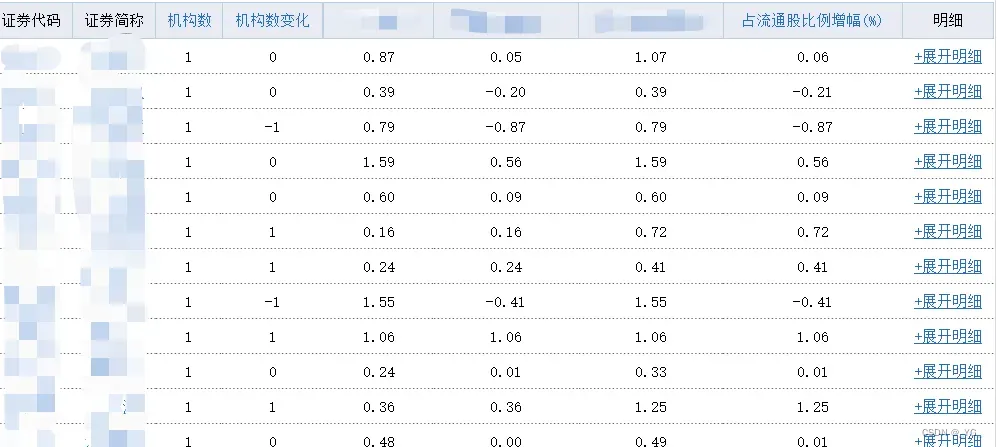

查看一下组成,发现数据在一个table里面,表格头就是thead,内容在tbody里面。
方法一:直接使用pandas的.read_html方法读取表格:
def pd_read_html(url):
df=pd.read_html(io=url)
print(df)直接能够得到dataframe格式的数据,处理之后可以用
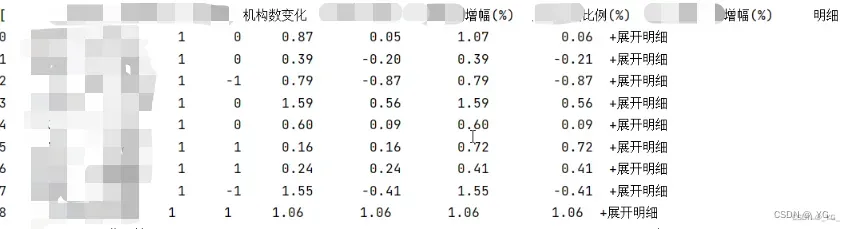

方法二:使用request请求数据并解析:
首先爬取表格头的内容:


打印thead里面的内容,发现有的在td,有的在td的子标签,是因为前端不同显示格式的要求,构造xpath路径的时候直接将td,还有子路径里面的内容都涉及到就好了。/text和//text分别表示td的内容还有td子标签的内容。
#爬取表格头:
tr_list_title=tree.xpath('//*[@id="dataTable"]/thead/tr/td/text() | //*[@id="dataTable"]/thead/tr/td//text()')
再爬取表格的内容:
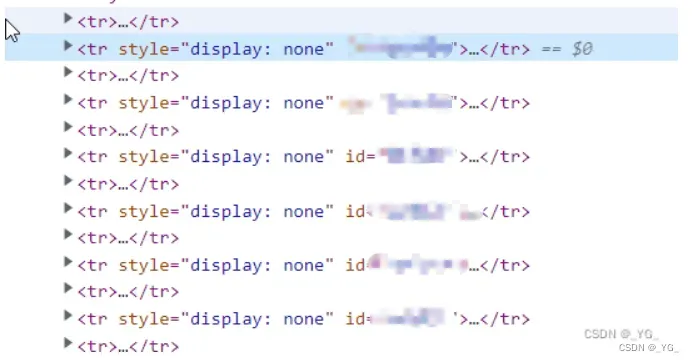

数据在tr标签里面存放,但是tr有id的仅是定位使用并没有数据存放。
自己用了一个比较笨的办法,直接使用range方法把自己需要的tr筛选出来。
#定位tr的函数
def get_tr(x):
# print('//*[@id="dataTable"]/tr[%s]' %x)
text1=tree.xpath('//*[@id="dataTable"]/tr[%s]//text()' %x)
text2=tree.xpath('//*[@id="dataTable"]/tr[%s]/text()' %x)
text=[]
text.append(text1)
return(text)
#使用range定位需要的tr标签
for i in range(1,80,2):
# tr_list_body.append(get_tr(i))
text_pre=get_tr(i)
print(text_pre)
for i in text_pre:
x=i[1:19:2]
body_list.append(x)
print(body_list)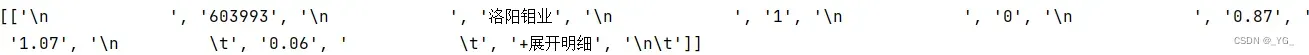

筛选出来之后再使用列表的切片,把有用的数据筛选出来。
最后直接构造成为dataframe,保存即可。同时也可以在每次取到一条数据的时候直接写入文档,这个方法在后续会有展示。
总结
1、思路还有过程都很简单,主要是再熟悉一下request还有数据解析的基本流程
2、任务要求比较简单,如果需要翻页或者定位操作可以使用selenium或者构造url,后面的爬虫会 有展示。
代码:
import numpy as np
from lxml import etree
import requests
import pandas as pd
#方法一函数,直接利用pd.read_html
def pd_read_html(url):
df=pd.read_html(io=url)
print(df)
if __name__ == "__main__":
url=''
headers={
'User-Agent':'*********************'
}
page_text=requests.get(url=url,headers=headers).text
# 数据解析
tree = etree.HTML(page_text)
# print(page_text)
#爬取表格头:
tr_list_title=tree.xpath('//*[@id="dataTable"]/thead/tr/td/text() | //*[@id="dataTable"]/thead/tr/td//text()')
#%%定义
title_list=[]
for i in tr_list_title:
title_list.append(i)
print(title_list)
# 爬取每一行内容
body_list=[]
text_pre=[]
#定位tr的函数
def get_tr(x):
# print('//*[@id="dataTable"]/tr[%s]' %x)
text1=tree.xpath('//*[@id="dataTable"]/tr[%s]//text()' %x)
text2=tree.xpath('//*[@id="dataTable"]/tr[%s]/text()' %x)
text=[]
text.append(text1)
return(text)
#使用range定位需要的tr标签
for i in range(1,80,2):
# tr_list_body.append(get_tr(i))
text_pre=get_tr(i)
# print(text_pre)
for i in text_pre:
x=i[1:19:2]
body_list.append(x)
print(body_list)
list_all=[]
for i in range(9):
list1 = []
for j in body_list:
list1.append(j[i])
list_all.append(list1)
dict=dict(zip(title_list,list_all))
print(dict)
df=pd.DataFrame(dict)
df.to_csv('text1.csv')
print(df)
文章出处登录后可见!
已经登录?立即刷新