

趁着寒假期间稍微尝试跑了一下yolov5和yolov7的代码,由于自己用的笔记本没有独显,台式机虽有独显但用起来并不顺利,所以选择了租云服务器的方式,选择的平台是矩池云(价格合理,操作便捷)
需要特别指出的是,如果需要用pycharm链接云服务器训练,必须要使用pycharm的专业版而不是社区版,专业版可以使用SSH服务连接云服务器。关于专业版的获取,据我所知一是可以买,二是如果你是在校大学生,可以用学生证向JetBrain申请专业版使用权,我就是通过这种方式激活专业版账户的,我记得当时两三天官方就发激活邮件了,还是很人性化的,使用期一年。
下面开始正题
本教程只涉及将yolov5及yolov7跑通,并不涉及yolov5及yolov7原理的讲解
yolov5:
首先GitHub上下载源码:https://github.com/ultralytics/yolov5
(这里使用的是yolov5-v6.0版本)之前也试过v5.0版本,可是有些报错一直无法解决,网上也说用更新的分支一些bug会被修改,遇到难以解决的bug也可以试试更新版本的代码。v6.0我是可以顺利跑通的,故以此为例。
环境搭建:
环境搭建一直一个比较麻烦的步骤,我也花了不少时间,因为本例可以直接使用云平台配置好的环境,可以不用麻烦自己搭建。在此稍微提一下:(建议将pytorch等必要库安装,原因后面再讲)
首先安装anaconda(安装教程不再赘述,csdn上帖子很全,但是注意一定要在windows系统环境中添加anaconda配置)
左下角windows开始处找到Anaconda文件夹,打开Anaconda Prompt(anaconda3),进入界面,输入
conda create -n pytorch python=3.7
如果有(y/N)一路输入y加回车,后面在这上面装东西基本都是
其中pytorch是自己搭建的环境名(可以改),这里建议选择python3.7版本(没有原因,但我用3.9有各种错误,3.7我用了没出错,编程用的这种都不建议装最新版,会有许多的兼容问题)

创建成功后输入
conda activate pytorch
可以看见进入了pytorch环境,当然这里是什么都没有的,只是个空壳
接下来进入pytorch官网PyTorch 在首页即可看到
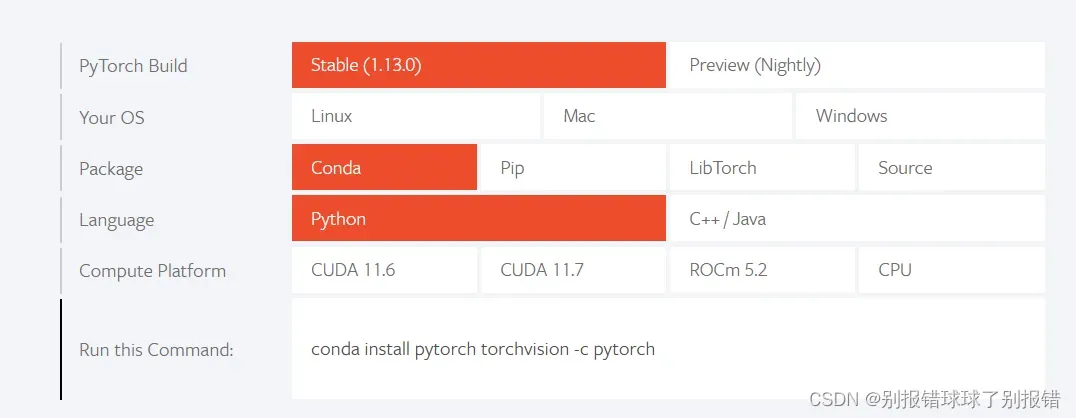

弟二行和第五行根据自己电脑配置的选择,看这篇帖子的大多数应该都是windows+CPU(如果电脑没有独显选CPU),然后复制最后一行的代码,复制到

回车键运行,如果有问(y/N)的地方一律按y,随后等待安装完成,最重要的pytorch就装好了。
这一步可能会卡在solving environment那不动,按其他帖子说的添加国内源还是没用,这时候在pytorch首页第四行,原来选Conda的地方改成Pip,复制pip指令下载应该就好了,我pytorch+cuda环境后来就是用pip下的。
这时候点开下载的代码,找到requirement.txt,pycharm一般会提示你按照requirement.txt安装相应依赖库,点一下等一会就好,也可以像安装pytorch那样,conda activate pytorch以后在自己的环境内
pip install xxx
的方式一个个安装,xxx为库的名称,如tensorflow、pandas等,而且当点开文件夹某个py文件上面报错,显示importxx库没有的时候,也可以通过这种方式安装缺失的库文件。注意依赖库的名称不要打错,如果遇到有些下载特别满或者下载出错的库,可以在conda环境中添加清华的源,下载会快些,详情可以直接在csdn上搜,帖子也很多
说一句题外话,我费了不少功夫将所有依赖库都装好了,包括有独显的台式机上cuda等部分都装好了,但是还是会遇到不少很奇怪且原因不是很明显的问题,很匪夷所思也很难解决(好像大部分和安装的各种库的版本有关),费很大功夫才完全解决。但是用云服务器配置好的环境很少出错,所以这也是为什么我最终选择云服务器训练,会少很多麻烦。(不要问为什么你全装好了还要选云服务器)
当把库安装完,准备工作就差不多结束了。
训练数据集:
同样地,通过anaconda安装labelimg(很简单,几乎不会有问题吧,教程csdn很多,不再赘述),我们通过labelimg对数据进行处理,简称贴标签

open dir选择自己照片存储的位置,change save dir选择标签保存位置,按w并拖动鼠标将目标框在框内,注意第8个选项要选pascal voc,保存的是xml文件(yolov5/yolov7数据集都是txt文件,软件左侧第八个也可以选成yolo,保存成txt,我是到后面才发现的,应该能直接用。但是如果大家怕出错就还是按这里先保存成xml文件吧)
技巧:假设你有多个分类,可以先固定画某一类的框,写好框名,如car,dog,person,然后点上方view,auto save mode 和single class mode,然后固定在所有数据上贴这一个标签,这样系统会自动帮你维持这一个标签,然后这个标签贴完,再把single class mode取消,再贴一个其他类目标,输入名称,然后再选single class mode 然后再贴这一类,方便一些。也就是一次贴一个标签
贴好以后我们可以正式开始改我们的代码了
代码部分:
首先在下载的文件夹中创建VOCData文件夹(自定义名称),然后在文件夹内创建两个文件夹Images和Annatations,前者放入自己准备的图片,后者放入用labelimg贴好的xml格式的标签,接着用pycharm打开文件夹,在VOCData下创建两个python文件:
import os import random import argparse parser = argparse.ArgumentParser() parser.add_argument('--xml_path', default='Annotations', type=str, help='input xml label path') parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path') opt = parser.parse_args() trainval_percent = 1.0 train_percent = 0.8 xmlfilepath = opt.xml_path txtsavepath = opt.txt_path total_xml = os.listdir(xmlfilepath) if not os.path.exists(txtsavepath): os.makedirs(txtsavepath) num = len(total_xml) list_index = range(num) tv = int(num * trainval_percent) tr = int(tv * train_percent) trainval = random.sample(list_index, tv) train = random.sample(trainval, tr) file_trainval = open(txtsavepath + '/trainval.txt', 'w') file_test = open(txtsavepath + '/test.txt', 'w') file_train = open(txtsavepath + '/train.txt', 'w') file_val = open(txtsavepath + '/val.txt', 'w') for i in list_index: name = total_xml[i][:-4] + '\n' if i in trainval: file_trainval.write(name) if i in train: file_train.write(name) else: file_val.write(name) else: file_test.write(name) file_trainval.close() file_train.close() file_val.close() file_test.close()
此文件对数据集进行划分,分出了训练集和验证集,并将其路径分别保存。此处设置训练集的数量占0.8,可以自行调整
# -*- coding: utf-8 -*- import xml.etree.ElementTree as ET import os from os import getcwd sets = ['train', 'val', 'test'] classes = ["car", "person", "motorbike"] # 改成自己的类别 abs_path = os.getcwd() print(abs_path) def convert(size, box): dw = 1. / (size[0]) dh = 1. / (size[1]) x = (box[0] + box[1]) / 2.0 - 1 y = (box[2] + box[3]) / 2.0 - 1 w = box[1] - box[0] h = box[3] - box[2] x = x * dw w = w * dw y = y * dh h = h * dh return x, y, w, h def convert_annotation(image_id): in_file = open('/mnt/yolov5_v6.0/yolov5-v6.0/VOCDate/Annotations/%s.xml' % (image_id), encoding='UTF-8') out_file = open('/mnt/yolov5_v6.0/yolov5-v6.0/VOCDate/labels/%s.txt' % (image_id), 'w') tree = ET.parse(in_file) root = tree.getroot() size = root.find('size') w = int(size.find('width').text) h = int(size.find('height').text) for obj in root.iter('object'): difficult = obj.find('difficult').text # difficult = obj.find('Difficult').text cls = obj.find('name').text if cls not in classes or int(difficult) == 1: continue cls_id = classes.index(cls) xmlbox = obj.find('bndbox') b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) b1, b2, b3, b4 = b # 标注越界修正 if b2 > w: b2 = w if b4 > h: b4 = h b = (b1, b2, b3, b4) bb = convert((w, h), b) out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n') wd = getcwd() for image_set in sets: if not os.path.exists('/mnt/yolov5_v6.0/yolov5-v6.0/VOCDate/labels/'): os.makedirs('/mnt/yolov5_v6.0/yolov5-v6.0/VOCDate/labels/') image_ids = open('/mnt/yolov5_v6.0/yolov5-v6.0/VOCDate/ImageSets/Main/%s.txt' % (image_set)).read().strip().split() if not os.path.exists('/mnt/yolov5_v6.0/yolov5-v6.0/VOCDate/dataSet_path/'): os.makedirs('/mnt/yolov5_v6.0/yolov5-v6.0/VOCDate/dataSet_path/') list_file = open('dataSet_path/%s.txt' % (image_set), 'w') # 这行路径不需更改 for image_id in image_ids: list_file.write('/mnt/yolov5_v6.0/yolov5-v6.0/VOCDate/images/%s.jpg\n' % (image_id)) convert_annotation(image_id) list_file.close()
此文件将xml文件转化为yolov5所需要的txt文件,把标签中的类别和所处位置单独提取,到这一步数据算是处理完了
!!!注意上文中所有的/mnt/..需要改成自己电脑上保存的路径,然后运行,然后再统一改成/mnt/..具体路径是什么要看后面在矩池云你自己保存的路径,在本地这个py文件生成的dataSet_path文件夹中txt文件里的所有数据路径生成以后也要全改成/mnt/开头的矩池云路径,emmmmm我是复制到wps上再ctrl+f统一替换的,大家也可以修改上面的py文件直接生成矩池云路径。保存矩池云我们后面再讲
接下来修改一些配置:
在data文件夹创建mydata.yaml
内容如下:
train: MYData/dataSet_path/train.txt val: MYData/dataSet_path/val.txt # number of classes nc: 3 # class names names: ["car", "person", "motorbike"]
这里的train和val后面的路径即为刚刚生成的训练集和验证集的图片路径,可能和其他教程不太一样,这里先按我的来(因为要配套矩池云上的路径)nc即为分类的数量,names后面就写自己的类别就行。
接下来选择训练的模型,具体各模型参数可以在网上找到,打开models/yolov5s.yaml,修改nc即可(为自己数据集的类别数)
然后打开train.py文件,找到这里
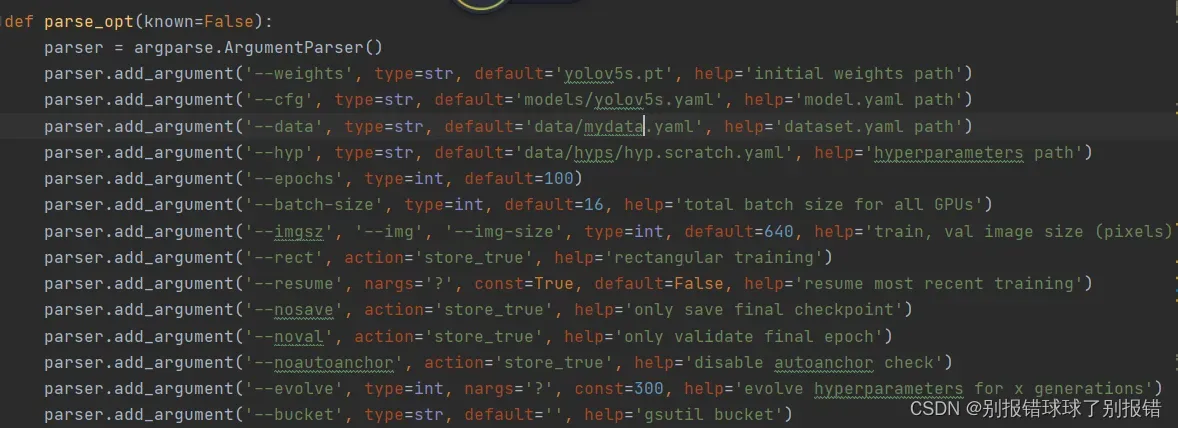

–weights后面为值为yolov5s.pt,此文件如果一开始下的代码没有需要去GitHub上下载一下,放在主文件夹里就行了
–cfg后面需要设置为yolov5s.yaml路径
–data后面为之前自己建的myvoc.yaml路径
–epochs为训练轮数,根据情况设置
–batch-size因为直接用的云服务器,就直接16了
–resume大家重点关注一下,因为云服务器训练受很多客观因素影响,比如网络啊什么的我就碰到好几次好好的突然停了,这时候修改–resume,令default=True就可以使网络自动接着上一次没训练完的训练
大概就是这些,接下来将连接矩池云
直接搜矩池云进入官网,第一次用先注册,我记得第一次官网会送五块钱的余额在账户上
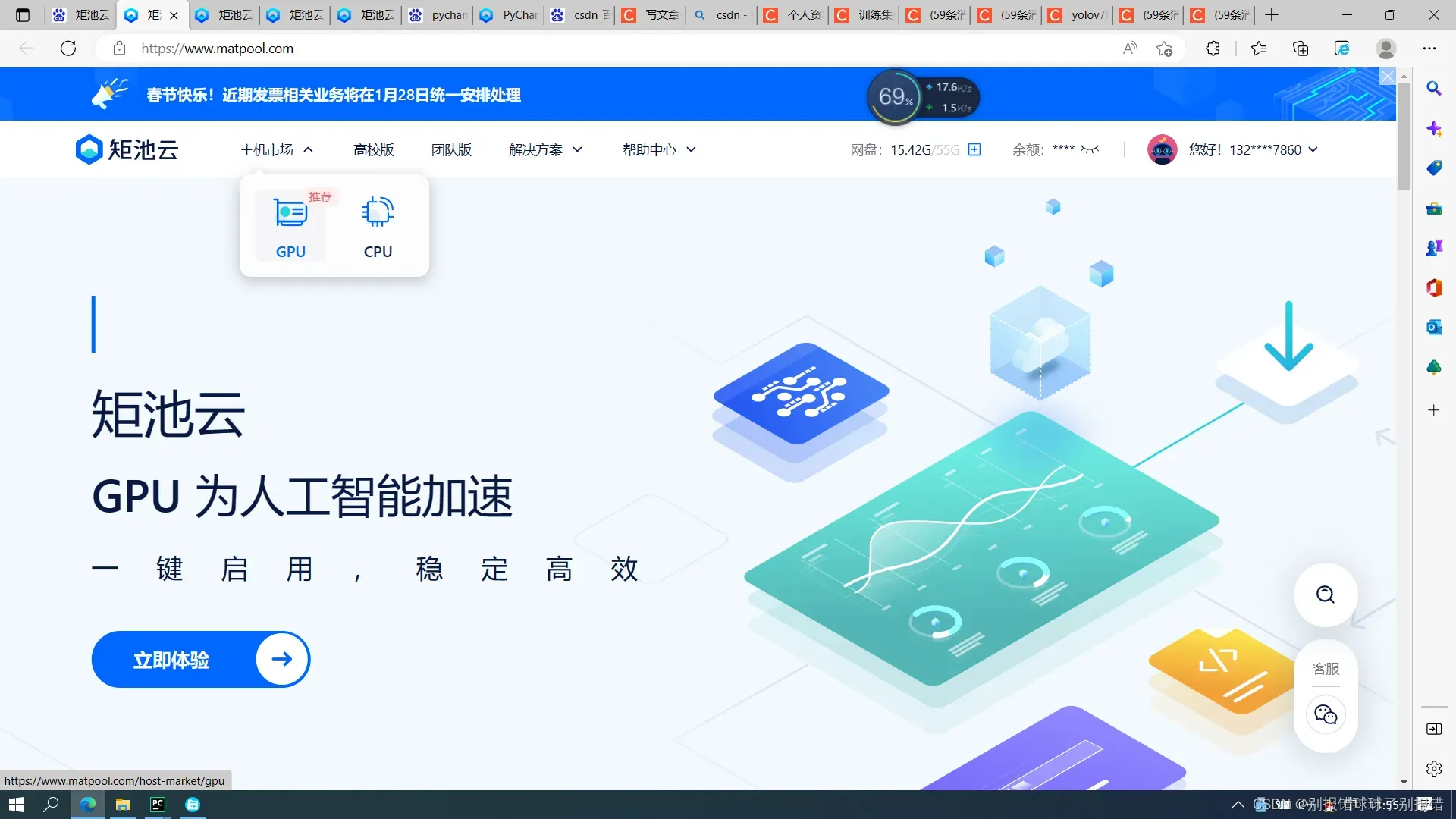
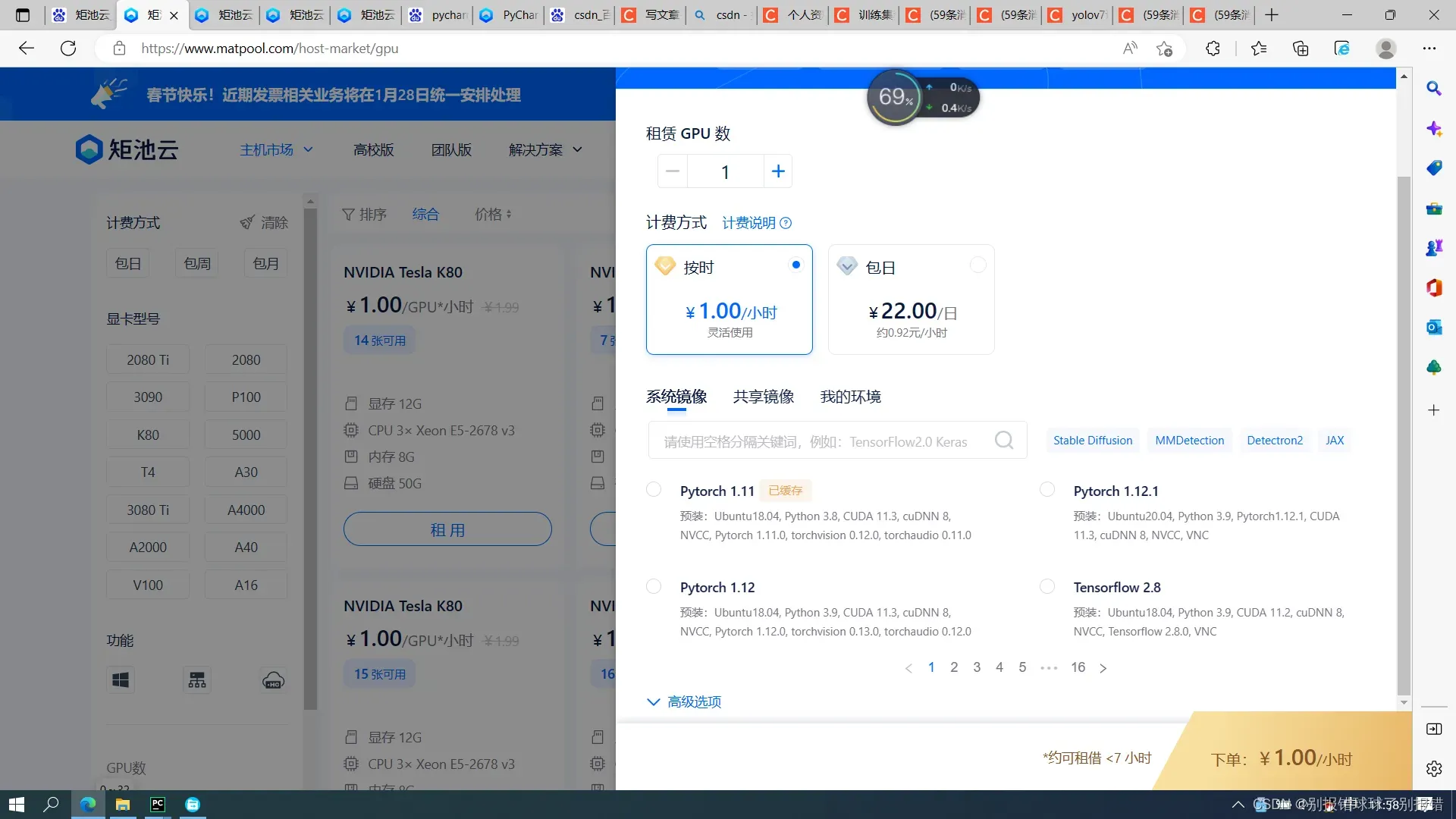
在系统镜像处,往后翻翻找到yolov5那个镜像(这个亲测yolov5、yolov7都能用,不同的镜像应该配置是有差别的,我试了其他好几个都会报其他错误),然后下单。
pycharm连接矩池云参考官方文档,写得很详细了PyCharm 使用矩池云机器教程 | 矩池云支持中心 (matpool.com)

强调一下
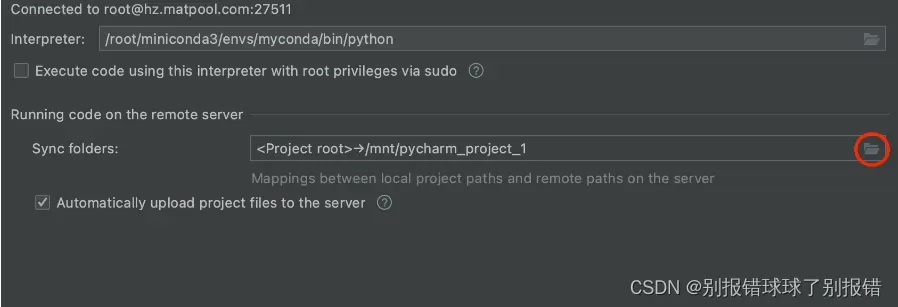

这里储存的文件夹一定要是/mnt目录下的,这样可以直接上传至云盘保存,然后下一次使用的时候,保存地址选到上一次保存的文件夹,再把底下automatically upload project files to the server给取消勾选,就不用麻烦用一次上传一次了,直接就可以进入之前保存的文件夹。我个傻子最开始不知道,用一次上传一次。
等到所有文件上传完毕,再回过头去刚才改地址的几个地方(),看云盘上存的地址,比如我就是/mnt/yolov5-v6.0/yolov5-v6.0/MYData/dataSet_path/..把前面的路径都给改成矩池云路径。mydata.yaml就不用改了,改好后直接run train.py就行了
结果会存储在,runs/train/exp’x’里面,x数字越大表示越新一次的训练结果,best.pt是训练效果最好的一次权重文件,last.pt是最后一次权重文件。当然,这个文件是保存在矩池云的网盘里,在自己的本地地址是找不到的,从矩池云上下载下来就行了
detect:
想要测试自己训练所得的detect文件,只需将
–weights后面的default设为自己的权重文件的保存地址
–source后面default设为自己想要检测的图片视频的保存地址即可
检测视频不需要改变什么配置,路径正确就行了
之前建议大家在电脑上安装相应的配置环境就是为了如果检测数量较小,只需要在本地环境进行检测就行了,不需要在云服务器上进行了,方便不少。


当然实测用cpu来跑一些视频的检测还是比用矩池云跑慢不少的
yolov7:
https://github.com/WongKinYiu/yolov7
相比yolov3而言,yolov7和yolov5真的很像,所以其实上面yolov5搞定了,yolov7运行就很简单。
依旧是先将images和annotations准备好,即待训练的图片和xml形式的标签,像之前一样放在一个文件夹内,在这里我就图省事,少改点地址,直接把源文件中的VOCdevkit文件夹内的图片标签换成自己的
同样加入一个xml转txt的文件
import xml.etree.ElementTree as ET import pickle import os from os import listdir, getcwd from os.path import join import random from shutil import copyfile classes = ["car", "person", "motorbike"] # classes=["ball"] TRAIN_RATIO = 90 def clear_hidden_files(path): dir_list = os.listdir(path) for i in dir_list: abspath = os.path.join(os.path.abspath(path), i) if os.path.isfile(abspath): if i.startswith("._"): os.remove(abspath) else: clear_hidden_files(abspath) def convert(size, box): dw = 1. / size[0] dh = 1. / size[1] x = (box[0] + box[1]) / 2.0 y = (box[2] + box[3]) / 2.0 w = box[1] - box[0] h = box[3] - box[2] x = x * dw w = w * dw y = y * dh h = h * dh return (x, y, w, h) def convert_annotation(image_id): in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml' % image_id,'r', encoding='utf-8') out_file = open('VOCdevkit/VOC2007/YOLOLabels/%s.txt' % image_id, 'w') tree = ET.parse(in_file) root = tree.getroot() size = root.find('size') w = int(size.find('width').text) h = int(size.find('height').text) for obj in root.iter('object'): # difficult = obj.find('difficult').text cls = obj.find('name').text if cls not in classes: continue cls_id = classes.index(cls) xmlbox = obj.find('bndbox') b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) bb = convert((w, h), b) out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n') in_file.close() out_file.close() wd = os.getcwd() wd = os.getcwd() data_base_dir = os.path.join(wd, "VOCdevkit/") if not os.path.isdir(data_base_dir): os.mkdir(data_base_dir) work_sapce_dir = os.path.join(data_base_dir, "VOC2007/") if not os.path.isdir(work_sapce_dir): os.mkdir(work_sapce_dir) annotation_dir = os.path.join(work_sapce_dir, "Annotations/") if not os.path.isdir(annotation_dir): os.mkdir(annotation_dir) clear_hidden_files(annotation_dir) image_dir = os.path.join(work_sapce_dir, "JPEGImages/") if not os.path.isdir(image_dir): os.mkdir(image_dir) clear_hidden_files(image_dir) yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/") if not os.path.isdir(yolo_labels_dir): os.mkdir(yolo_labels_dir) clear_hidden_files(yolo_labels_dir) yolov5_images_dir = os.path.join(data_base_dir, "images/") if not os.path.isdir(yolov5_images_dir): os.mkdir(yolov5_images_dir) clear_hidden_files(yolov5_images_dir) yolov5_labels_dir = os.path.join(data_base_dir, "labels/") if not os.path.isdir(yolov5_labels_dir): os.mkdir(yolov5_labels_dir) clear_hidden_files(yolov5_labels_dir) yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/") if not os.path.isdir(yolov5_images_train_dir): os.mkdir(yolov5_images_train_dir) clear_hidden_files(yolov5_images_train_dir) yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/") if not os.path.isdir(yolov5_images_test_dir): os.mkdir(yolov5_images_test_dir) clear_hidden_files(yolov5_images_test_dir) yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/") if not os.path.isdir(yolov5_labels_train_dir): os.mkdir(yolov5_labels_train_dir) clear_hidden_files(yolov5_labels_train_dir) yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/") if not os.path.isdir(yolov5_labels_test_dir): os.mkdir(yolov5_labels_test_dir) clear_hidden_files(yolov5_labels_test_dir) train_file = open(os.path.join(wd, "yolov7_train.txt"), 'w') test_file = open(os.path.join(wd, "yolov7_val.txt"), 'w') train_file.close() test_file.close() train_file = open(os.path.join(wd, "yolov7_train.txt"), 'a') test_file = open(os.path.join(wd, "yolov7_val.txt"), 'a') list_imgs = os.listdir(image_dir) # list image files prob = random.randint(1, 100) print("Probability: %d" % prob) for i in range(0, len(list_imgs)): path = os.path.join(image_dir, list_imgs[i]) if os.path.isfile(path): image_path = image_dir + list_imgs[i] voc_path = list_imgs[i] (nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path)) (voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path)) annotation_name = nameWithoutExtention + '.xml' annotation_path = os.path.join(annotation_dir, annotation_name) label_name = nameWithoutExtention + '.txt' label_path = os.path.join(yolo_labels_dir, label_name) prob = random.randint(1, 100) print("Probability: %d" % prob) if (prob < TRAIN_RATIO): # train dataset if os.path.exists(annotation_path): train_file.write(image_path + '\n') convert_annotation(nameWithoutExtention) # convert label copyfile(image_path, yolov5_images_train_dir + voc_path) copyfile(label_path, yolov5_labels_train_dir + label_name) else: # test dataset if os.path.exists(annotation_path): test_file.write(image_path + '\n') convert_annotation(nameWithoutExtention) # convert label copyfile(image_path, yolov5_images_test_dir + voc_path) copyfile(label_path, yolov5_labels_test_dir + label_name) train_file.close() test_file.close()
上面代码中写地址的部分的名称都是要注意一下的,要根据自己的存放位置修正
在这里跟yolov5的不同是,yolov5划分的训练集和验证集都是以图片地址给分割开的,训练集和测试集对应的图片地址分别保存,图片文件还是都放在一起,这里将训练集和验证集将图片直接分到两个文件夹内
注意在这里生成本地文件夹后,我们看到主文件夹内有yolov7_train.txt和yolov7_val.txt,也需要以同样的方式,用wps替换功能把自己的本地地址改成矩池云的地址。
最上面的classes根据自己的需要改成自己训练的类别,TRAIN_RATIO = 90表示9成为训练集,以100为基准可以改成自己需要的比例
在这里依然要修改一些配置文件,在cfg/training/yolov7.yaml中,修改nc为自己数据集的类别数
在data文件夹下创建voc.yaml
train: /mnt/pytorch-yolov7-main/pytorch-yolov7-main/VOCdevkit/images/train # 687 images
val: /mnt/pytorch-yolov7-main/pytorch-yolov7-main/VOCdevkit/images/val # 67 images
# number of classes
nc: 3
names: ['car','person','motorbike ']将训练集和验证集的地址改一下,类别数,类别名也改一下完成
然后来到train.py,同样地,将train.py中的一些参数仿照yolov5地那样改一下就好,要改的地方上面都提到过,就不再赘述
然后连接一下矩池云,将文件存到云盘就可以开始训练啦,这里建议根据矩池云的官方教程连接一下终端,因为终端默认是本地的,要通过pycharm/tools里面的Start SSH Session连接一下矩池云,然后在终端cd /mnt/pytorch-yolov7-main/pytorch-yolov7-main切换到自己保存的yolov7的地址(前面那是我的地址)
python train.py --workers 4 --device 0 --batch-size 16 --data data/voc.yaml --img 640 640 --cfg cfg/training/yolov7.yaml --weights '' --name yolov7 --hyp data/hyp.scratch.p5.yaml
键入上文直接在终端进行训练,终端可以直接设置workers数量和device选择等,感觉workers数量低一些gpu占用率会大一些,速度会快一些(不确定,也可能是幻觉),然后用终端运行好像也快一些,当然怕麻烦直接run train.py就行
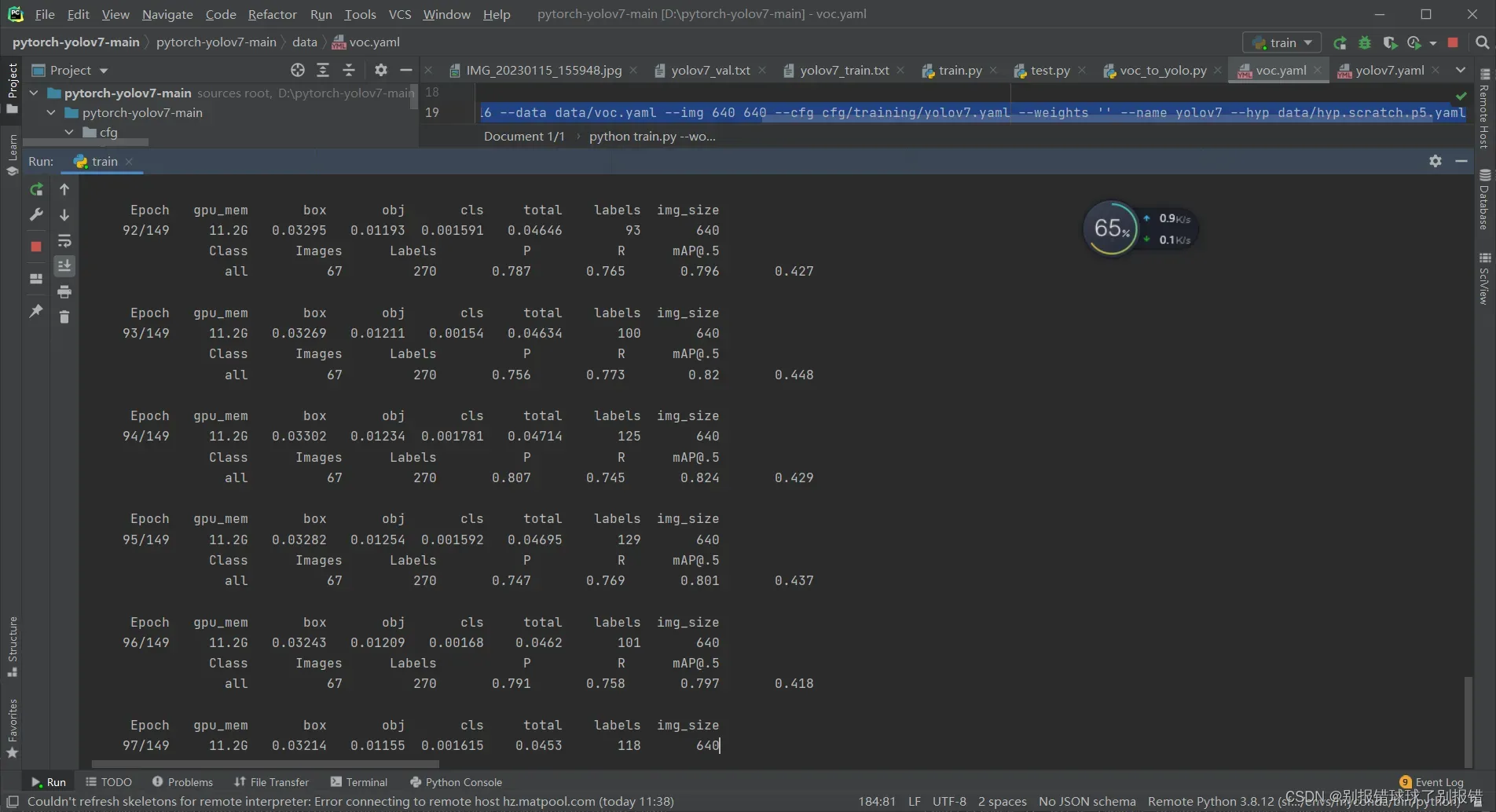

这是我正常训练的画面~
同样的数据集,我yolov5训练了120个epoch,yolov7训练了150个epoch,yolov5取最后一次的权重文件,yolov7取给出的最好的和最后一次的权重文件。实际测试发现yolov5的效果甚至更好一些。可能跟我自己建的数据集的数量,以及训练集比重划分,以及训练时batchsize等参数设置不同有关,还在找原因。
下图是我同yolov5 last.pt测试了一段速激片段效果,可以明显地看出yolo系列对小目标检测还是不够理想,但是目前的效果已经很不错了。
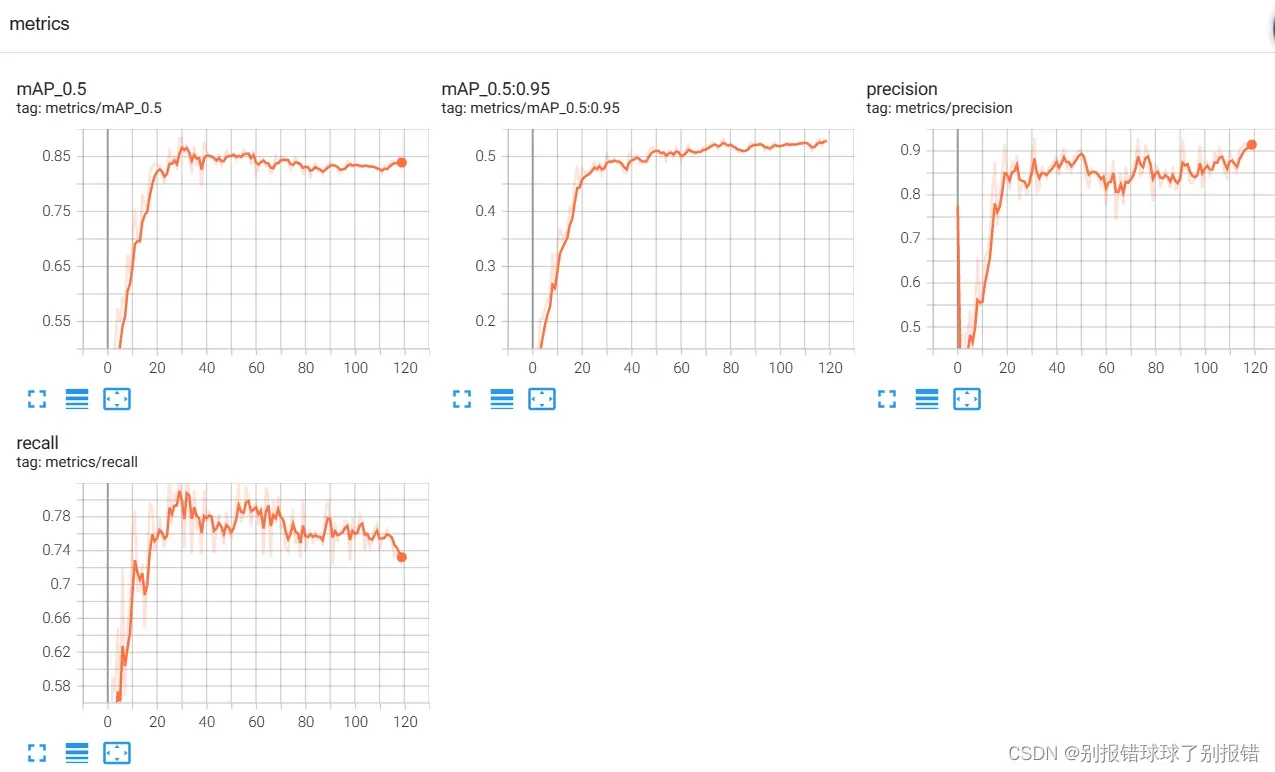

这是yolov5的数据
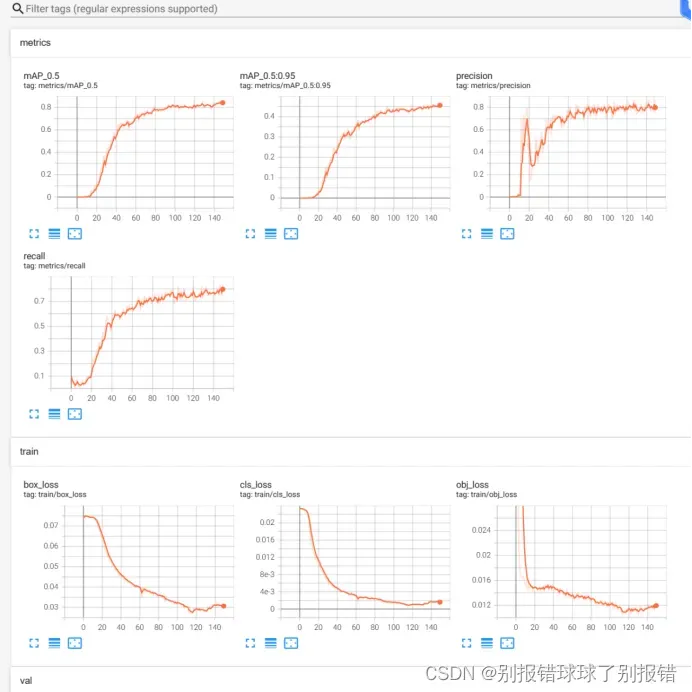

这是yolov7
yolov5实测视频
VID_20230125_170856
文章出处登录后可见!