本文是笔者自学ChatGPT的总结与思考,类型为综述文章,适合想全面了解ChatGPT或对人工智能感兴趣的小伙伴~~
目录先行,自行找需,全文三万六千余字。分为三大模块,追求效率可跳转感兴趣部分直接开卷。
感谢大佬们以前的写的文章给我提供了素材和思路,欢迎大家转发交流,您的点赞关注收藏是对我最大的鼓励噢,本文为博主原创文章,转载请附上原文出处链接和声明。
文章目录
- 前言
- 发展历程
- 行业概况
- 研究现状
- 技术路径
- 初学者必读10篇论文
- 技术架构详解
- ChatGPT的训练
- 行业未来和投资机会
- ChatGPT的产业未来
- AIGC商业方向
- 常见问题解答
- 个人总结
- 参考资料
前言
随着计算机技术的飞速发展,人工智能已经成为当前最热门的研究领域之一。在人工智能领域中,自然语言处理是一个重要的分支。它研究如何使计算机和人类能够以自然语言的方式进行交流。
新年伊始,你可能会想,人工智能领域最热门的技术是什么?那应该是 ChatGPT。它就像一个六角战士,可以聊天、编写代码、修复错误、创建表单、发表论文、做作业、翻译,甚至是谷歌搜索引擎的有力竞争者。
2022年12月1日,OpenAI推出人工智能聊天原型ChatGPT,ChatGPT是一种由OpenAI开发的预训练语言模型。它能够根据用户的文本输入,产生相应的智能回答。这个回答可以是简短的词语,也可以是长篇大论。其中GPT是Generative Pre-trained Transformer(生成型预训练变换模型)的缩写。它是基于Transformer架构,并使用了大量的文本数据进行训练,以实现对自然语言的理解和生成。ChatGPT具有出色的语法理解能力和语义理解能力,并且能够生成高质量的文本。因此,它被广泛应用于聊天机器人、问答系统、机器翻译等多领域。
近期ChatGPT突然爆火,在2个月内达到1亿活跃用户 ,是历史上增长最快的消费者应用程序。甚至有懂技术和懂赚钱的商业鬼才利用ChatGPT国内注册和使用的壁垒来赚钱,几天怒赚几百W(慕!),可见ChatGPT对当今风靡的程度。
接下来让我们揭开ChatGPT神秘的面纱吧!
以下是本篇文章正文内容
发展历程
行业概况
ChatGPT是由OpenAI团队研发创造,OpenAI是由创业家埃隆·马斯克、美国创业孵化器Y Combinator总裁阿尔特曼、全球在线支付平台PayPal联合创始人彼得·蒂尔等人于2015年在旧金山创立的一家非盈利的AI研究公司,其总部位于美国加利福尼亚州,并拥有多位硅谷重量级人物的资金支持,启动资金高达10亿美金。OpenAI的使命是使人工智能技术对人类产生积极影响,并帮助人类应对其带来的挑战。
OpenAI的研究方向包括人工智能、机器学习、自然语言处理、强化学习等多领域。该机构拥有一支顶尖的研究团队,并与世界各地的研究机构和企业合作,以推动人工智能技术的发展。
OpenAI 的ChatGPT是生成式人工智能技术(AIGC)。 AI模型可大致分为决策式/分析式AI(Discriminant/Analytical AI)和生成式AI (Generative AI)两类。决策式AI:学习数据中的条件概率分布,根据已有数据进行分析、判断、预测,主要应用模型有用于推荐系 统和风控系统的辅助决策、用于自动驾驶和机器人的决策智能体。生成式AI:学习数据中的联合概率分布,并非简单分析已有数据而是学习归纳已有数据后进行演技创造,基于历史进行模仿式、缝合式创作,生成了全新的内容,也能解决判别问题。
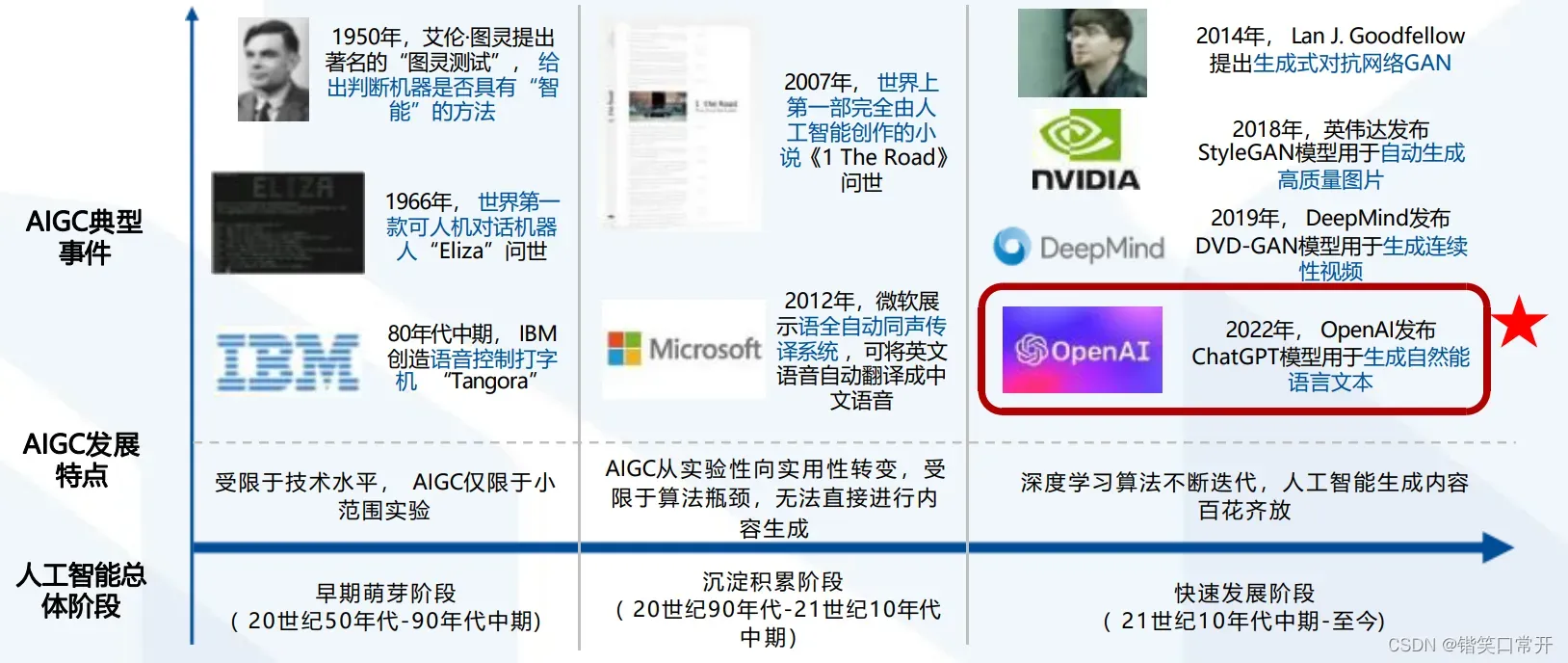
ChatGPT爆火的背后是人工智能算法的迭代升级。神经网络的爆发使人工智能广泛应用:2015年左右开始繁荣爆发,神经网络是实现AI深度学习的一种重要算法,是通过对人脑的基本单元神经元的建模和链接,探索模拟人脑系统功能的模型,并研发出的一种具有学习、联想、记忆和模式识别等具有智慧信息处理功能的人工系统。典型的应用场景为自然语言处理(NLP)和机器视觉(CV),其中具有代表的两个模型分别是循环神经网络(RNN)和卷积神经网络(CNN)。
国内外科技巨头都非常重视ChatGPT引发的科技浪潮,积极布局生成式AI,部分公司已有成型产品。
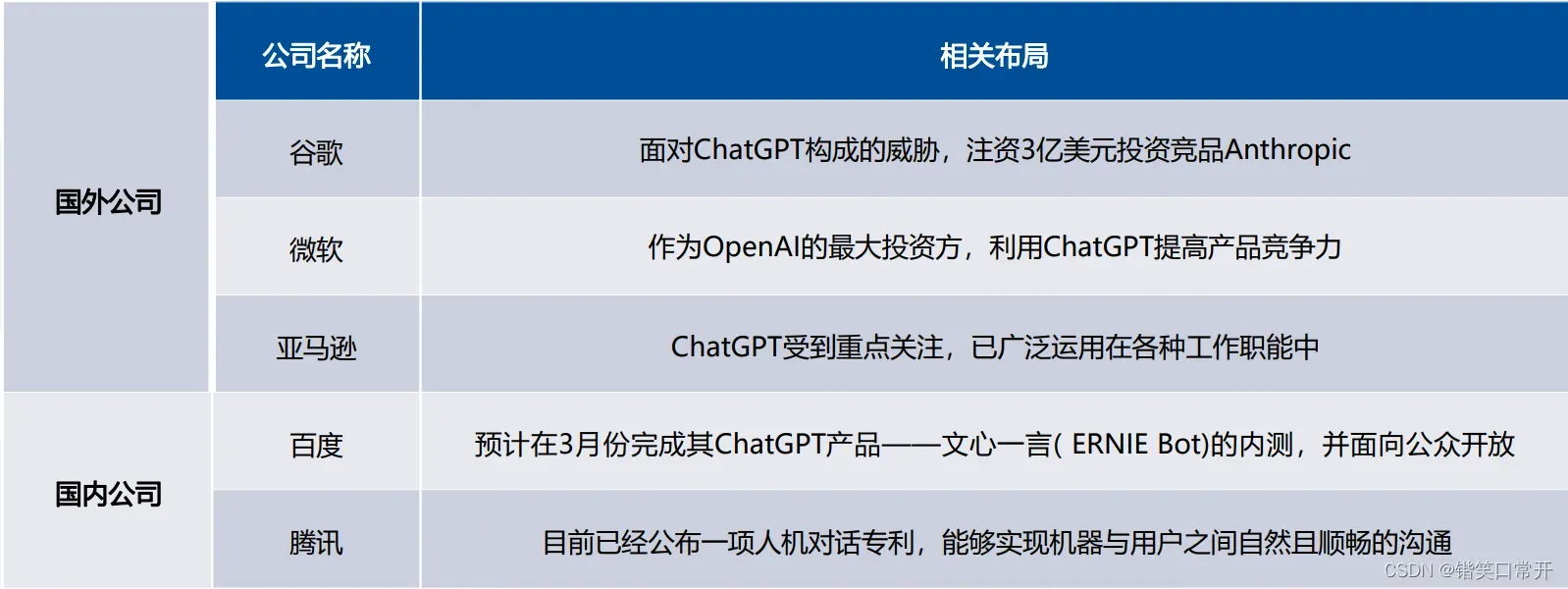
- 谷歌:面对ChatGPT构成的威胁,谷歌的CEO在公司内部发布“红色警报”。注资3亿美元投资竞品Anthropic公司,同时批准谷歌搜索引擎中加入AI聊天机器人。
- 微软: OpenAl的最大投资方,开始利用ChatGPT提高产品竞争力,将ChatGPT整合进Bing搜索引擎、Office全家桶、Azure云服务等产品中。
- 亚马逊:ChatGPT受到重点关注,已广泛运用在各种工作职能中,包括回答面试问题、编写软件代码和创建培训文档。
- 美国新媒体巨头Buzzfeed宣布计划采用ChatGPT协助内容创作,股价一夜暴涨近120%,两天时间市值飙升3倍。
- 百度:1月10日,百度宣布将升级百度搜索的“生成式搜索”能力,智能解答用户的搜索提问;2月7日,百度宣布将在3月份完成其ChatGPT产品的内测,面向公众开放,该项目名字为文心一言(ERNIEBot)。
- 腾讯:2月3日,腾讯公布一项人机对话专利,能够实现机器与用户之间自然且顺畅的沟通。该项专利与这段时间爆火的人工智能聊天机器人 ChatGPT 的原理十分相似。
- 科大讯飞:科大讯飞在回答投资者提问时表示,科大讯飞有坚实的相关技术积累,多年来始终保持关键核心技术处于世界前沿水平(如科大讯飞于 2022 年获得 CommonsenseQA 2.0、OpenBookQA 等多个认知智能领域权威评测的第一)。且在认知智能领域重点技术和以教育、医疗为代表的专业领域,应用落地效果整体处于业界领先水平。
研究现状
最近大火的ChatGPT的计算逻辑来自于一个算法名字叫Transformer。它来源于2017年的一篇科研论文《Attention is all your need》。Transformer算法在神经网络中具备跨时代的意义。Transformer具备跨时代的意义的原因是算法上添加了注意力机制,这种机制具备突破性的原因在于
1、突破了RNN 模型不能并行计算的限制;
2、相比CNN模型,关联所需的操作次数不随距离增长;
3、模型解释力度明显加强。从结果上看,
根据CDSN数据,Transformer的综合特征提取能力、远距离特征捕获能力、语义特征提取能力,全部明显增强,因此此算法正逐步取代RNN算法,也是ChatGPT算法的底座。
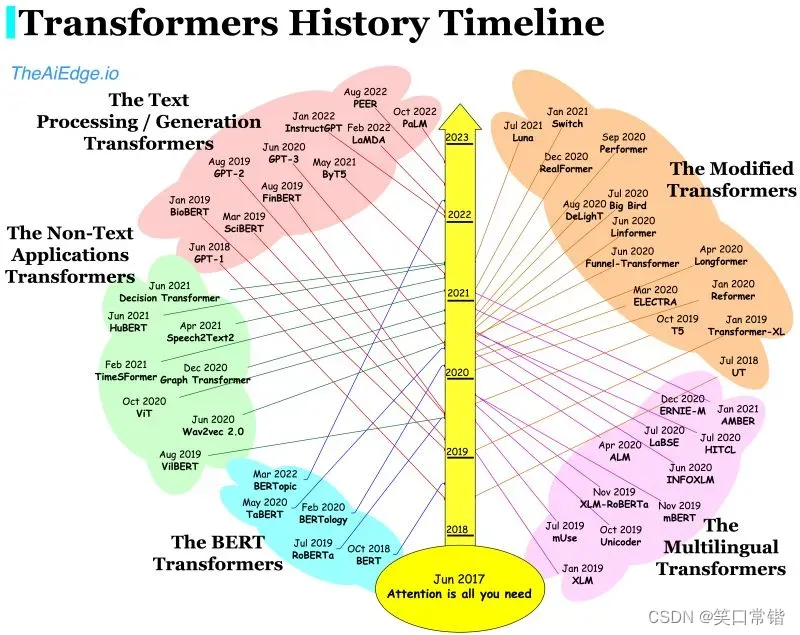
从Transformer提出到GPT的诞生,再到GPT2的迭代标志Open AI成为营利性公司,以及GPT3和ChatGPT的“出圈”;再看产业界,第四范式涉及到多个重要领域比如生物医疗,智能制造纷纷有以Transformer落地的技术产生。

ChatGPT 是基于GPT-3.5(Generative Pre-trained Transformer 3.5)架构开发的对话AI模型,是InstructGPT 的兄弟模型。ChatGPT很可能是OpenAI 在GPT-4 正式推出之前的演练,或用于收集大量对话数据。
GPT是OpenAI开发的一种预训练语言模型。它采用了Transformer网络结构,并在语言任务领域中具有很高的表现。GPT的主要优势在于它可以通过预训练大量语料数据来获得对语言任务的预测能力,而不需要大量的人工标注数据。它具有良好的语言生成能力,可以生成文本、回答问题、进行对话等多项语言任务。
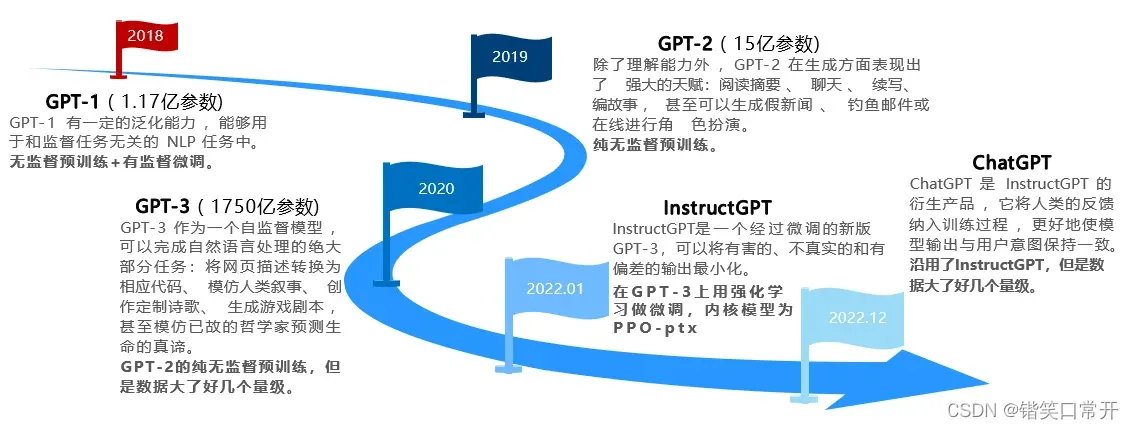
- 第一代:从有监督到无监督GPT-1。2018年,OpenAI推出了第一代生成式预训练模型GPT-1,此前,NLP任务需要通过大规模数据集来进行有监督的学习,需要成本高昂的数据标注工作,GPT-1的关键特征是:半监督学习。先用无监督学习的预训练,在8个GPU上花费了1 个月的时间,从大量未标注数据中增强AI系统的语言能力,获得大量知识,然后进行有监督的微调,与大型数据集集成来提高系统在NLP任务中的性能。只需要极少的微调,就可以增强NLP模型的能力,减少对资源和数据的需求。同时,GPT-1也存在明显的问题,一是数据局限性,GPT-1是在互联网上的书籍和文本上训练的,对世界的认识不够完整和准确;二是泛化性依然不足,在一些任务上性能表现就会下降。
- 第二代:更大更高更强的GPT-2。2019年推出的GPT-2,与GPT-1并没有本质上的不同(注意这一点),架构相同,使用了更大的数据集WebText,大约有40 GB的文本数据、800万个文档,并为模型添加了更多参数(达到惊人的 15 亿个参数),来提高模型的准确性,可以说是加强版或臃肿版的GPT-1。进一步证明了无监督学习的价值,以及预训练模型在下游NLP任务中的广泛成功,已经开始达到图灵测试的要求。
- 第三代:跨越式进步的GPT-3。2020年,GPT-3的这次迭代,出现了重大的飞跃,成为与GPT-2迥然不同的物种。首先,GPT-3的体量空前庞大,拥有超过 1750 亿个参数,是GPT-2的 117 倍;其次,GPT-3不需要微调,它可以识别到数据中隐藏的含义,并运用此前训练获得的知识,来执行下游任务。这意味着,哪怕从来没有接触过的示例,GPT-3就能理解并提供不错的表现。因此,GPT-3也在商业应用上表现出了极高的稳定性和实用性,通过云上的 API访问来实现商业化。这种入得了实验室、下得了车间的能力,使得GPT-3成为2020年AI领域最惊艳的模型之一。
- 第四代:基于理解而生成的GPT-3.5 (InstructGPT)。出现了颠覆式的迭代,产生了技术路线上的又一次方向性变化:基于人工标注数据+强化学习的推理和生成。GPT-3虽然很强,但无法理解人类指令的含义(比如写一段博文、改一段代码),无法判断输入,自然也就很难给出高质量的输出答案。所以OpenAI通过专业的标注人员(听说40个博士标注人员)标注了12.7K的样本,给出相应指令/问题的高质量答案,在基于这些数据来调整GPT-3.5的参数,从而让GPT -3.5具备了理解人类指令的能力。在人工标注训练数据的基础上,再使用强化学习来增强预训练模型的能力。强化学习,简单理解就是做对了奖励、做错了惩罚,不断根据系统的打分来更新参数,从而产生越来越高质量的回答,使得模型具备从人类的反馈中强化学习并重新思考的能力,这是一条通向通用人工智能AGI的路径。
学习资料:
ChatGPT怎么变得这么强?华人博士万字长文拆解GPT-3.5
ChatGPT背后的超神模型:GPT-1到GPT-3.5是如何演化的?
一文讲清chatGPT的发展历程、能力来源和复现它的关键之处
技术路径
作为一个大型语言模型,ChatGPT是通过大量的数据和算法训练得到的。下面是大致的技术路径:
- 数据收集:OpenAI使用大量的网络文章和书籍等数据作为ChatGPT的训练数据,这些数据经过精心筛选和清洗,以确保其质量和可靠性。
- 自然语言处理技术:对原始数据进行预处理和标记化,使用技术如分词、词性标注、句法分析、实体识别等技术。
- 机器学习技术:OpenAI使用大量的机器学习算法对数据进行训练,包括深度学习技术如神经网络,递归神经网络等,还包括传统的机器学习算法如支持向量机、决策树等。
- 算法优化:通过对算法进行改进和优化,以提高模型的性能和准确性。例如,使用更复杂的模型、改进梯度下降算法等。
- 模型评估:OpenAI使用大量的评估指标来评估我的性能和准确性,以确保ChatGPT可以为用户提供高质量的服务。
- 持续更新:ChatGPT会不断地进行更新和优化,以提高准确性和性能,同时也会随着时间推移而适应新的数据和技术趋势。
初学者必读10篇论文
我让ChatGPT帮我推荐论文,竟然没有InstructGPT,感觉不是很满意结果,之后我又运用多种方式来提问他,最后选出我认为入门必读的10篇论文。

- Transformer
ChatGPT 使用的预训练模型 GPT,而Transformer是GPT的核心组成部分。
- Title:Attention Is All You Need
- 英文摘要
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.
- 简介
该文章是一篇由Google Brain的研究人员于2017年发表在NIPS会议上的论文。该论文介绍了一种新的神经机器翻译模型Transformer,并且该模型在机器翻译任务上表现出了非常好的性能。Transformer模型使用了self-attention机制来计算输入序列中各个位置之间的依赖关系,避免了传统的循环神经网络模型中需要进行逐步迭代的计算,大大加快了模型的训练速度。在传统的机器翻译模型中,通常使用编码器-解码器(Encoder-Decoder)结构来进行翻译。编码器将输入序列(例如英文句子)转换为一系列隐藏状态,然后解码器使用这些隐藏状态来生成输出序列。在这个过程中,编码器和解码器之间通常使用循环神经网络进行连接。但是,这种结构在长序列的情况下容易产生梯度消失和梯度爆炸等问题,导致模型性能下降。Transformer模型通过引入self-attention机制,避免了循环神经网络的限制。Self-attention机制可以将输入序列中各个位置之间的依赖关系进行并行计算,使得每个位置都可以直接参考输入序列中所有其他位置的信息。这样可以更好地捕捉序列中的长程依赖关系,从而提高模型的性能。
Transformer的主要优点在于它不依赖于传统的循环神经网络,因此具有更高的并行计算能力和更好的处理长序列数据的能力。回到ChatGPT,它是在Transformer架构的基础上进行改进和扩展,并在大量的文本数据上进行预训练,以提高对自然语言的理解能力。ChatGPT使用了两个模型组成:一个用于语言理解,一个用于文本生成。它可以通过输入文本来预测输出文本,并且能够生成高质量的文本。
Transfomer优秀学习资料:
Transformer的细节到底是怎么样的? – 月来客栈
Transformer模型详解(图解最完整版)
- GPT
这是GPT的原始论文,介绍了使用无监督的方式进行预训练的思想,该思想在各种自然语言处理任务上都获得了很好的效果,为ChatGPT的开发提供了基础。 GPT-1的训练分为无监督的预训练和有监督的模型微调,下面进行详细介绍。
-
Title:Improving Language Understanding by Generative Pre-Training
-
英文摘要
Natural language understanding comprises a wide range of diverse tasks such as textual entailment, question answering, semantic similarity assessment, and document classification. Although large unlabeled text corpora are abundant, labeled data for learning these specific tasks is scarce, making it challenging for discriminatively trained models to perform adequately. We demonstrate that large gains on these tasks can be realized by generative pre-training of a language model on a diverse corpus of unlabeled text, followed by discriminative fine-tuning on each specific task. In contrast to previous approaches, we make use of task-aware input transformations during fine-tuning to achieve effective transfer while requiring minimal changes to the model architecture. We demonstrate the effectiveness of our approach on a wide range of benchmarks for natural language understanding. Our general task-agnostic model outperforms discriminatively trained models that use architectures specifically crafted for each task, significantly improving upon the state of the art in 9 out of the 12 tasks studied. For instance, we achieve absolute improvements of 8.9% on commonsense reasoning (Stories Cloze Test), 5.7% on question answering (RACE), and 1.5% on textual entailment (MultiNLI). -
简介
该论文提出了一种名为Generative Pre-Training的预训练方法,旨在提高自然语言处理任务中的语言理解能力。这种方法利用了大量的未标记数据来训练模型,这种训练方式被称为预训练。
具体来说,Generative Pre-Training的思路是,利用Transformer等深度神经网络模型,在大规模未标记语料上进行预训练。在预训练中,模型学习使用无监督任务来学习语言表示,例如利用掩码语言模型和下一句预测任务等。在这个过程中,模型可以学习语言中的各种语言知识和语言规则,包括语义、语法、词义等等。这些学习到的知识可以用于后续监督训练的微调,从而提高模型在这些任务上的性能。
Generative Pre-Training方法的优点是,它可以在大规模未标记语料上进行训练,从而可以提高模型的泛化能力。此外,通过预训练,模型可以学习到更为通用的语言表示,可以用于多个自然语言处理任务。
- GPT-2
GPT-2的目标旨在训练一个泛化能力更强的词向量模型,它并没有对GPT-1的网络进行过多的结构的创新与设计,只是使用了更多的网络参数和更大的数据集。下面我们对GPT-2展开详细的介绍。
-
Title:Language Models are Unsupervised Multitask Learners
-
英文摘要
Natural language processing tasks, such as question answering, machine translation, reading comprehension, and summarization, are typically approached with supervised learning on taskspecific datasets. We demonstrate that language models begin to learn these tasks without any explicit supervision when trained on a new dataset of millions of webpages called WebText. When conditioned on a document plus questions, the answers generated by the language model reach 55 F1 on the CoQA dataset matching or exceeding the performance of 3 out of 4 baseline systems without using the 127,000+ training examples. The capacity of the language model is essential to the success of zero-shot task transfer and increasing it improves performance in a log-linear fashion across tasks. Our largest model, GPT-2, is a 1.5B parameter Transformer that achieves state of the art results on 7 out of 8 tested language modeling datasets in a zero-shot setting but still underfits WebText. Samples from the model reflect these improvements and contain coherent paragraphs of text. These findings suggest a promising path towards building language processing systems which learn to perform tasks from their naturally occurring demonstrations. -
简介
GPT-2的学习目标是使用无监督的预训练模型做有监督的任务。该论文使用了无监督学习的方法,通过预先训练来完成多种自然语言处理任务,从而为各种应用场景提供服务。GPT-2的核心思想概括为:任何有监督任务都是语言模型的一个子集,当模型的容量非常大且数据量足够丰富时,仅仅靠训练语言模型的学习便可以完成其他有监督学习的任务。
主要贡献是验证了通过海量数据和大量参数训练出来的词向量模型有迁移到其它类别任务中而不需要额外的训练。但是很多实验也表明,GPT-2的无监督学习的能力还有很大的提升空间,甚至在有些任务上的表现不比随机的好。尽管在有些zero-shot的任务上的表现不错,但是我们仍不清楚GPT-2的这种策略究竟能做成什么样子。GPT-2表明随着模型容量和数据量的增大,其潜能还有进一步开发的空间,基于这个思想,诞生了我们下面要介绍的GPT-3。GPT1和GPT2对比:
1.GPT1使用了双向Transformer,而GPT2使用了单向Transformer。
2.GPT1通过了两个阶段的微调来适应不同的自然语言处理任务,而GPT2使用了多任务学习来进行微调。
3.GPT1是在BERT模型之前提出的,而GPT2是在BERT模型之后提出的,它使用的是基于Transformer的架构和更多的未标记数据,因此表现更优秀。

学习资料:
GPT-2技术学习(论文+原理+代码)
- GPT-3
GPT-3的论文,介绍了使用更大规模的数据和更大规模的模型进行预训练的思想。这些强大能力的能力则依赖于GPT-3疯狂的1750亿的参数量,45TB的Web文本数据以及高达1200万美元的训练费用(行业壁垒这不就来了吗小公司就只能调调API)。
- Title:Language Models are Few-Shot Learners
- 英文摘要
Recent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-training on a large corpus of text followed by fine-tuning on a specific task. While typically task-agnostic in architecture, this method still requires task-specific fine-tuning datasets of thousands or tens of thousands of examples. By contrast, humans can generally perform a new language task from only a few examples or from simple instructions – something which current NLP systems still largely struggle to do. Here we show that scaling up language models greatly improves task-agnostic, few-shot performance, sometimes even reaching competitiveness with prior state-of-the-art fine-tuning approaches. Specifically, we train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting. For all tasks, GPT-3 is applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model. GPT-3 achieves strong performance on many NLP datasets, including translation, question-answering, and cloze tasks, as well as several tasks that require on-the-fly reasoning or domain adaptation, such as unscrambling words, using a novel word in a sentence, or performing 3-digit arithmetic. At the same time, we also identify some datasets where GPT-3’s few-shot learning still struggles, as well as some datasets where GPT-3 faces methodological issues related to training on large web corpora. Finally, we find that GPT-3 can generate samples of news articles which human evaluators have difficulty distinguishing from articles written by humans. We discuss broader societal impacts of this finding and of GPT-3 in general. - 简介
这篇论文探讨了GPT-3在零样本学习(Zero-shot Learning)和少样本学习(Few-shot Learning)任务上的表现,并且对其内部机制进行了分析。在这篇论文中,作者提出了一种新的任务描述方式,称为“Prompt”,它可以指示模型在执行特定任务时应该执行的操作。GPT-3使用这种Prompt描述来解决各种不同的任务,包括文本生成、翻译、问答和代码生成等等。论文还展示了GPT-3在执行零样本学习和少样本学习任务时的惊人表现,它可以通过非常少量的样本数据来完成各种任务,甚至可以完成从未见过的任务。
作者还对GPT-3的内部机制进行了分析,包括了一些基于控制信号的机制,这些机制可以被用于控制模型生成的输出。这些控制信号可以是文本描述,也可以是一些特殊的Token,可以用来控制模型的生成过程,使其生成更加精准、准确的输出。
仅仅用惊艳很难描述GPT-3的优秀表现。首先,在大量的语言模型数据集中,GPT-3超过了绝大多数的zero-shot或者few-shot的state-of-the-art方法。另外GPT-3在很多复杂的NLP任务中也超过了fine-tune之后的state-of-the-art方法,例如闭卷问答,模式解析,机器翻译等。除了这些传统的NLP任务,GPT-3在一些其他的领域也取得了非常震惊的效果,例如进行数学加法,文章生成,编写代码等。
学习资料:
预训练语言模型之GPT-1,GPT-2和GPT-3
5. InstructGPT
虽然现在ChatGPT没有论文发布,但是ChatGPT与Open AI此前发布的InstructGPT具有非常接近的姊妹关系,两个模型的算法原理也非常接近,因此InstructGPT有较为可靠的参考价值。
-
Title:Training language models to follow instructions with human feedback
-
英文摘要
Making language models bigger does not inherently make them better at following a user’s intent. For example, large language models can generate outputs that are untruthful, toxic, or simply not helpful to the user. In other words, these models are not aligned with their users. In this paper, we show an avenue for aligning language models with user intent on a wide range of tasks by fine-tuning with human feedback. Starting with a set of labeler-written prompts and prompts submitted through the OpenAI API, we collect a dataset of labeler demonstrations of the desired model behavior, which we use to fine-tune GPT-3 using supervised learning. We then collect a dataset of rankings of model outputs, which we use to further fine-tune this supervised model using reinforcement learning from human feedback. We call the resulting models InstructGPT. In human evaluations on our prompt distribution, outputs from the 1.3B parameter InstructGPT model are preferred to outputs from the 175B GPT-3, despite having 100x fewer parameters. Moreover, InstructGPT models show improvements in truthfulness and reductions in toxic output generation while having minimal performance regressions on public NLP datasets. Even though InstructGPT still makes simple mistakes, our results show that fine-tuning with human feedback is a promising direction for aligning language models with human intent. -
简介
该论文介绍了一种新方法,该方法使用人类反馈指导语言模型执行特定任务。在传统的机器学习方法中,通常需要手动为模型标记数据并进行训练。而这篇论文提出的方法则通过与人类合作,让模型通过互动学习任务的执行。
具体来说,该论文提出的方法包括以下几个步骤:
提供指令:系统向模型提供一组指令,要求模型执行某个任务。这些指令可能是自然语言文本,也可能是一系列操作。
模型执行任务:模型根据指令尝试执行任务。
人类提供反馈:人类根据模型执行的结果提供反馈,反馈可以是正面的或负面的。如果模型执行得好,反馈就是正面的,如果模型执行得不好,反馈就是负面的。
模型更新:模型根据人类提供的反馈进行更新,尝试更好地执行任务。
重复以上步骤:系统通过反复执行上述步骤来不断改进模型的性能。
通过以上步骤,该论文提出的方法能够帮助模型更好地理解自然语言指令,从而更好地执行任务。同时,该方法还可以减少人工标注数据的需求,从而提高了训练效率。可以说该论文提出了一种基于互动学习的方法,能够让语言模型更好地执行任务。这一方法在实际应用中具有很大的潜力,可以为语言理解、智能对话等领域带来新的突破。
学习资料:
OpenAI是如何“魔鬼调教” GPT的?——InstructGPT论文解读
- BERT
这篇论文提出了一种新的预训练方法——Bidirectional Encoder Representations from Transformers(BERT),是另一个非常流行的自然语言处理模型,也是使用Transformer模型进行预训练的。它为ChatGPT的开发提供了一些启示。
-
Title:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
-
英文摘要
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications.
BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural language processing tasks, including pushing the GLUE score to 80.5% (7.7% point absolute improvement), MultiNLI accuracy to 86.7% (4.6% absolute improvement), SQuAD v1.1 question answering Test F1 to 93.2 (1.5 point absolute improvement) and SQuAD v2.0 Test F1 to 83.1 (5.1 point absolute improvement). -
简介
该论文介绍了一种新的自然语言处理模型BERT,旨在改进自然语言处理(NLP)任务中的语言理解能力。BERT采用了双向Transformer编码器,允许模型同时访问输入序列的左右两侧上下文信息,以更好地理解自然语言的含义。为了提高模型的泛化能力,BERT使用了两种预训练方式:Masked Language Model (MLM)和Next Sentence Prediction (NSP)。MLM随机屏蔽输入序列的某些单词,使模型尝试预测被屏蔽的单词。NSP要求模型预测两个句子是否是连续的。BERT在多项NLP任务中取得了最新的最佳结果,如问答、文本分类、自然语言推理等任务。
该论文的贡献在于,提出了一种预训练方法和双向Transformer编码器,以更好地处理自然语言的上下文和语义。BERT成为当时最新的自然语言处理领域的最佳模型之一,其思路和方法也被广泛应用于自然语言处理领域,成为了自然语言处理领域的重要里程碑之一。
- RLHF
ChatGPT与 GPT-3 的主要区别在于新加入了被称为 RLHF(Reinforcement Learning from Human Feedback,人类反馈强化学习)的方法,该技术在训练循环中使用人类反馈来最大限度地减少有害、不真实和/或有偏见的输出。基本思想是训练一个额外的奖励模型,从人类的角度评估模型的反应有多好,以指导模型的学习过程。然后使用这个奖励模型使用强化学习对原始语言模型进行微调。
-
Title:Augmenting Reinforcement Learning with Human Feedback
-
英文摘要
As computational agents are increasingly used beyond research labs, their success will depend on their ability to learn new skills and adapt to their dynamic, complex environments. If human users — without programming skills — can transfer their task knowledge to agents, learning can accelerate dramatically, reducing costly trials. The TAMER framework guides the design of agents whose behavior can be shaped through signals of approval and disapproval, a natural form of human feedback. More recently, TAMER+RL was introduced to enable human feedback to augment a traditional reinforcement learning (RL) agent that learns from a Markov decision process’s (MDP) reward signal. Using a reimplementation of TAMER and TAMER+RL, we address limitations of prior work, contributing in two critical directions. First, the four successful techniques for combining a human reinforcement with RL from prior TAMER+RL work are tested on a second task, and these techniques’ sensitivities to parameter changes are analyzed. Together, these examinations yield more general and prescriptive conclusions to guide others who wish to incorporate human knowledge into an RL algorithm. Second, TAMER+RL has thus far been limited to a sequential setting, in which training occurs before learning from MDP reward. We modify the sequential algorithms to learn simultaneously from both sources, enabling the human feedback to come at any time during the reinforcement learning process. To enable simultaneous learning, we introduce a new technique that appropriately determines the magnitude of the human model’s influence on the RL algorithm throughout time and state-action space. -
简介
我使用ChatGPT的时候其中最令人印象深刻的就是它的保护机制,比如它不会为暴力行动提供建议、也不会为世界杯结果进行预测等等。虽然我用Prompt Injection 攻击撬开过 ChatGPT 的保护方式,但ChatGPT 的开发者也在想方设法提升保护机制。OpenAI 投入了大量的精力让 ChatGPT 更安全,其主要的训练策略采用 RLHF,简单来说,开发人员会给模型提出各种可能的问题,并对反馈的错误答案进行惩罚,对正确的答案进行奖励,从而实现控制 ChatGPT 的回答。
在强化学习中,智能体在与环境交互的过程中,通常需要通过与环境的交互来学习到最优策略。然而,在某些情况下,由于环境太过复杂或任务不够明确,智能体可能无法获得足够的奖励信号来推导出最优策略。因此,该论文提出了一种基于人类反馈的增强学习方法——人类反馈强化学习(Human Feedback Reinforcement Learning,HFRL)。该方法通过人类提供反馈信息,指导智能体学习到更优的策略。同时,为了防止人类反馈过于频繁地干扰学习,该方法还引入了一种基于学习的策略选择(Learning-Based Policy Selection,LBPS)方法,动态平衡人类反馈和自主学习的权衡。实验结果表明,HFRL方法比传统的强化学习方法和其他基于人类反馈的方法在各种任务上都有更好的表现。该论文的研究成果为利用人类反馈指导强化学习提供了一种新的思路和方法,也为将强化学习方法应用于实际应用场景提供了新的可能性。
学习资料:
抱抱脸:ChatGPT背后的算法——RLHF | 附12篇RLHF必刷论文
RLHF:基于人类反馈(Human Feedback)对语言模型进行强化学习【Reinforcement Learning from Human Feedback】
How ChatGPT actually works
Why is ChatGPT so good?
- Prompt
ChatGPT 训练时的输入使用的是 Prompt(“提示”),Prompt已经被广泛应用于各种自然语言处理任务的模型预训练和微调中。使用Prompt可以有效地指导模型学习特定的语言规则和模式,提高模型的泛化能力,以及提高模型在不同任务上的性能。
- Title:Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
- 英文摘要
This paper surveys and organizes research works in a new paradigm in natural language processing, which we dub “prompt-based learning”. Unlike traditional supervised learning, which trains a model to take in an input x and predict an output y as P(y|x), prompt-based learning is based on language models that model the probability of text directly. To use these models to perform prediction tasks, the original input x is modified using a template into a textual string prompt x’ that has some unfilled slots, and then the language model is used to probabilistically fill the unfilled information to obtain a final string x, from which the final output y can be derived. This framework is powerful and attractive for a number of reasons: it allows the language model to be pre-trained on massive amounts of raw text, and by defining a new prompting function the model is able to perform few-shot or even zero-shot learning, adapting to new scenarios with few or no labeled data. In this paper we introduce the basics of this promising paradigm, describe a unified set of mathematical notations that can cover a wide variety of existing work, and organize existing work along several dimensions, e.g.the choice of pre-trained models, prompts, and tuning strategies. To make the field more accessible to interested beginners, we not only make a systematic review of existing works and a highly structured typology of prompt-based concepts, but also release other resources, e.g., a website this http URL including constantly-updated survey, and paperlist. - 简介
这篇论文是对自然语言处理中预训练模型中提示方法的一次系统调查。自然语言处理中的预训练模型需要在大量的未标记数据上进行训练,以便在特定的任务上进行微调,获得更好的性能。提示方法是一种提高预训练模型性能的技术,它是在输入序列中添加特殊的提示(prompt)或指示语言,以帮助模型更好地理解任务或上下文。论文系统地总结了自然语言处理中使用的各种提示方法,包括单一提示和多提示方法、基于语言模型的提示方法、基于模板的提示方法和基于知识库的提示方法等。此外,论文还讨论了如何选择最佳的提示方法,并分析了提示方法在各种自然语言处理任务中的性能表现。
论文的主要贡献在于系统总结了自然语言处理中提示方法的现状和进展,帮助人们更好地了解提示方法的特点和应用情况。此外,论文还提供了一个框架来比较不同的提示方法,并为未来研究提供了指导。
9.Adam收敛 –On the Convergence of Adam and Beyond–ICLR 2018最佳论文
该论文主要探讨了常用的优化器Adam在训练深度神经网络时可能出现的问题,以及提出了一种新的优化器RAdam(Rectified Adam)来解决这些问题,为ChatGPT中的优化器设计提供了参考。
-
Title:On the Convergence of Adam and Beyond
-
英文摘要
Several recently proposed stochastic optimization methods that have been successfully used in training deep networks such as RMSProp, Adam, Adadelta, Nadam are based on using gradient updates scaled by square roots of exponential moving averages of squared past gradients. In many applications, e.g. learning with large output spaces, it has been empirically observed that these algorithms fail to converge to an optimal solution (or a critical point in nonconvex settings). We show that one cause for such failures is the exponential moving average used in the algorithms. We provide an explicit example of a simple convex optimization setting where Adam does not converge to the optimal solution, and describe the precise problems with the previous analysis of Adam algorithm. Our analysis suggests that the convergence issues can be fixed by endowing such algorithms with `long-term memory’ of past gradients, and propose new variants of the Adam algorithm which not only fix the convergence issues but often also lead to improved empirical performance. -
简介
这篇论文是由李宏毅等人于2019年提出的一篇论文。该论文主要探讨了常用的优化器Adam在训练深度神经网络时可能出现的问题,以及提出了一种新的优化器RAdam(Rectified Adam)来解决这些问题。Adam优化器是目前深度学习中应用最广泛的一种优化器之一,但在某些情况下会出现性能下降的问题,尤其是对于较大的批次大小(batch size)和高维度的参数空间。RAdam通过引入一个修正项,对Adam进行改进,可以在更广的范围内获得更稳定的性能。该论文的研究结论和RAdam优化器已被广泛应用于各种深度学习任务中。
- The Curious Case of Neural Text Degeneration
在神经网络生成文本时,模型通常会在每一步输出一个概率分布,用来表示下一个可能的单词或字符。然而,研究人员发现,有些模型会倾向于在生成过程中不断重复相同的单词或短语,或者输出无意义的字符序列。这种现象被称为“文本退化”,因为生成的文本质量在生成过程中不断降低,最终可能完全无意义。
这篇论文探讨了神经文本生成中的退化问题,并提出了一些解决方案,对于ChatGPT的改进也具有一定的参考意义。
-
Title:The Curious Case of Neural Text Degeneration
-
英文摘要
Despite considerable advancements with deep neural language models, the enigma of neural text degeneration persists when these models are tested as text generators. The counter-intuitive empirical observation is that even though the use of likelihood as training objective leads to high quality models for a broad range of language understanding tasks, using likelihood as a decoding objective leads to text that is bland and strangely repetitive.
In this paper, we reveal surprising distributional differences between human text and machine text. In addition, we find that decoding strategies alone can dramatically effect the quality of machine text, even when generated from exactly the same neural language model. Our findings motivate Nucleus Sampling, a simple but effective method to draw the best out of neural generation. By sampling text from the dynamic nucleus of the probability distribution, which allows for diversity while effectively truncating the less reliable tail of the distribution, the resulting text better demonstrates the quality of human text, yielding enhanced diversity without sacrificing fluency and coherence. -
简介
在这篇论文中,作者首先介绍了文本生成任务中的一些基本概念和技术,包括循环神经网络(RNN)和变换器(Transformer)等模型。然后,作者详细说明了文本退化问题的出现原因和特点,并提出了一种名为“Top-k采样”的技术,用于缓解文本退化问题。该方法可以在每一步中只考虑前k个可能的单词或字符,从而避免模型倾向于生成重复或无意义文本的问题。作者在多个数据集和任务上验证了这种技术的有效性,证明了它可以显著提高生成文本的质量和多样性。此外,论文还讨论了一些与文本退化问题相关的实际应用,包括机器翻译、对话生成和摘要生成等任务。通过这些应用案例的分析,作者展示了文本退化问题对这些任务的影响,并说明了Top-k采样技术对于解决这些问题的重要性。补充资料:
关于 ChatGPT 必看的 10 篇论文
技术架构详解
ChatGPT 是一类被称为大型语言模型 (LLM) 的机器学习自然语言处理模型的外推。LLM 消化大量文本数据并推断文本中单词之间的关系。随着我们看到计算能力的进步,这些模型在过去几年中得到了发展。随着输入数据集和参数空间大小的增加,LLM 的能力也会增加。与其他 LLM 一样,ChatGPT 接受过大量不同数据源的培训,例如新闻文章、书籍、网站和社交媒体帖子,以学习语言的模式和结构。
GPT系列它们都是基于 Google 发起的革命性 Transformer 架构,那我们先从 Transformer 架构及其工作原理慢慢讲到RLHF吧。
Transformer
在提出transformer之前,我们使用基于RNN的Encoder-Decoder架构。由于使用了梯度下降,RNN 存在梯度消失的问题,科学家们很难绕过。
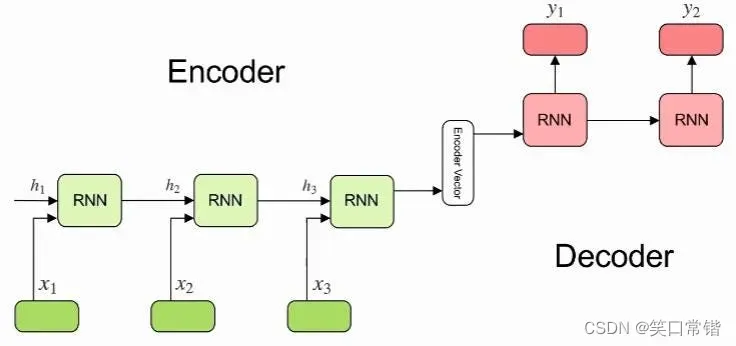
Transformer 通过仅使用 Attention 替代 Encoder-Decoder 架构中的 RNN 来避免这个问题。Transformer 的结构与 Encoder-Decoder 类似(见下图)。左侧块是编码组件,由N个编码器堆栈组成,右侧块是解码组件,包含相同数量的解码器堆栈。
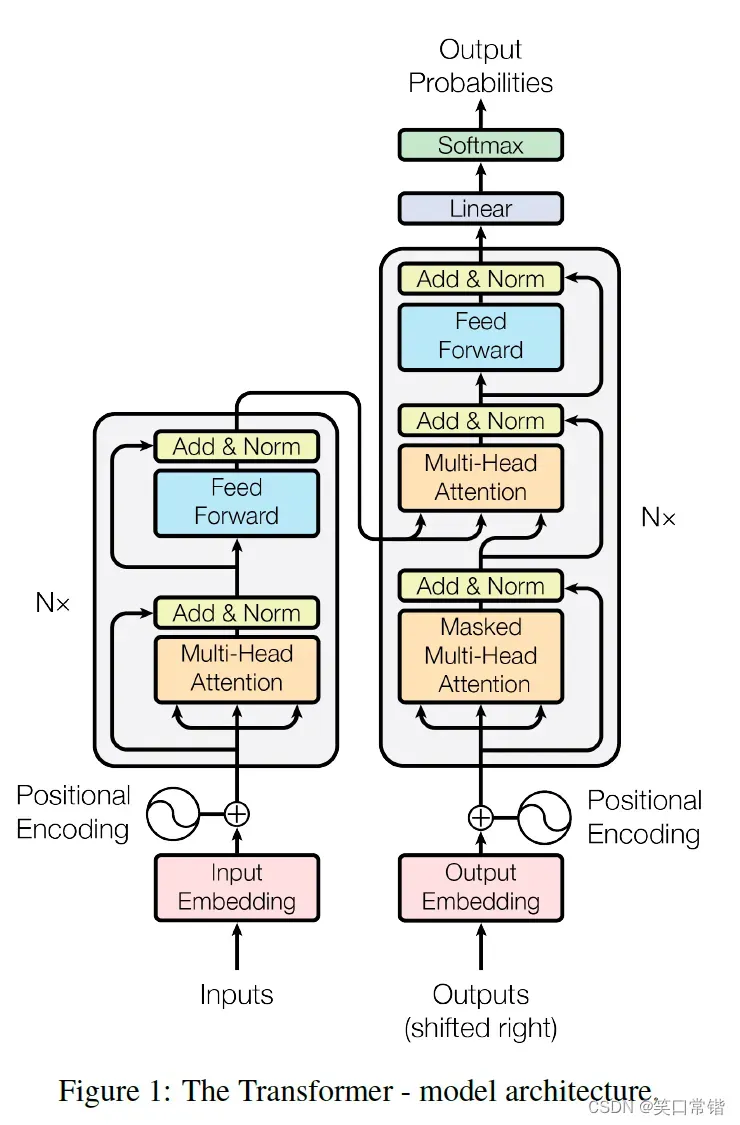
Encoder
每个编码器由两个主要层组成:多头自注意力层和前馈层。多头自注意力层使用所有输入向量来生成具有相同维度的中间向量。这个过程混合了所有输入向量的信息。前馈层是完全连接的神经网络,它独立于多头自注意层产生的每个中间向量。通过前馈层后,新向量被向上发送到下一个编码器。
Decoder
每个解码器由三个主要层组成:屏蔽多头自注意层、编码器-解码器自注意层和前馈层。顶层编码器的输出将被转换成一组注意力向量,并馈送到编码器-解码器自注意力层,以帮助解码器关注输入的适当位置。
我们在每个解码器块上重复这个过程。中间向量通过解码器中的前馈层并向上发送到下一个解码器。顶部解码器的输出通过线性层和 softmax 层来产生字典中单词的概率。我们选择概率(分数)最高的词,然后将输出反馈给底部解码器并重复该过程以预测下一个词。
Self-Attention
Self-Attention 给出输入序列的每个元素的权重,表示在序列处理中的重要性。给定权重,我们可以得到我们应该对每个元素给予多少关注的信息。
多头自注意力意味着我们计算多个中间向量并将它们组合在一起以获得与输入向量具有相同维度的新中间向量。Multi-head self-attention 可以让我们从不同的角度得到输入向量之间的关系。
masked multi-head self-attention layer 是指我们在该层中添加一个mask,使模型只能看到序列的受限窗口大小。具体来说,在解码器中,我们只让模型看到之前输出序列的窗口大小,而不是未来输出序列的位置。
GPT-3 架构
GPT-3 仅使用 transformer 的解码组件。每个解码器由两个主要层组成:屏蔽多头自注意力层和前馈层。在最大的 GPT-3 模型中,我们使用了 1750 亿个参数、96 个自注意层、2048 个令牌窗口大小的掩码以及每个多头自注意层的 96 个自注意头。与转换器一样,GPT-3 基于输入和先前生成的标记,一次生成一个标记的输出文本。
GPT-3.5(ChatGPT)
GPT-3.5是GPT-3的微调版本,在GPT-3模型的微调阶段加入了RLHF。
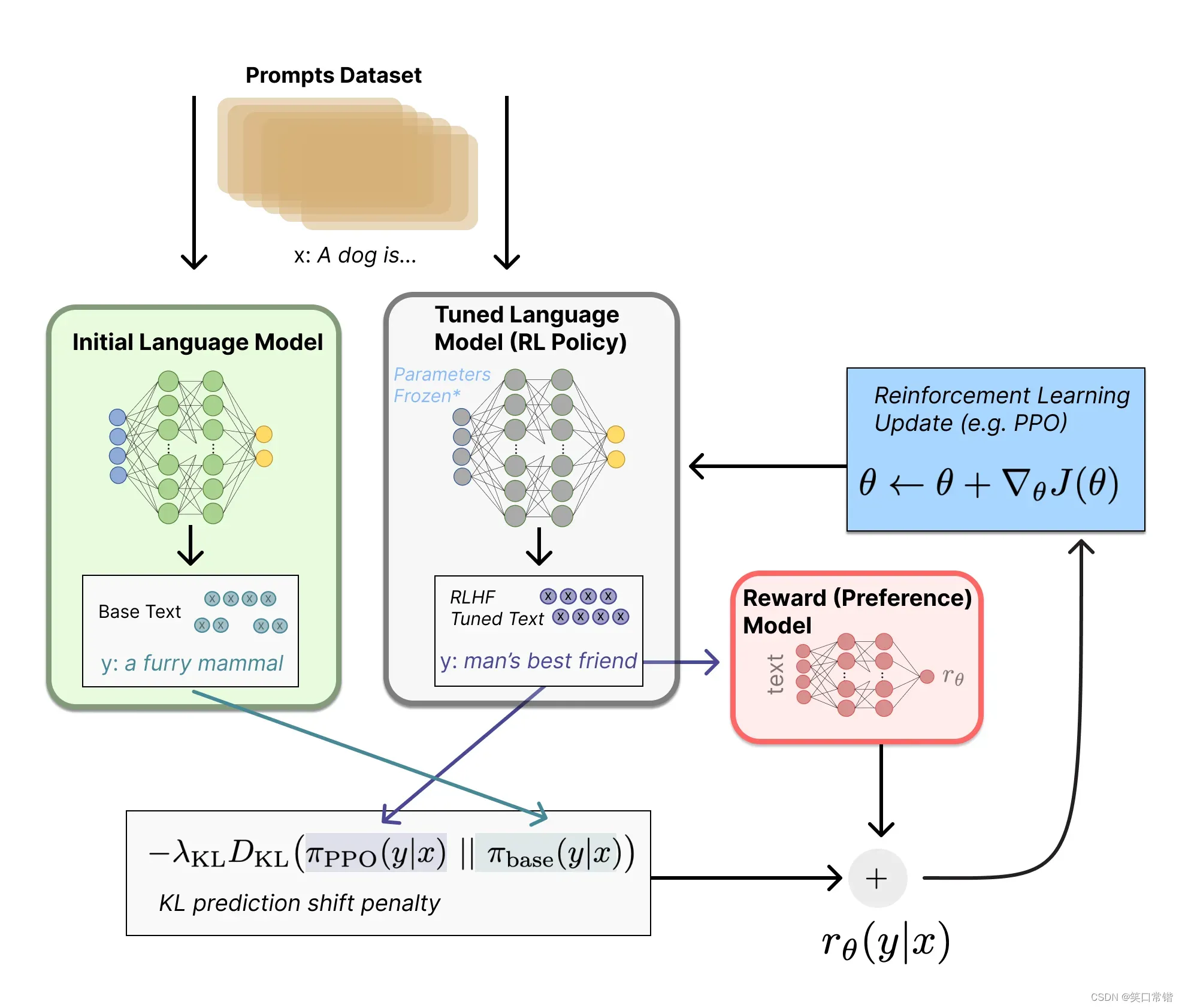
RLHF(人类反馈强化学习)
RLHF 涉及三个主要步骤:预训练语言模型 (LM)、收集数据和训练奖励模型 (RM),以及使用强化学习微调语言模型。
在 ChatGPT 中,我们使用 GPT-3 的监督微调 (SFT) 版本作为语言模型。
RLHF 中 RM 的目标是给定一个文本序列,RM 可以返回一个应该代表人类偏好的标量奖励。用于训练 RM 的数据通过以下步骤收集。首先,我们从预定义数据集向 LM 提供一组提示,并从 LM 获得多个输出。其次,人工注释者将同一提示的输出从最佳到最差进行排序。第三,RM 使用带注释的提示数据集和 LM 生成的输出来训练模型。
对于强化学习部分,我们首先使用策略梯度 RL PPO(近端策略优化)从第一步复制原始 LM。对于从数据集中采样的给定提示,我们从原始 LM 和 PPO 模型中得到两个生成的文本。然后我们计算两个输出分布之间的 KL 散度。为了计算可用于更新策略的奖励,我们使用 PPO 模型的奖励(即 RM 的输出)减去 λ 乘以 KL 散度。
ChatGPT的训练
ChatGPT 取得惊人成绩的一个重要特点是在训练过程中引入了人类反馈强化学习(RLHF),以更好地捕捉人类的偏好。OpenAI团队从GPT-3.5系列中的一个模型进行微调,使用与 InstructGPT相同的方法,用人类反馈强化学习(RLHF)训练该模型,并对数据收集设置相对做了优化。
ChatGPT模型的训练过程主要分为三个主要阶段:
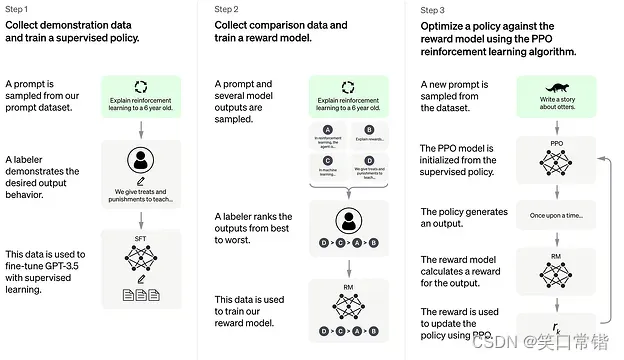
来源:https://www.hpc-ai.tech/blog/colossal-ai-chatgpt
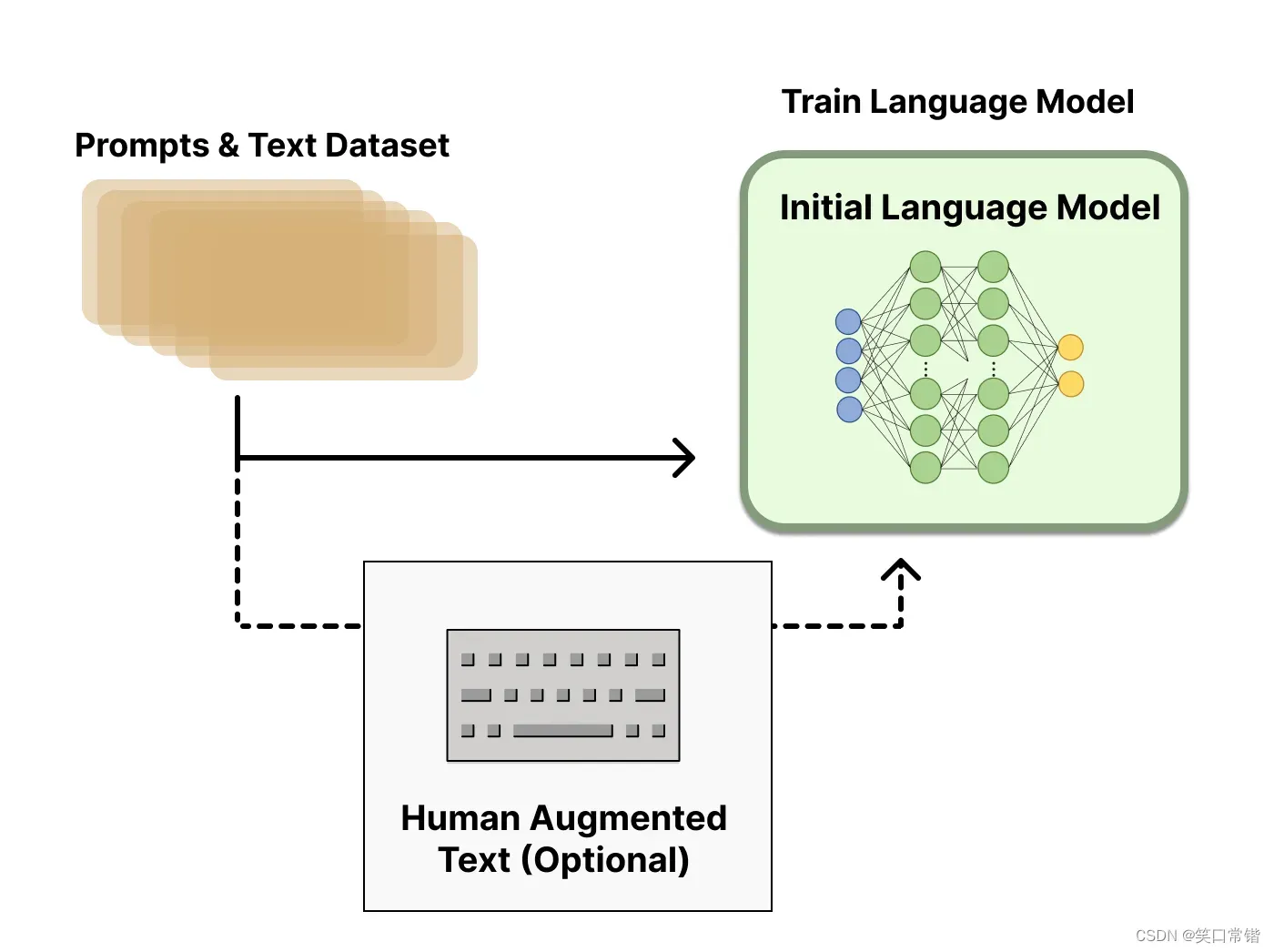
第一阶段:从 Prompt 库中抽样,收集其人类反应,并使用这些数据微调预训练的大型语言模型。(训练监督策略模型)
GPT 3.5本身很难理解人类不同类型指令中蕴含的不同意图,也很难判断生成内容是否是高质量的结果。
为了让GPT 3.5初步具备理解指令的意图,首先会在数据集中随机抽取问题,由人类标注人员,给出高质量答案,然后用这些人工标注好的数据来微调 GPT-3.5模型(获得SFT模型, Supervised Fine-Tuning)。
此时的SFT模型在遵循指令/对话方面已经优于 GPT-3,但不一定符合人类偏好。
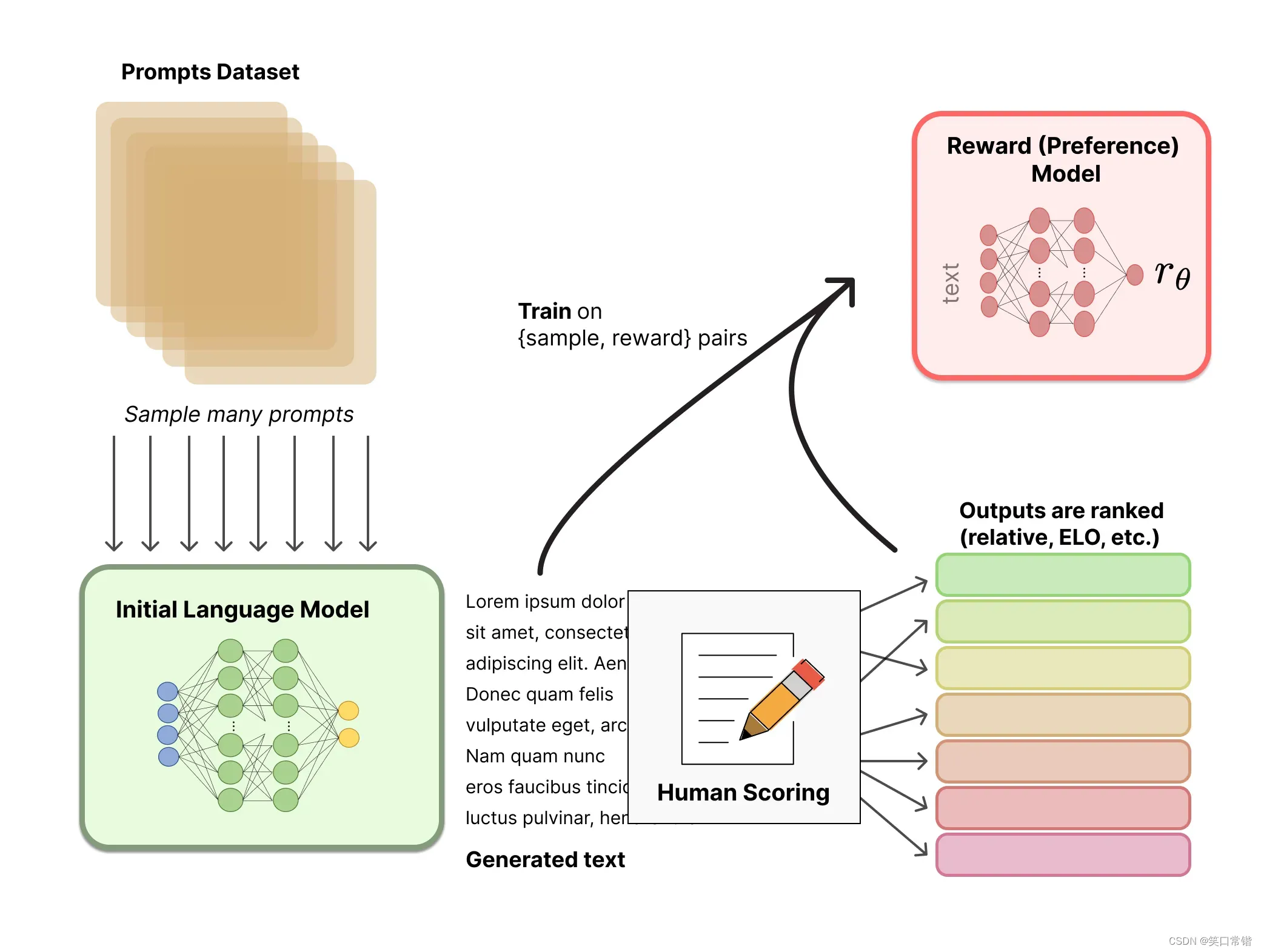
第二阶段:从 Prompt 库中采样,使用大型语言模型生成多个响应,手动对这些响应进行排序,并训练奖励模型 (RM) 以适应人类偏好。(训练奖励模型(Reward Mode,RM))
这个阶段的主要是通过人工标注训练数据(约33K个数据),来训练回报模型。
在数据集中随机抽取问题,使用第一阶段生成的模型,对于每个问题,生成多个不同的回答。人类标注者对这些结果综合考虑给出排名顺序。这一过程类似于教练或老师辅导。
接下来,使用这个排序结果数据来训练奖励模型。对多个排序结果,两两组合,形成多个训练数据对。
RM模型接受一个输入,给出评价回答质量的分数。这样,对于一对训练数据,调节参数使得高质量回答的打分比低质量的打分要高。
第三阶段:基于第一阶段的监督微调模型和第二阶段的奖励模型,使用强化学习算法进一步训练大型语言模型。(采用PPO(Proximal Policy Optimization,近端策略优化)强化学习来优化策略。)
PPO的核心思路在于将Policy Gradient中On-policy的训练过程转化为Off-policy,即将在线学习转化为离线学习,这个转化过程被称之为Importance Sampling。这一阶段利用第二阶段训练好的奖励模型,靠奖励打分来更新预训练模型参数。在数据集中随机抽取问题,使用PPO模型生成回答,并用上一阶段训练好的RM模型给出质量分数。
把回报分数依次传递,由此产生策略梯度,通过强化学习的方式以更新PPO模型参数。
如果我们不断重复第二和第三阶段,通过迭代,会训练出更高质量的ChatGPT模型。
如果想自己等效且低成本复制ChatGPT训练过程,可参考该解决方案Colossal-AI
开源解决方案复制了 ChatGPT 培训过程!只需 1.6GB GPU 内存即可使用,训练速度提高 7.73 倍!
行业未来和投资机会
ChatGPT的产业未来
ChatGPT作为一种聊天机器人模型,具有广泛的应用前景。它可以帮助企业和个人提高工作效率,实现客户服务自动化,并且在保证服务质量的同时节省大量人力成本。同时,ChatGPT可以用于语音识别、智能客服、智能对话系统等多种场景。随着人工智能技术的不断发展,ChatGPT将有望进一步拓展其应用范围,从而为企业和个人带来更多价值。总体来说,ChatGPT有着巨大的产业潜力,是一种有前途的人工智能技术。它将在未来不断发挥重要作用,推动人工智能产业的发展。
- 2023年2月2日,ChatGPT订阅计划—-ChatGPT Plus发布,目前每月20美元,说明商业化序幕已经拉开。ChatGPT Plus订阅者可获得比免费版本更稳定、更快的响应速度和更高的优先体验权。
-
ChatGPT+传媒:实现智能新闻写作,提升新闻的时效性。
它可以作为一种智能内容生成工具,帮助制作和编辑人员更快地创建高质量的内容。此外,它还可以作为一种智能客服工具,帮助公司更好地处理客户询问和建议,提高客户满意度。例如,新闻编辑人员可以使用 ChatGPT 来生成新闻摘要和标题,广告公司可以使用它来生成广告文案,在线客服可以使用它来快速回答客户询问。 -
ChatGPT+营销:打造虚拟客服,赋能产品销售。
它可以作为一种智能内容生成工具,帮助营销人员更快地创建高质量的营销内容。此外,它还可以作为一种智能客服工具,帮助公司更好地处理客户询问和建议,提高客户满意度。例如,营销人员可以使用 ChatGPT 来生成营销电子邮件、社交媒体帖子和广告文案,销售人员可以使用它来快速回答客户询问,从而提高客户对产品和服务的信心。
-
ChatGPT+娱乐:人机互动加强,激发用户参与热情。
ChatGPT 在娱乐领域具有很多潜在的应用。例如,开发人员可以利用它创建聊天机器人应用程序,以便与用户进行互动,制作更具娱乐性的内容。此外,它还可以作为一种问答智能系统,通过回答用户关于游戏、电影、音乐等方面的问题,来提高用户体验。ChatGPT 可以帮助娱乐公司制作出更具互动性和娱乐性的内容,同时可以帮助他们提高用户体验,增加用户满意度。在未来,随着人工智能技术的发展,ChatGPT 在娱乐领域的应用前景也将非常广阔。 -
ChatGPT+教育:赋予教育教材新活力,让教育方式更个性化、更智能。
它可以作为一种智能助手,帮助学生更快地获得信息,解决学习中的问题,并且还可以作为一种教学工具,帮助教师更好地控制课堂气氛,提高教学效率。例如,学生可以使用 ChatGPT 获得关于课程内容的实时回答,教师可以使用它来评估学生的学习进度并且提供相应的支持。此外,ChatGPT 还可以通过语音识别和语音合成技术帮助辅助语音处理障碍的学生。 -
ChatGPT+其他:促进数实共生,助力产业升级。
医疗保健:通过让 ChatGPT 对患者的健康问题进行快速诊断,以帮助医生制定更准确的诊疗计划。
金融:通过让 ChatGPT 回答客户的财务问题,以帮助银行和金融机构提高客户服务质量。
商业:通过让 ChatGPT 回答销售代表的问题,以帮助他们更快地解决客户问题,并提高销售业绩。
制造业:通过让 ChatGPT 回答工程师的问题,以帮助他们更快地解决生产问题。
这些仅仅是 ChatGPT 应用的一些例子,实际上它还可以在其他许多行业得到应用。随着人工智能技术的不断发展,ChatGPT 在不同行业的应用前景也将越来越广阔。
AIGC商业方向
AIGC (Artificial Intelligence for General Computation) 商业方向主要围绕人工智能的应用,具体来说可以有以下几点:
-
AIGC赋能–搜索引擎
AIGC 技术可以帮助搜索引擎更加智能地理解用户的查询,并返回更准确、更相关的搜索结果。这是因为它可以根据用户的查询历史和语言模式来判断用户的需求,并为其生成相应的回答。例如,如果用户查询“最近有什么好电影”,搜索引擎可以使用 AIGC 技术来识别用户对电影类型、上映日期等的具体要求,并返回相应的搜索结果。此外,AIGC 技术还可以帮助搜索引擎提高其自然语言处理能力,使其能够更好地理解和回答用户的询问。
Microsoft Bing在2009年5月28日由微软推出,截至2013年5月已成为北美地区第二大搜索引擎,加上为雅虎提供的搜索技术支持,必应已占据29.3%的市场份额。Bing同时集成了网页、图片、视频、词典、翻译、资讯、地图等全球信息搜索服务。新版Microsoft Edge功能于2月8日发布,将加入AI聊天和相关写作功能。根据TechCrunch报道,除聊天功能外,这些写作功能可以有效帮助用户对长文章归纳总结提炼重点、对比筛选文章内容以及创造新内容。此外新版BING可以协助用户生成内容,包括电子邮件、规划旅行等。
-
AIGC赋能–新闻媒体
AIGC 技术也可以应用于新闻媒体。AIGC 技术可以帮助新闻媒体快速生成大量高质量的新闻报道,从而提高新闻媒体的生产效率。此外,AIGC 技术还可以帮助新闻媒体生成个性化的新闻报道,以满足不同读者的需求。例如,如果新闻媒体想要生成关于某地区经济发展情况的新闻报道,它可以使用 AIGC 技术来快速生成大量相关的新闻报道。这些新闻报道可以囊括该地区的经济数据、投资情况、就业情况等方面的信息,以满足读者对该地区经济情况的关注。AIGC 技术的应用于新闻媒体,可以提高新闻媒体的生产效率,同时也可以提供更多、更准确、更个性化的新闻信息,从而更好地满足读者的需求。 -
AIGC渗透传媒行业各个领域。随着人工智能技术的不断提高,未来它们在传媒行业的应用将更加广泛。
新闻采写:可以帮助新闻媒体快速生成新闻报道,并缩短新闻生成的时间。编辑:可以帮助编辑快速生成各种类型的文本,如简报、评论等。
广告: 可以帮助广告公司快速生成各种类型的广告文本,如广告语、广告标语等。
节目制作:可以帮助电视台和节目制作公司生成节目剧本、对话等内容。
数字内容:可以帮助数字内容公司生成各种类型的数字内容,如微信文章、微博等。
-
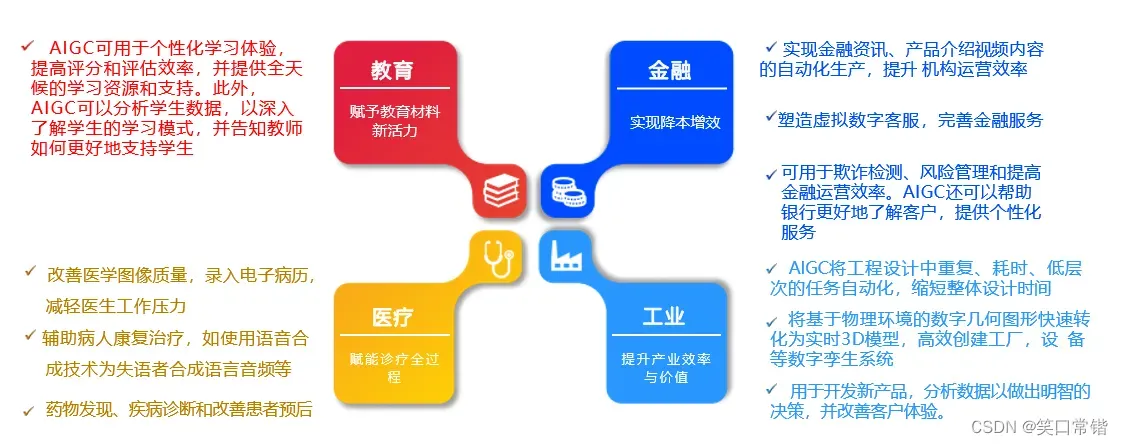
AIGC促进各行业升级转型
AIGC技术不仅仅可以帮助传媒行业,它还有可能帮助其他行业实现升级转型。AIGC在各个行业的优势在于它能够处理和分析大量的数据,做出明智的决策,提高效率,并提供个性化的体验。
常见问题解答
问:如何训练我自己的 ChatGPT 或 GPT-3?如何才能做到这一点吗?
答:当然!这实际上很容易做到。要达到 GPT-3 175B davinci 模型标准(及以上),您需要具备以下条件:
1.培训硬件:使用拥有约 10,000 个 GPU 和约 285,000 个 CPU 内核的超级计算机。如果你买不到它,你可以像 OpenAI 对微软所做的那样,花费他们10 亿美元(USD) 来租用它。
2.人员配备:对于培训,您需要接触世界上最聪明的博士级数据科学家。2016 年, OpenAI 每年向首席科学家 Ilya Sutskever 支付190 万美元(USD),他们拥有一支 120 人的团队。第一年的人员配置预算可能超过 2 亿美元。
3.时间(数据收集): EleutherAI 花了整整 12-18 个月的时间来同意、收集、清理和准备 The Pile的数据。请注意,如果 The Pile 只有 ~400B 代币,你需要以某种方式至少四次找到 The Pile 质量的数据才能做出类似于新效率标准的东西,即 DeepMind 的 Chinchilla 70B(1400B 代币),你可能想要瞄准现在几个 TB 就可以胜过 GPT-3。
4.时间(训练):预计模型需要 9-12 个月的训练,如果一切顺利的话。您可能需要多次运行它,并且可能需要并行训练多个模型。事情确实出错了,它们可能会完全弄乱结果(参见GPT-3 论文、中国的 GLM-130B和Meta AI 的 OPT-175B 日志)。
问:ChatGPT 是否在向我们学习?它有感觉吗?
答:不,2022 年没有语言模型是有感知力/意识的。ChatGPT 和 GPT-3 都不会被视为有感知力/意识。这些模型应该被视为非常非常好的文本预测器(就像你的 iPhone 或 Android 文本预测)。为了响应提示(问题或查询),AI 模型经过训练以预测下一个单词或符号,仅此而已。另请注意,当不响应提示时,AI 模型是完全静态的,没有思想或意识。
问:ChatGPT出来之后,对我们国内相关产业的影响?国内相关的厂商,阿里、百度未来一段时间落地情况?
专家答:关于从国家层面,GPT这个产品推出以后,网信办已经发出了一些政策相关的东西。从国家层面的角度来说,短期内我们很难看到ChatGPT这些产品直接跟国内的应用,或者做比较深度的结合,因为这块不管是基于信息安全,还是国内的一些产业保护的角度来说,国内可能都得需要有这样一个窗口期,得需要有逐步缓冲的时间。所以,国家后续会出台相关的政策,给国内的玩家们提供追赶的时机。从我们之前对百度文心类似产品的使用体验来看,内容的质量上百度文心和ChatGPT差距不是特别大,只是在内容的多样性上有差距。咱们国内研究相关的大模型的,目前主要靠工程人员和研发人员,大概几百号人或者上千号人这么研发,在这个过程中没有引入像OpenAI这种用户反馈机制,没有大量的用户在技术模型的迭代过程中参与进来。所以在内容的多样性上会有所欠缺。第三,可能跟目前实际没有放开政策有关系,就是比如像ChatGPT响应能力,一个Q过去,A回来大概是1-3秒,响应能力比较快。目前百度文心这边我们能够体验到的,大概短的在20秒左右,长的甚至在80秒以上。当然这个不是技术瓶颈问题,需要在模型研发完成以后,我需要在服务器做部署,部署完之后支持数以百万计,甚至数以千万计高并发访问的需求,这块属于常态的部分。
未来3-6个月左右的时间,像百度文心、阿里推出类似于ChatGPT的产品应该可以达到目前ChatGPT60%-70%左右的水平。
参考链接:GPT-3.5 + ChatGPT: An illustrated overview
个人总结
从优缺点的角度简单评价一下ChatGPT吧。
ChatGPT的优点在于其能够生成高质量的文本,并具有出色的语法理解能力和语义理解能力。这使得它能够适用于多种应用场景,例如聊天机器人、问答系统、机器翻译等。
然而,ChatGPT也存在一些缺点。由于它是基于大量文本数据进行训练的,因此它可能会受到数据偏见的影响,导致生成的文本具有偏见性。此外,ChatGPT也不能很好地处理诸如情感分析、推理等复杂任务。还有潜在威胁,如黑客可以利用 ChatGPT的回答教学轻松入侵网络、存在prompt injection问题可泄露信息和可能侵犯知识产权等等问题。
尽管存在一些缺点,ChatGPT仍然是一种非常有前途的技术。它的出色表现和广泛应用场景使其成为人工智能领域内值得关注的一个重要领域。未来,我们可以期待ChatGPT在更多领域得到广泛应用,并在提高生成文本质量、减少数据偏见等方面取得更多进展。直接转NLP了,CV玩不转(doge)
ChatGPT 一个划时代的产品,AI平民化的里程碑
呼~~,终于写完了,接下来要专心备考我的研究生啦,二战路漫漫,小锴常叹叹,祝自己上岸成功,也希望大家各自努力顶峰相见!
笔者水平有限,必定存在问题,欢迎大家交流讨论感谢感谢;
参考资料
1.ChatGPT
2.国泰君安证券研究。ChatGPT研究框架(2023)
3.华西证券研究所。ChatGPT: 重新定义搜索“入口”AIGC行业深度报告
4.ChatGPT and the Model Behind
5.Illustrating Reinforcement Learning from Human Feedback (RLHF)
6.How ChatGPT Works: The Model Behind The Bot
7.ChatGPT、LLM 和 Foundation 模型——仔细研究炒作和对初创公司的影响
8.ChatGPT发展历程、原理、技术架构详解和产业未来
9.精选的 ChatGPT 演示、工具、文章
10.ChatGPT内核:InstructGPT,基于反馈指令的PPO强化学习
11.万字长文教你如何做出 ChatGPT
+文章中所有提及的链接
欢迎大家交流,您的点赞关注收藏是对我最大的鼓励噢,本文为博主原创文章,转载请附上原文出处链接和声明。
文章出处登录后可见!