最近完成了一个项目,利用python+yolov5实现数字仪表的自动读数,并将读数结果进行输出和保存,现在完成的7788了,写个文档记录一下,若需要数据集和源代码可以私信。
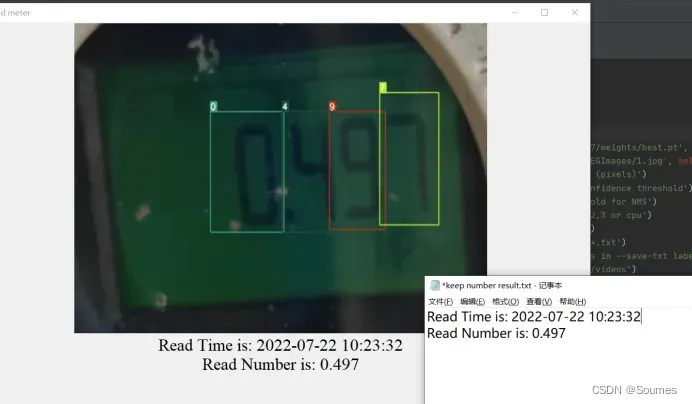
最后实现的结果如下:
项目过程
首先查阅文献和文档,好家伙,不看不知道,做相似项目的很多资料都是硕士研究生的毕业项目,看来还是有一定难度的,做完以后可以自己给自己颁发一个硕士研究生水平证明。
先归纳一下我总体的思路:
第一步是利用各种目标检测技术(包括SSD,YOLO等,我用的是YOLOV5)从图中识别并提取仪表,这样做可以将仪表从复杂的背景图中提取出来,去掉无关紧要的背景信息,在后续训练的时候可以让网络更集中的学习需要学习的特征,从而降低训练所需要的时间,优化训练的结果。(这里亲测带着背景直接训练和提取表盘再训练两个结果差很多,在precision和recall上都可以有一个0.3左右的差距,并且在速度上明显提取后收敛的更快,读数表现更好)


这部分的实现很简单,制作一个仪表盘的数据集,只对表盘进行标注,随后训练网络识别仪表,在输出结果的时候写一个裁切方法把识别的图像裁切出来就可以了,比较简单,不多赘述。这里分享一个算法,由于网上保存的图像乱七八糟的,如果直接使用可能会遇到很多格式报错,但是往往格式导致的报错都很难排查,所以通过下面这个算法,可以将下载的图像里面乱七八糟的格式去掉,只保留jpg文件需要的rgb元素,这样可以保证格式不出错:
import os
from PIL import Image
class convert2RGB():
def __init__(self, path):
# 图片文件夹路径
self.path = "../"
def convert(self):
filelist = os.listdir(self.path)
for item in filelist:
if item.endswith('.jpg') or item.endswith('.png'):
print(item)
file = self.path + '/' + item
im = Image.open(file)
length = len(im.split())
if length == 4:
r, g, b, a = im.split()
# im = img.convert('RGB')
im = Image.merge("RGB", (r, g, b))
os.remove(file)
im.save(file[:-4] + ".jpg")
if __name__ == '__main__':
# 输入自己的需要处理的文件夹路径
imgPath = '../'
demo = convert2RGB(imgPath)
demo.convert()
第二步是对提取后的表盘图像进行处理,由于各种各样的原因,我们实际上获得的表盘图像不一定都是很清晰,角度很正,光线很好的情况。肯定会存在拍摄角度倾斜,或者光线过亮或过暗等情况,所以需要进行一个图像预处理,将图像都转换为我们比较喜欢的亮度均匀,角度正对着我们的图像。


这里主要是进行一些图像增强,利用算法对提取的表盘图像进行矫正,清晰化,比如一个倾斜的或者不是从正面角度拍摄的仪表,可以通过算法进行空间变换矫正,将表盘从歪歪斜斜的角度调整为“面朝我们”,同时一些表盘图像由于拍摄时光线不好,或者相机太烂,图像不清晰,存在过亮或者过暗的情况,需要用算法对图像的明暗分布进行一个平衡化处理,同时利用滤波算法去除掉图像的噪点,让图像更清晰和平滑,方便我们读数。

可以看到图像处理过后有明显的改善,有利于后续的训练和读数,所以这一步是非常有必要的,在这一步针对不同的图像问题编写了多个算法,这里分享一个比较实用的,可以根据图像的亮暗来自动调用不同的算法进行亮度均匀化处理:
# 这个算法是用来进行自动化图像处理的,可以对一个文件夹中的图像进行处理
# 具体效果是可以自动判断图像的亮暗,然后调用不同的算法对图像进行处理,让图像更清晰,方便后续的读数
import os
import cv2
path = "" # 读取图片的路径
save_file = "" # 保存图片的路径
for i in os.listdir("/VOCdevkit/VOC2007/JPEGImages/"): # 批量读取 批量保存
img = cv2.imread(path+"/"+i,0) # 读取顺便灰度化
r, c = img.shape[:2]
dark_sum = 0 # 偏暗的像素 初始化为0个
dark_prop = 0 # 偏暗像素所占比例初始化为0
piexs_sum = r * c # 整个弧度图的像素个数为r*c
for row in img:
for colum in row:
if colum < 40: # 人为设置的超参数,表示0~39的灰度值为暗
dark_sum += 1
dark_prop = dark_sum / piexs_sum
if dark_prop >= 0.30: # 人为设置的超参数:表示若偏暗像素所占比例超过0.30,调整这个参数 来调整判断图像亮暗的尺度
print(" is dark!") # 暗的图像
equa = cv2.equalizeHist(img)
result1 = cv2.GaussianBlur(equa, (3, 3), 3)
cv2.imwrite(save_file+"/"+"%s" %i, result1)
# 对于比较暗的图像,调用图像均衡化算法进行图片增强和高斯滤波去噪
else:
print(" is bright!")
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8)) # 创建CLAHE对象
dst = clahe.apply(img) # 限制对比度的自适应阈值均衡化
result = cv2.GaussianBlur(dst, (3, 3), 3)
cv2.imwrite(save_file+"/"+"%s" %i, result)
# 对于比较亮的图像 调用CLAHE 限制对比度的直方图均衡化进行图像处理,并采用高斯滤波去噪第三步将图像都处理好后,就开始进行标注和训练了,使用的是labelimg进行标注,同时由于常见的数据集,如coco等没有仪表图像,所以所有的数据集只可以手动获取,这里也是花了很多时间进行数据集的收集制作,主要的方式有直接搜索存图(这里推荐使用以图搜图的方式进行查找,比直接搜索可以得到更多更相关的图像),购买别人仪表数据集,最后整理了一份几百张的数据集。但是对于一个深度学习任务来说,几百张的数据集是远远不够的,所以还需要进行数据增强,也就是数据集扩充。本来想着调用opencv直接遍历文件夹对图像进行各种变换就可以了,但是一想到后面生成的数以千计的图像还要再标注,心情是崩溃的,本着能偷懒就偷懒的原则,我就想能否在进行数据增强的时候,带着标记好的文件一起变换,思路一打开动力就来了,果然前人早就遇到过这个问题,并且想到了解决方案,不得不感叹我们真的是站在巨人的肩膀上前进。我借鉴了一些前人的算法,改良出了一个数据增强算法,可以扩充数据集,并且可以带着标签一起变换,不需要再做其他标注了。最后在进行数据增强以后也是把数据集的图像扩充到了4位数,开始喂给网络训练。
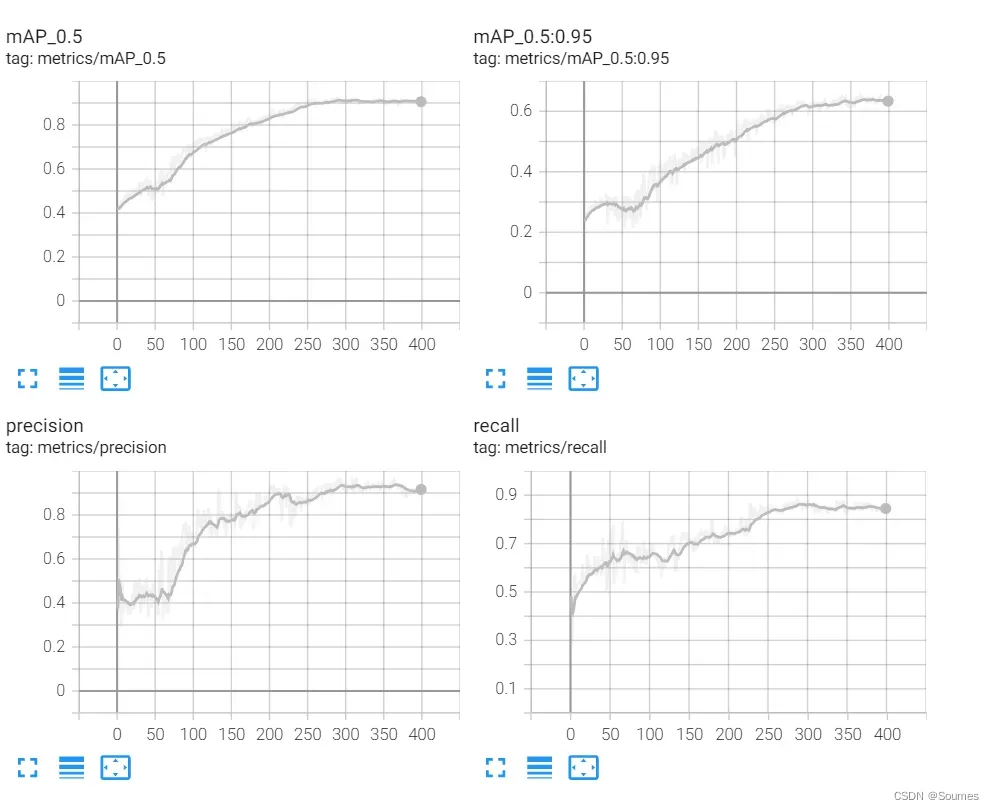
在训练的过程中要关注各个参数的值,不能在一旁打lol就不管了,yolov5提供了很棒的可视化工具tensorboard,一定要用起来,通过分析tensorboard里面的各大性能指标曲线,不仅可以实时了解训练的情况,还可以在训练跑完后帮助我们找到可能存在的问题,从而进行对应的调整。
tensorboard --logdir=runs/train # 可视化命令最后一次训练完我的参数跑的已经相当不错了,但是都是一路摸索过来的,一路上经历了precision很高但是recall很低,recall很高但是precision左右横跳,误判率高的吓人等等问题,但是都一步一步调整了过来,在tensorboard里面把所有曲线都打开,可以看到每一次的对比,没有什么成功是一蹴而就的,都需要一个过程,努力吧,骚年!
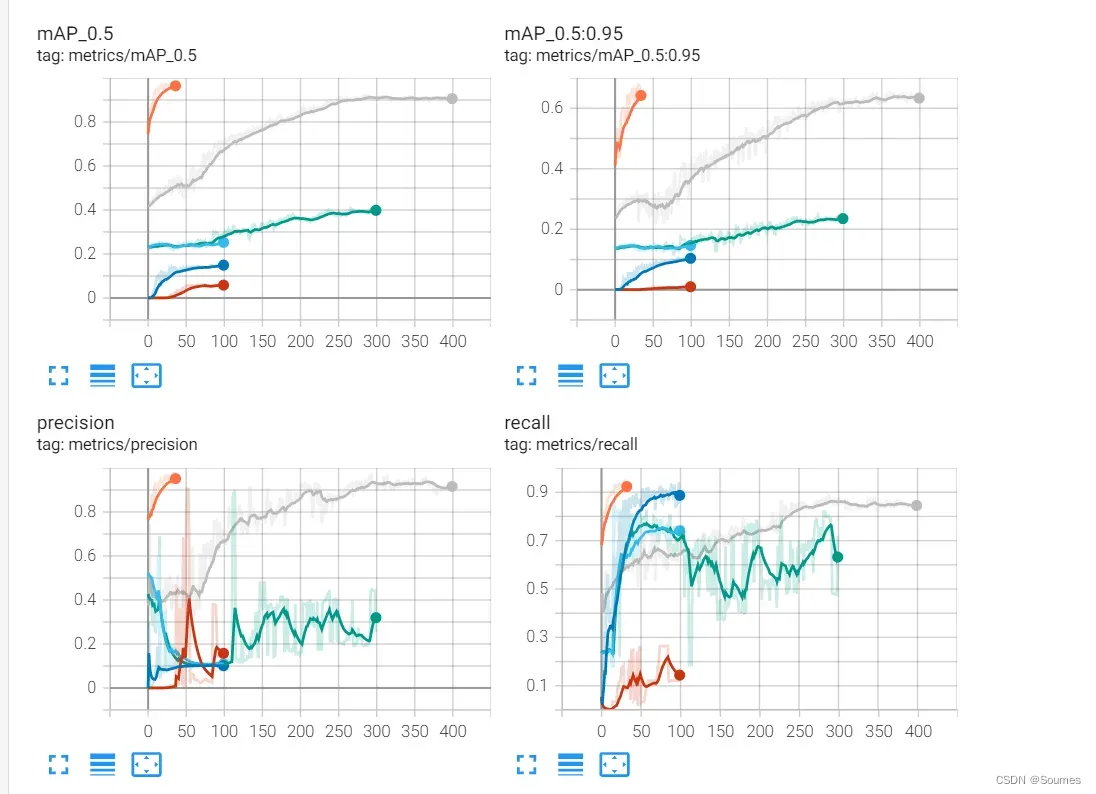
训练完成之后,就是喜闻乐见的detect环节,虽然网络已经提供了自带的训练结果展示,但是我还是留了一小部分数据,没有当测试集也没有当数据集,就是留着检验模型的成果,结果如下,效果还是很不错的。

没有显示置信度是因为我手动设置了不显示置信度,同时还修改了框的粗细,因为都是数字,比较密集,如果显示置信度以及用原始的框的粗细的话会导致识别结果很难看,就像下图

检测完毕之后,其实神经网络已经可以实现大体上的任务了,但是还需要写一个接口,获得读数的数值和读数的时间,如果还能把读取的图片一并显示出来就更好了,这样才像一个比较成熟的系统,总不能一直在pycharm里的控制台来看结果吧。
第五步动手尝试实现一个接口,完成上述目标,看起来简单,做起来难,因为要做一个接口意味着要能够获取到网络detect过程中的参数,同时把他拿出来为己用,这需要对yolov5的源码很了解,才可以做到随心所欲的从里面拿走参数,于是我又花了一段时间来啃yolov5的源码。功夫不负有心人,在一段时间的硬啃之后,我已经大概明白yolov5的推理过程,于是我在源代码的基础上加了一些内容,实现了这个接口功能,具体实现思路如下:
1、首先阅读源代码我们知道,yolov5是先检测到目标以后,再将检测到的目标的信息传递给一个绘图工具(plot_one_box),由这个工具在图像上把检测的目标框起来,并打上其类别和置信度,所以我们要做的就是获得这个检测目标的各种信息,同时我们也要明确,这个信息包含着检测目标的位置信息,类别信息,和置信度。
2、其次我们要知道,yolov5在进行目标检测的时候是无序的,比如一张图上有两只狗一只猫,yolov5在检测的时候有可能先检测出猫,然后把它在图上框出来,再去检测狗1和狗2,也有可能是狗1,猫,狗2,在我们的任务中,一个表的示数是0479,yolov5不一定是按照0479这个顺序来检测,有可能是4790,4097,4970,这就给我们带来了麻烦,表的读数是有序的,yolov5的检测是无序的,我们需要先排序。
3、排序的方法,考虑到仪表读数一定是从左往右依次读取,所以如果可以获得每个检测目标的位置信息,随后计算出中心点坐标,按照中心点坐标从小到大的顺序来输出(yolov5的坐标轴原点在图像的左上角),得到的结果自然就是从左往右的读数结果了,所以我们明确了目标,获得位置信息,计算中心坐标,将中心坐标排序,并按照这个排序输出对应的类别,也就是读数。
4、接下来就是coding过程,烧了几天脑子后,写出了一个读数工具,可以获取网络每次检测目标的参数,同时计算其中心坐标点,并将其和本次检测的目标以键值对的方式保存在字典里,比如0和4在图中的位置是0,4那么就会创建一个字典,保存的内容是{123:0,223:4}最后由于123小于223,所以先输出0再输出4,就完成了对于读数的正确输出。
最后能够get到读数以后,又花了一些时间,学习编写了一个简单的UI界面,能够显示出本次读取的图片,读数的时间,和读数的结果,同时在本地创建一个txt,把每一次读数的时间和结果保存,方便后续查看。在这里也遇到了一个问题,就是小数点,由于不同类型的表小数点的位置都不同,如何正确输出小数点,也是一个问题,我尝试了前期标注小数点,让网络去识别的方法,但是效果很一般,原因就是小数点就是黑不溜秋的一个小点,基本上没有什么特别的特征,并且小数点实在是太小了,记得武忠祥老师有一句话,叫做有条件麻溜点上,没有条件创造条件也要上,我宁愿犯错,也不愿什么都不做#¥%……&*,所以在考虑后,打算用算法解决,烧了一下脑子,写了一个小数点算法,可以根据表的读数和表的类型自动加上小数点,到此终于完工了,运行,输出,结果如下:

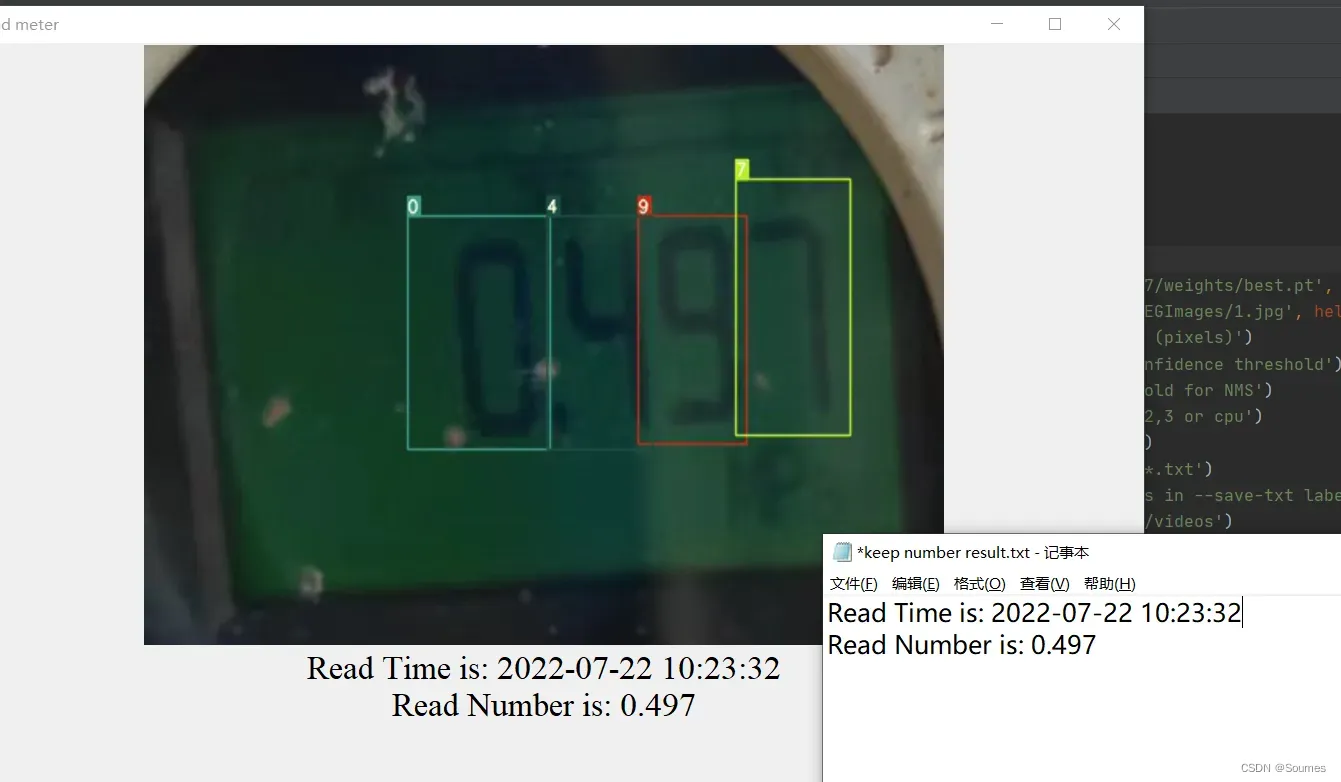
可以看到在一个UI窗口正确输出了读数的时间和读数的值,并且在txt中保存了当下读数的时间和读数的值,这么模糊的图都能够正确读数,由此可见读数效果还是不错的….
最后的最后再将写的各种算法进行封装整理,写进yolov5的源码里串联在一起,这样只需要丢进去一张图片,就可以直接得到如上的UI界面,并保存读数,不用手动跑多个程序了,舒服多了,其实可以再写一个入口的UI界面,完全做成一个读表的小程序,但是由于作者太懒,所以暂时先搁置吧,以上就是这一个项目的大致总结,如果想起来什么再进行补充吧….
(下面是一点总结碎碎念,内容已经全部写完,如果只是借鉴思路的话,以下可以跳过)
本次项目中学到了:
- 项目到手后先多读文献,多查,多看,上到期刊paper,下到csdn各种文档,这个过程主要的目的就是看看前人是怎么做这个任务的,积累思路,如果遇到不错的方法可以做一下笔记,这个互联网时代,最不缺的就是资源,只要你愿意去找。
- 遇到问题先去搜索,看看是否有人遇到过类似的问题,看看别人是怎么解决的,吸收思路,站在巨人的肩膀上学习可以更有效率,如果没有找到类似的问题就自己排查,将代码分成不同的块,一块一块执行,执行一步就print出来,看看是哪一步出了问题。如果是很复杂的算法,就把核心模块写一个简化版本,看看核心部分可不可以跑通,如果核心区域没问题,那就可以考虑是不是数据的传入,或者类型的转换出了问题,实在不行就保留核心,其他重写。如果是和文件,路径,数据集有关的问题,那就一定要打开对应的文件路径看看,是不是有什么东西忘记删除,有中文路径,或者某一个图片有点问题,导致了整个数据集跑不起来,可以遍历文件,一张一张图排查,找到罪魁祸首。如果实在无法解决问题,那就直接remake,从头开始,仔细的把每个步骤过一遍,有时候项目大了注意力分散,很容易在细节的地方出问题,从头走一遍可以帮助自己找到细节的问题。
- 不可以忽视理论的重要性,虽然刚开始做这个项目的时候我也是想着赶紧先把整体功能干出来,再去看理论,但是做着做着发现,理论不仅可以帮你优化你的模型,还可以帮你找到很多问题,如果理论理解的比较清晰,甚至可以更改这个大框架,让他为你服务。理论,源码要多看,多积累,但是不可以看了就算了,要做做笔记,毕竟看的过程也是学的过程,学一遍就写一遍,加深印象。
- 书里的知识就当做是字典,是help文档,可以帮助你解决一些问题,但是真正的创新还是藏在解决问题的过程之中,你在解决新的问题的同时,就已经是创新了,书上的东西都是旧的,只有卡着你脖子让你停滞不前的,才是新的,在艰难前进突破关卡的时候,回头看看自己烧脑子写出来的,替你过关斩将的算法和工具,那些都是你的创新成果,是任何一本现有的书籍上都没有的新内容。
- 路还很长,这个时代就是很卷,不努力就会被淘汰,就会在饭局的角落里沉默不语,只能看着多有成绩的同辈们笑谈风声,早点动手,多吃点苦,提高自己的下限,没有什么成功是一蹴而就的,努力吧骚年!
文章出处登录后可见!