目录
- 1. 前提 + 效果图
- 2. 更改步骤
- 2.1 得到PR_curve.csv和F1_curve.csv
- 2.1.1 YOLOv7的更改
- 2.1.1.1 得到PR_curve.csv
- 2.2.1.2 得到F1_curve.csv
- 2.1.2 YOLOv5的更改(v6.1版本)
- 2.1.3 YOLOv8的更改(附训练、验证方式)
- 2.2 绘制PR曲线
1. 前提 + 效果图
-
不错的链接:YOLOV7训练模型分析
-
关于map的绘图或者loss绘图,可参考:【YOLO系列result中的map绘图】根据v5、v8、v7训练后生成的result文件用matplotlib进行绘图
-
v5、v8调用val.py,v7调用test.py(作用都是一样的,都是用已训练好权重对测试集进行验证,然后打印出一系列指标) -
实现效果:就是将运行
val.py/test.py后生成的PR_curve.png中最粗的蓝线整合到同一张图中(注意:本代码最重要的作用是将验证时得到的一系列P、R值给提出来,所以绘图就比较潦草,直接用的matplotlib画的,如果要用于论文中的绘图,一般使用origin)
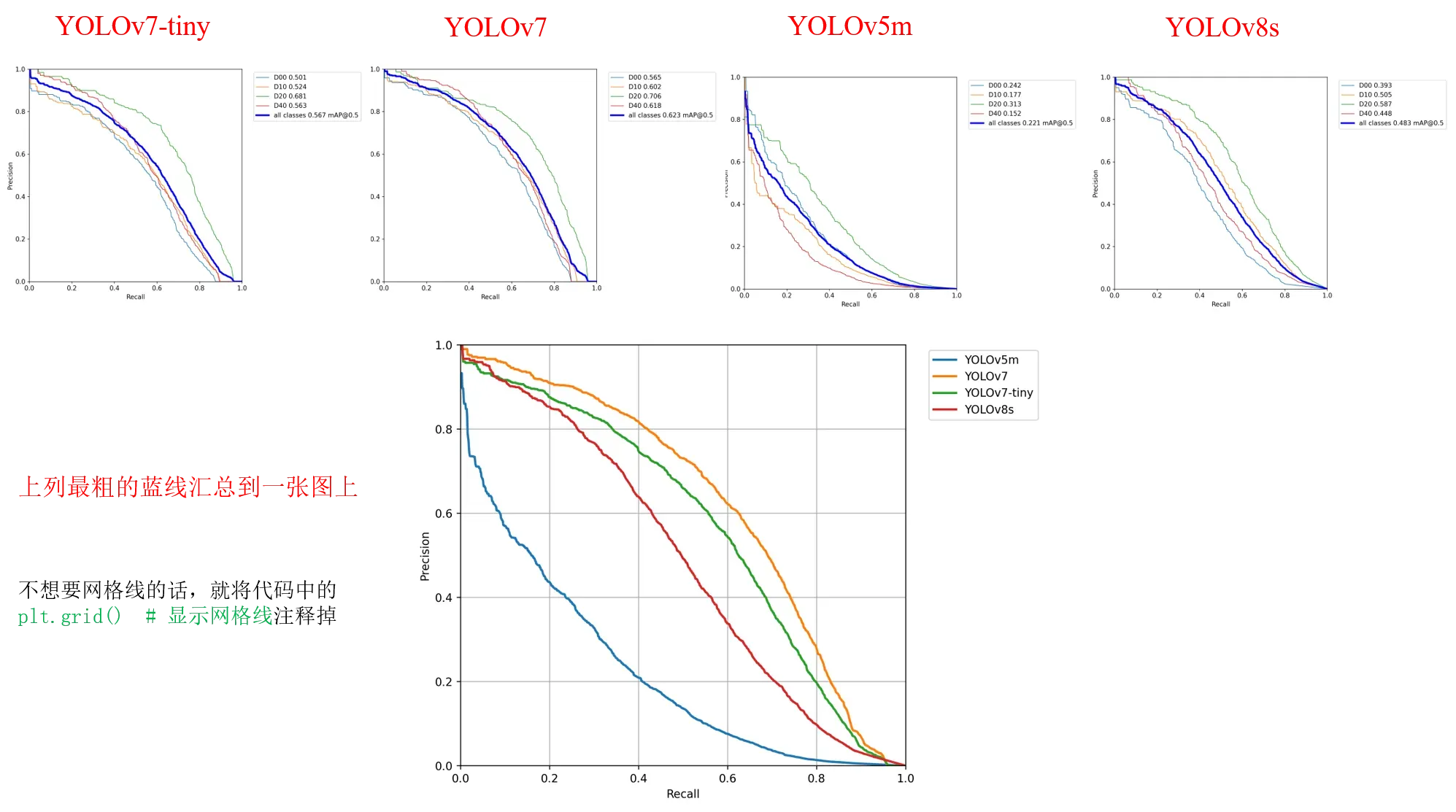
- 同理,可以实现
F1_curve.png绘图
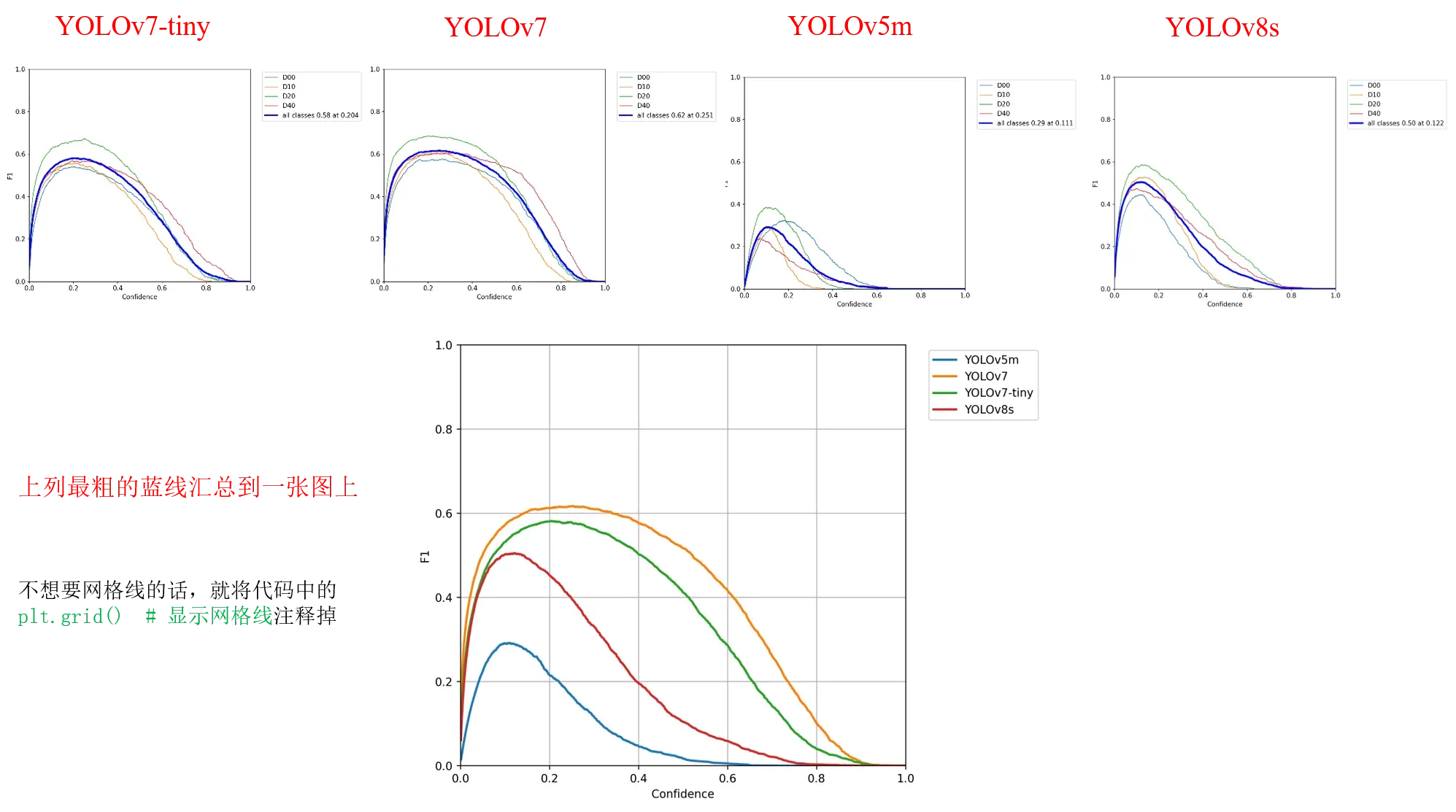
2. 更改步骤
2.1 得到PR_curve.csv和F1_curve.csv
2.1.1 YOLOv7的更改
2.1.1.1 得到PR_curve.csv
在utils/metrics.py中,按住Ctrl+F搜索def plot_pr_curve定位过去,然后如图做更改:
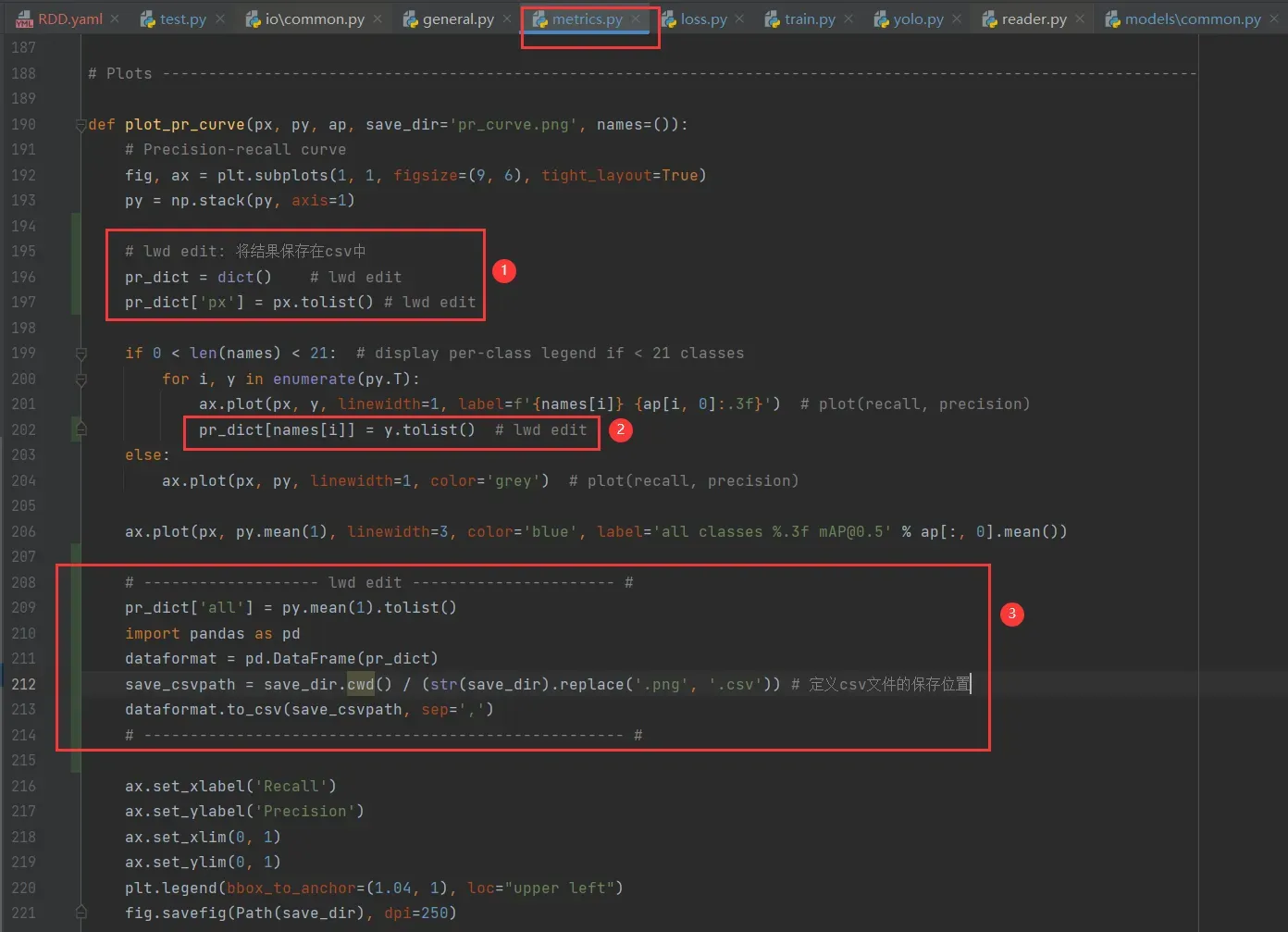
# Plots ----------------------------------------------------------------------------------------------------------------
def plot_pr_curve(px, py, ap, save_dir='pr_curve.png', names=()):
# Precision-recall curve
fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
py = np.stack(py, axis=1)
# lwd edit: 将结果保存在csv中
pr_dict = dict() # lwd edit
pr_dict['px'] = px.tolist() # lwd edit
if 0 < len(names) < 21: # display per-class legend if < 21 classes
for i, y in enumerate(py.T):
ax.plot(px, y, linewidth=1, label=f'{names[i]} {ap[i, 0]:.3f}') # plot(recall, precision)
pr_dict[names[i]] = y.tolist() # lwd edit
else:
ax.plot(px, py, linewidth=1, color='grey') # plot(recall, precision)
ax.plot(px, py.mean(1), linewidth=3, color='blue', label='all classes %.3f mAP@0.5' % ap[:, 0].mean())
# ------------------- lwd edit ---------------------- #
pr_dict['all'] = py.mean(1).tolist()
import pandas as pd
dataformat = pd.DataFrame(pr_dict)
save_csvpath = save_dir.cwd() / (str(save_dir).replace('.png', '.csv')) # 定义csv文件的保存位置
dataformat.to_csv(save_csvpath, sep=',')
# ---------------------------------------------------- #
ax.set_xlabel('Recall')
ax.set_ylabel('Precision')
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
fig.savefig(Path(save_dir), dpi=250)
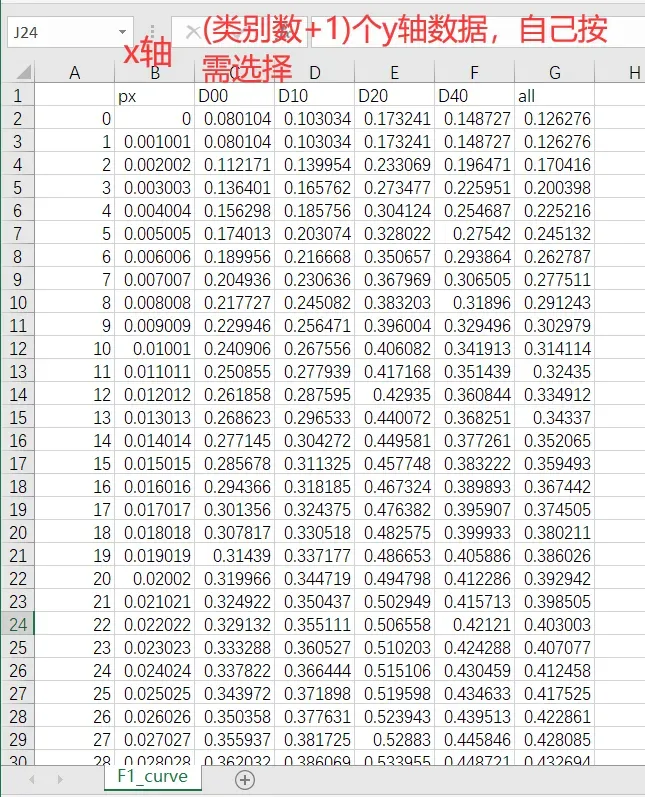
生成的表格数据,共1000行数据:(PR、F1的表格长得差不多,就是数据内容不同,表头相同,行数相同)
2.2.1.2 得到F1_curve.csv
在utils/metrics.py中,按住Ctrl+F搜索def plot_mc_curve定位过去,然后如图做更改:
ps: 因为在utils/metrics.py中的def ap_per_class中会 3 次调用plot_mc_curve,分别绘制F1_curve.png、P_curve.png、R_curve.png,而我只想在F1_curve.png的时候把F1值给提出来,所以我在下图代码中231处进行判断是否是在绘制F1_curve.png,不是的话运行之后就不会生成F1_curve.csv
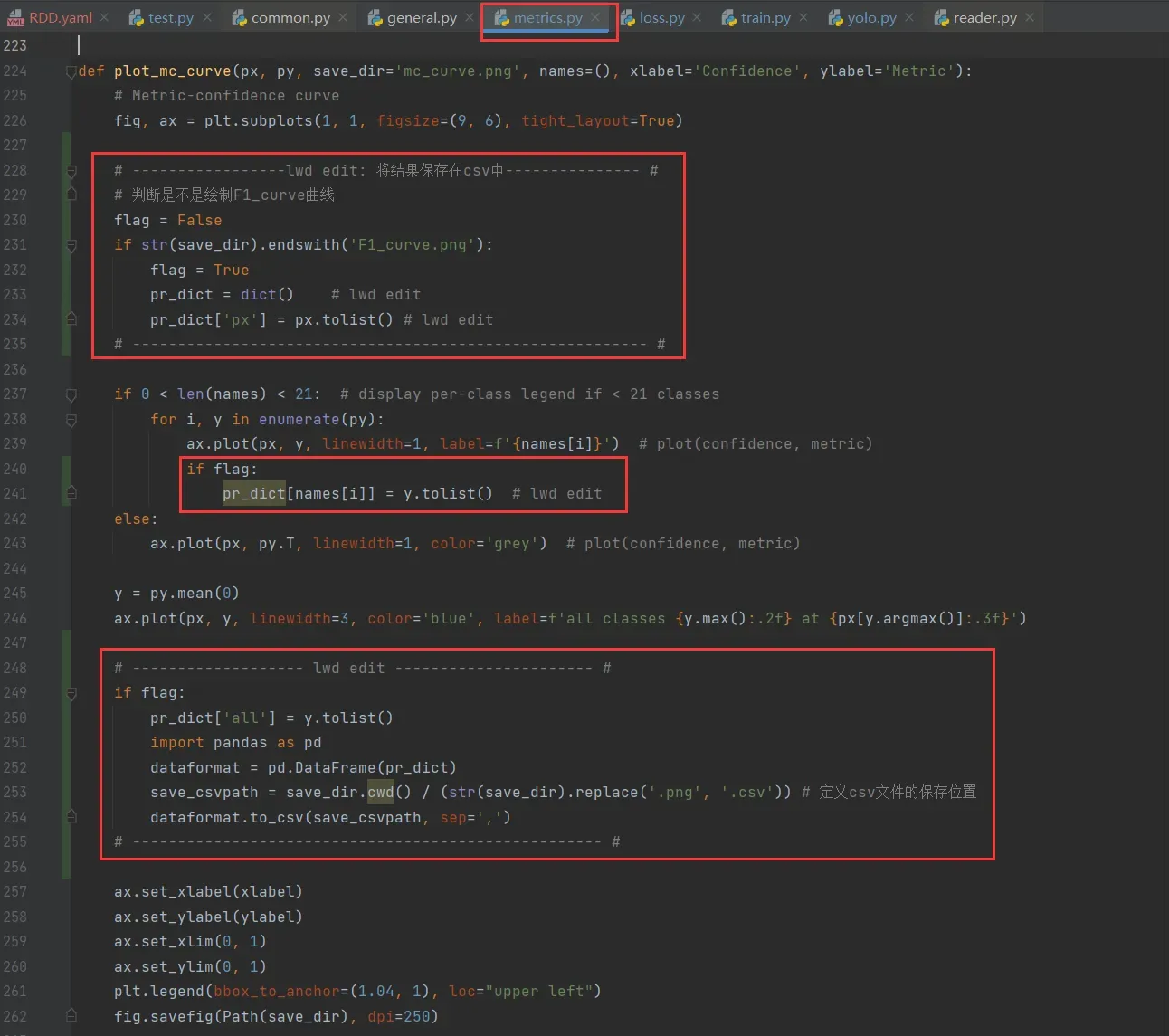
def plot_mc_curve(px, py, save_dir='mc_curve.png', names=(), xlabel='Confidence', ylabel='Metric'):
# Metric-confidence curve
fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
# -----------------lwd edit: 将结果保存在csv中--------------- #
# 判断是不是绘制F1_curve曲线
flag = False
if str(save_dir).endswith('F1_curve.png'):
flag = True
pr_dict = dict() # lwd edit
pr_dict['px'] = px.tolist() # lwd edit
# --------------------------------------------------------- #
if 0 < len(names) < 21: # display per-class legend if < 21 classes
for i, y in enumerate(py):
ax.plot(px, y, linewidth=1, label=f'{names[i]}') # plot(confidence, metric)
if flag:
pr_dict[names[i]] = y.tolist() # lwd edit
else:
ax.plot(px, py.T, linewidth=1, color='grey') # plot(confidence, metric)
y = py.mean(0)
ax.plot(px, y, linewidth=3, color='blue', label=f'all classes {y.max():.2f} at {px[y.argmax()]:.3f}')
# ------------------- lwd edit ---------------------- #
if flag:
pr_dict['all'] = y.tolist()
import pandas as pd
dataformat = pd.DataFrame(pr_dict)
save_csvpath = save_dir.cwd() / (str(save_dir).replace('.png', '.csv')) # 定义csv文件的保存位置
dataformat.to_csv(save_csvpath, sep=',')
# ---------------------------------------------------- #
ax.set_xlabel(xlabel)
ax.set_ylabel(ylabel)
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
fig.savefig(Path(save_dir), dpi=250)
2.1.2 YOLOv5的更改(v6.1版本)
在utils/metrics.py中做与YOLOv7同样的更改
2.1.3 YOLOv8的更改(附训练、验证方式)
在ultralytics-main\ultralytics\yolo\utils\metrics.py中做与YOLOv7同样的更改
❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀ 分割线 ❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀
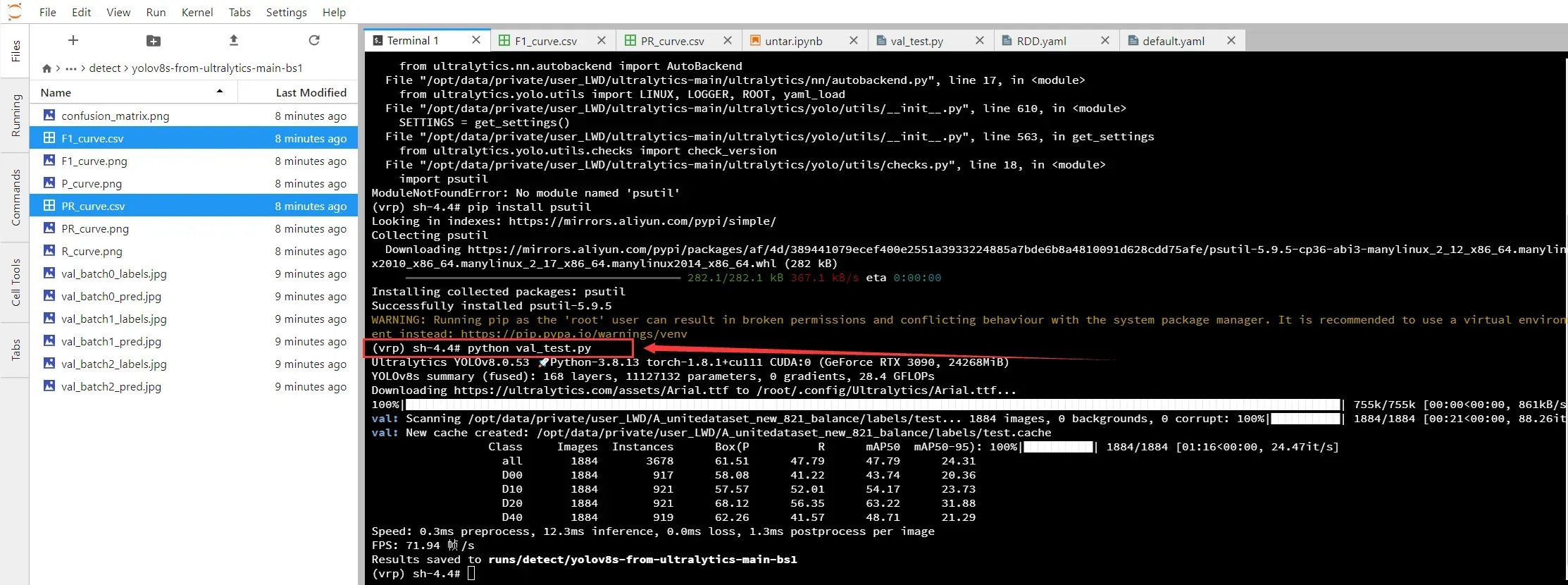
因为有同学说按照这方式,v8中没有生成csv文件,那可以采取一下我的验证方式,看看能不能生成csv文件
- 🍀强烈打call的博客:YoloV8的python启动
- 注意:下面设定的值是对
ultralytics\yolo\cfg\default.yaml中相应参数进行的更改,例如data、imgsz、batch...,还有很多参数可以看文件里面的注释
- 以下是我参考博客并自行设定了一些值的
val_test.py及运行结果
- 验证
测试集的时候,这几个值最好都这么设定:split='test', batch=1, conf=0.001, iou=0.5,因为split='test'表示对测试集test进行验证(默认是对验证集val进行验证),batch=1, conf=0.001, iou=0.5是目标检测中约定俗成的
# 参考博客:https://blog.csdn.net/ljlqwer/article/details/129175087
from ultralytics import YOLO
model = YOLO("/opt/data/private/user_LWD/train_result/yolov8s/yolov8s-best.pt") # 权重地址
results = model.val(data="ultralytics/datasets/RDD.yaml", imgsz=640, split='test', batch=1, conf=0.001, iou=0.5, name='yolov8s-from-ultralytics-main-bs1', optimizer='Adam') # 参数和训练用到的一样
- 暂存一下我训练设置的
train_test.py
from ultralytics import YOLO
# 参考的链接:https://blog.csdn.net/ljlqwer/article/details/129175087
# 这里如果需要预权重就写你的权重文件地址,没有预权重写cfg地址,写一个就够了
# model = YOLO("yolov8n.pt")
model = YOLO("ultralytics/models/v8/yolov8s.yaml")
model.train(data="ultralytics/datasets/RDD.yaml", epochs=300, imgsz=640, batch=32, name='yolov8s-from-ultralytics-main', optimizer='Adam')
2.2 绘制PR曲线
按照2.1得到v7、v5、v8验证后的PR_curve.csv、F1_curve.csv后,在两个函数的csv_dict中指明相应的csv位置,即可运行得到整合图(可见博客最上面的效果图)
import matplotlib.pyplot as plt
import pandas as pd
# 绘制PR
def plot_PR():
csv_dict = {
'YOLOv5m': r'F:\ChromeDown\yolov5-6.1-pruning-autodl\yolov5-6.1-pruning-autodl\runs\val\exp\PR_curve.csv',
'YOLOv7': r'G:\pycharmprojects\yolov7-distillation\runs\test\exp\PR_curve.csv',
'YOLOv7-tiny': r'G:\pycharmprojects\yolov7-distillation\runs\test\exp2\PR_curve.csv',
'YOLOv8s': r'G:\pycharmprojects\ultralytics-main\runs\detect\yolov8s-from-ultralytics-main-bs111\PR_curve.csv',
}
# 绘制pr
fig, ax = plt.subplots(1, 1, figsize=(8, 6), tight_layout=True)
for modelname in pr_csv_dict:
res_path = pr_csv_dict[modelname]
x = pd.read_csv(res_path, usecols=[1]).values.ravel()
data = pd.read_csv(res_path, usecols=[6]).values.ravel()
ax.plot(x, data, label=modelname, linewidth='2')
# 添加x轴和y轴标签
ax.set_xlabel('Recall')
ax.set_ylabel('Precision')
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
plt.legend(bbox_to_anchor=(1.04, 1), loc='upper left')
plt.grid() # 显示网格线
# 显示图像
fig.savefig("pr.png", dpi=250)
plt.show()
# 绘制F1
def plot_F1():
csv_dict = {
'YOLOv5m': r'F:\ChromeDown\yolov5-6.1-pruning-autodl\yolov5-6.1-pruning-autodl\runs\val\exp\F1_curve.csv',
'YOLOv7': r'G:\pycharmprojects\yolov7-distillation\runs\test\exp5\F1_curve.csv',
'YOLOv7-tiny': r'G:\pycharmprojects\yolov7-distillation\runs\test\exp4\F1_curve.csv',
'YOLOv8s': r'G:\pycharmprojects\ultralytics-main\runs\detect\yolov8s-from-ultralytics-main-bs111\F1_curve.csv'
}
fig, ax = plt.subplots(1, 1, figsize=(8, 6), tight_layout=True)
for modelname in pr_csv_dict:
res_path = pr_csv_dict[modelname]
x = pd.read_csv(res_path, usecols=[1]).values.ravel()
data = pd.read_csv(res_path, usecols=[6]).values.ravel()
ax.plot(x, data, label=modelname, linewidth='2')
# 添加x轴和y轴标签
ax.set_xlabel('Confidence')
ax.set_ylabel('F1')
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
plt.legend(bbox_to_anchor=(1.04, 1), loc='upper left')
plt.grid() # 显示网格线
# 显示图像
fig.savefig("F1.png", dpi=250)
plt.show()
if __name__ == '__main__':
plot_PR() # 绘制PR
plot_F1() # 绘制F1
文章出处登录后可见!