
尽管AI的发展取得了巨大进步,但编译器LLVM之父Chris Lattner认为,AI技术应用并不深入,远远没有发挥出已有机器学习研究的所有潜力。而AI系统和工具的单一化和碎片化正是造成这一问题的根源。
为了让AI发挥其真正的潜力,计算碎片化是需要解决的重点问题之一,目标是让AI软件开发人员能够无缝地充分利用现有硬件和下一代创新硬件。但解决这一问题并不容易,硬件、模型和数据的多样性使得当前市场上的现有解决方案都只是单点性质的,Chris Lattner创立的Modular团队从矩阵算法的角度对此进行了深入分析。
(以下内容由OneFlow编译发布,译文转载请联系OneFlow获得授权。https://www.modular.com/blog/ais-compute-fragmentation-what-matrix-multiplication-teaches-us)
作者|Eric Johnson、Abdul Dakkak、Chad Jarvis
OneFlow编译
翻译|徐佳渝、杨婷
1
算力碎片化正在阻碍AI的发展
AI由数据、算法(即模型)和算力驱动,三者之间形成了良性循环。其中任意一方的发展会推动其他方面需求的增长,从而严重影响开发者在可用性和性能等方面的体验。如今,我们拥有更多的数据,做了更多的AI模型研究,但算力的扩展速度却没有跟上,这主要是由于物理限制。
如果你一直在关注AI和硬件的发展,可能听说过摩尔定律时代即将结束。过去60年,单核处理器每18个月翻一倍性能提升速度的情况已然改变。除了继续制造越来越小的晶体管的物理限制之外(例如,电流泄漏会导致功耗过高,从而引起发热),性能也越来越多地受到内存延迟的限制,而这种限制的增长速度比处理速度要缓慢得多。
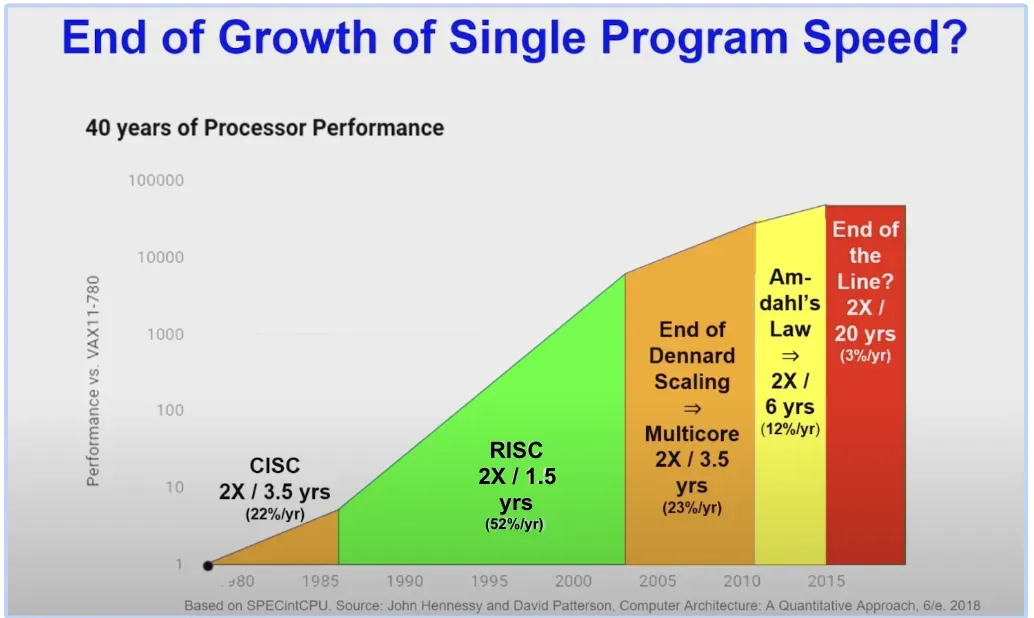
(Hennessy和Patterson的图灵演讲:不同时期CPU处理器性能提升的分析(性能提升的速度保持稳定))
然而,随着模型不断扩大,在边缘计算中创建和处理的企业数据更多,对AI计算的需求也在不断增加。因此,尽可能地利用硬件设备的性能已成为业界的关注焦点。
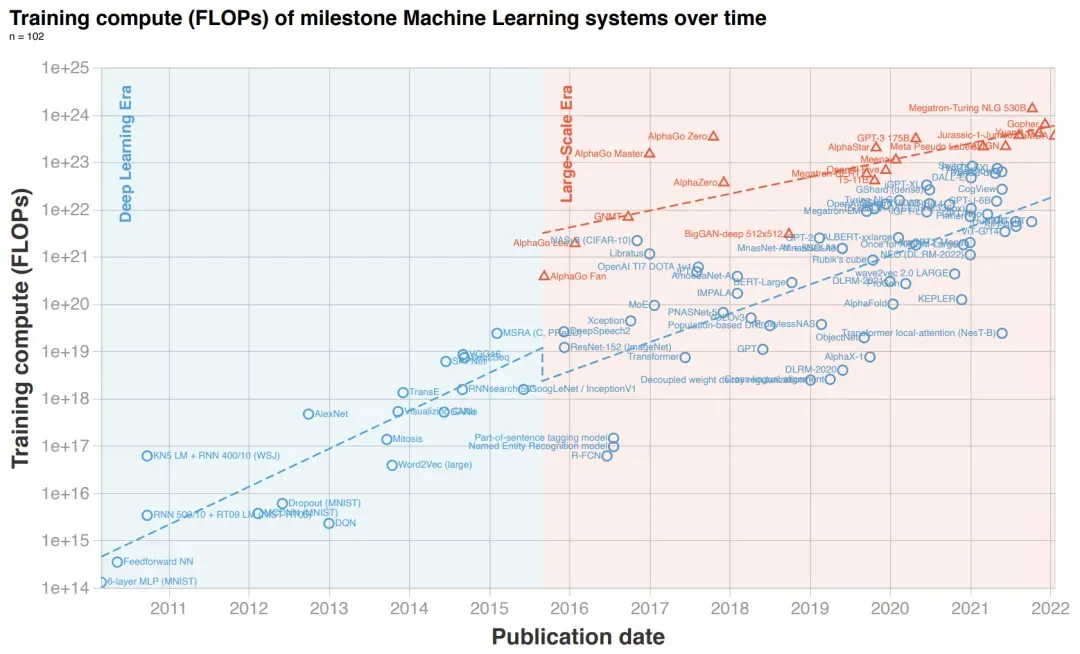
(机器学习三个时代的算力走向(https://arxiv.org/pdf/2202.05924.pdf),Sevilla:计算需求随时间呈对数方式变化的分析。其中,2010年左右深度学习开始受到关注,2016年左右迎来了大型模型时代,这促使了算力需求急剧增长。)
那么,算力的碎片化是如何阻碍AI发展的呢?由于传统CPU无法扩展以满足更多的算力需求,因此,唯一的解决之道是创建并行的、用于特定领域的硬件平台,尽管这些硬件平台的通用性不强,但在特定的AI领域却表现良好——例如图形处理单元(GPU)、张量处理单元(TPU)和其他专用集成电路(ASIC)。
虽然这些创新推动了AI行业的发展,让边缘设备能够使用规模更大、效率更高的处理器,但硬件的多样性使得整个AI行业变得碎片化,AI开发者们需要努力解决以下问题:
1. 开发出能够充分利用硬件能力的软件,且能与其他软件协同工作。
2. 在任意一款设备上实现并行软件算法。
3. 将软件扩展到多设备的生态系统,甚至扩展到异构系统。
Modular公司致力于从零开始重建全球的AI基础设施。在本系列博客中,我们将探讨如何采用全新的方法解决AI行业的算力碎片化问题。我们会专注于单个运算符——矩阵乘法(matrix multiplication,matmul),这是机器学习算法中的关键计算。
通过这种方式,我们会看到构建真正统一的解决方案所面临的底层挑战。我们将深入研究矩阵乘法的内部运作,探讨其工作原理的一些细节,以了解矩阵乘法为什么如此困难。
2
矩阵乘法为何如此困难
矩阵对机器学习系统来说至关重要,因为它提供了一种简单而高效的方式来表示数据。例如,输入数据(图像中的像素集合)或者模型内部不同层之间的运作机制都可以用矩阵来表示。因此,矩阵相乘的运算在深度学习模型总计算量中占据很大比例。
实际上,在许多当前流行的Transformer模型BERT、CLIP以及ChatGPT中,矩阵乘法的运行时长约占其总运行时长的45-60%。矩阵乘法在计算卷积运算中扮演着重要角色,该运算是大多数计算机视觉模型的基础,也是许多高性能计算应用的核心。
考虑到矩阵乘法在机器学习和计算机视觉等领域的重要性,研究人员对其进行了广泛的算法研究,以编写出高效的矩阵乘法算法。自60年代(https://ieeexplore.ieee.org/abstract/document/1687427)、70年代(https://apps.dtic.mil/sti/pdfs/AD0705509.pdf)、80年代
(https://dl.acm.org/doi/10.1145/356012.356020), 90年代(https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.54.9411&rep=rep1&type=pdf)、21世纪初至今(https://netlib.org/lapack/lawnspdf/lawn147.pdf),一直有论文在尝试使用当时的硬件来解决该问题。

简单的O(n^3)矩阵乘法算法。
但是概念上的矩阵乘法并不是难点。相反,挑战在于编写一个足够高效的矩阵乘法,以在AI行业的所有硬件、模型和数据多样性上实现SOTA性能。此外,与其他AI算子的协同工作更具挑战性。
硬件
每种用于运行AI模型的设备都有其独特的特征,例如内存层次结构不同、乘法和累加单元(MAC)不同等等。
例如,CPU采用了这种内存层次结构——从慢速的RAM到越来越快的缓存,包括Level-3、Level-2、Level-1和CPU寄存器。内存大小与速度成反比,例如,L1缓存的访问速度通常为1纳秒量级,而RAM的访问速度为100纳秒量级。
要获得最高性能的矩阵运算,必须让算法有效地处理不同的内存级别和大小。因为原始矩阵太大,所以无法将其一次性放入寄存器或最快的内存缓存中。因此,挑战在于将原始矩阵分解为大小合适的block或tiles,以最大限度地利用最快内存。
此外,处理核心矩阵功能(core matrix functionality)单元的实际形状因硬件而异。就传统意义而言,CPU是一种标量(scalar)机器,这意味着它需要逐个处理指令。然而,在过去二十年中,所有CPU供应商都增加了向量单元(如SIMD),GPU则采用了SIMT(单指令多线程,Single Instruction, Multiple Threads)的方式,以最大限度地提高高度并行、重复运算的效率。
此外,更专业的硬件通过对二维矩阵进行运算来进一步实现这一点。最著名的是Google的TPU,不过苹果和英特尔已经增加了自己的矩阵乘法功能AMX。虽然更先进的MAC单元提高了性能,但也产生了相应的需求,即能够在标量、向量和矩阵处理器上工作的灵活算法。
(深入了解谷歌的第一个张量处理单元:不同乘法和累加(MAC)单元形状。)
模型
AI模型具有多样性。虽然矩阵乘法是许多模型的基础,但它们的矩阵大小可能差异巨大。例如,模型具有不同的输入形状(如不同的序列长度)、不同的内部形状(即作为模型隐藏层一部分的相乘矩阵),以及不同的batch size大小(对于训练和推理效率至关重要)。因此,矩阵乘法在生产中有数百种不同的形状,使得难以将它们分解为不同的block,以实现内存效率最大化。
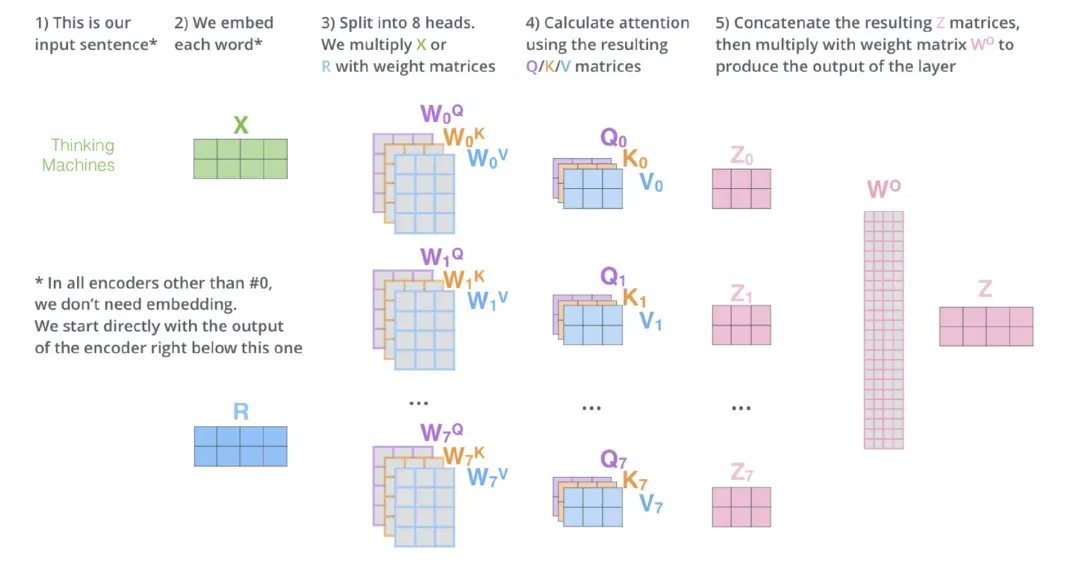
(Transformer图解,Jay Alammar:多头注意力块中涉及的各种矩阵大小,Transformer模型(如BERT, GPT2和CLIP)的关键构建块。)
数据
数据也存在差异。大多数读者可能比较熟悉结构化和非结构化数据方面的差异,但在本文,我们重点关注数据类型(“dtype”)。在AI模型中,数据通常使用dtype FP32,但为了减少模型大小,提高模型性能,业界也接受较低精度的数据类型,如Bfloat16,Int8以及更特殊的FP4和Int4。用例不同,Matmul算法需要运行的数据精度也不同。
量化在AI中的重要性:将FP32量化为Int8。
3
当前的SOTA矩阵乘法算法
那么,目前的SOTA矩阵乘法算法是如何实现的呢?鉴于其重要性,matmul通常是硬件供应商最先优化的算法之一,一般来说,供应商会利用他们的库来实现优化,比如英特尔的MKL和OneDNN
库、AMD的AOCL和RocBLAS、ARM的performance库、Apple的Accelerate、Nvidia的CUBLAS。
就效率而言,在上述提及的硬件库中,当前的SOTA是有效地编写汇编代码:在最低层级向硬件提供直接指令来微观管理硬件,而无需抽象。

面向AVX512,用x86汇编编写的矩阵算法
这样做的主要原因是什么?编写汇编可以实现任意特定用例的最佳性能,通过汇编编写,开发人员可以避免编译器的不可预测性,编译器将Python和C++等高级语言转换为汇编语言,可以执行编译器难以做到的优化,因为编译器必须泛化。更重要的是,它们可以利用编译器未意识到的指令和模式,因为扩展编译器以支持新的硬件功能需要时间。
4
手写汇编kernel无法扩展
那么,汇编能否真正解决用户的碎片问题呢?虽然汇编编写可以最大限度地提高个人用例性能,但它不可移植、组合、扩展且对用户不够友好。少数手工编写和微调汇编代码的专家怎么可能将他们的工作扩展到不同配置,同时整合到所有AI框架中呢?这简直就是不可能完成的任务。

(机器学习编译优化器介绍,Chip Huyen:不断增加的框架和硬件支持组合)
可移植性
汇编是使用特定于硬件的接口(指令集架构ISA)编写的,因此它不能跨硬件移植。事实上,汇编甚至无法在同一硬件供应商的多代芯片上实现最佳性能!
此外,即使我们在开发模型时考虑了目标硬件,也仍然存在两大实际问题:
1. 首先,我们无法在云上控制运行汇编的特定硬件。你可能会说“我选择了一个非常适合自己模型的实例”。但事实是,某些云提供商(如AWS)上的实例不能保证特定的CPU类型。比如,如果你选择了c5.4xlarge实例,那么相应的,你只能使用老一代英特尔SkyLake处理器或新一些的级联湖处理器(Cascade Lake processor)。汇编无法适应运行代码的特定芯片,更无法为其提供最佳性能。
2. 你的产品将继续迅速迭代,你可能希望完全迁移到不同的硬件架构。确定一种特定配置会限制你根据模型需求的变化或新一代硬件进行适应性调整的灵活性。
可扩展性和可组合性
如前所述,AI模型的多样性导致了矩阵形状差异。使用基于汇编的库意味着选择对内存tile大小等参数进行硬编码的特定处理器指令。这些硬编码的汇编库可以针对特定的张量形状进行优化,但需要对其他张量形状进行不同的实现。
因此,许多现有的kernel库膨胀到了千兆字节(例如,MKL为3.2GB,cuDNN最高可达2.5GB)。当这些库的大小影响到容器构建时间时,如果你想部署到不切实际的边缘端,或者想要部署供应商尚未手动优化的新创新和研究时,这将成为一个麻烦。
从整体来看,高性能矩阵乘法对性能确实很重要。但为了获得最佳结果,矩阵乘法运算可以与其他运算一起执行,例如Elementwise、跨步访问(strided accesses)、广播(broadcasts)等。通过减少内存数据流量,算子融合(Operator fusion)带来了显著的性能改进,但问题是有成千上万的AI算子。
此外,模型使用了很多不同运算的排列组合,手动融合所有重要组合是不切实际的(虽然有些人已经尝试过了!),特别是在AI高速发展的情况下。
用户友好性
最后,汇编对于用户来说并不友好,不利于跨组织的生产力。汇编编程在现代编程语言(如参数化和面向对象编程)中可用的功能有限,且不能在调试(debugging)、代码覆盖率(code coverage)、测试(testing)等方面提供有效助益。
虽然大多数想要编写新运算符的研究人员都对Python比较满意,但还是有一些众所周知的性能问题(https://en.wikipedia.org/wiki/Global_interpreter_lock)。为了应对这些问题,组织不得不花高价高薪聘请专家来填补鸿沟。
其他人都在看
欢迎Star、试用OneFlow: github.com/Oneflow-Inc/oneflow/![]() http://github.com/Oneflow-Inc/oneflow/
http://github.com/Oneflow-Inc/oneflow/
文章出处登录后可见!