
1 案例说明(实现MINE正方法的功能)
定义两组具有不同分布的模拟数据,使用神经网络的MINE的方法计算两个数据分布之间的互信息
2 代码编写
2.1 代码实战:准备样本数据
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # 可能是由于是MacOS系统的原因
### 本例实现了用神经网络计算互信息的功能。这是一个简单的例子,目的在于帮助读者更好地理MNE方法。
# 1.1 准备样本数据:定义两个数据生成函数gen_x()、gen_y()。函数gen_x()用于生成1或-1,函数gen_y()在此基础上为其再加上一个符合高斯分布的随机值。
# 生成模拟数据
data_size = 1000
def gen_x():
return np.sign(np.random.normal(0.0,1.0,[data_size,1]))
def gen_y(x):
return x + np.random.normal(0.0,0.5,[data_size,1])
def show_data():
x_sample = gen_x()
y_sample = gen_y(x_sample)
plt.scatter(np.arange(len(x_sample)), x_sample, s=10,c='b',marker='o')
plt.scatter(np.arange(len(y_sample)), y_sample, s=10,c='y',marker='o')
plt.show() # 两条横线部分是样本数据x中的点,其他部分是样本数据y。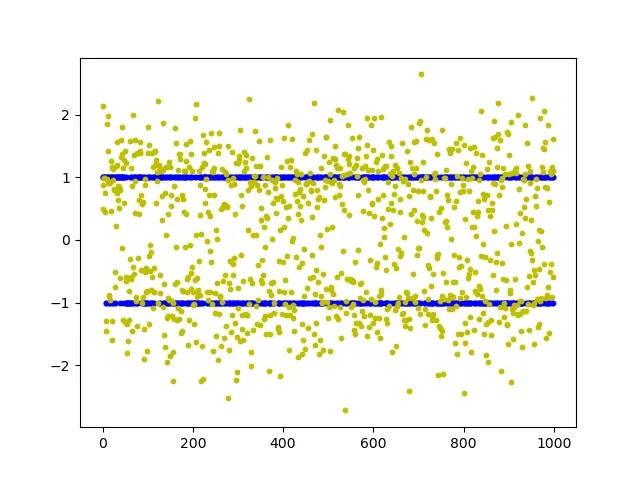
2.2 代码实战:定义神经网络模型
# 1.2 定义神经网络模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(1,10)
self.fc2 = nn.Linear(1,10)
self.fc3 = nn.Linear(10,1)
def forward(self,x,y):
h1 = F.relu(self.fc1(x) + self.fc2(y))
h2 = self.fc3(h1)
return h22.3 代码实战:利用MINE方法训练模型并输出结果
# 1.3 利用MINE方法训练模型并输出结果
if __name__ == '__main__':
show_data()# 显示数据
model = Net() # 实例化模型
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # 使用Adam优化器并设置学习率为0.01
n_epoch = 500
plot_loss = []
# MiNE方法主要用于模型的训练阶段
for epoch in tqdm(range(n_epoch)):
x_sample = gen_x() # 调用gen_x()函数生成样本x_Sample。X_sample代表X的边缘分布P(X)
y_sample = gen_y(x_sample) # 将生成的×_sample样本放到gen_x()函数中,生成样本y_sample。y_sample代表条件分布P(Y|X)。
y_shuffle = np.random.permutation(y_sample) # )将 y_sample按照批次维度打乱顺序得到y_shuffle,y_shuffle是Y的经验分布,近似于Y的边缘分布P(Y)。
# 转化为张量
x_sample = torch.from_numpy(x_sample).type(torch.FloatTensor)
y_sample = torch.from_numpy(y_sample).type(torch.FloatTensor)
y_shuffle = torch.from_numpy(y_shuffle).type(torch.FloatTensor)
model.zero_grad()
pred_xy = model(x_sample, y_sample) # 式(8-49)中的第一项联合分布的期望:将x_sample和y_sample放到模型中,得到联合概率(P(X,Y)=P(Y|X)P(X))关于神经网络的期望值pred_xy。
pred_x_y = model(x_sample, y_shuffle) # 式(8-49)中的第二项边缘分布的期望:将x_sample和y_shuffle放到模型中,得到边缘概率关于神经网络的期望值pred_x_y 。
ret = torch.mean(pred_xy) - torch.log(torch.mean(torch.exp(pred_x_y))) # 将pred_xy和pred_x_y代入式(8-49)中,得到互信息ret。
loss = - ret # 最大化互信息:在训练过程中,因为需要将模型权重向着互信息最大的方向优化,所以对互信息取反,得到最终的loss值。
plot_loss.append(loss.data) # 收集损失值
loss.backward() # 反向传播:在得到loss值之后,便可以进行反向传播并调用优化器进行模型优化。
optimizer.step() # 调用优化器
plot_y = np.array(plot_loss).reshape(-1, ) # 可视化
plt.plot(np.arange(len(plot_loss)), -plot_y, 'r') # 直接将|oss值取反,得到最大化互信息的值。
plt.show()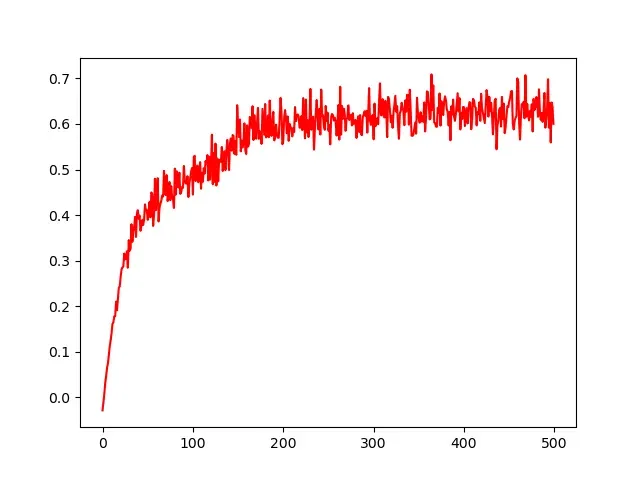
3 代码总览
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # 可能是由于是MacOS系统的原因
### 本例实现了用神经网络计算互信息的功能。这是一个简单的例子,目的在于帮助读者更好地理MNE方法。
# 1.1 准备样本数据:定义两个数据生成函数gen_x()、gen_y()。函数gen_x()用于生成1或-1,函数gen_y()在此基础上为其再加上一个符合高斯分布的随机值。
# 生成模拟数据
data_size = 1000
def gen_x():
return np.sign(np.random.normal(0.0,1.0,[data_size,1]))
def gen_y(x):
return x + np.random.normal(0.0,0.5,[data_size,1])
def show_data():
x_sample = gen_x()
y_sample = gen_y(x_sample)
plt.scatter(np.arange(len(x_sample)), x_sample, s=10,c='b',marker='o')
plt.scatter(np.arange(len(y_sample)), y_sample, s=10,c='y',marker='o')
plt.show() # 两条横线部分是样本数据x中的点,其他部分是样本数据y。
# 1.2 定义神经网络模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(1,10)
self.fc2 = nn.Linear(1,10)
self.fc3 = nn.Linear(10,1)
def forward(self,x,y):
h1 = F.relu(self.fc1(x) + self.fc2(y))
h2 = self.fc3(h1)
return h2
# 1.3 利用MINE方法训练模型并输出结果
if __name__ == '__main__':
show_data()# 显示数据
model = Net() # 实例化模型
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # 使用Adam优化器并设置学习率为0.01
n_epoch = 500
plot_loss = []
# MiNE方法主要用于模型的训练阶段
for epoch in tqdm(range(n_epoch)):
x_sample = gen_x() # 调用gen_x()函数生成样本x_Sample。X_sample代表X的边缘分布P(X)
y_sample = gen_y(x_sample) # 将生成的×_sample样本放到gen_x()函数中,生成样本y_sample。y_sample代表条件分布P(Y|X)。
y_shuffle = np.random.permutation(y_sample) # )将 y_sample按照批次维度打乱顺序得到y_shuffle,y_shuffle是Y的经验分布,近似于Y的边缘分布P(Y)。
# 转化为张量
x_sample = torch.from_numpy(x_sample).type(torch.FloatTensor)
y_sample = torch.from_numpy(y_sample).type(torch.FloatTensor)
y_shuffle = torch.from_numpy(y_shuffle).type(torch.FloatTensor)
model.zero_grad()
pred_xy = model(x_sample, y_sample) # 式(8-49)中的第一项联合分布的期望:将x_sample和y_sample放到模型中,得到联合概率(P(X,Y)=P(Y|X)P(X))关于神经网络的期望值pred_xy。
pred_x_y = model(x_sample, y_shuffle) # 式(8-49)中的第二项边缘分布的期望:将x_sample和y_shuffle放到模型中,得到边缘概率关于神经网络的期望值pred_x_y 。
ret = torch.mean(pred_xy) - torch.log(torch.mean(torch.exp(pred_x_y))) # 将pred_xy和pred_x_y代入式(8-49)中,得到互信息ret。
loss = - ret # 最大化互信息:在训练过程中,因为需要将模型权重向着互信息最大的方向优化,所以对互信息取反,得到最终的loss值。
plot_loss.append(loss.data) # 收集损失值
loss.backward() # 反向传播:在得到loss值之后,便可以进行反向传播并调用优化器进行模型优化。
optimizer.step() # 调用优化器
plot_y = np.array(plot_loss).reshape(-1, ) # 可视化
plt.plot(np.arange(len(plot_loss)), -plot_y, 'r') # 直接将|oss值取反,得到最大化互信息的值。
plt.show()
文章出处登录后可见!
已经登录?立即刷新