如何标注多词实体?
nlp 460
原文标题 :How to label multi-word entities?
我对数据分析(以及一般的 Python)还很陌生,我目前有点卡在我的项目中。
对于我的 NLP 任务,我需要创建训练数据,即。在句子中查找特定实体并标记它们。我有多个包含我要查找的实体的 csv 文件,其中许多由多个单词组成。我已经标记化和词形化将未标记的句子用 spaCy 加载到 apandas.DataFrame。
我的主要问题是:我现在如何将标记化的句子与实体列表进行比较并标记(通常是多词)实体?有大约 0.5 GB 的句子,我认为只循环每个句子然后循环每个类列表中的每个实体并进行简单的子字符串搜索是不可行的。有什么聪明的方法来使用 pandas .Series 或 DataFrame 来做这个标签?
如前所述,我对 pandas/numpy 等并没有任何经验,经过大量网络搜索后,我似乎仍然没有找到问题的答案
假设这是一个 Finance.csv 样本,我的实体列表之一:
"Frontwave Credit Union",
"St. Mary's Bank",
"Center for Financial Services Innovation",
...
这是 sport.csv 的一个样本,我的另一个实体列表:
"Christiano Ronaldo",
"Lewis Hamilton",
...
还有一个例子(愚蠢的)句子:
"Dear members of Frontwave Credit Union, any credit demanded by Lewis Hamilton is invalid, said Ronaldo"
我想要的结果类似于带有匹配实体标签(带有 IOB 标签)的令牌表:
"Dear "- O
"members" - O
"of" - O
"Frontwave" - B-FINANCE
"Credit" - I-FINANCE
"Union" - I-FINANCE
"," - O
"any" - O
...
"Lewis" - B-SPORT
"Hamilton" - I-SPORT
...
"said" - O
"Ronaldo" - O
回复
我来回复-
 keramat 评论
keramat 评论采用:
FINANCE = ["Frontwave Credit Union", "St. Mary's Bank", "Center for Financial Services Innovation"] SPORT = [ "Christiano Ronaldo", "Lewis Hamilton", ] FINANCE = '|'.join(FINANCE) sent = pd.DataFrame({'sent': ["Dear members of Frontwave Credit Union, any credit demanded by Lewis Hamilton is invalid, said Ronaldo"]}) home = sent['sent'].str.extractall(f'({FINANCE})') def labeler(row, group): l = len(row.split()) return [f'I-{group}' if i !=0 else f'B-{group}' for i in range(l)] home[0].apply(labeler, group='FINANCE').explode()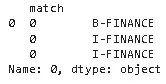 2年前
2年前