使用 BeautifulSoup 进行网页抓取,在 html 中找不到表格
python 543
原文标题 :Webscraping with BeautifulSoup, can’t find table within html
我正在尝试从该站点抓取主表:https://www.atptour.com/en/stats/leaderboard?boardType=serve&timeFrame=52Week&surface=all&versusRank=all&formerNo1=false这是我的代码:
import requests
from bs4 import BeautifulSoup, Comment
import pandas as pd
url = "https://www.atptour.com/en/stats/leaderboard?boardType=serve&timeFrame=52Week&surface=all&versusRank=all&formerNo1=false"
request = requests.get(url).text
soup = BeautifulSoup(request, 'lxml')
divs = soup.findAll('tbody', id = 'leaderboardTable')
print(divs)
然而,这是这个的唯一输出:
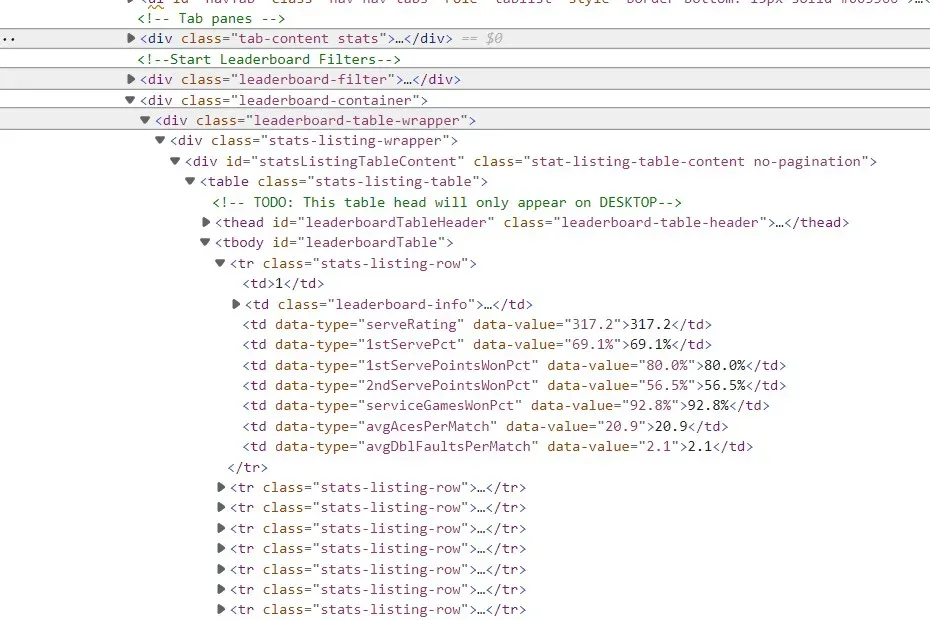
如何访问 html 的其余部分?当我搜索汤时,它似乎不在那里。我还附上了我要访问的 html 的图像。任何帮助表示赞赏。谢谢!
回复
我来回复-
 Jessica 评论
Jessica 评论您的代码按预期工作。您正在解析的 HTML 表下没有任何数据。
$ wget https://www.atptour.com/en/stats/leaderboard\?boardType\=serve\&timeFrame\=52Week\&surface\=all\&versusRank\=all\&formerNo1\=false -O page.html $ grep -C 3 'leaderboardTable' page.html class="stat-listing-table-content no-pagination"> <table class="stats-listing-table"> <!-- TODO: This table head will only appear on DESKTOP--> <thead id="leaderboardTableHeader" class="leaderboard-table-header"> </thead> <tbody id="leaderboardTable"></tbody> </table> </div>您已经显示了包含数据的开发人员视图的屏幕截图。我猜想有一个 Javascript 在加载并放入行后修改 HTML。您的浏览器能够运行此 Javascript,因此您会看到这些行。
requests当然不运行任何脚本,它只下载 HTML。您可以在浏览器中“另存为”以获取重新使用的 HTML,或者您将不得不使用更高级的 Web 模块,例如可以运行脚本的 Selenium。
2年前