PyTorch 数据集变换归一化 nb_samples += batch_samples IndexError: Dimension out of range (expected to be in range of [-2, 1], but got 2)
pytorch 324
原文标题 :PyTorch dataset transform normalization nb_samples += batch_samples IndexError: Dimension out of range (expected to be in range of [-2, 1], but got 2)
目标:找到用于transforms.Normalize部分data_transforms的均值和标准张量
疑问:我们是否需要为每个训练集、验证集和测试集设置三个不同的均值和标准张量?
错误:不确定如何将 PyTorch 论坛中的代码应用到我的数据加载器。下面是错误和代码。
我有一些不是自然图像的图像,我计划使用 Inception V3 预训练的 ImageNet 进行微调。
我有这个来自 PyTorch 培训和 Piotr 的代码的代码(稍作修改/添加)。但是,我收到一个错误:
# Create training and validation datasets
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'val', 'test']}
# Create training and validation dataloaders
print('batch size: ', batch_size)
dataloaders_dict = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True, num_workers=4) for x in ['train', 'val', 'test']}
mean = 0.
std = 0.
nb_samples = 0.
for data in dataloaders_dict['train']:
print(print(len(data)))
print("data[0] shape: ", data[0].shape)
batch_samples = data[0].size(0)
data = data[0].view(batch_samples, data[0].size(1), -1)
mean += data[0].mean(2).sum(0)
std += data[0].std(2).sum(0)
nb_samples += batch_samples
mean /= nb_samples
std /= nb_samples
我假设,我也需要为dataloaders_dict['val']和dataloaders_dict['test']使用与上面类似的代码。如果我错了,请纠正我。无论如何,错误是:
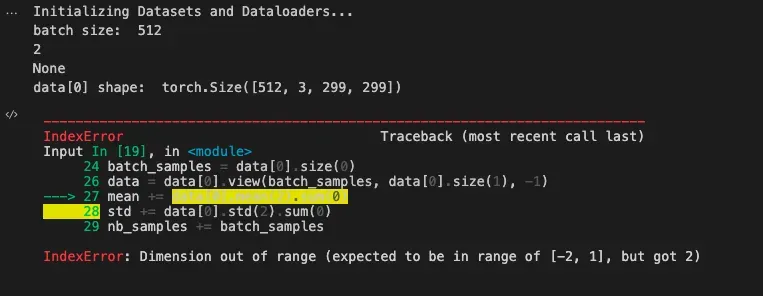
batch size: 512
2
None
data[0] shape: torch.Size([512, 3, 299, 299])
IndexError Traceback (most recent call last) Input In [19], in <module> **24** batch_samples = data[0].size(0) **26** data = data[0].view(batch_samples, data[0].size(1), -1) ---> 27 mean += data[0].mean(2).sum(0) **28** std += data[0].std(2).sum(0) **29** nb_samples += batch_samples IndexError: Dimension out of range (expected to be in range of [-2, 1], but got 2)
目前,我已经评论了数据转换的“标准化”部分,并将其仅用于调整大小。如果我们的初始目标是计算均值和标准张量,我不确定数据转换应该是什么样子。请让我知道是否有误。
input_size = 299 # for Inception V3
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(input_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
#transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(input_size),
transforms.CenterCrop(input_size),
transforms.ToTensor(),
#transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'test': transforms.Compose([
transforms.Resize(input_size),
transforms.CenterCrop(input_size),
transforms.ToTensor(),
#transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
}
回复
我来回复-
 Mona Jalal 评论
Mona Jalal 评论def get_mean_std(loader): # VAR[X] = E[X**2] - E[X]**2 channels_sum, channels_squared_sum, num_batches = 0, 0, 0 for data, _ in loader: channels_sum += torch.mean(data, dim=[0,2,3]) channels_squared_sum += torch.mean(data**2, dim=[0,2,3]) num_batches += 1 mean = channels_sum/num_batches std = (channels_squared_sum/num_batches - mean**2)**0.5 return mean, stdtrain_mean, train_std = get_mean_std(dataloaders_dict['train']) print(train_mean, train_std)张量([0.7031, 0.5487, 0.6750]) 张量([0.2115, 0.2581, 0.1952])
test_mean, test_std = get_mean_std(dataloaders_dict['test']) print(test_mean, test_std)张量([0.7048, 0.5509, 0.6763]) 张量([0.2111, 0.2576, 0.1979])
val_mean, val_std = get_mean_std(dataloaders_dict['val']) print(val_mean, val_std)张量([0.7016, 0.5549, 0.6784]) 张量([0.2099, 0.2583, 0.1998])
取自此 YouTube 教程
2年前