将python中的无序数据更改为有序数据框
python 206
原文标题 :change unordered data in python as ordered dataframe
我已经给出了以下格式的txt文件
a: 40 b: 20 c: 20 d: 00 23 4f 40 5f
a: 20 b: 30 c: 50 d: 23 45 21 54 43
a: 20 b: 30 c: 50 d: 23 45 21
a: 20 b: 30 c: 50 d:
我使用 read_csv() 函数来读取 Fiven 文件。但是,我正在努力将这种格式作为数据框进行分析。
我想要的最终数据框是
a b c d_1 d_2 d_3 d_4 d_5
40 20 20 00 23 4f 40 5f
20 30 50 23 45 21 54 43
20 30 50 23 45 21
20 30 50
我尝试使用”作为除数的拆分功能。但是,由于存在未写入的数据,因此会导致混乱。
有没有另一种方法可以将这种类型的数据作为数据框。
回复
我来回复-
 Kong Vungsovanreach 评论
Kong Vungsovanreach 评论如果您尝试找到一种使用 read_csv() 加载它的方法,可能会很困难。我认为在将数据加载到数据框之前清理数据会更好。
def check_index(list, index): return "" if index > (len(list)-1) else list[index].rstrip() a, b, c, d1 ,d2, d3, d4, d5 = [] , [] ,[] , [],[] , [] ,[] , [] with open('./text.txt') as file: for line in file.readlines(): values = list(compo.split(': ')[1] for compo in line.split(' ')) # 4 space split according to your sample data a.append(values[0]) b.append(values[1]) c.append(values[2]) d_values = values[3].split(' ') d1.append(check_index(d_values,0)) d2.append(check_index(d_values,1)) d3.append(check_index(d_values,2)) d4.append(check_index(d_values,3)) d5.append(check_index(d_values,4)) df = pd.DataFrame(list(zip(a, b, c, d1 ,d2, d3, d4, d5)), columns = ['a', 'b', 'c', 'd1', 'd2', 'd3', 'd4', 'd5'])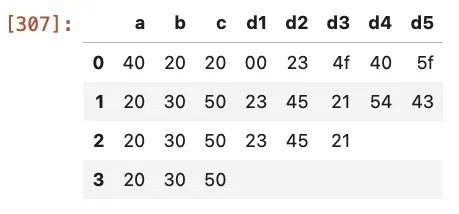 2年前
2年前