从熊猫多索引数据透视表中的时间序列计算值
python 205
原文标题 :Calculating values from time series in pandas multi-indexed pivot tables
我在 pandas 中有一个数据框,其中存储了一个人的 ID、交互的质量和交互的日期。一个人可以跨多个日期进行多次交互,因此为了帮助可视化和绘制它,我将其转换为数据透视表,首先按 Id 分组,然后按日期分组以分析随时间变化的模式。
e.g.
import pandas as pd
df = pd.DataFrame({'Id':['A4G8','A4G8','A4G8','P9N3','P9N3','P9N3','P9N3','C7R5','L4U7'],
'Date':['2016-1-1','2016-1-15','2016-1-30','2017-2-12','2017-2-28','2017-3-10','2019-1-1','2018-6-1','2019-8-6'],
'Quality':[2,3,6,1,5,10,10,2,2]})
pt = df.pivot_table(values='Quality', index=['Id','Date'])
print(pt)
导致:
| Id | Date | Quality |
|---|---|---|
| A4G8 | 2016-1-1 | 2 |
| 2016-1-15 | 4 | |
| 2016-1-30 | 6 | |
| P9N3 | 2017-2-12 | 1 |
| 2017-2-28 | 5 | |
| 2017-3-10 | 10 | |
| 2019-1-1 | 10 | |
| C7R5 | 2018-6-1 | 2 |
| L4U7 | 2019-8-6 | 2 |
不过,我也想…
- 测量每个 Id 每次交互的第一次交互的时间
- 测量上一次使用相同 ID 交互的时间
所以我会得到一张类似于下面的表格
| Id | Date | Quality | Time From First | Time To Prev |
|---|---|---|---|---|
| A4G8 | 2016-1-1 | 2 | 0 days | NA days |
| 2016-1-15 | 4 | 14 days | 14 days | |
| 2016-1-30 | 6 | 29 days | 14 days | |
| P9N3 | 2017-2-12 | 1 | 0 days | NA days |
| 2017-2-28 | 5 | 15 days | 15 days | |
| 2017-3-10 | 10 | 24 days | 9 days |
Id 列是字符串类型,我将日期列转换为日期时间,将质量列转换为整数。
该列相当大(> 10,000个唯一ID),因此出于性能原因,我试图避免使用for循环。我猜该解决方案以某种方式使用pd.eval,但我不知道如何正确应用它。
抱歉,我是 python、pandas 和堆栈溢出)noob,我还没有在任何地方找到答案,所以即使是一些关于在哪里寻找的指针也会很棒:-)。非常感谢提前
回复
我来回复-
 jezrael 评论
jezrael 评论将
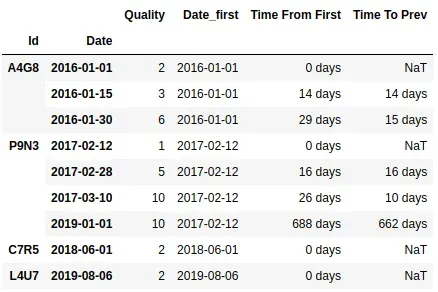
Dates 转换为日期时间,然后将每组的最小日期时间减去GroupBy.transformb 减去列Date,然后使用第二个新列DataFrameGroupBy.diff:df['Date'] = pd.to_datetime(df['Date']) df['Time From First'] = df['Date'].sub(df.groupby('Id')['Date'].transform('min')) df['Time To Prev'] = df.groupby('Id')['Date'].diff() print (df) Id Date Quality Time From First Time To Prev 0 A4G8 2016-01-01 2 0 days NaT 1 A4G8 2016-01-15 3 14 days 14 days 2 A4G8 2016-01-30 6 29 days 15 days 3 P9N3 2017-02-12 1 0 days NaT 4 P9N3 2017-02-28 5 16 days 16 days 5 P9N3 2017-03-10 10 26 days 10 days 6 P9N3 2019-01-01 10 688 days 662 days 7 C7R5 2018-06-01 2 0 days NaT 8 L4U7 2019-08-06 2 0 days NaT2年前 -
Salvatore Daniele Bianco 评论
df["Date"] = pd.to_datetime(df.Date) df = df.merge( df.groupby(["Id"]).Date.first(), on="Id", how="left", suffixes=["", "_first"] ) df["Time From First"] = df.Date-df.Date_first df['Time To Prev'] = df.groupby('Id').Date.diff() df.set_index(["Id", "Date"], inplace=True) df输出:
 2年前
2年前