论文:Let Imbalance Have Nowhere to Hide Class-Sensitive Feature Extraction for Imbalanced Traffic Classification
摘要:本文提出了一个新的框架,该框架使用深度学习来进行特征提取,以解决NTC(network traffic classification)任务中的不平衡问题,名为DeepFE。模型的关键在于使用改进的ResNet和SE block 提取类敏感信息,并使用non-local对特征进行重构。内容
- 介绍
- 方法
- A. 流量向量化
- B. 类敏感特征学习 🌼
- C. 特征重建
- D. 分类
- 实验
- 数据集
- 性能指标
- DeepFE设置
- 实验结果
- 综上所述

介绍
贡献:
- 提出了一种端到端的非平衡流量分类模型DeepFE。DeepFE提供了从不平衡流量中学习类敏感特征的能力,以有针对性的方式提高了每个类的性能,并且对不同任务的不同初始特征具有鲁棒性。
- 类别敏感的特征学习旨在从通道层学习特征,同时通过深度网络提取有效的表示。通过显式建模特征通道之间的相互依赖关系,自动学习每个特征通道的重要性,并获得每个类别最合适的特征表示。
- 对两个真实流量数据集的综合实验表明,我们的方法可以显着改善由不平衡引起的性能下降,并且优于几种最先进的方法。
方法
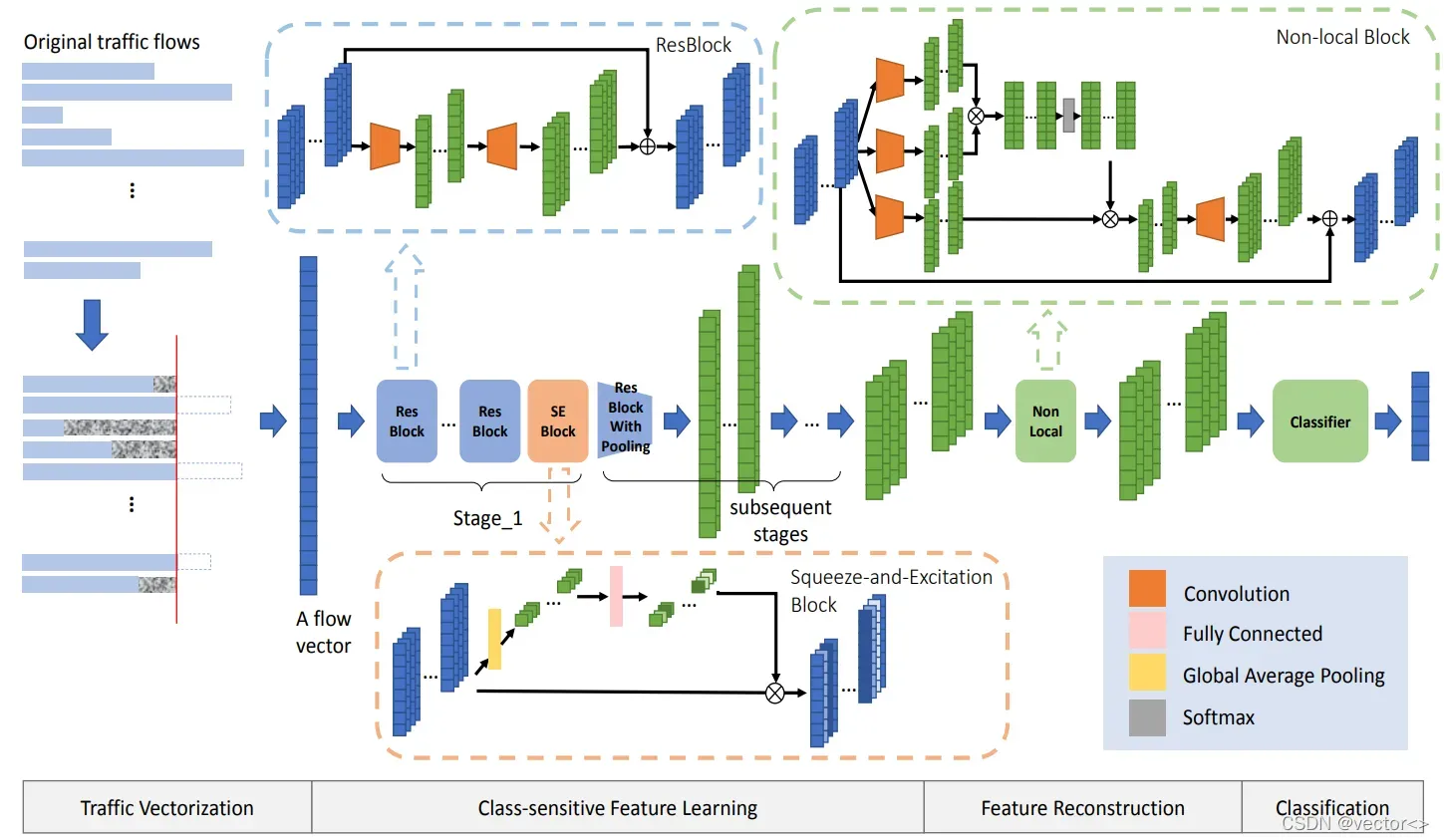
A. 流量向量化
- 在非平衡NTC任务中,流是指具有相同5元组(源IP、目标IP、源端口、目标端口和传输层协议)的数据包的集合。
- 首先,执行数据清理以去除一些错误的流,例如不断重传的流,只有握手而没有实质性通信包的流等。
- 之后,剩余的N个流被用作训练集,需要进行向量化。
- 输入向量的长度设置为L,超过L的部分将被截断,不足的部分将用0填充。每个流将以这种方式表示为长度为L的向量。
- 经过向量化之后,
,1xW表示空间维度,X1表示通道数。
B. 类敏感特征学习 🌼
- 该模块的设计参考了 ResNet 的结构,由初始卷积层和四个subsequent stage组成。在这里,stage表示特征映射上操作的块集合。
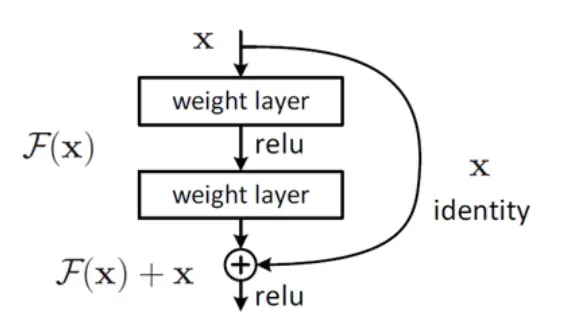
- ResNet提出了拟合残差映射的思想,而不是直接拟合期望的底层映射,使网络更好地收敛。
- ResNet使用”shortcut connections” 避免梯度消失/爆炸,同时解决网络深度过深导致的精度下降问题。
🍓在学习本论文提出的模型之前,需要先了解一下ResNet
- 深度网络的退化问题
网络深度增加时,网络准确度出现饱和,甚至出现下降。56层的网络比20层网络效果还要差。这不会是过拟合问题,因为56层网络的训练误差同样高。我们知道深层网络存在着梯度消失或者爆炸的问题,这使得深度学习模型很难训练。但是现在已经存在一些技术手段如BatchNorm来缓解这个问题。因此,出现深度网络的退化问题是非常令人诧异的。- 残差学习
ResNet通过残差学习解决了深度网络的退化问题,让我们可以训练出更深的网络。下图是残差学习的单元,是残差函数,拟合目标是使
参考:
https://www.zhihu.com/question/38499534
https://zhuanlan.zhihu.com/p/31852747
这篇论文的模型在原ResNet的基础上做了一些改进:
- 初始卷积操作不会对 stride 或 pooling进行采样操作,只增加通道数。空间维度的特征尺寸保持不变。
- 然后,在 Stage 1 中不执行采样操作,subsequent stages中,在第一个ResBlock中使用 stride-1 卷积和stride-2 max pooling 。
- 此外,我们在每个阶段的末尾添加了一个 squeeze-and-excitation SE 块。ResBlock通过捕捉特征之间的空间相关性来增强表示,而SE Block则从通道的角度来提高表示的质量
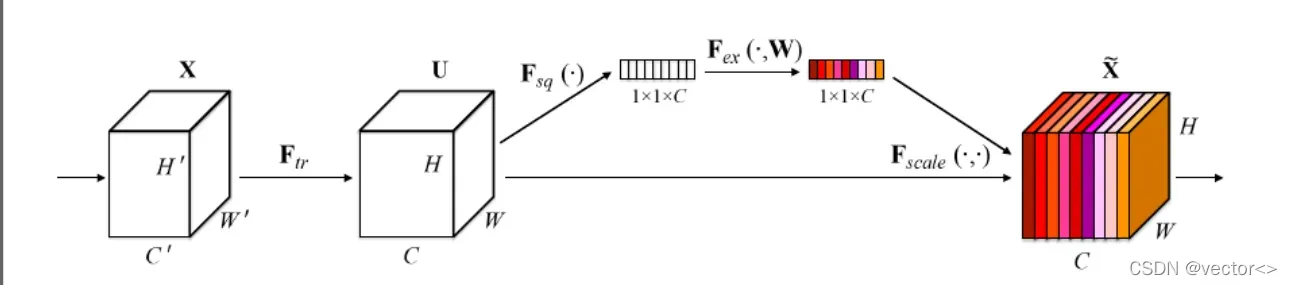
🍓 此处需要对squeeze-and-excitation (SE)进行一个补充学习
- SENet的提出动机非常简单,传统的方法是将网络的Feature Map等权地传到下一层,SENet的核心思想在于建模通道之间的相互依赖关系,通过网络的全局损失函数自适应的重新矫正通道之间的特征相应强度。
- SENet由一些列SE block组成,一个SE block的过程分为Squeeze(压缩)和Excitation(激发)两个步骤。其中Squeeze通过在Feature Map层上执行Global Average Pooling得到当前Feature Map的全局压缩特征向量,Excitation通过两层全连接得到Feature Map中每个通道的权值,并将加权后的Feature Map作为下一层网络的输入。从上面的分析中我们可以看出SE block只依赖与当前的一组Feature Map,因此可以非常容易的嵌入到几乎现在所有的卷积网络中。
C. 特征重建
- 在前面的模块中,对每个类具有不同敏感性的特征表示是从通道级别学习的。在这一部分中,从空间角度进一步增强了这些特征。
- 使用 non-local(一种注意机制)通过捕获任意两个位置之间的远程依赖关系来维护更多信息。通过将某个位置的响应计算为输入特征图中所有位置的特征的加权和。
- non-local 块可以融合不同位置的特征,增强特征表示。
- 该模块有助于进一步挖掘流量中潜在的有效信息,提高表示的鲁棒性。
🍓 non-local
- non-local block旨在从其他位置聚集信息来增强当前位置的特征。回想一下我们熟悉的CNN,RNN,这些神经网络模型都是基于局部区域进行操作,属于local operations。为了获得长距离依赖,也就是图像中非相邻像素点之间的关系,提出利用non-local operations构建non-local 神经网络。
D. 分类
- 以 global average pooling、fully connected layer、softmax 结束模型。
- 损失函数是交叉熵。
- 之所以没有使用更复杂的网络和高级损失函数来形成分类器,是为了突出DeepFE在特征提取方面的优越性能。也就是说,重构后的特征表达式具有足够的区分性和鲁棒性,并且对类敏感。
实验
数据集
ISCXVPN2016
- 总流量为28GB。根据不同的用户行为,它包含7种类型的流量。每种类型都包括常规流量会话和封装流量会话。后者更难分类,因为它由加密的VPN协议包装。
- 该论文选择具有挑战性的VPN封装流量作为第一个实验数据集,称为ISCX VPN,删除了难以标记的“Web浏览”类别。将每个流的应用程序数据的前784字节作为初始特征向量。
27 APP
- 由作者的实验室收集,包含27种应用程序流量。从Google Play Store的前100个热门应用中随机选择了27个应用,并将它们安装在两台Android设备上。对于每个应用程序,使用Android测试工具Monkeyrunner随机触发一些函数,捕获过程中生成的流量,并将其保存为pcap文件。
- 对每个应用重复此步骤150次,获得pcap文件。对于每个应用程序流的第一个特征,将其初始长度取为200。
性能指标
Inpidual metrics:
- Precision
- Recall
- F1
Global metrics:
- G-mean (GM) :所有recall的几何平均值。
- MAUC:每一个类的Precision-and-Recall curve (AUC-PR)下面积的平均值。
DeepFE设置
选择ResNet18作为DeepFE的基本结构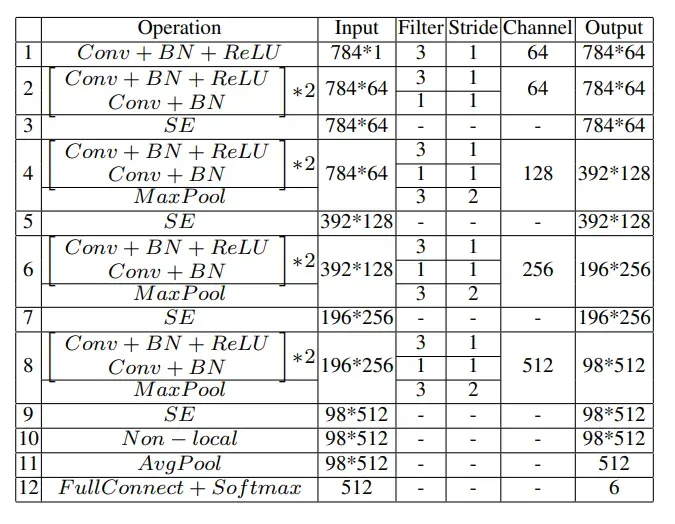
实验结果
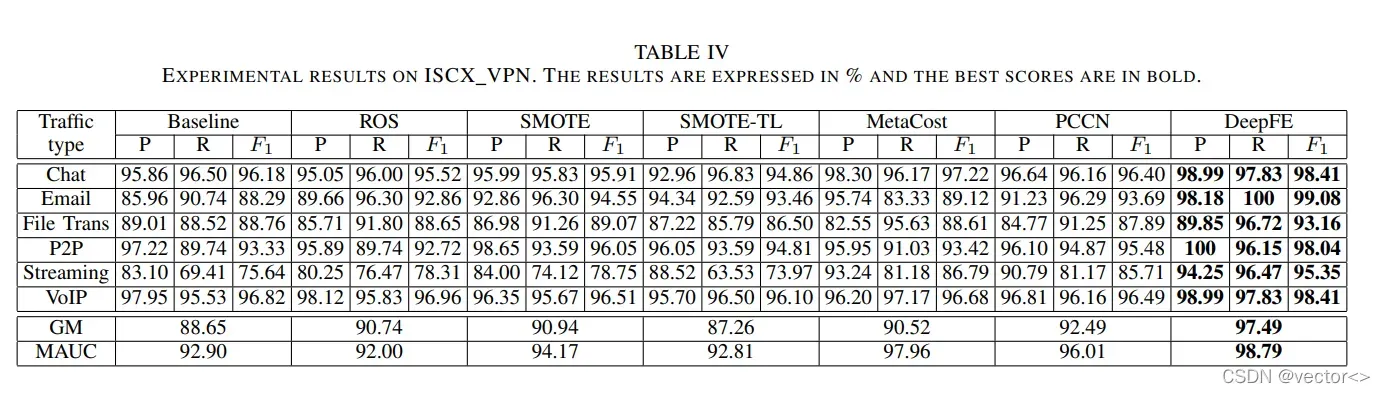
ISCX VPN dataset:
- 提出的DeepFE在各方面都优于比较方法,可以极大地解决由于类不平衡导致的NTC任务性能下降问题。
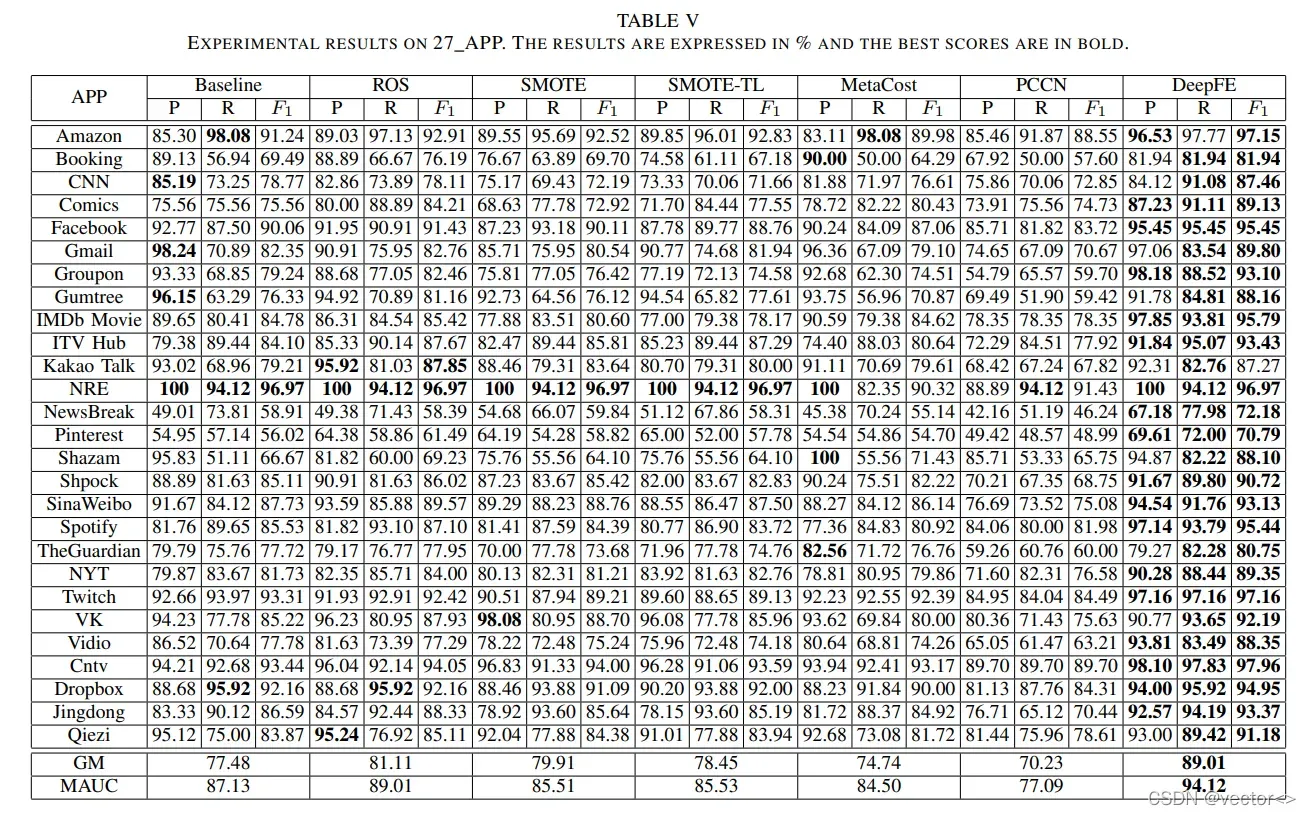
27 APP dataset:
- 虽然DeepFE在少数类的Precision上没有获得最高的分数,但其对应的Recall和F1得分最高,整体表现良好。
综上所述
提出了一个端到端的非平衡流量分类框架DeepFE
- 通过基本的 ResNet 结构,DeepFE能够深入挖掘有效特征。
- 为了缓解少数类的性能下降,DeepFE 使用 squeeze-and-excitation( SE ) 显式地建模了特征通道之间的相互依赖关系,并学习了通道权重。为不同类别生成的特定特征表示大大增加了区分。
- 它还使用 non-local 从空间角度挖掘有价值的信息,以进一步增强特征表达的鲁棒性。
- 此外,DeepFE中的流量向量化设计使其具有通用性,可以适应不同格式的初始流量特性。
- 在两个真实数据集上进行了全面的实验,结果表明,DeepFE在不同的任务中表现出色,优于几种最先进的方法,极大地提高了少数类的性能,同时保持了大多数类的优势。
版权声明:本文为博主vector<>原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_39328436/article/details/123447262