来源:爱奇艺 EMNLP2019 Workshop
论文:https://aclanthology.org/D19-5522.pdf
代码:GitHub – iqiyi/FASPell: 2019-SOTA简繁中文拼写检查工具:FASPell Chinese Spell Checker (Chinese Spell Check / 中文拼写检错 / 中文拼写纠错 / 中文拼写检查)
内容
模型结构
1. 基于bert掩码语言模型的微调
2. 基于汉字相似度的解码器
汉字相似度
实验结果
模型结构
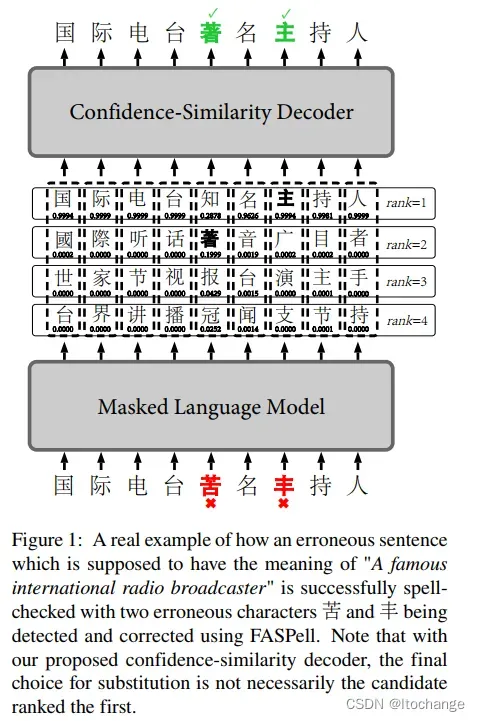
1. 基于bert掩码语言模型的微调
利用训练语料(错误-正确句子对),微调bert
- 对于无错误的句子和bert一样构造数据,即选出15%的tokens预测,80%用[Mask]替换,10%用保持不变,10%用随机token替换
- 对于有错误的句子,有错误的位置为需要预测的位置,标签是对应正确的token;为了防止过拟合,另外再选择相同数量的无错的位置进行预测。
2. 基于汉字相似度的解码器
汉字相似度
字形相似度(与使用中文图片相比,以下方法考虑了笔顺、汉字结构等)。考虑到复杂性,这里只使用序列信息,不使用树结构信息(kanji データベースプロジェクト)
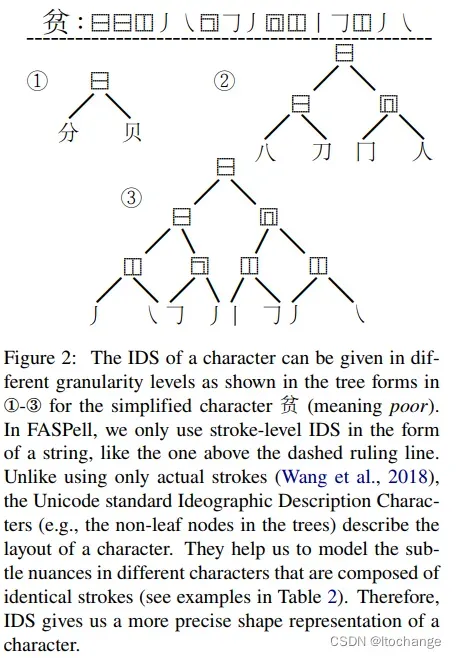
发音相似度: 1减去标准化的拼音编辑距离
在解码阶段,原有的方法是对多个特征设置不同的权重。论文同时利用bert预测的置信度和汉字之间的相似度进行解码。
首先基于训练集绘制原字-候选字相似度和bert置信度的散点图,画出能将检测错误,纠正错误与纠正正确分开的曲线。
横坐标是bert的置信度,纵坐标是汉字的相似度
最终的选择是基于这条曲线。
这个曲线是要手工调整的,其实就是在解码的时候,综合考虑字的相似度以及bert预测的输出概率
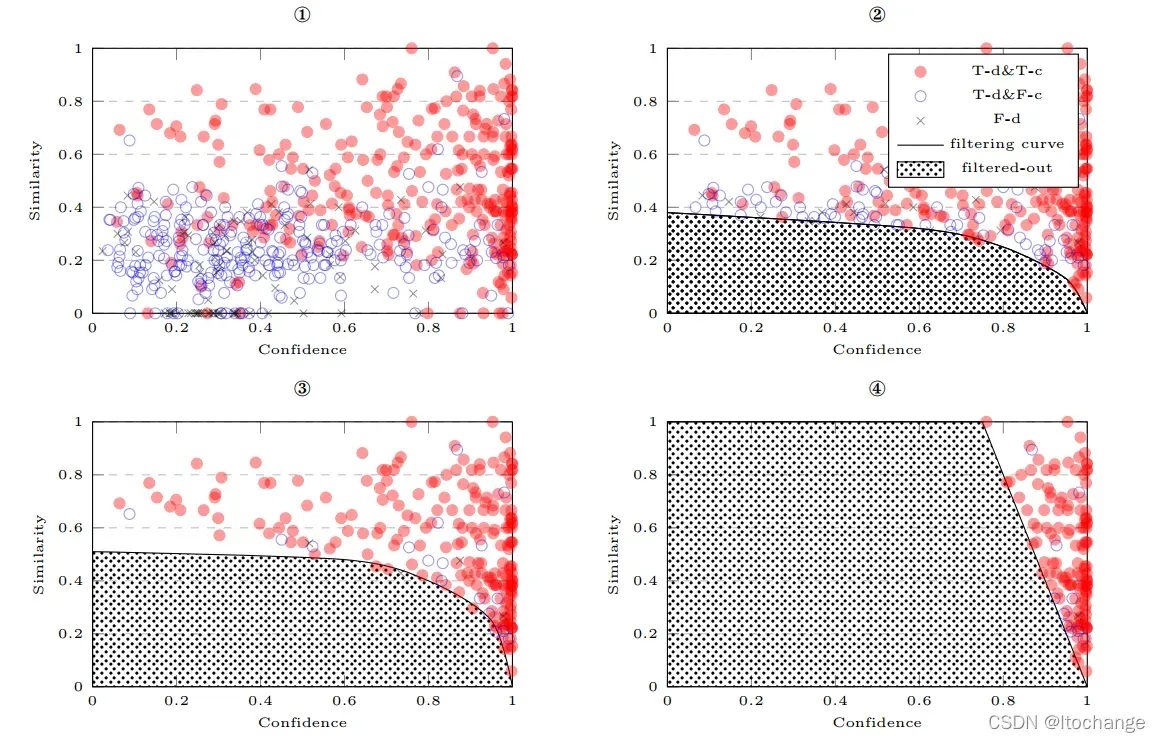
可以实现在召回率损失小的基础上提高准确率
实验结果
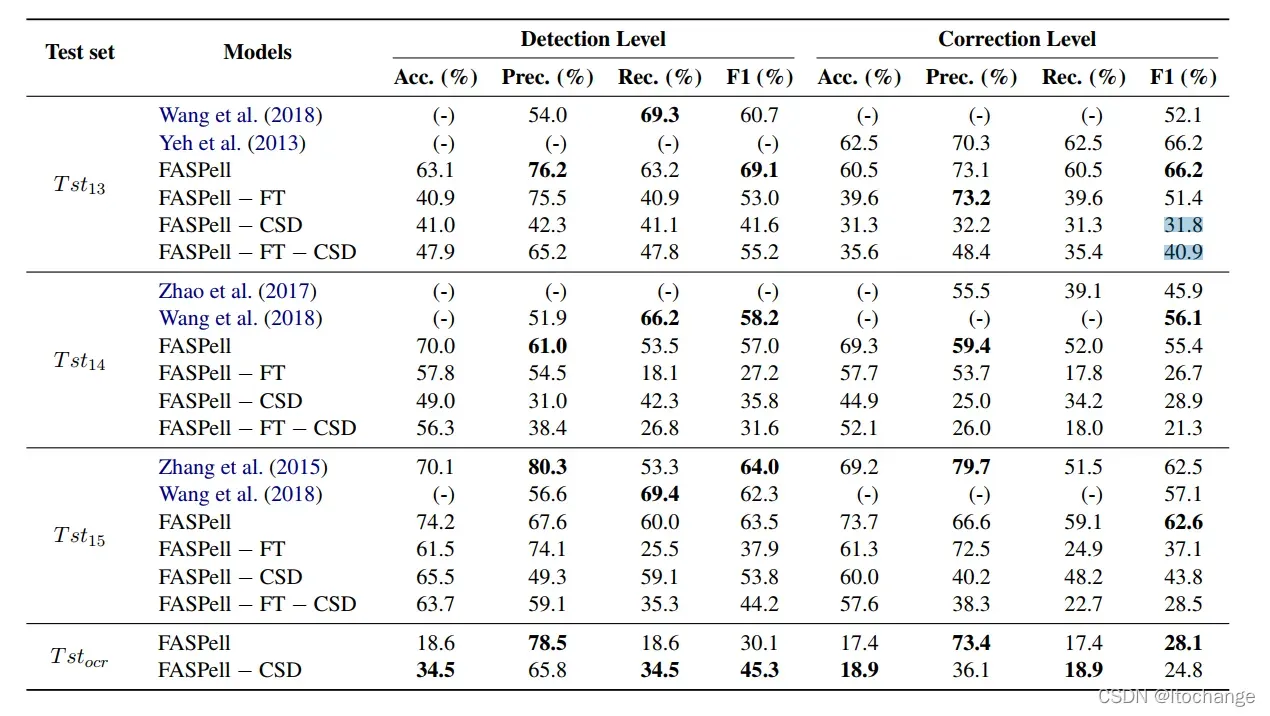
——FT代表去掉微调
——CSD代表去掉基于汉字相似度的解码器
文章出处登录后可见!
已经登录?立即刷新