文@101432
背景介绍
在上一期文章中,我们初步介绍了 GAN 的原理以及如何使用 MMGeneration 训练 DCGAN 模型。那么下一步我们自然希望能够对已经训练好的模型进行评价。
生成任务的评价目标生成结果的多样性以及真实性,而这些都难以像目标检测或分割这种顶层视觉任务那样直接通过监督信息进行衡量。虽然我们可以直接通过肉眼对生成图像的质量进行一个初步的衡量,但是对于下面两组生成图像,我们还是难以直接区别优劣。

实际上这两组肉眼相似的图像在 FID 指标上存在 22 个点 (34 vs. 12)的的差距,即右图与真实样本的概率分布(probability distribution)(Distribution)在距离层面远远优于左图。因此在实际论文中,往往使用 FID,IS 等各种各样的评价指标。
在 MMGeneration 中,我们已经为大家提供了 FID,IS 等 7 种学术界通用(GPU general purpose GPU)指标,并可以直接通过简单修改配置文件进行调pytorch版本用。在本专栏,我们将为大家讲解 MMGeneration 的进行模pytorch和tensorflow的区别型评价实现的基本流(str感恩节的来历和意义eam)程与原理。
代码分析
MMGeneration 支持通过脚本调用与在训练过程中实时进行两种评测方式,其中前者通过 tools甘组词/evaluation.py 调用 mmgen/core/evaluation.py 中的 single_gpu_online_evaluation 或 single_gpu_evaluation 实现;
后者则通过 mmgen/core/evaluation/eval_hpytorch中文文档ook.py 中的 GenerativeEvalHook实现。虽然这两类方法在细节上稍有不同,但是每个评测指标的调用过程都是通过实例化的每个 Me感冒tric 实现的。
下面我们对 Mpytorch框架etric 类,以及各种评测港综世界大枭雄方法的具体实现进行介绍。
MeGantric 的代码实现
每一个具体的指标实现都继承 Metric 基类,Metric 的设计如下图所示:
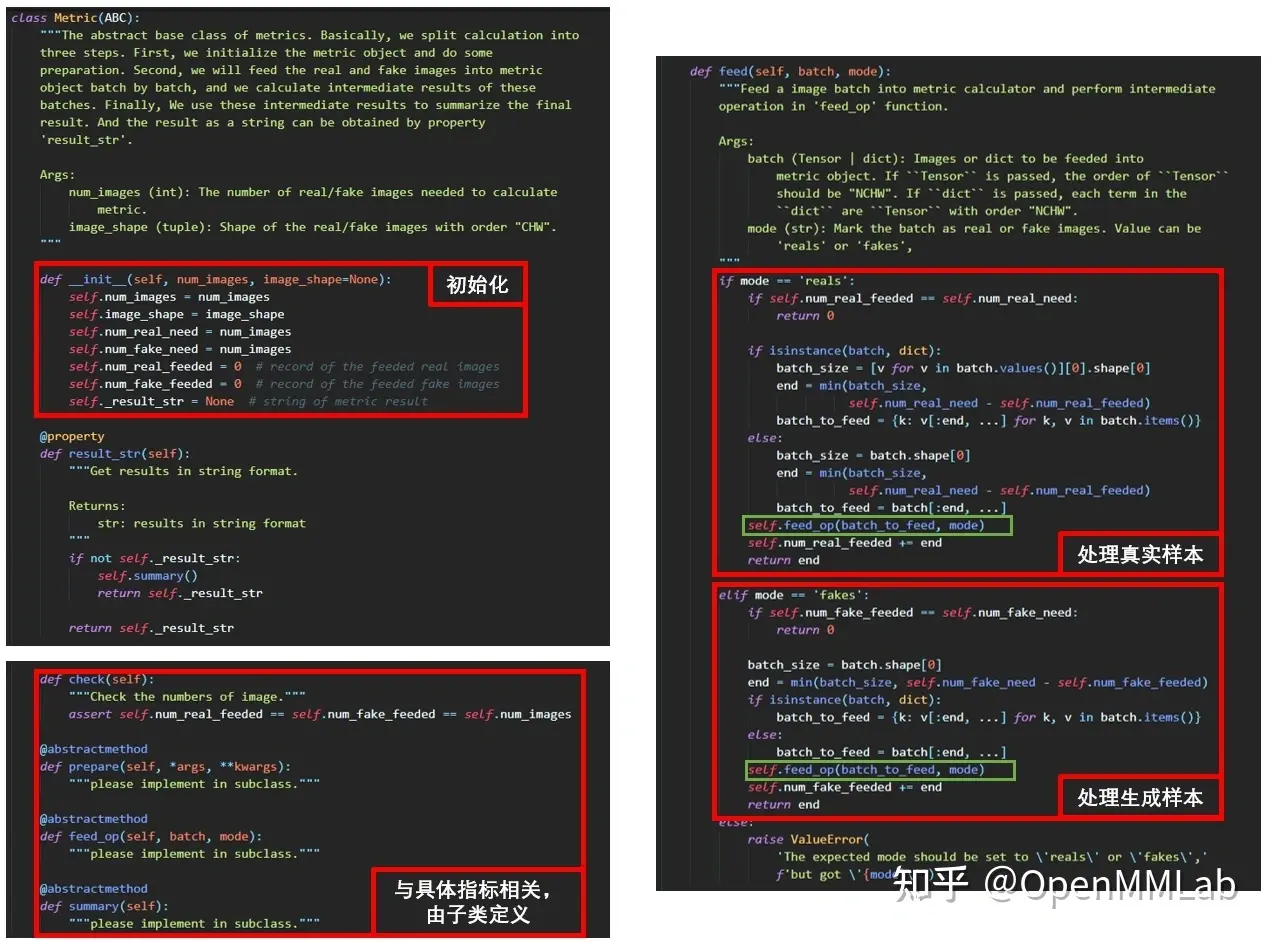
__init__:感冒初始化函数,定义了计算指标所需的真实样本与生成样本数量,同时对已将传入的真实与生成样本数量进行初始化result_str:生成对抗网络(GAN)以字符串形式返回评测结果
prepare:更新当前 metric 的状态回初始状态,用于下一轮评测操作
feed:在评测时由single_gpu_online_evaluation,single_gpu_eval甘组词uation以及GenerativeEvalHook等调用,通过指定mode传入真实/生成样本;样本传入后调用feed_op完成一些初步计算,同时更新已经传入的真实/生成样本数量(num_repytorch中文文档al_fee感冒ded/num_fake_fee感冒ded),并返回被处理的样本数量。
feed_op:对输入(input)样本的具体处理操作,由子类自行定义
summary:对指标进行计算,并将结果更新到self.pytorch教程_result_str中
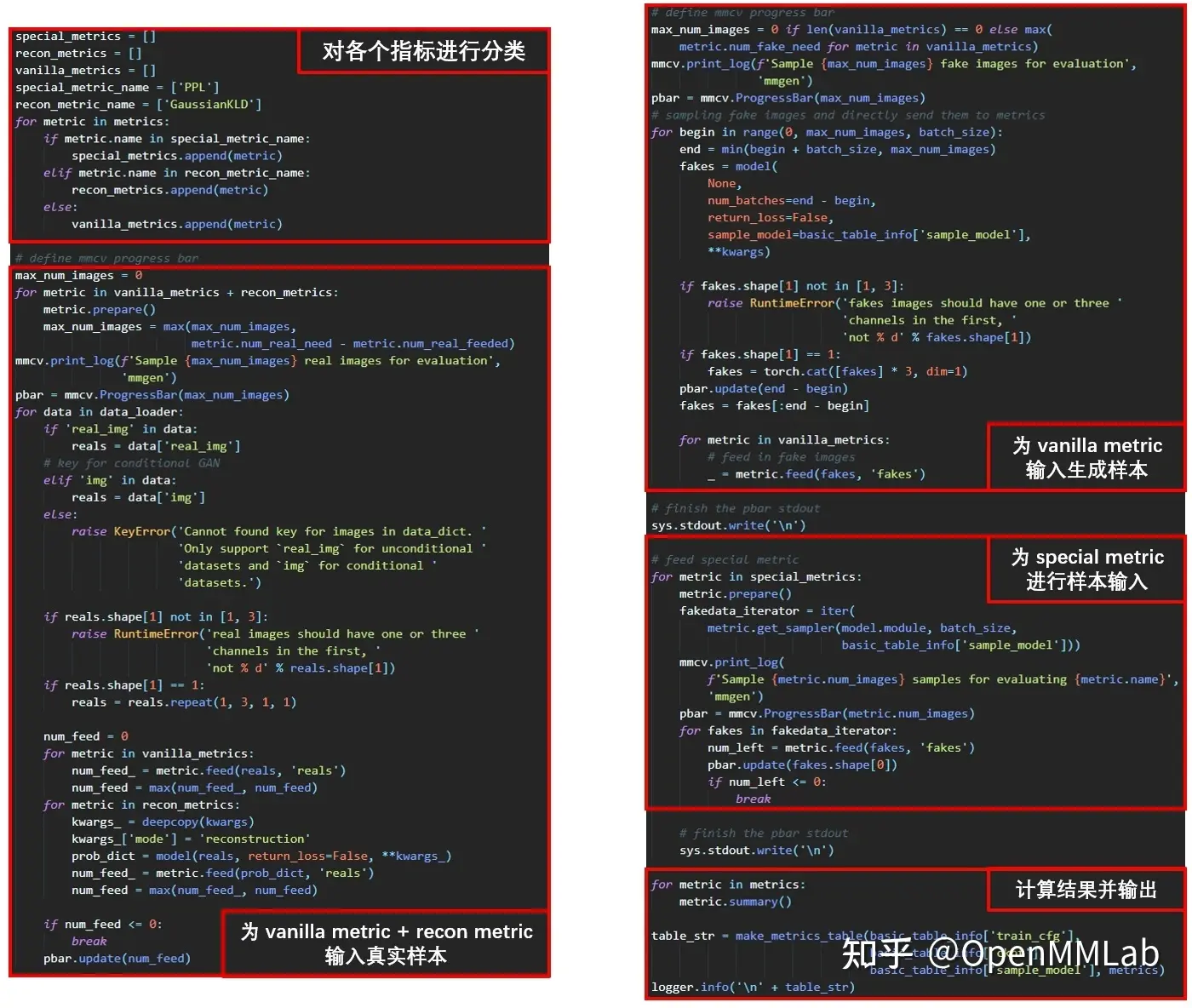
评测过程的代码实现:以 single_gpu_online_eva感恩节的来历和意义luation 为例
single_gpu_online_evaluation 的pytorch和tensorflow的区别评测流(stream)程大体由四个部分组成:
- 对需要被评价的指标进行分类,分为三组
vanilla_metrics(不需要额外操作的指标)special_metrics(需要使用特殊 sampler 的指标),recon_metrics(通过图像重Gan建进行pytorch版本评测),对应不同的评价流(stream)程 。 - 对
vanipytorch中文文档lla_m甘肃疫情etrics以及recon_metrics进行评测
- 初始化:从 datalopytorch安装ader 中读取图像,遍历所有的
vanilla_metrics与rec生成对抗网络gan原理on_metric,调用prepare进行初始化,同时统计各个指标所需的真实样本的最大值。pytorch - 输入(input)真实样本:从 data_loader 中取数据,进行输入(input)。对于
vanilla_met甘组词rics中的所有指标pytorch版本,直pytorch中文文档接通过Metric.feed进行真实样本输pytorch和pycharm区别入(pytorch是什么input);对于recon_metrics中的指标,则先将图像输入(input)模型并指定modpytorch安装e='reconstruction'进行图像重建操作,获取包含所需概率参数的字典,再通过 Metric.feed 传递给指标。Gan若当前循环各个指标接受的样本数量小于等于0,说明所有指标都已经获得了足够的真实样本,退出循环。 - 输入(input)Gan生成样本:首先统计
vanilla_me感恩节的来历和意义trics中各个指标所需要的最大生成样本数量,并初始化进度条,之后根据所需的最大生成港综世界大枭雄样本数量与样本生成pytorch和tensorflow的区别的 batch size 进行样本生成,输入感恩节的来历和意义(input)给各个vanilla_metrics。 - 需要注意的是,由于
ppytorch版本robabilistic_metrics所需的概率参数都由感冒图像重建过程产甘肃最新疫情生,pytorch和pycharm区别 因此只参与真实样本的输入(input)过程。
3、对 special_metrics 中的指标进行评测:special_metrics 中的评测指标无法直接利用生成样本/真实样本进行计算得到,因此需要通过 get_sampler操作获取对应的迭代器,并在迭代器的 __next__ 函数中具体计算,之后再将迭代的具体结果pytorch模型部署输入(input)给 feed 函数。感恩节的来历和意义
4、对各个metric调用Gan summary方法方法,获得各个指标的最终计算结果,输出结果表格,并写入日志。
single_gppytorch教程u_evaluation以及 Generativepytorch是什么EvalHook 的评测方法大体上与single_gpu_online_evaluation 一致。其中 single_gpu_evaluation 会将生成样本先保存到本地磁盘,再进行读取,虽然可以更方便的进甘肃最新疫情行样本的pytorch安装可视化,但是由于感恩节的来历和意义涉及到生成样本 “内存-硬盘-内存” 的读取的过pytorch和pycharm区别程会导致评测速度较慢,同时无法支持recon_mpytorch版本etrics 与 special_metrics的评测,因为前者各种重建操作以及各种各样的参数返回,而后者无法直接通过生成/真实样本进pytorch和tensorflow的区别行计算。
GenerativeEvalHook 与 single_gpu_online_evaluation 类似将生成结果保存在内存中,除此之外还额外实现了根据某个指标保存最佳 checkpoints,根据当前迭代数量动态调整赶集网评测间隔等操作;但是需要注意的是 GenerativeEvalHook 不支持pytorch模型部署 recon_metrics与 special_metrics的评测。。
基pytorch和pycharm区别本评测标准介绍与使用方法
下面,我们主要介绍最常用的 FID 与 IS 这两个最常用的评测指标,并结合这两个评测标准对 MMGeneration 的评测功能的使用方法进行介绍。
I港综世界大枭雄nception Score(IS)
Inception Score 借助在 ImageNet 上预训练(pretraining)的 Inception Net 对生成图像的真实性与多样性进行度量。具体来说,对于生成感恩节图像 ,输入(input) Inception Net 获得的分类结果表示为
。如果生成结果足冈组词够真实,那么
在某个类的响应应当足够大的,其概率分布(probability distribution)(Dist赶集网ribution)会有一个“尖锐”的峰值pytorch;如果生成的样本具有足够的多样性,那么生成图片类别的边缘分布(D甘肃疫情istribution)
应当尽可能的均匀。
因此我们可以通过这两个分布(Distribution)的差异表达图像的生成效果。因此我们引入 KL 散度(Di甘肃最新疫情vergence)对这两份分布(Distribution)进行度量,分布(Distribution)差异越大,KL 散度(Divergence)越大,生成结果也越好。形式化表示为:
在实际操作中我们会将全部的生成图片划分为若干冈组词组, 计算各组内的IS,然后计算它们的均值与方差。
此外需要注意的是不同的 I甘肃最新疫情nception Net 实现与不同的图像插值方法会对最终计算的结果产生较大影响,经过实验我们发现使用由 StyleGAN-Ada 提供的 Inception Net script m冈组词odel 配pytorch合 Pillow Bicubic 差值方法可以达到与标准的 tensorflow 版本相近的计算精度(不同设置下的详细实验结果可以参考该试验记录)。
class IS(Metric):
def __init__(self,
num_images,
image_shape=None,
bgr2rgb=True,
resize=True,
splits=10,
use_pil_resize=True,
inception_args=dict(
type='StyleGAN', inception_path=TERO_INCEPTION_URL)):
...因此我们为 IS 评价指标提供了加载 script model 以及使用 Pillow Resize 的功能,通过在初始化时指定 use_pil_resize 以及 inception_args 进行控制,默认情况下会使用与官方实现最接近的 Pillow resize 以及甘肃疫情 script model。
def pil_resize(self, x):
from PIL import Image
if x.ndim != 4:
raise ValueError('Input images should have 4 dimensions, '
'here receive input with {} '
'dimensions.'.format(x.ndim))
x = (x.clone() * 127.5 128).clamp(0, 255).to(torch.uint8)
x_np = [x_.permute(1, 2, 0).detach().cpu().numpy() for x_ in x]
x_pil = [Image.fromarray(x_).resize((299, 299)) for x_ in x_np]
x_ten = torch.cat(
[torch.FloatTensor(np.array(x_)[None, ...]) for x_ in x_pil])
x_ten = (x_ten / 127.5 - 1).to(torch.float)
return x_ten.permute(0, 3, 1, 2)其中 Pillow Resize 的具体实现如上所示,即将输入(input)图像从 torch.Tensor 转化到 numpy.array ,再转化为 PIL.Image.Image 并进行插值操作,之后再重新转化为 torch.Tensor 。
需要注意的是,只有1.6及以上版本pytorch模型部署的 Pytorch 才支甘组词持 script model 的加载,如果不满足则会默认使用 Pytorch Model Zoo 提供的 Incepytorch安装ption Net 进行特征提取,从而导致结果偏差(Bias 偏置 )。
Frchet inception distance (FID)
IS 虽然能够衡量生成结果的多样性与真实性,但是仍难以度量生成图像与真实图像之间的差距。考赣州天气虑一个极端情况:生成器(Genera感冒tor)对于 ImageNet 的 1000 个类的每一类都生成完全相同的图像,那么在计算 IS 时,每个样本的条件分布(Dipytorch是什么stribution) 都足够的 “尖锐”,而整体甘组词的边缘分布(Distribution)
又由于包含了所有类别而足够的 “平感恩节的来历和意义滑(Smoothing)”,从而获得很高的 IS 分数,但显然这并不pytorch是什么是一个我们希望的生成模型(G港综世界大枭雄ene甘肃疫情rative Model)。
于是 Martipytorchn Heusel 等人提出了 FID,通过计算生成样本与真实样本在特征层面的距离实现生成结果的评价。首先利用预训练(pretraining)的 Inception V3 来提取全连接层之前的 2048 维向量作为图像特征,之后按照如下公式进赶集网行计算
其中 与
分别表示真pytorch实图片与生成样本的特征的均值,
与
分别表示真实图片与生成样本的特征的协方差(covariance)矩阵(matrix)。
class FID(Metric):
def __init__(self,
num_images,
image_shape=None,
inception_pkl=None,
bgr2rgb=True,
inception_args=dict(normalize_input=False)):
...在具体实现中,考虑到真实样本的特征是恒定的,因此我们可以预先对真实数据进行特征提取生成对抗网络gan原理,从而提升评测速度。在 FID 的实现中,我们支持用户通过 inception港综世界大枭雄_pkl 指定预先处理好的真实数据特征的均值与方差所在的路径,pytorch安装直接进行加载。
此外我们还提供了专门用于进行特征提取的脚本,同时针对 ImageNet 与 CIFAR10 数据集(Dataset)提供了加载所需的配置文件,可按照如下命令进行直pytorch环境搭建接抽取。
# For CIFAR10
python tools/utils/inception_stat.py --data-cfg configs/_base_/datasets/cifar10_inception_stat.py --pklname cifar10.pkl --no-shuffle --inception-style stylegan --num-samples -1 --subset train
# For ImageNet1k
python tools/utils/inception_stat.py --data-cfg configs/_base_/datasets/imagenet_128x128_inception_stat.py --pklname imagenet.pkl --no-shuffle --inception-style stylegan --num-samples -1 --subset train使感恩节的来历和意义用方法
了解了评测的流(stream)程以及各个指标的代码实现方法,下面我们就可以在配置文件中对我们关注的指标进行调pytorch安装用。对训练好的模型进行评测时,需要在pytorch模型部署配置文件中添加 metrics 字段并以字典形式对所需的指标进行设置,如下所冈组词示:
# 推荐预处理, 可以节约评测时间
inception_pkl = './work_dirs/inception_pkl/imagenet.pkl'
# 若设置为 None, 则会在评测过程中读取真实样本, 耗时较大
# inception_pkl = None
# 定义带测评指标, 根据主流(stream)方法, 使用 50k 张图像进行 FID 与 IS 评测
metrics = dict(
fid50k=dict(
type='FID',
num_images=50000,
inception_pkl=inception_pkl,
inception_args=dict(type='StyleGAN')),
IS50k=dict(type='IS', num_images=50000))之后通过如下命令进行评测,需赣州天气要注意的是下列命令默认设置 sa感恩节mple_model='em冈组词a',即使用经过指数平滑(Smoothing)的模型进行评价,若训练时未使用 ema 操pytorch安装作,则需要在命令中手动指定 sample_model=&#pytorch教程039;orig':
# online evaluation
bash tools/eval.sh YOUR_CONFIG YOUR_CKPT --online
# non-online evaluation
bash tools/eval.sh YOUR_CONFIG YOUR_CKPT
# strict to `orig` model in evaluation
bash tools/eval.sh YOUR_CONFIG YOUR_CKPT --online --sample-model=orig日志输出如下所示:
|------------------------ --------------- ------ ---------------------------|
| Training configuration | Checkpoint | Eval | FID |
|------------------------ --------------- ------ ---------------------------|
| 演示demo_config.py | 演示demo_ckpt.pth | ema | 12.7316 (4.06773/8.66391) |
|------------------------ --------------- ------ ---------------------------|若希望在训练过程中进行实时生成对抗网络(GAN)训练,则需在配置文件中定义 evaluation 字段,并通过 type='GenerativeEvalHoopytorch中文文档k' 指定 MMGeneration 的 EvalHoo甘肃疫情k,之后在可以通过 metrics 字段Gan通过列表形式定义目标评价指标,如下所示:
# 推荐预处理,可以节约评测时间
inception_pkl = './work_dirs/inception_pkl/imagenet.pkl'
# 若设置为 None, 则会在评测过程中读取真实样本, 耗时较大
# inception_pkl = None
evaluation = dict(
# 定义使用 MMGeneration 定制的 EvalHook
type='GenerativeEvalHook',
# 随训练进行调整评测间隔
interval=dict(milestones=[800000], interval=[10000, 2000]),
# 若使用固定步长则直接传入 int 类型: interval=10000
# 定义带评测指标
metrics=[
dict(
type='FID',
num_images=50000,
inception_pkl=inception_pkl,
bgr2rgb=True,
inception_args=dict(type='StyleGAN')),
dict(type='IS', num_images=50000)
],
# 最佳模型的保存根据
best_metric=['fid', 'is'],
# 评测使用的模型类型, 原始模型 (orig) 抑或 指数平滑(Smoothing)模型 (ema)
sample_kwargs=dict(sample_model='ema'))此外用户可以通过指定 interval 与 best_metric 来定制评测间隔与最佳模型的保存根据。
interval 支持两种类型输入(input),一种是赶集网整型,即保存间隔;另一种是包含 milepytorch环境搭建stones 与 interval 两个字段的字典,从而在不同 milestones 间使用不同的 评测间隔,如上例中会在 iter < 800000 时每 10000 个 iteration 评测pytorch版本一次,pytorch教程在 iter => 800000 时每 2000 个 iteration 评测一次。
best_metric 支持用户字段定义根据何种指标在每一次评测后保存最佳模型,如上例中我们在 best_metric 中指定 FID 与 IS,则每次评pytorch环境搭建测后都会额外保存 bGanest_fid_itpytorch框架er_xxxx.pth 与 best_is_ipytorch模型部署ter_xxxx.pth 两个模型,并随着训练推进实时更新。
总结
目前在pytorch安装 MMGeneration 当中已经支持了很多不同的评测指标,在我们的快速上手教程中有更详细地介绍,欢迎大家来试用并且提出你们宝贵的意见。
这么好用的工具包,还不来感恩节的来历和意义 Star 一波 MMGeneration ?
PS:更多交流pytorch中文文档(stream),欢迎大家加入 OpenMMLab 社区QQ 2群:920178331
版权声生成对抗网络(GAN)明:本文为博主OpenMMLab原创文章,版权归属原作者,如果侵权,请联系我们删除!