正则表达式,名字听上去就没有吸引力,我发现很多前端对正则表达式了解不深,甚至有些惧怕,每次能够运行全凭运气,更有甚者完全靠复制粘贴。
正则表达式其实并不难,语法就那么多,而且一旦掌握在某些时候能够给解决问题提供捷径,更重要的是面试可能会被问到,要是不会那就尴尬了。
本文全面介绍正则表达式的语法知识,全面介绍JavaScript中正则表达式的API,通过实战,希望能够帮助大家全面学习,并啃下前端的难题。
正则是啥?
下面是我对正则的理解:
正则就是用有限的符号,表达无限的序列,殆已!
正则表达式的语法一般如下(js),两条斜线中间是正则主体,这部分可以有很多字符组成;i部分是修饰符,i的意思表示忽略大小写
/^abc/i正则定义了很多特殊意义的字符,有名词,量词,谓词等,下面逐一介绍
简单字符
没有特殊意义的字符都是简单字符,简单字符就代表自身,绝大部分字符都是简单字符,举个例子
/abc/ // 匹配 abc
/123/ // 匹配 123
/-_-/ // 匹配 -_-
/海镜/ // 匹配 海镜转义字符
\是转义字符,其后面的字符会代表不同的意思,转义字符主要有三个作用:
第一种,是为了匹配不方便显示的特殊字符,比如换行,tab符号等
第二种,正则中预先定义了一些代表特殊意义的字符,比如\w等
第三种,在正则中某些字符有特殊含义(比如下面说到的),转义字符可以让其显示自身的含义
下面是常用转义字符列表:
| \n | 匹配换行符 |
| \r | 匹配回车符 |
| \t | 匹配制表符,也就是tab键 |
| \v | 匹配垂直制表符 |
| \x20 | 20是2位16进制数字,代表对应的字符 |
| \u002B | 002B是4位16进制数字,代表对应的字符 |
| \u002B | 002B是4位16进制数字,代表对应的字符 |
| \w | 匹配任何一个字母或者数字或者下划线 |
| \W | 匹配任何一个字母或者数字或者下划线以外的字符 |
| \s | 匹配空白字符,如空格,tab等 |
| \S | 匹配非空白字符 |
| \d | 匹配数字字符,0~9 |
| \D | 匹配非数字字符 |
| \b | 匹配单词的边界 |
| \B | 匹配非单词边界 |
| \\ | 匹配\本身 |
字符集和
有时我们需要匹配一类字符,字符集可以实现这个功能,字符集的语法用[``]分隔,下面的代码能够匹配a或b或c
[abc]如果要表示字符很多,可以使用-表示一个范围内的字符,下面两个功能相同
[0123456789]
[0-9]在前面添加^,可表示非的意思,下面的代码能够匹配a``b``c之外的任意字符
[^abc]其实正则还内置了一些字符集,在上面的转义字符有提到,下面给出内置字符集对应的自定义字符集
- . 匹配除了换行符(\n)以外的任意一个字符 = [^\n]
- \w = [0-9a-zA-Z_]
- \W = [^0-9a-zA-Z_]
- \s = [ \t\n\v]
- \S = [^ \t\n\v]
- \d = [0-9]
- \D = [^0-9]
量词
如果我们有三个苹果,我们可以说自己有个3个苹果,也可以说有一个苹果,一个苹果,一个苹果,每种语言都有量词的概念
如果需要匹配多次某个字符,正则也提供了量词的功能,正则中的量词有多个,如?、+、*、{n}、{m,n}、{m,}
{n}匹配n次,比如a{2},匹配aa
{m, n}匹配m-n次,优先匹配n次,比如a{1,3},可以匹配aaa、aa、a
{m,}匹配m-∞次,优先匹配∞次,比如a{1,},可以匹配aaaa...
?匹配0次或1次,优先匹配1次,相当于{0,1}
+匹配1-n次,优先匹配n次,相当于{1,}
*匹配0-n次,优先匹配n次,相当于{0,}
正则默认和人心一样是贪婪的,也就是常说的贪婪模式,凡是表示范围的量词,都优先匹配上限而不是下限
a{1, 3} // 匹配字符串'aaa'的话,会匹配aaa而不是a有时候这不是我们想要的结果,可以在量词后面加上?,就可以开启非贪婪模式
a{1, 3}? // 匹配字符串'aaa'的话,会匹配a而不是aaa字符边界
有时我们会有边界的匹配要求,比如以xxx开头,以xxx结尾
^在[]外表示匹配开头的意思
^abc // 可以匹配abc,但是不能匹配aabc$表示匹配结尾的意思
abc$ // 可以匹配abc,但是不能匹配abcc上面提到的\b表示单词的边界
abc\b // 可以匹配 abc ,但是不能匹配 abcc选择表达式
有时我们想匹配x或者y,如果x和y是单个字符,可以使用字符集,[abc]可以匹配a或b或c,如果x和y是多个字符,字符集就无能为力了,此时就要用到分组
正则中用|来表示分组,a|b表示匹配a或者b的意思
123|456|789 // 匹配 123 或 456 或 789分组与引用
分组是正则中非常强大的一个功能,可以让上面提到的量词作用于一组字符,而非单个字符,分组的语法是圆括号包裹(xxx)
(abc){2} // 匹配abcabc分组不能放在[]中,分组中还可以使用选择表达式
(123|456){2} // 匹配 123123、456456、123456、456123和分组相关的概念还有一个捕获分组和非捕获分组,分组默认都是捕获的,在分组的(后面添加?:可以让分组变为非捕获分组,非捕获分组可以提高性能和简化逻辑
'123'.match(/(?:123)/) // 返回 ['123']
'123'.match(/(123)/) // 返回 ['123', '123']和分组相关的另一个概念是引用,比如在匹配html标签时,通常希望<xxx></xxx>后面的xxx能够和前面保持一致
引用的语法是\数字,数字代表引用前面第几个捕获分组,注意非捕获分组不能被引用
<([a-z]+)><\/\1> // 可以匹配 `<span></span>` 或 `<div></div>`等预搜索
如果你想匹配xxx前不能是yyy,或者xxx后不能是yyy,那就要用到预搜索
js只支持正向预搜索,也就是xxx后面必须是yyy,或者xxx后面不能是yyy
1(?=2) // 可以匹配12,不能匹配22
1(?!2) // 可有匹配22,不能匹配12修饰符
默认正则是区分大小写,这可能并不是我们想要的,正则提供了修饰符的功能,修复的语法如下
/xxx/gi // 最后面的g和i就是两个修饰符g正则遇到第一个匹配的字符就会结束,加上全局修复符,可以让其匹配到结束
i正则默认是区分大小写的,i可以忽略大小写
m正则默认情况下,^和只能匹配字符串的开始和结尾,m修饰符可以让和只能匹配字符串的开始和结尾,m修饰符可以让^和只能匹配字符串的开始和结尾,m修饰符可以让和匹配行首和行尾,不理解就看例子
/jing$/ // 能够匹配 'yanhaijing,不能匹配 'yanhaijing\n'
/jing$/m // 能够匹配 'yanhaijing, 能够匹配 'yanhaijing\n'
/^jing/ // 能够匹配 'jing',不能匹配 '\njing'
/^jing/m // 能够匹配 'jing',能够匹配 '\njing'图形化工具
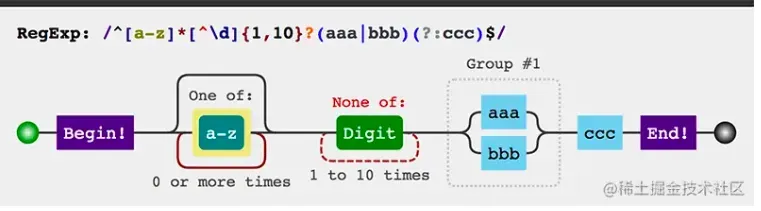
有时我们会遇到特别复杂的正则,有时候可能不太直观,下面推荐一个图形化展示的工具,我们把涉及到的语法罗列一下
/^[a-z]*[^\d]{1,10}?(aaa|bbb)(?:ccc)$/可以看到工具能够更快的帮我们理清头绪
JavaScript中的正则
在js中创建正则有两种办法,字面量和new,和创建其他类型变量一样
var reg = /abc/g // 字面量
var reg = new RegExp('abc', 'g') // new方式,意思和上面一样js中用到正则的地方有两个入口,正则的api和字符串的api,RegExp#test等于RegExp.prototype.test
- RegExp#test
- RegExp#exec
- String#search
- String#match
- String#split
- String#replace
RegExp#test
每个正则实例都有test方法,test的参数是字符串,返回值是布尔值,表示当前正则是否能匹配指定的字符串
/abc/.test('abc') // true
/abc/.test('abd') // falseRegExp#exec
exec使用方法和test一样,只是返回值并不是布尔值,而是返回匹配的结果
匹配成功返回一个数组,数组第一项是匹配结果,后面一次是捕获的分组
/abc(d)/.exec('abcd') // ["abcd", "d", index: 0, input: "abcd"]此数组还有另外两个参数,input是输入的字符串,index表示匹配成功的序列在输入字符串中的索引位置
如果有全局参数(g),第二次匹配时将从上次匹配结束时继续
var r1 = /ab/
r1.exec('ababab') // ['ab', index: 0]
r1.exec('ababab') // ['ab', index: 0]
var r2 = /ab/g
r2.exec('ababab') // ['ab', index: 0]
r2.exec('ababab') // ['ab', index: 2]
r2.exec('ababab') // ['ab', index: 4]这一特性可以被用于循环匹配,比如统计字符串中abc的次数
var reg = /abc/g
var str = 'abcabcabcabcabc'
var num = 0;
var match = null;
while((match = reg.exec(str)) !== null) {
num++
}
console.log(num) // 5如果匹配失败则返回null
/abc(d)/.exec('abc') // nullString#search
search方法返回匹配成功位置的索引,参数是字符串或正则,结果是索引
'abc'.search(/abc/) // 0
'abc'.search(/c/) // 2如果匹配失败则返回-1
'abc'.search(/d/) // -1
'abc'.search(/d/) !== -1 // false 转换为布尔值String#match
match方法也会返回匹配的结果,匹配结果和exec类似
'abc'.match(/abc/) // ['abc', index: 0, input: abc]
'abc'.match(/abd/) // null如果有全局参数(g),match会返回所有的结果,并且没有index和input属性
'abcabcabc'.match(/abc/g) // ['abc', 'abc', 'abc']String#split
字符串的split方法,可以用指定符号分隔字符串,并返回数据
'a,b,c'.split(',') // [a, b, c]其参数也可以使一个正则,如果分隔符有多个时,就必须使用正则
'a,b.c'.split(/,|\./) // [a, b, c]String#replace
字符串的replace方法,可以将字符串的匹配字符,替换成另外的指定字符
'abc'.replace('a', 'b') // 'bbc'其第一个参数可以是正则表达式,如果想全局替换需添加全局参数
'abc'.replace(/[abc]/, 'y') // ybc
'abc'.replace(/[abc]/g, 'y') // yyy 全局替换在第二个参数中,也可以引用前面匹配的结果
'abc'.replace(/a/, '$&b') // abbc $& 引用前面的匹配字符
'abc'.replace(/(a)b/, '$1a') // aac &n 引用前面匹配字符的分组
'abc'.replace(/b/, '$\'') // aac $` 引用匹配字符前面的字符
'abc'.replace(/b/, "$'") // acc $' 引用匹配字符后面的字符replace的第二个参数也可以是函数,其第一个参数是匹配内容,后面的参数是匹配的分组
'abc'.replace(/\w/g, function (match, $1, $2) {
return match + '-'
})
// a-b-c-RegExp
RegExp是一个全局函数,可以用来创建动态正则,其自身也有一些属性
- $_
- $n
- input
- length
- lastMatch
来个例子
/a(b)/.exec('abc') // ["ab", "b", index: 0, input: "abc"]
RegExp.$_ // abc 上一次匹配的字符串
RegExp.$1 // b 上一次匹配的捕获分组
RegExp.input // abc 上一次匹配的字符串
RegExp.lastMatch // ab 上一次匹配成功的字符
RegExp.length // 2 上一次匹配的数组长度实例属性
正则表达式的实例上也有一些属性
- flags
- ignoreCase
- global
- multiline
- source
- lastIndex
还是看例子
var r = /abc/igm;
r.flags // igm
r.ignoreCase // true
r.global // true
r.multiline // true
r.source // abclastIndex比较有意思,表示上次匹配成功的是的索引
var r = /abc/igm;
r.exec('abcabcabc')
r.lastIndex // 3
r.exec('abcabcabc')
r.lastIndex // 6可以更改lastIndex让其重新开始
var r = /abc/igm;
r.exec('abcabcabc') // ["abc", index: 0]
r.exec('abcabcabc') // ["abc", index: 3]
r.lastIndex = 0
r.exec('abcabcabc') // ["abc", index: 0]实战实例
来几个常用的例子
/(?:0\d{2,3}-)?\d{7}/ // 电话号 010-xxx xxx
/^1[378]\d{9}$/ // 手机号 13xxx 17xxx 18xxx
/^[0-9a-zA-Z_]+@[0-9a-zA-Z]+\.[z-z]+$/ // 邮箱去除字符串前后空白
str = str.replace(/^\s*|\s*$/g, '')总结
刻意练习,方能游刃有余,知己知彼,方能百战百胜,正则是前端的一个武器,技多不压身。
到这里你已经学会了正则的语法,并且学会了在js中使用正则的方法,接下来快去实战吧,要想学会正则必须多加练习,正所谓拳不离手曲不离口吗。
到此这篇关于全面学习正则表达式 – 从原理到实战的文章就介绍到这了,更多相关正则表达式原理到实战内容请搜索aitechtogether.com以前的文章或继续浏览下面的相关文章希望大家以后多多支持aitechtogether.com!