决策树
概述
我们先来看看下面的问题。现在我要在网上买一件衣服,在决定是否购买之前,我会考虑一些基本问题。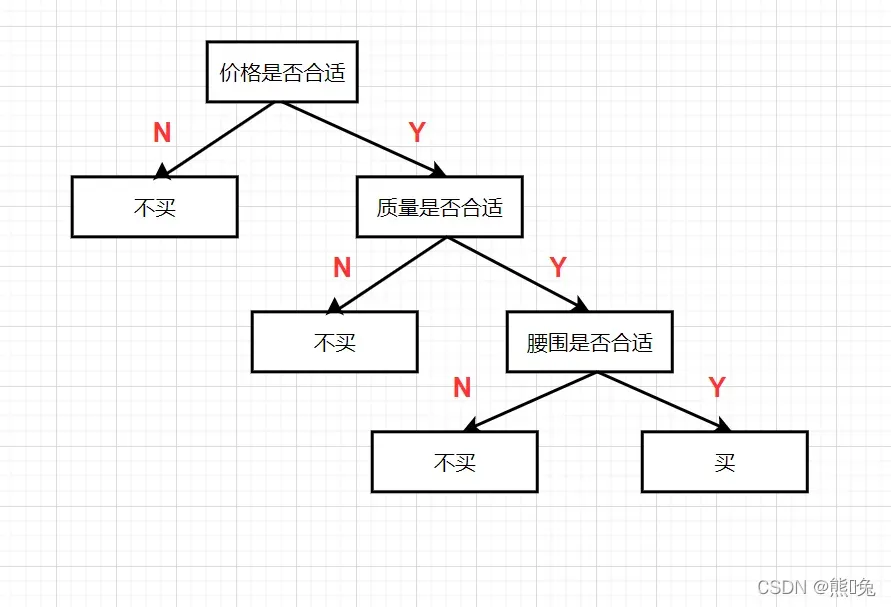
注意图,是不是感觉在代码的世界里有点眼熟? – 树状结构。现在这棵树正在帮助我决定是否购买这件衣服,所以我们现在可以称它为决策树。
概念
决策树是一种可以用于分类与回归的机器学习算法,但主要用于分类。用于分类的决策树是一种描述对实例进行分类的树形结构。决策树由结点和边组成,其中结点分为内部结点和叶子结点,内部结点表示一个特征或者属性(即价格是否合适,质量是否合适,腰围是否合适)叶子结点表示标签(即买与不买)。从根节点开始一步一步走到叶子节点,即做决策的过程。再从代码角度来看,决策树还可以看作一些if…else语句组成的集合(可以自己结合上面的例子写一个if…else的判断语句哦)
熵
那么如何构造出一棵好的决策树呢?其实构造决策树时会遵循一个指标,有的是按照信息增益来构建,如ID3算法;有的是信息增益率来构建,如C4.5算法;有的是按照基尼系数来构建的,如CART算法。但不管是使用哪种构建算法,决策树的构建过程通常都是一个递归选择最优特征,并根据特征对训练集进行分割,使得对各个子数据集有一个最好的分类的过程。
这个过程对应于特征空间的划分和决策树的构建。一开始,构建决策树的根节点,将所有的训练数据放在根节点中。选择一个最优特征,并根据这个特征将训练数据集划分为子集,使每个子集在当前条件下都有一个最佳分类。如果这些子集可以基本正确分类,则构造叶子节点,并将这些子集分配给对应的叶子节点;如果还有子集不能基本正确分类,那么这些子集选择新的最优特征,继续分割,构建对应的节点。这是递归完成的,直到所有训练数据子集都基本正确分类,或者没有合适的特征。最后,将每个子集分配给一个叶子节点,即具有明确的类别。这构建了一个决策树。
信息熵
高中化学学习,不知你还记得熵的知识点吗?在热力学中,熵是一个物理量,表示分子状态的无序程度。但是将其与信息联系起来可以用来描述来源的不确定性。来源的不确定性越大,信息熵越大。
从机器学习的角度来看,信息熵表示的是信息量的期望值。则信息量I(xi)的定义如下(其xi表示多个类别中的第i个类别,p(xi)数据集中类别为 xi 的数据在数据集中出现的概率表示):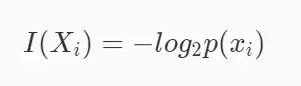
由于信息熵是信息量的期望值,所以信息熵H(X)的定义如下(其中n为数据集中类别的数量):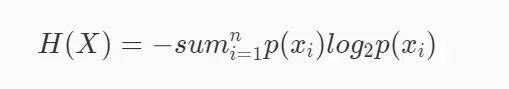
从这个公式也可以看出,如果概率是0或者是1的时候,熵就是0(因为这种情况下随机变量的不确定性是最低的)。那如果概率是0.5,也就是五五开的时候,此时熵达到最大,也就是1。熵越大,不确定性就越高。
条件熵
在实际的场景中,我们可能需要研究数据集中某个特征等于某个值时的信息熵等于多少,这个时候就需要用到条件熵。条件熵H(Y|X)表示特征X为某个值的条件下,类别为Y的熵。条件熵的计算公式如下: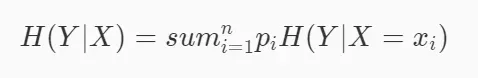
当然,条件熵的性质与熵的性质相同。概率越确定,条件熵越小,概率越大,条件熵越大。
信息增益
所谓的信息增益就是表示我已知条件X后能得到信息Y的不确定性的减少程度。所以信息增益如果套上机器学习的话就是,如果把特征A对训练集D的信息增益记为g(D, A)的话,那么g(D, A)的计算公式就是: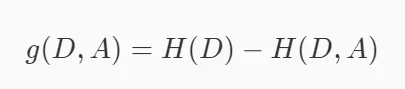
代码实现:(尽量理解这部分,还要注意传入数据的类型)
import numpy as np
def calcInfoGain(feature, label, index):
'''
计算信息增益
:param feature:测试用例中字典里的feature,类型为ndarray
:param label:测试用例中字典里的label,类型为ndarray
:param index:测试用例中字典里的index,即feature部分特征列的索引。该索引指的是feature中第几个特征,如index:0表示使用第一个特征来计算信息增益。
:return:信息增益,类型float
'''
# 计算熵
def calcInfoEntropy(feature, label):
'''
计算信息熵
:param feature:数据集中的特征,类型为ndarray
:param label:数据集中的标签,类型为ndarray
:return:信息熵,类型float
'''
label_set = set(label)
result = 0
for l in label_set:
count = 0
for j in range(len(label)):
if label[j] == l:
count += 1
# 计算各个标签在数据集中出现的概率
p = count / len(label)
# 计算熵
result -= p * np.log2(p)
return result
# 计算条件熵
def calcHDA(feature, label, index, value):
'''
计算信息熵
:param feature:数据集中的特征,类型为ndarray
:param label:数据集中的标签,类型为ndarray
:param index:需要使用的特征列索引,类型为int
:param value:index所表示的特征列中需要考察的特征值,类型为int
:return:信息熵,类型float
'''
count = 0
# sub_feature和sub_label表示根据特征列和特征值分割出的子数据集中的特征和标签
sub_feature = []
sub_label = []
for i in range(len(feature)):
if feature[i][index] == value:
count += 1
sub_feature.append(feature[i])
sub_label.append(label[i])
pHA = count / len(feature)
# 计算信息熵
e = calcInfoEntropy(sub_feature, sub_label)
# 条件熵
return pHA * e
# 信息熵
base_e = calcInfoEntropy(feature, label)
f = np.array(feature)
# 得到指定特征列的值的集合
f_set = set(f[:, index])
sum_HDA = 0
# 计算条件熵
for value in f_set:
sum_HDA += calcHDA(feature, label, index, value)
# 计算信息增益
return base_e - sum_HDA
ID3算法
树是根据特征的信息增益构建的。一般步骤是从根节点开始,计算节点所有可能特征的信息增益,然后选择信息增益最大的特征作为节点的特征,通过不同的值建立子节点特征,然后比较节点递归执行上述步骤,直到信息增益很小或没有特征可以继续选择。
代码:
import numpy as np
class DecisionTree(object):
def __init__(self):
#决策树模型
self.tree = {}
def calcInfoGain(self, feature, label, index):
'''
计算信息增益
:param feature:测试用例中字典里的feature,类型为ndarray
:param label:测试用例中字典里的label,类型为ndarray
:param index:测试用例中字典里的index,即feature部分特征列的索引。该索引指的是feature中第几个特征,如index:0表示使用第一个特征来计算信息增益。
:return:信息增益,类型float
'''
# 计算熵
def calcInfoEntropy(label):
'''
计算信息熵
:param label:数据集中的标签,类型为ndarray
:return:信息熵,类型float
'''
# 注意需要把标签进行去重操作
label_set = set(label)
result = 0
for l in label_set:
count = 0
for j in range(len(label)):
if label[j] == l:
count += 1
# 计算标签在数据集中出现的概率
p = count / len(label)
# 计算熵
result -= p * np.log2(p)
return result
# 计算条件熵
def calcHDA(feature, label, index, value):
'''
计算信息熵
:param feature:数据集中的特征,类型为ndarray
:param label:数据集中的标签,类型为ndarray
:param index:需要使用的特征列索引,类型为int
:param value:index所表示的特征列中需要考察的特征值,类型为int
:return:信息熵,类型float
'''
count = 0
# sub_feature和sub_label表示根据特征列和特征值分割出的子数据集中的特征和标签
sub_feature = []
sub_label = []
for i in range(len(feature)):
if feature[i][index] == value:
count += 1
sub_feature.append(feature[i])
sub_label.append(label[i])
pHA = count / len(feature)
e = calcInfoEntropy(sub_label)
return pHA * e
base_e = calcInfoEntropy(label)
f = np.array(feature)
# 得到指定特征列的值的集合
f_set = set(f[:, index])
sum_HDA = 0
# 计算条件熵
for value in f_set:
sum_HDA += calcHDA(feature, label, index, value)
# 计算信息增益
return base_e - sum_HDA
# 获得信息增益最高的特征
def getBestFeature(self, feature, label):
max_infogain = 0
best_feature = 0
for i in range(len(feature[0])):
infogain = self.calcInfoGain(feature, label, i)
if infogain > max_infogain:
max_infogain = infogain
best_feature = i
return best_feature
def createTree(self, feature, label):
# 样本里都是同一个label没必要继续分叉了
if len(set(label)) == 1:
return label[0]
# 样本中只有一个特征或者所有样本的特征都一样的话就看哪个label的票数高
if len(feature[0]) == 1 or len(np.unique(feature, axis=0)) == 1:
vote = {}
for l in label:
if l in vote.keys():
vote[l] += 1
else:
vote[l] = 1
max_count = 0
vote_label = None
for k, v in vote.items():
if v > max_count:
max_count = v
vote_label = k
return vote_label
# 根据信息增益拿到特征的索引
best_feature = self.getBestFeature(feature, label)
tree = {best_feature: {}}
f = np.array(feature)
# 拿到bestfeature的所有特征值
f_set = set(f[:, best_feature])
# 构建对应特征值的子样本集sub_feature, sub_label
for v in f_set:
sub_feature = []
sub_label = []
for i in range(len(feature)):
if feature[i][best_feature] == v:
sub_feature.append(feature[i])
sub_label.append(label[i])
# 递归构建决策树
tree[best_feature][v] = self.createTree(sub_feature, sub_label)
return tree
# 训练
def fit(self, feature, label):
'''
:param feature: 训练集数据,类型为ndarray
:param label:训练集标签,类型为ndarray
:return: None
'''
self.tree = self.createTree(feature, label)
# 预测
def predict(self, feature):
'''
:param feature:测试集数据,类型为ndarray
:return:预测结果,如np.array([0, 1, 2, 2, 1, 0])
'''
result = []
# 分类
def classify(tree, feature):
if not isinstance(tree, dict):
return tree
t_index, t_value = list(tree.items())[0]
f_value = feature[t_index]
if isinstance(t_value, dict):
classLabel = classify(tree[t_index][f_value], feature)
return classLabel
else:
return t_value
for f in feature:
result.append(classify(self.tree, f))
return np.array(result)
信息增益率
信息增益率的数学定义为如下,其中D表示数据集,a表示数据集中的某一列,Gain(D,a)表示D中a的信息增益,V表示a这一列中取值的集合,v表示V中的某种取值,∣D∣表示D中样本的数量,∣Dv∣表示D中a这一列中值等于v的数量。
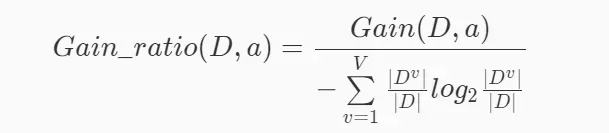
从公式可以看出,信息增益率很容易计算,只需将信息增益除以另一个分母,通常称为内在价值。
代码:
import numpy as np
def calcInfoGain(feature, label, index):
'''
计算信息增益
:param feature:测试用例中字典里的feature,类型为ndarray
:param label:测试用例中字典里的label,类型为ndarray
:param index:测试用例中字典里的index,即feature部分特征列的索引。该索引指的是feature中第几个特征,如index:0表示使用第一个特征来计算信息增益。
:return:信息增益,类型float
'''
# 计算熵
def calcInfoEntropy(label):
'''
计算信息熵
:param label:数据集中的标签,类型为ndarray
:return:信息熵,类型float
'''
# 同样对label去重
label_set = set(label)
result = 0
for l in label_set:
count = 0
for j in range(len(label)):
if label[j] == l:
count += 1
# 计算标签在数据集中出现的概率
p = count / len(label)
# 计算熵
result -= p * np.log2(p)
return result
# 计算条件熵
def calcHDA(feature, label, index, value):
'''
计算信息熵
:param feature:数据集中的特征,类型为ndarray
:param label:数据集中的标签,类型为ndarray
:param index:需要使用的特征列索引,类型为int
:param value:index所表示的特征列中需要考察的特征值,类型为int
:return:信息熵,类型float
'''
count = 0
# sub_feature和sub_label表示根据特征列和特征值分割出的子数据集中的特征和标签
sub_feature = []
sub_label = []
for i in range(len(feature)):
if feature[i][index] == value:
count += 1
sub_feature.append(feature[i])
sub_label.append(label[i])
pHA = count / len(feature)
e = calcInfoEntropy(sub_label)
return pHA * e
base_e = calcInfoEntropy(label)
f = np.array(feature)
# 得到指定特征列的值的集合
f_set = set(f[:, index])
sum_HDA = 0
# 计算条件熵
for value in f_set:
sum_HDA += calcHDA(feature, label, index, value)
# 计算信息增益
return base_e - sum_HDA
def calcInfoGainRatio(feature, label, index):
'''
计算信息增益率
:param feature:测试用例中字典里的feature,类型为ndarray
:param label:测试用例中字典里的label,类型为ndarray
:param index:测试用例中字典里的index,即feature部分特征列的索引。该索引指的是feature中第几个特征,如index:0表示使用第一个特征来计算信息增益。
:return:信息增益率,类型float
'''
info_gain = calcInfoGain(feature, label, index)
unique_value = list(set(feature[:, index]))
IV = 0
for value in unique_value:
len_v = np.sum(feature[:, index] == value)
IV -= (len_v/len(feature))*np.log2((len_v/len(feature)))
return info_gain/IV
基尼系数
在ID3算法中我们使用了信息增益来选择特征,信息增益大的优先选择。在C4.5算法中,采用了信息增益率来选择特征,以减少信息增益容易选择特征值多的特征的问题。但是无论是ID3还是C4.5,都是基于信息论的熵模型的,这里面会涉及大量的对数运算。能不能简化模型同时也不至于完全丢失熵模型的优点呢?——基尼系数。
基尼系数的数学定义,其中D表示数据集,pk 表示D中第k个类别在D中所占比例。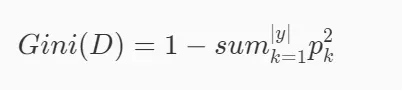
基尼系数越小,杂质越少,特性越好。
import numpy as np
def calcGini(feature, label, index):
'''
计算基尼系数
:param feature:测试用例中字典里的feature,类型为ndarray
:param label:测试用例中字典里的label,类型为ndarray
:param index:测试用例中字典里的index,即feature部分特征列的索引。该索引指的是feature中第几个特征,如index:0表示使用第一个特征来计算信息增益。
:return:基尼系数,类型float
'''
def _gini(label):
# 先对label去重然后再化为列表形式
unique_label = list(set(label))
gini = 1
for l in unique_label:
p = np.sum(label == l)/len(label)
gini -= p**2
return gini
# 列出指定的特定列
unique_value = list(set(feature[:, index]))
gini = 0
for value in unique_value:
len_v = np.sum(feature[:, index] == value)
gini += (len_v/len(feature))*_gini(label[feature[:, index] == value])
return gini
修剪
决策树的一个缺点是它们很容易过拟合。在构建决策树的过程中,会过多考虑如何提高训练集中数据的分类精度,从而构建出非常复杂的决策树(树的宽度和深度)。更大)。前面训练提到过,模型的复杂度越高,越容易过拟合。因此,简化决策树的复杂度可以有效缓解过拟合现象,最常用的简化决策树的方法就是剪枝。
预修剪
预剪枝的核心思想是,在决策树生成过程中,每个节点在被划分之前都要进行评估。如果当前节点的划分不能提高决策树的泛化性能,则停止划分,对当前节点进行划分。点被标记为叶节点。
可以随机取一部分训练数据集作为验证数据集,然后用当前状态的决策树计算验证数据集上的正确率,再用训练数据集划分每个节点。正确率越高,决策树的泛化性能越好。如果在划分节点时发现泛化性能下降或没有提高,则意味着停止划分,并通过投票计数将当前节点标记为叶子。节点。
后修剪
后剪枝是先从训练集中生成一棵完整的决策树,然后自下而上检查非叶子节点。如果将节点对应的子树替换为叶子节点,则可以推广决策树。要提高性能,请将子树替换为叶节点。
(Theory should be combined with practice!)
来源:头曲
文章出处登录后可见!