
自然语言处理(Natural Language Processing,NLP)领域内的预训练语言模型,包括基于RNN的ELMo和ULMFiT,基于Transformer的OpenAI GPT及Google BERT等。预训练语言模型的成功,证明了我们可以从海量的无标注文本中学到潜在的语义信息,而无需为每一项下游NLP任务单独标注大量训练数据。
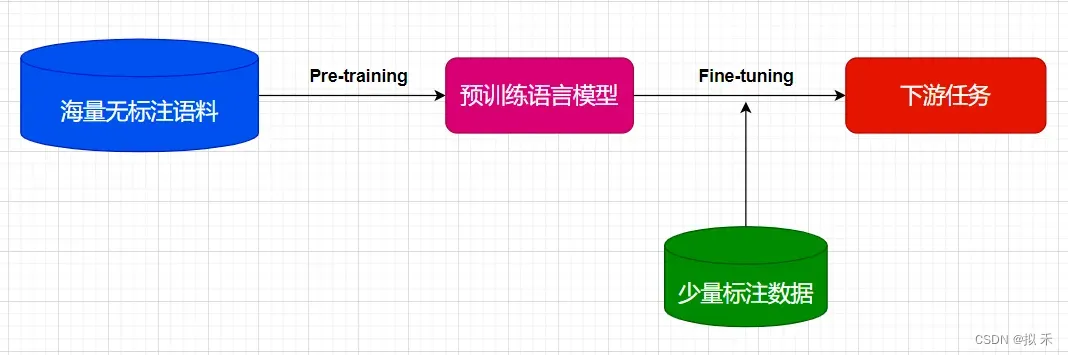
此外,预训练语言模型的成功也开创了NLP研究的新范式,如上图所示,即首先使用大量无监督语料进行语言模型预训练(Pre-training),再使用少量标注语料进行微调(Fine-tuning)来完成具体NLP任务(分类、序列标注、句间关系判断和机器阅读理解等)。
1 Abstract🌺
- 我们引入了一种新的语言表征模型BERT,即Bidirectional Encoder Representations from Transformers(来自Transformers的双向编码器表示)。与最近的语言表征模型不同(ELMo和GPT),BERT旨在通过考虑未标记文本的左右(即双向)上下文(context)来预训练文本的深度双向表征。因此,只需要一个额外的输出层,就可以对预训练的BERT模型进行微调,从而为各种任务(如问题回答和语言推断)创建最先进的模型,而无需对特定于任务的体系结构进行实质性修改。
- BERT在概念上很简单,在实验上很强大。它在11个自然语言处理任务上获得了最新的结果,包括将GLUE得分推至80.5%(绝对提高7.7%),将多MultiNLI accuracy推至86.7%(绝对提高4.6%),将SQuAD v1.1问答测试F1推至93.2(绝对提高1.5分),将SQuAD v2.0测试F1推至83.1(绝对提高5.1分)。
2 Conclusion🌲
最近由于语言模型在迁移学习(transfer learning)上的实验改进表明,丰富的、无监督的预训练是许多语言理解系统不可分割的一部分。特别是,这些结果使低资源任务也能从深度单向架构中受益。我们的主要贡献是将这些发现进一步推广到深度双向架构,允许相同的预训练模型成功解决广泛的NLP任务。
3 Introduction🌷
- 所谓的“预训练”,其实并不是什么新概念,这种“Pre-training and Fine-tuning”的方法在图像领域早有应用。2009年,邓嘉、李飞飞等人在CVPR 2009发布了ImageNet数据集,其中120万张图像分为1000个类别。基于ImageNet,以图像分类为目标使用深度卷积神经网络(如常见的ResNet、VCG、Inception等)进行预训练,得到的模型称为预训练模型。针对目标检测或者语义分割等任务,基于这些预训练模型,通过一组新的全连接层与预训练模型进行拼接,利用少量标注数据进行微调,将预训练模型学习到的图像分类能力迁移到新的目标任务。预训练的方式在图像领域取得了广泛的成功,比如有学者将ImageNet上学习得到的特征表示用于PSACAL VOC上的物体检测,将检测率提高了20%。
- 图像领域预训练的成功也启发了NLP领域研究,深度学习时代广泛使用的词向量(即词嵌入,Word Embedding)即属于NLP预训练工作。使用深度神经网络进行NLP模型训练时,首先需要将待处理文本转为词向量作为神经网络输入,词向量的效果会影响到最后模型效果。词向量的效果主要取决于训练语料的大小,很多NLP任务中有限的标注语料不足以训练出足够好的词向量,通常使用跟当前任务无关的大规模未标注语料进行词向量预训练,因此预训练的另一个好处是能增强模型的泛化能力。目前,大部分NLP深度学习任务中都会使用预训练好的词向量(如Word2Vec和GloVe等)进行网络初始化(而非随机初始化),从而加快网络的收敛速度。
- 预训练词向量通常只编码词汇间的关系,对上下文信息考虑不足,且无法处理一词多义问题。如“bank”一词,根据上下文语境不同,可能表示“银行”,也可能表示“岸边”,却对应相同的词向量,这样显然是不合理的。为了更好的考虑单词的上下文信息,Context2Vec使用两个双向长短时记忆网络(Long Short Term Memory,LSTM)来分别编码每个单词左到右(Left-to-Right)和右到左(Right-to-Left)的上下文信息。类似地,ELMo也是基于大量文本训练深层双向LSTM网络结构的语言模型。ELMo在词向量的学习中考虑深层网络不同层的信息,并加入到单词的最终Embedding表示中,在多个NLP任务中取得了提升。ELMo这种使用预训练语言模型的词向量作为特征输入到下游目标任务中,被称为Feature-based方法。
- 另一种方法是微调(Fine-tuning)。GPT(只考虑单向的语义信息)、BERT和后续的预训练工作都属于这一范畴,直接在深层Transformer网络上进行语言模型训练,收敛后针对下游目标任务进行微调,不需要再为目标任务设计Task-specific网络从头训练。
4 BERT🍄
BERT是基于Transformer的深度双向语言表征模型,基本结构下图所示,本质上是利用Transformer结构构造了一个多层双向的Encoder网络。Transformer是Google在2017年提出的基于自注意力机制(Self-attention)的深层模型,在包括机器翻译在内的多项NLP任务上效果显著,超过RNN且训练速度更快。Transformer已经取代RNN成为神经网络机器翻译的State-Of-The-Art(SOTA)模型,关于Transformer的详细介绍可以参考这篇博文:http://t.csdn.cn/A5BOP
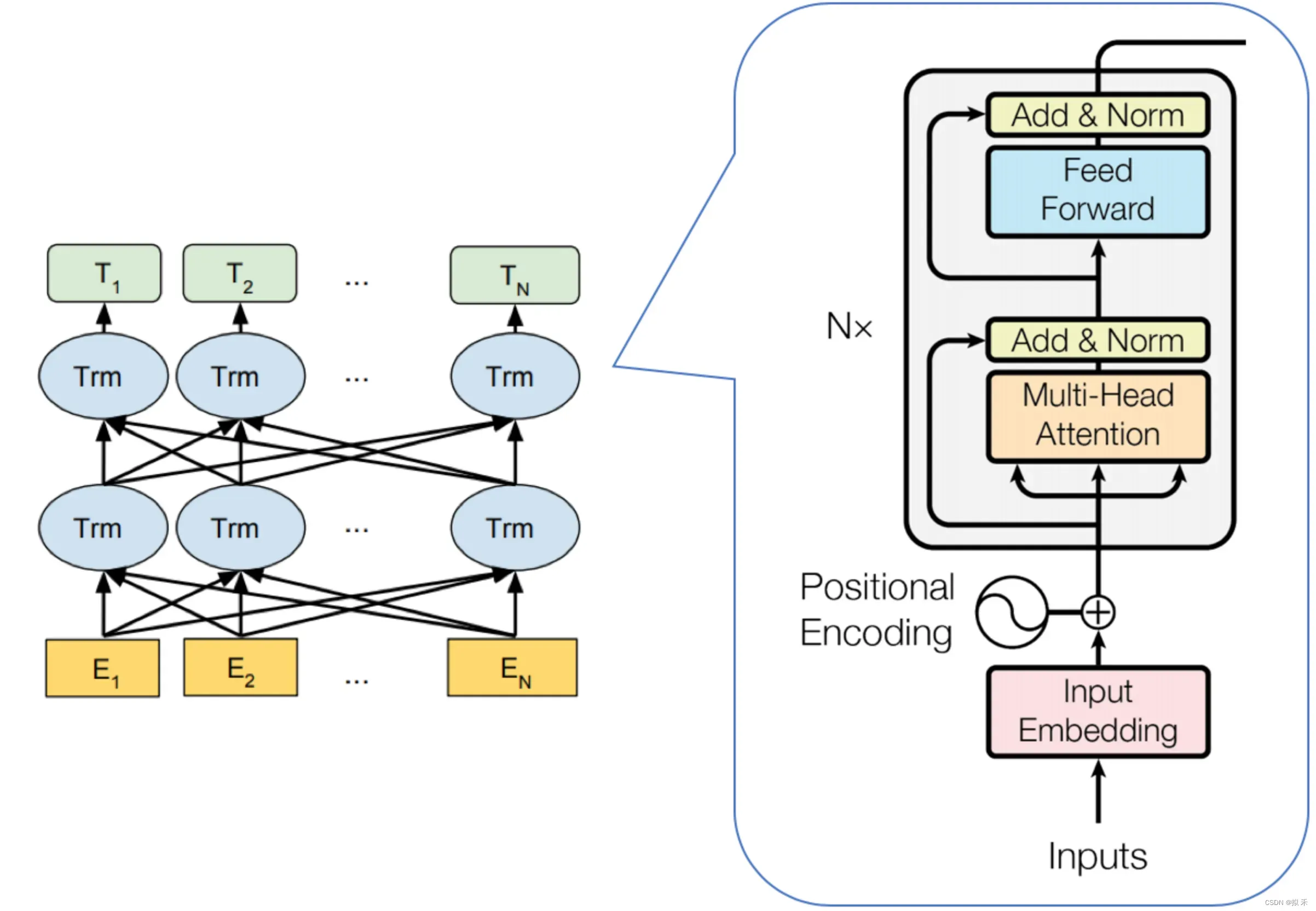
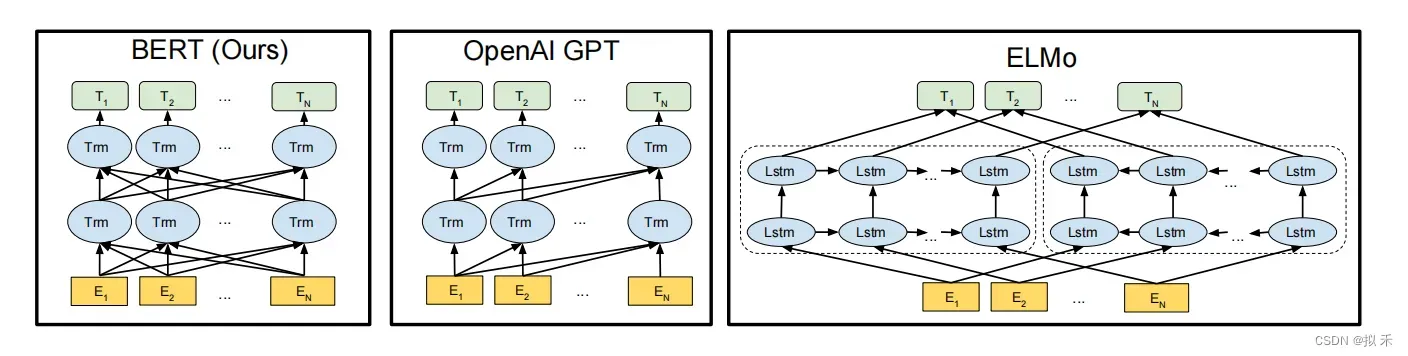
- 预训练模型架构的差异如下图所示。BERT使用双向Transformer。OpenAI GPT使用从左到右的Transformer。ELMo使用独立训练的从左到右和从右到左lstm的连接来为下游任务生成特征。
- 在这三种表示中,只有BERT表示同时以所有层中的左右上下文为条件。除了架构差异之外,BERT和OpenAI GPT是一种Fine-tuning方法,而ELMo是一种Feature-based的方法。
4.1 Architecture🌱
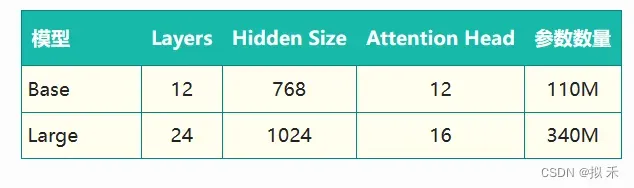
如下表所示,根据参数设置的不同,Google 论文中提出了Base和Large两种BERT模型。
5 Input Representations🌴
- 我们使用带有30000个token词汇表的WordPiece embeddings。每个序列的第一个标记总是一个特殊的分类标记([CLS])。
- 句子对被打包成一个序列。我们用两种方法来区分这些句子。首先,我们用一个特殊的标记([SEP])将它们分开。其次,我们为每个标记添加一个学习嵌入,表明它属于句子a还是句子b。
- CLS = Classification
- SEP = Separate
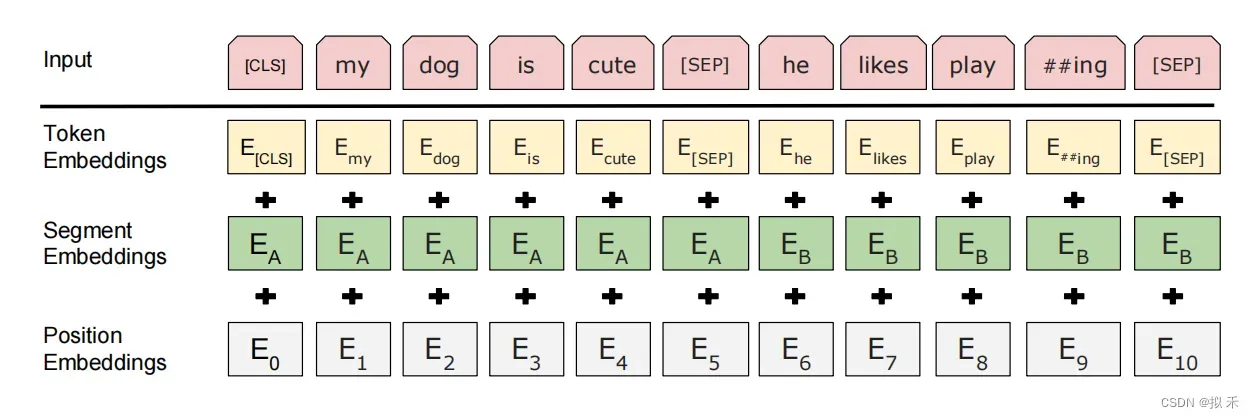
- 针对不同的任务,BERT模型的输入可以是单句或者句对。对于每一个输入的Token,它的表征由其对应的词表征(Token Embedding)、段表征(Segment Embedding)和位置表征(Position Embedding)相加产生,如上图所示。
- 对于英文模型,使用了Wordpiece模型来产生Subword从而减小词表规模;对于中文模型,直接训练基于字的模型。
- 模型输入需要附加一个起始Token,记为[CLS],对应最终的Hidden State(即Transformer的输出)可以用来表征整个句子,用于下游的分类任务。
- 模型能够处理句间关系。为区别两个句子,用一个特殊标记符[SEP]进行分隔,另外针对不同的句子,将学习到的Segment Embeddings 加到每个Token的Embedding上。
- 对于单句输入,只有一种Segment Embedding;对于句对输入,会有两种Segment Embedding。
6 Pre-training🌳
BERT预训练过程包含两个不同的预训练任务,分别是Masked Language Model和Next Sentence Prediction任务。
6.1 Masked Language Model🌏
通过随机掩盖一些词(替换为统一标记符[MASK]),然后预测这些被遮盖的词来训练双向语言模型,并且使每个词的表征参考上下文信息(完型填空)。这样做会产生两个缺点:
- 会造成预训练和微调时的不一致,因为在微调时[MASK]总是不可见的;
- 由于每个Batch中只有15%的词会被预测,因此模型的收敛速度比起单向的语言模型会慢,训练花费的时间会更长。对于第一个缺点的解决办法是,把80%需要被替换成[MASK]的词进行替换,10%的随机替换为其他词,10%保留原词。由于Transformer Encoder并不知道哪个词需要被预测,哪个词是被随机替换的,这样就强迫每个词的表达需要参照上下文信息。对于第二个缺点目前没有有效的解决办法,但是从提升收益的角度来看,付出的代价是值得的。
例如:
- 80%为特殊的“<mask>”词元(例如,“this movie is great”变为“this movie is<mask>”);
- 10%为随机替换词元(例如,“this movie is great”变为“this movie is drink”);
- 10%为不变的标签词元(例如,“this movie is great”变为“this movie is great”)。
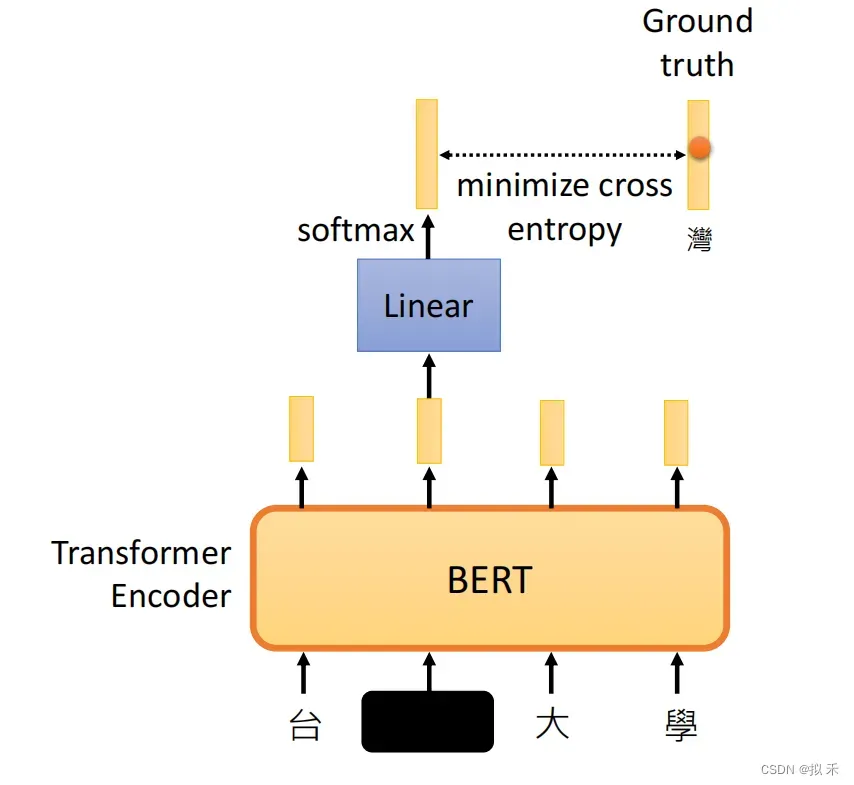
例如上面我们可以把“台湾大学”的“湾”盖住,对模型进行预训练。
6.2 Next Sentence Prediction🎄
- 为了训练一个理解句子间关系的模型,引入一个下一句预测任务。这一任务的训练语料可以从语料库中抽取句子对包括两个句子A和B来进行生成,其中50%的概率B是A的下一个句子,50%的概率B是语料中的一个随机句子。NSP任务预测B是否是A的下一句。NSP的目的是获取句子间的信息,这点是语言模型无法直接捕捉的。
- Google的论文结果表明,这个简单的任务对问答和自然语言推理任务十分有益,但是后续一些新的研究发现,去掉NSP任务之后模型效果没有下降甚至还有提升。我们在预训练过程中也发现NSP任务的准确率经过1-2个Epoch训练后就能达到98%-99%,去掉NSP任务之后对模型效果并不会有太大的影响。
7 Fine-tuning🚩
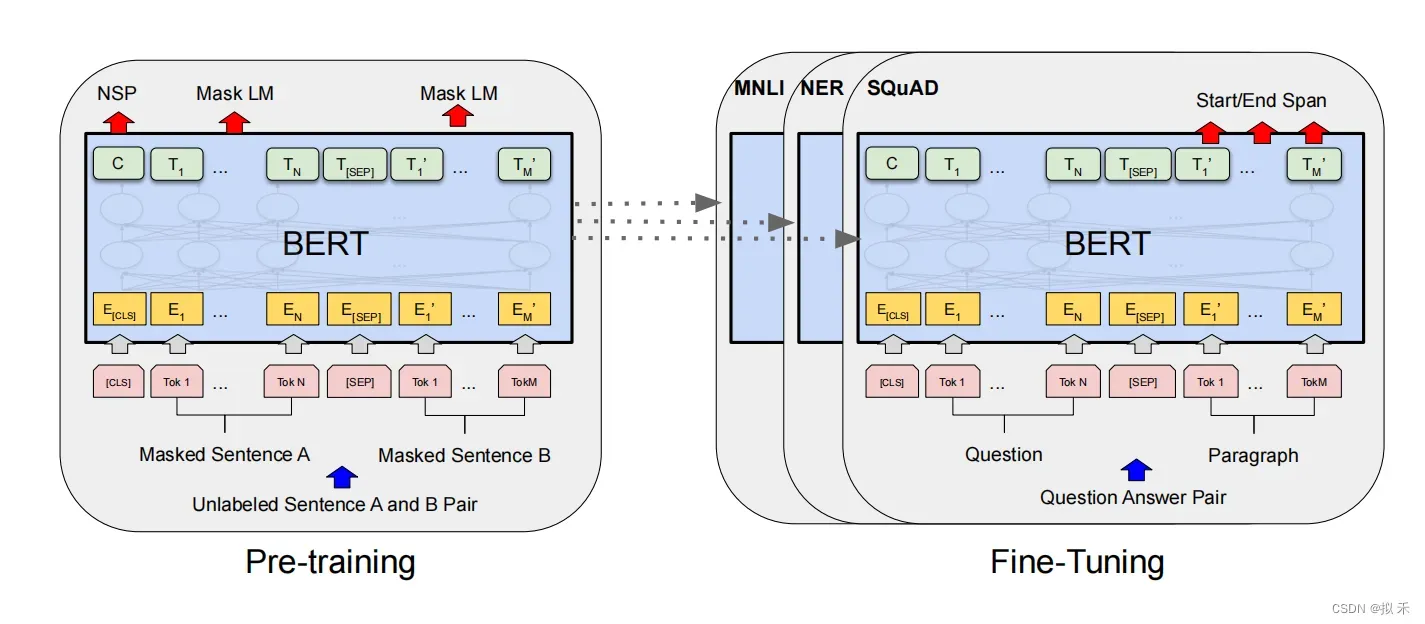
- 除了输出层之外,在预训练和微调中也使用了相同的架构。相同的预训练模型参数用于初始化不同下游任务(downstream tasks)的模型。在微调过程中,对所有参数进行微调,BERT对每一个词元(token)返回抽取了上下文信息的特征向量。
- 即使下游任务各有不同,使用BERT微调时均只需要增加输出层,但根据任务的不同,输入的表示,和使用的BERT特征也会不一样。
7.1 Text Classifification🚀
Single Text Classifification(单文本分类)
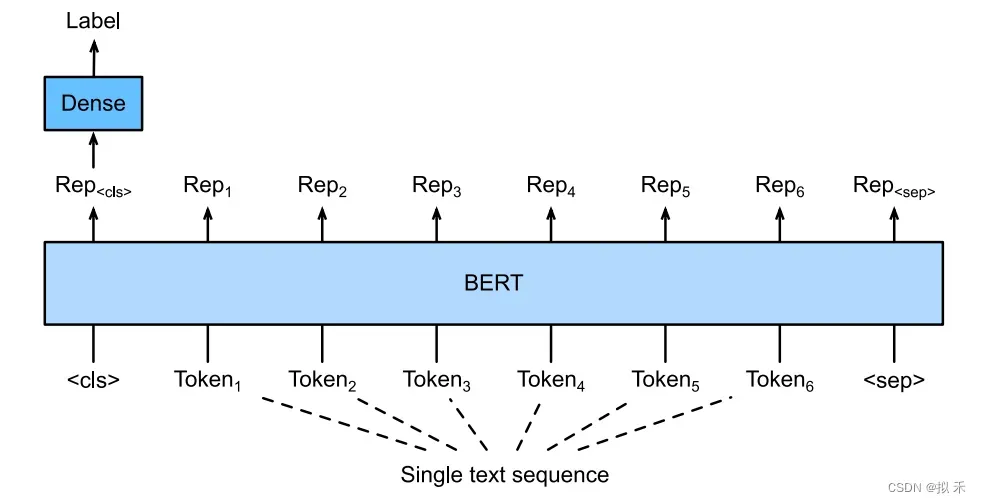
Text Pair Classifification(文本对分类)
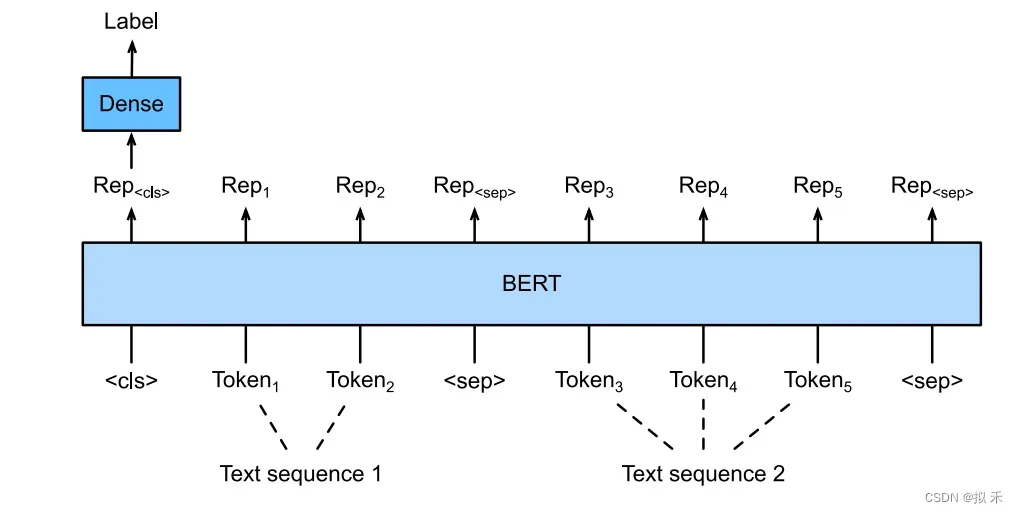
上面的两种情况要求模型输入需要附加一个起始Token,记为[CLS],对应最终的Hidden State(即Transformer的输出)可以用来表征整个句子,用于下游的分类任务。就是将[CLS]对应的向量输入到全连接层进行分类。
7.2 Text Tagging✈️
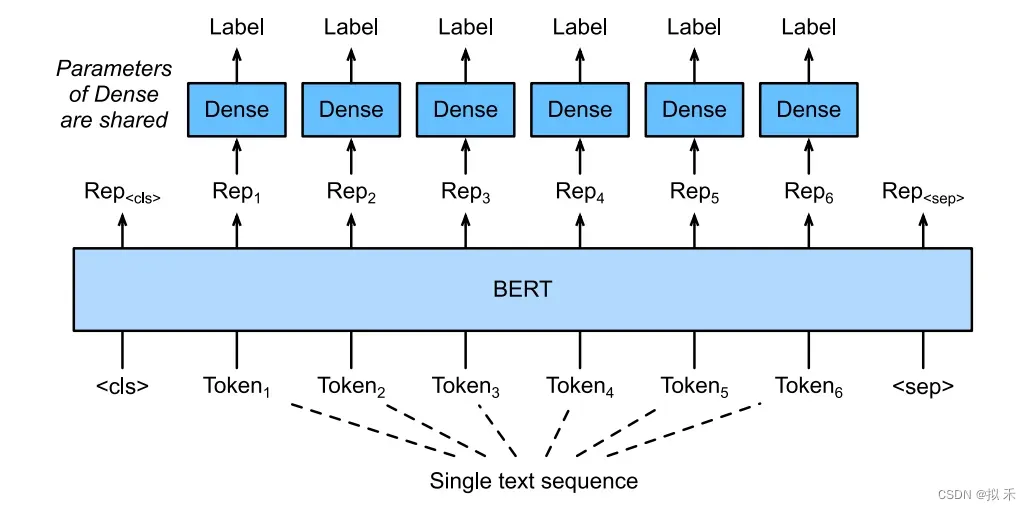
为了识别一个词元是不是命名实体,例如人名、机构、位置,可以将非特殊词元放进全连接层进行分类。
7.3 Question Answering🍉
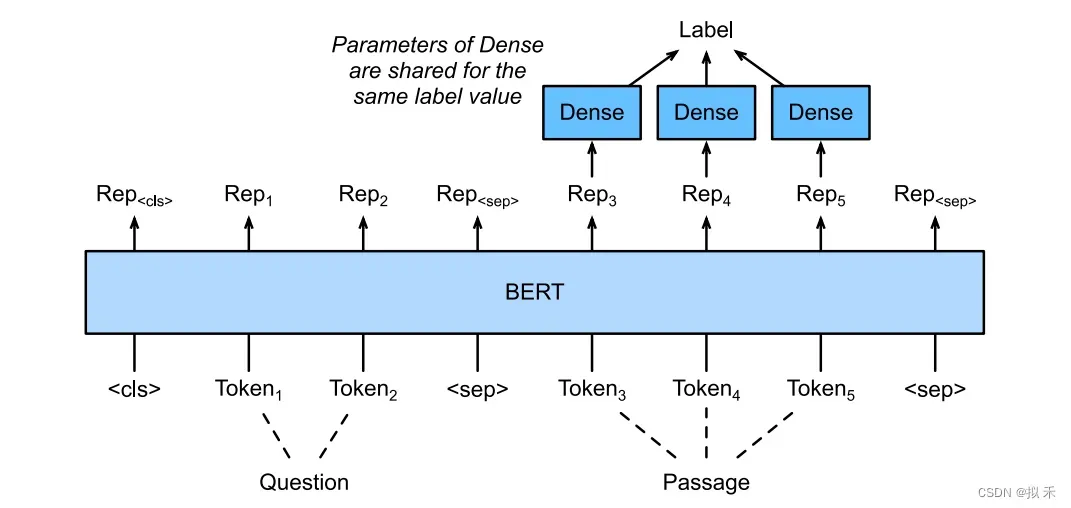
给定一个问题,和描述文字,找出一个片段作为回答,对片段中的每个词元预测它是不是回答的开头或结束,然后返回两个整数分别表示开始和结束是给定描述文字第几个词,所以开始和结束(包括自身)中间的部分就是答案啦。
8 My View🍗
- 显然BERT模型的应用范围不止于此,并且BERT模型也只是一个新的开端。
- 在BERT模型发布以后,很多类似BERT的模型不断被推出,不断刷新着NLP任务的新纪录,NLP领域也因此迎来了新一轮的快速发展。
- ELMo双向编码上下文,但使用特定于任务(task-specifific)的架构;而GPT是与任务无关的(task-agnostic ),但从左到右编码上下文。BERT可以对上下文进行双向编码,并需要对广泛的自然语言处理任务进行最小的架构更改。使用预先训练的Transformer encoder,BERT能够基于其双向上下文表示任何词元。在下游任务的监督学习过程中,BERT与GPT在两个方面相似。首先,BERT表示将被输入到一个添加的输出层中,根据任务的性质对模型体系结构进行最小的更改,例如对每个词元的预测和对整个序列的预测。其次,对预训练后的Transformer encoder的所有参数都进行了微调,而额外的输出层将从头开始进行训练。这种 A + B (把两个最好的结合起来)的思想值得借鉴。
文章出处登录后可见!