算法背景:
传统的人工神经网络基本只有输入层、隐藏层、以及输出层。随着大数据时代的来临以及GPU算力的提升,更加深层的神经网络出现了,使得人工智能进入深度学习时代。更深层的神经网络相比较于浅层的神经网络来说特征提取能力更强了,但训练权值的拟合也愈加困难。
梯度下降算法经常用来完成神经网络的训练以及拟合优化,梯度下降算法会影响网络训练的速度和精度,而Adagrad算法是一种比较不错的梯度下降算法。
Adagrad算法
Adagrad优化算法被称为自适应学习率优化算法,之前我们讲的随机梯度下降对所有的参数都使用的固定的学习率进行参数更新,但是不同的参数梯度可能不一样,所以需要不同的学习率才能比较好的进行训练,但是这个事情又不能很好地被人为操作,所以 Adagrad 便能够帮助我们做这件事。
如下图所示,是几种不同梯度下降算法的梯度下降过程,其中五角星为最佳点: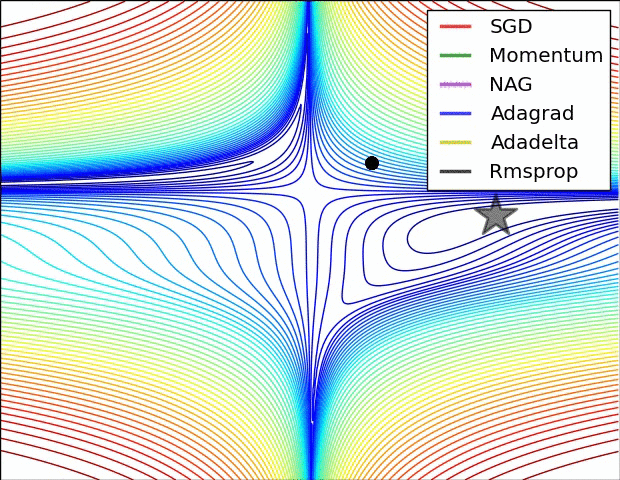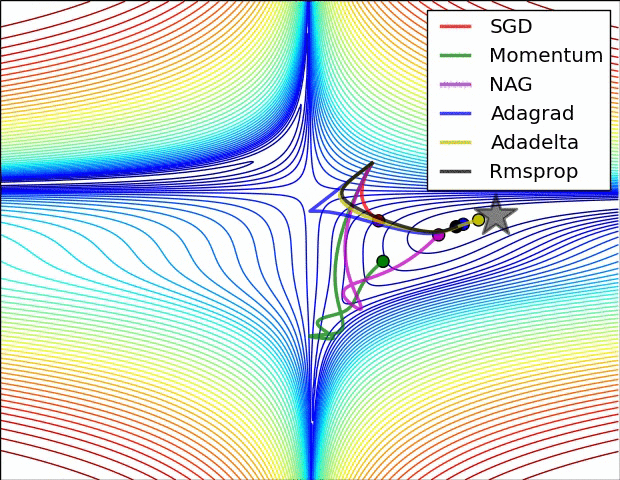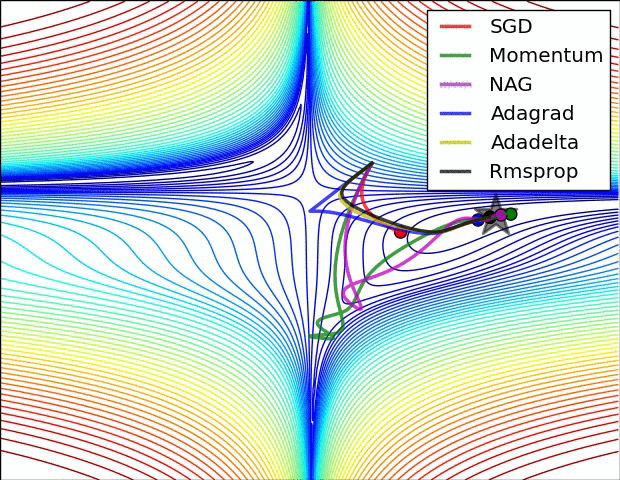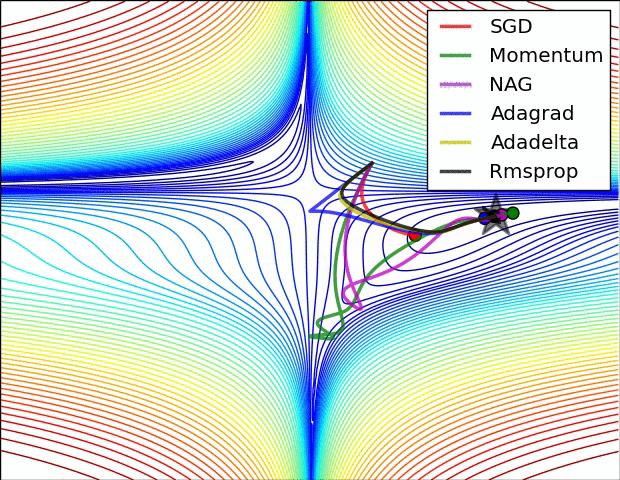
算法过程:
Adagrad优化算法就是在每次使用一个 batch size 的数据进行参数更新的时候,算法计算所有参数的梯度,那么其想法就是对于每个参数,初始化一个变量 s 为 0,然后每次将该参数的梯度平方求和累加到这个变量 s 上,然后在更新这个参数的时候,学习率就变为: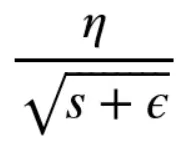
如上为Adagrad算法的公式
首先η为初始学习率,这里的 ϵ是为了数值稳定性而加上的,因为有可能 s 的值为 0,那么 0 出现在分母就会出现无穷大的情况,通常 ϵ 取 10的负10次方,这样不同的参数由于梯度不同,他们对应的 s 大小也就不同,所以上面的公式得到的学习率也就不同,这也就实现了自适应的学习率。
使用自适应学习率可以帮助算法在梯度大的参数方向减慢学习率,在梯度小的参数方向加快学习率,可以加快神经网络的训练速度.
算法代码实现:
def sgd_adagrad(parameters, sqrs, lr):
eps = 1e-10
for param, sqr in zip(parameters, sqrs):
sqr[:] = sqr + param.grad.data ** 2
div = lr / torch.sqrt(sqr + eps) * param.grad.data
param.data = param.data - div
算法总结:
Adagrad 的核心想法就是,如果一个参数的梯度一直都非常大,那么其对应的学习率就变小一点,防止震荡,而一个参数的梯度一直都非常小,那么这个参数的学习率就变大一点,使得其能够更快地更新,这就是Adagrad算法加快深层神经网络的训练速度的核心。
参考:
论文:[1] Duchi, J., Hazan, E., & Singer, Y. (2011). Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research, 12(Jul), 2121-2159.
实践学习的深度:
https://tangshusen.me/Dive-into-DL-PyTorch/#/chapter07_optimization/7.5_adagrad
文章出处登录后可见!