
🌠 『精品学习专栏导航帖』
- 🐳最适合入门的100个深度学习实战项目🐳
- 🐙【PyTorch深度学习项目实战100例目录】项目详解 + 数据集 + 完整源码🐙
- 🐶【机器学习入门项目10例目录】项目详解 + 数据集 + 完整源码🐶
- 🦜【机器学习项目实战10例目录】项目详解 + 数据集 + 完整源码🦜
- 🐌Java经典编程100例🐌
- 🦋Python经典编程100例🦋
- 🦄蓝桥杯历届真题题目+解析+代码+答案🦄
- 🐯【2023王道数据结构目录】课后算法设计题C、C++代码实现完整版大全🐯
文章目录
- 一、基于逻辑回归方法完成垃圾邮件过滤任务
- 1、✌ 任务描述
- 2、✌ 数据集
- 3、✌ 方法概述
- 4、✌ 数据可视化及数据预处理
- 4.1 ✌ 读取数据
- 4.2 ✌ 数据分析
- 4.3 ✌ 数据可视化
- 4.4 ✌ 数据预处理
- 4.5 ✌ 数据集划分和向量化
- ✌ CountVectorizer统计词频矩阵
- 5、✌ 模型训练
- 5.1 ✌ 加载模型
- 5.2 ✌ 训练模型
- 5.3 ✌ 预测结果
- 6、✌ 模型评估
- 6.1 ✌ 测试集准确率
- 6.2 ✌ 不同分类器的结果分析
- 6.3 ✌ 预测结果展示
一、基于逻辑回归方法完成垃圾邮件过滤任务
1、✌ 任务描述
我们日常学习以及工作中会收到非常多的邮件,除了与学习工作相关的邮件,还会收到许多垃圾邮件,包括广告邮件、欺诈邮件等等。本任务通过邮件中包含的文本内容来判断该邮件是正常邮件(ham)还是垃圾邮件(spam),来实现自动化垃圾邮件过滤,是一种典型的文本分类任务。
2、✌ 数据集
该数据集包含5574条邮件,所有邮件都被标记为正常邮件(ham)或者垃圾邮件(spam)。
3、✌ 方法概述
4、✌ 数据可视化及数据预处理
下载下来的数据集是csv格式的,每条数据有两列,分别是文本内容和对应的标签(ham or spam)。我们首先利用python的pandas库读取csv文件中的数据,然后先对数据进行简单分析,然后对数据进行预处理,最后是将文本内容向量化,文本向量化后才可以利用算法模型进行文本分类任务。整体步骤总结如下:
- (1)读取数据
- (2)数据分析
- (3)数据可视化
- (4)数据预处理
- (5)数据向量化
4.1 ✌ 读取数据
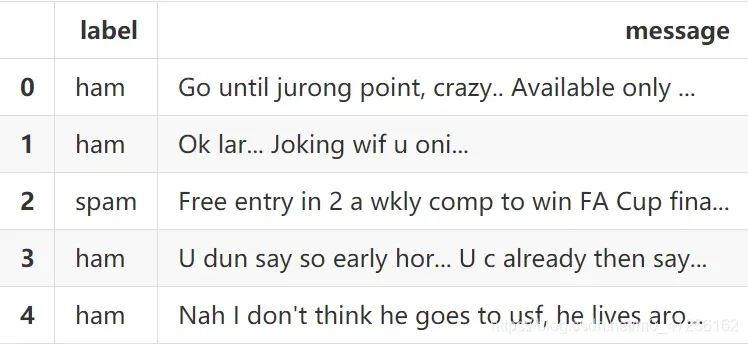
我们首先通过pandas工具包的read_csv()方法来读取csv格式的数据集文件,读取为dataframe格式的数据
通过dropna去除掉其中为空值的数据
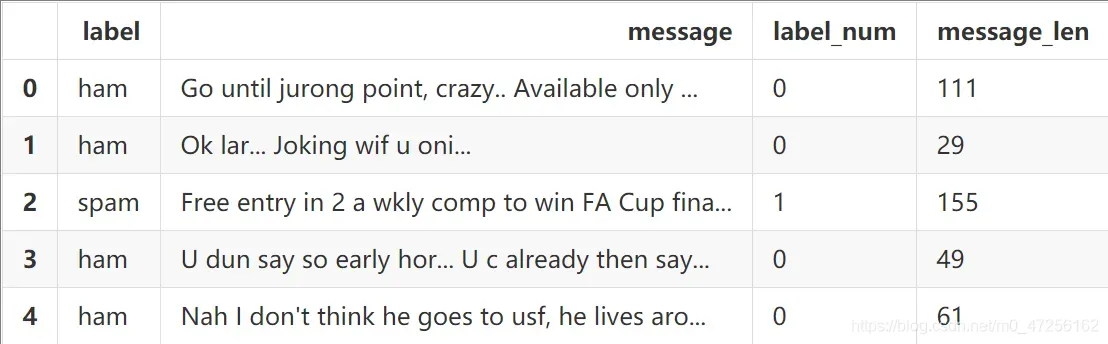
通过head()方法来查看dataframe中的前五条数据
可以看到每条训练数据都有对应的标签label和对应的文本内容message。
import pandas as pd
sms=pd.read_csv('data.csv',encoding='latin-1')
sms=sms[['v1','v2']]
sms.columns=['label','message']
sms.head()
4.2 ✌ 数据分析
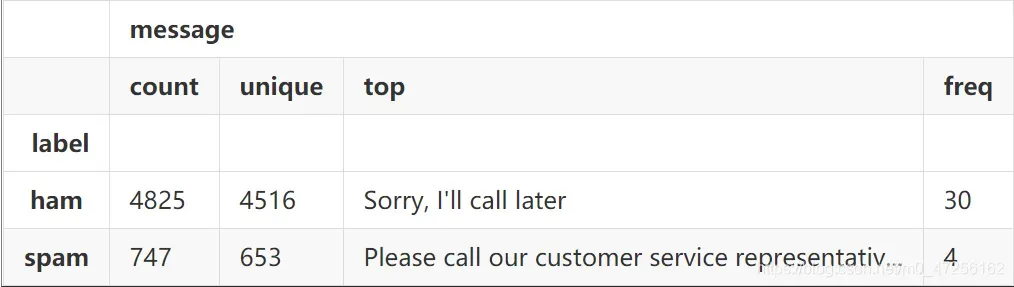
利用groupby()方法来组合ham类和spam类的数据,然后通过describe()方法来查看基本统计数据;可以看到ham类一共有4825条数据,非重复数据有4516条;spam类一共有747条数据,非重复数据一共有653条
sms.groupby('label').describe()
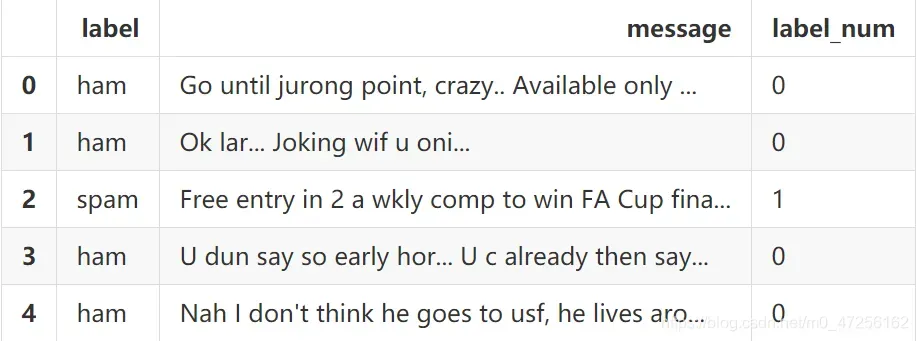
将标签数值化,进行算法模型训练
sms['label_num']=sms.label.map({'ham':0,'spam':1})
sms.head()
统计每条数据中的message的文本长度
sms['message_len']=sms.message.map(len)
sms.head()
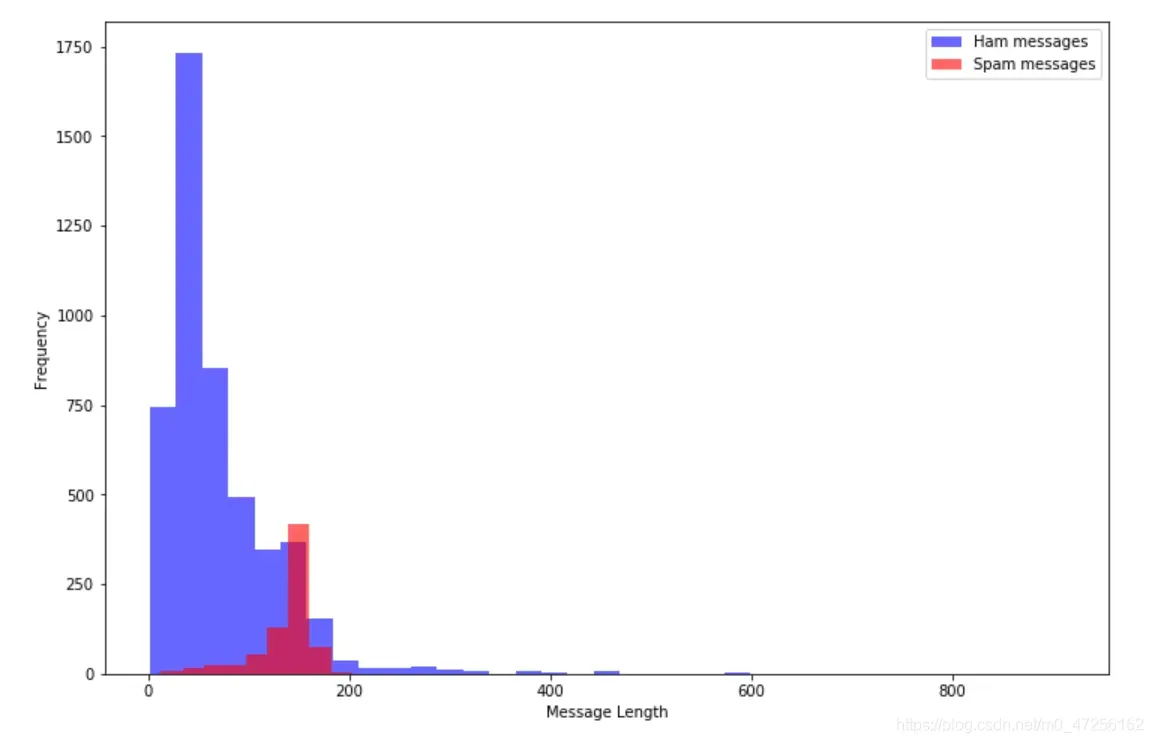
4.3 ✌ 数据可视化
import matplotlib.pyplot as plt
sms[sms.label=='ham'].message_len.plot(bins=35,kind='hist',color='blue',label='Ham Message',alpha=0.6)
sms[sms.label=='spam'].message_len.plot(kind='hist',color='red',label='Spam Message',alpha=0.6)
plt.legend()
plt.xlabel('Message Length')
import seaborn as sns
sns.histplot(sms[sms.label=='ham'].message_len,bins=35,color='blue')
sns.histplot(sms[sms.label=='spam'].message_len,bins=35,color='red')
4.4 ✌ 数据预处理
文本预处理是自然语言处理中的关键步骤,在本案例中本文预处理包括:1、移除所有标点符号;2、移除所有的通用词,如”the”, “a”等。在正常邮件和垃圾邮件中,标点符号和通用词汇的数量和类型是相似的,因此这些文本内容并不能起很好的区分作用,属于“无关特征”,需要利用预处理的手段将这些无关特征移除。
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
stopword=stopwords.words('english')
import string
def text_process(message):
string_message=[char for char in message if char not in string.punctuation]
string_message=''.join(string_message)
return ' '.join([word for word in string_message.split() if word not in stopword+['u', 'ü', 'ur', '4', '2', 'im', 'dont', 'doin', 'ure']])
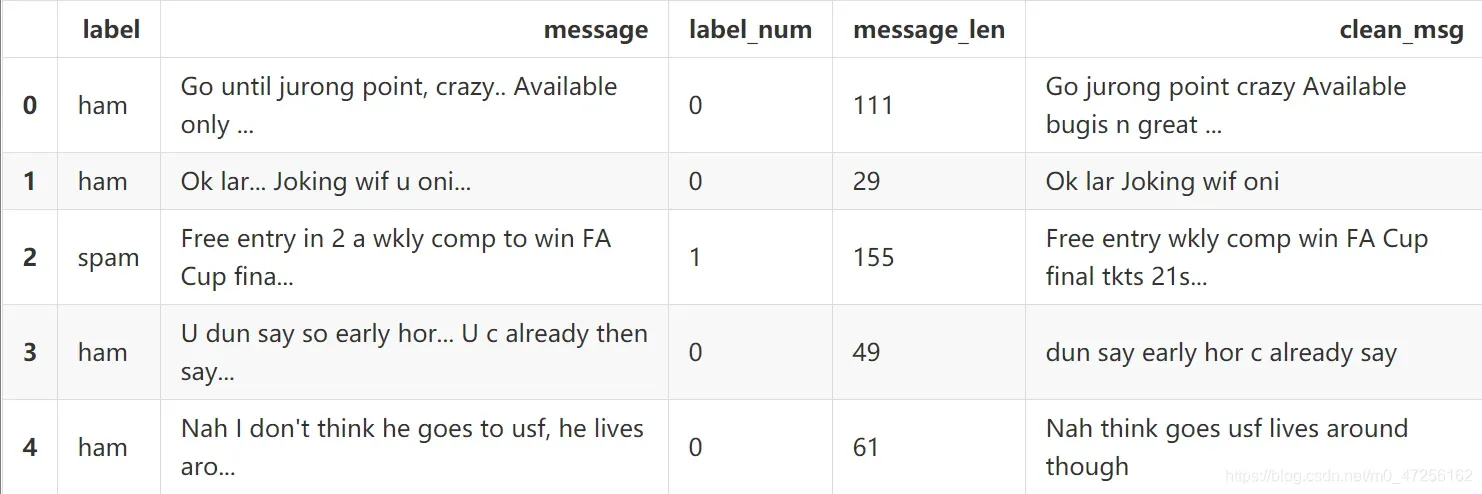
利用map()方法将上面定义的函数应用到数据中message中,得到预处理后的数据clean_msg。
sms['clean_msg'] = sms.message.map(text_process)
sms.head()
4.5 ✌ 数据集划分和向量化
x=sms.clean_message
y=sms.label
✌ CountVectorizer统计词频矩阵
在词袋模型统计词频的时候,可以使用sklearn中的CountVectorizer来完成。
CountVectorizer类会将文本中的词语转换为词频矩阵,例如矩阵中包含一个元素a[i][j],它表示j词在i类文本下的词频。它通过fit_transform函数首先统计有多少词语出现,然后计算词语出现的次数,形成词频矩阵。训练集用fit_transform方法,测试集用transfrom方法。
from sklearn.feature_extraction.text import CountVectorizer
x=CountVectorizer().fit_transform(x)
# from sklearn.feature_extraction.text import TfidfTransformer
# x=TfidfTransformer().fit_transform(x)
利用sklearn工具中的train_test_split方法将数据划分为训练集和测试集。
利用该方法划分可以保证训练集和测试集有一致的分布(不同类别的数据比例相近)。
其中random_state用来指定随机种子,保证每次划分的训练集和测试集都是一样的。
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3)
5、✌ 模型训练
在完成数据预处理以及向量化后,接下来就是构建算法模型,完成模型的训练和结果预测,整体流程如下:
- (1)加载模型
- (2)训练模型
- (3)预测结果
5.1 ✌ 加载模型
from sklearn.metrics import accuracy_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
import lightgbm as lgb
from sklearn.svm import SVC
5.2 ✌ 训练模型
clf_dtc=DecisionTreeClassifier()
clf_dtc.fit(x_train,y_train)
score_dtc=accuracy_score(y_test,clf_dtc.predict(x_test))
clf_rfc=RandomForestClassifier(n_estimators=200)
clf_rfc.fit(x_train,y_train)
score_rfc=accuracy_score(y_test,clf_rfc.predict(x_test))
clf_log=LogisticRegression(solver='liblinear')
clf_log.fit(x_train,y_train)
score_log=accuracy_score(y_test,clf_log.predict(x_test))
clf_svc=SVC(kernel='sigmoid', gamma=1.0)
clf_svc.fit(x_train,y_train)
score_svc=accuracy_score(y_test,clf_svc.predict(x_test))
# clf_lgb=lgb.LGBMClassifier()
# clf_lgb.fit(x_train,y_train)
# score_lgb=accuracy_score(y_test,clf_lgb.predict(x_test))
print(score_dtc,score_rfc,score_log,score_svc)
5.3 ✌ 预测结果
score_dtc=accuracy_score(y_test,clf_dtc.predict(x_test))
score_rfc=accuracy_score(y_test,clf_rfc.predict(x_test))
score_log=accuracy_score(y_test,clf_log.predict(x_test))
score_svc=accuracy_score(y_test,clf_svc.predict(x_test))
![]()
6、✌ 模型评估
完成模型训练以及测试集的结果预测后,需要评估模型的性能,包括:
- (1)计算测试集分类准确率
- (2)预测结果的展示
6.1 ✌ 测试集准确率
分类准确率是指所有分类正确的百分比。
准确率 = 分类正确的样本数 / 总样本数
这里可以直接使用sklearn工具中的metrics.accuracy_score()计算分类准确率。
from sklearn import metrics
# 逻辑回归准确率
score_log=accuracy_score(y_test,clf_log.predict(x_test))
score_log
![]()
6.2 ✌ 不同分类器的结果分析
pred_score=[('DecisionTree',[score_dtc]),
('RandomForest',[score_rfc]),
('Logistic',[score_log]),
('SVM',[score_svc])]
df=pd.DataFrame.from_dict(dict(pred_score),orient='index',columns=['Score'])
df.plot(kind='bar',ylim=(0.7,1),figsize=(8,6),align='center',colormap='Accent')
plt.ylabel('Accurancy Score')
plt.title('Distribution by Classifier')
plt.legend()
plt.show()
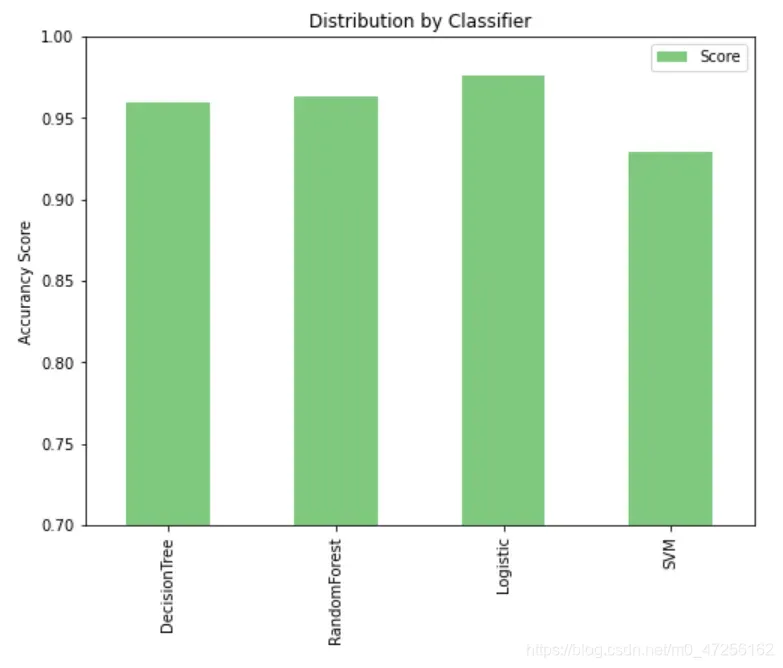
可以看到,线性分类器(逻辑回归)的准确率较高。
6.3 ✌ 预测结果展示
clf_log.predict(x_test)[0:100]

文章出处登录后可见!