如果使用原来的7.节的sigmode作为最后一层的激活层会有什么问题?(Design 10 Outputs using Sigmode?)
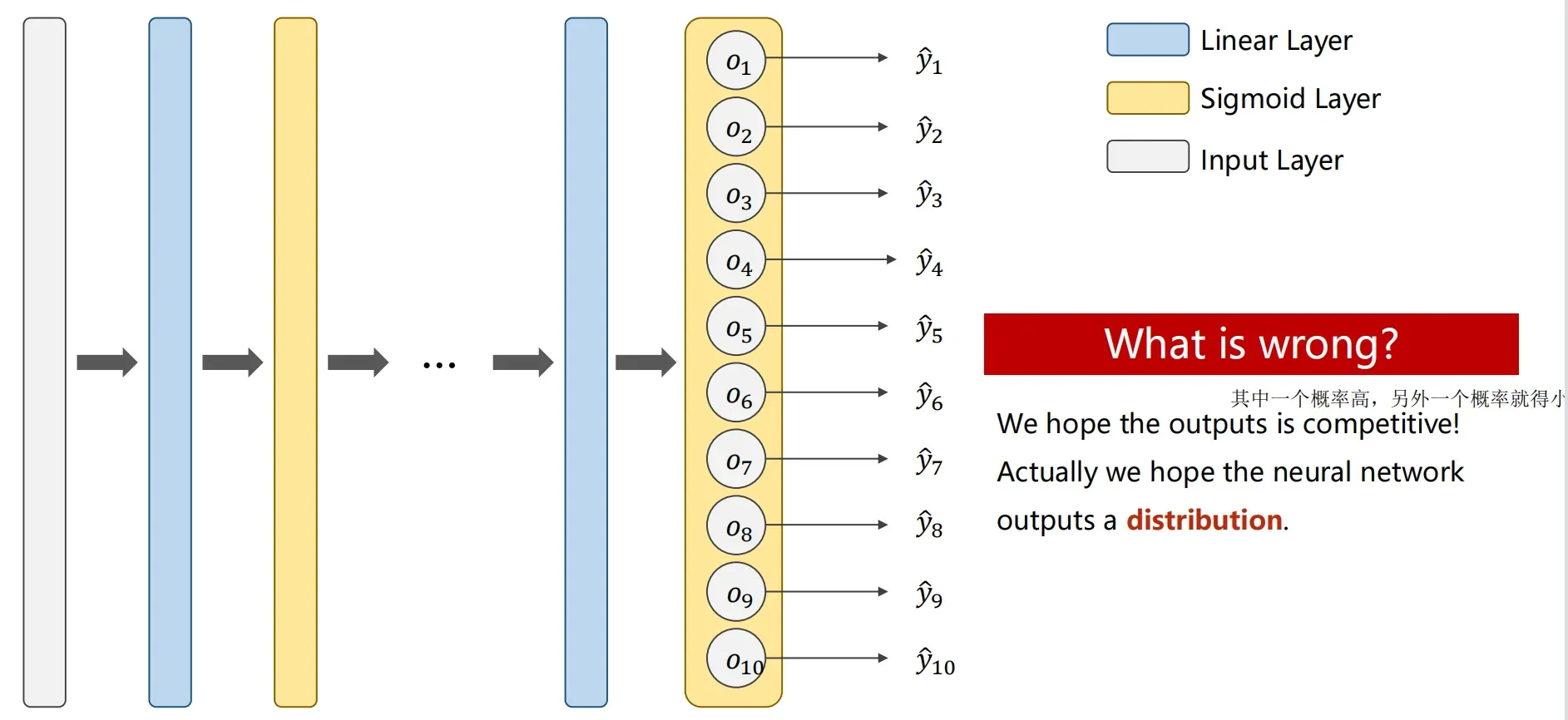
如果使用sigmode函数就将多分类问题看成多个二分类问题(二分类实现多分类 – 努力的孔子 – 博客园),这样加大了计算的复杂度,并且最后的输出也不是一个分布,而是多个二分类的概率,我们期望的是输出的10类,每一类都有自己的概率(并且 > 0),它们的概率之和为1。
Output a Distribution of prediction with Softmax
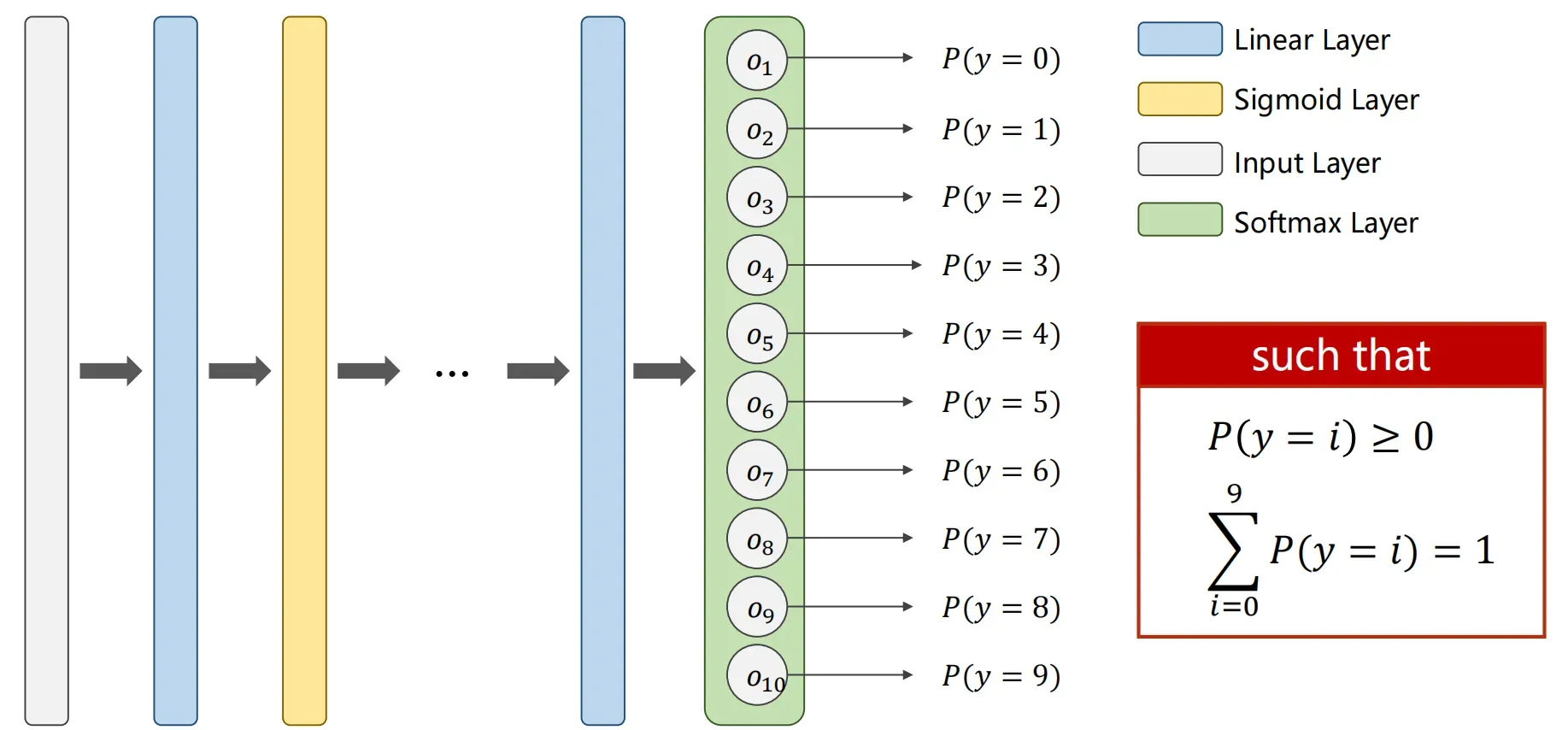
Suppose 𝑍𝑙 ∈ ℝ𝐾 is the output of the last linear layer, the Softmax function:
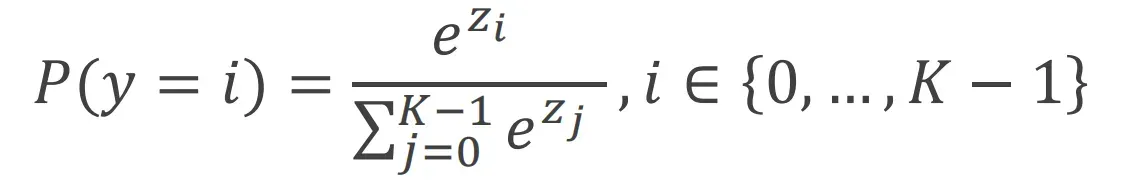
关于softmax如何将多个输出变成“ 每一类概率 > 0,它们的概率之和为1 ”的方法可以看:(如下图所示)Softmax归一化【把数据压缩到[0,1],把量纲转为无量纲的过程,方便计算、比较等】_马鹏森的博客-CSDN博客_softmax归一化
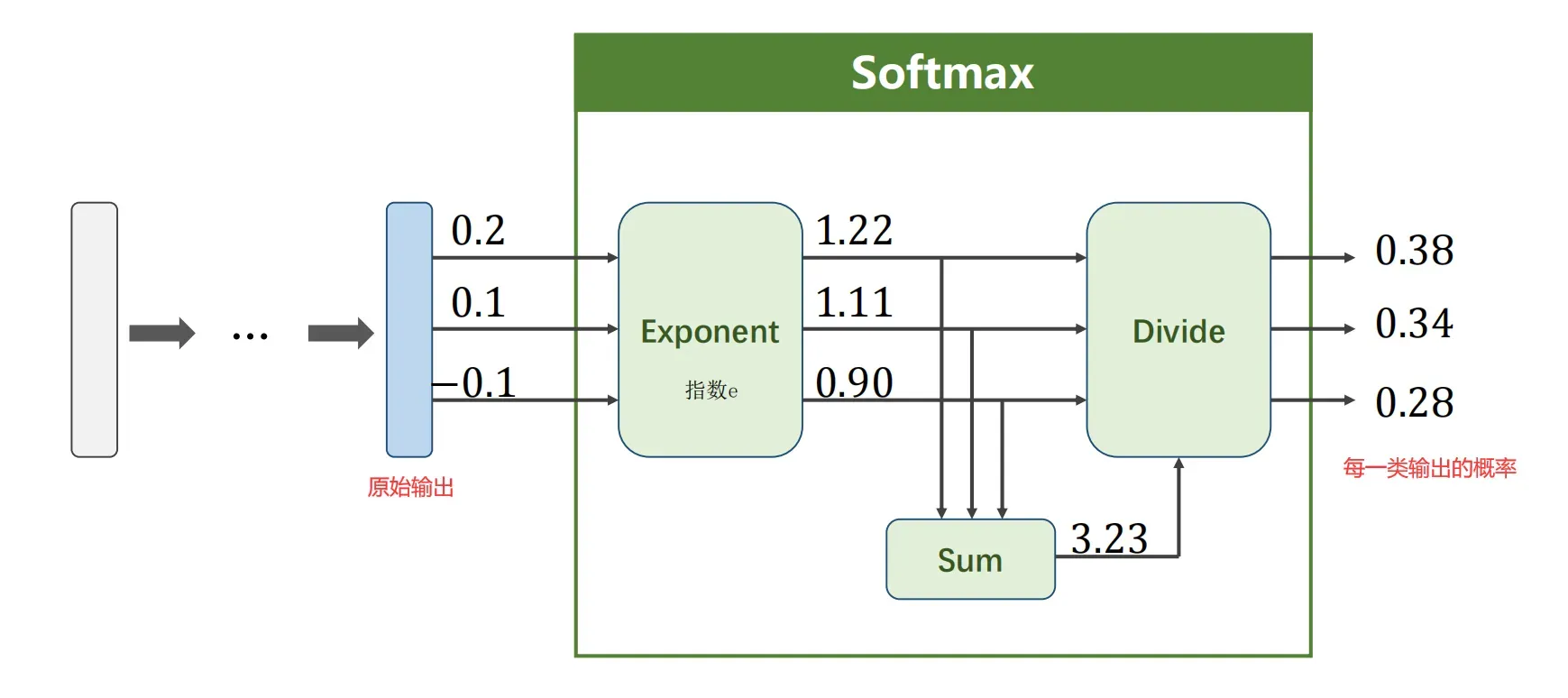
得到了每一类输出的概率,怎么计算损失呢?损失函数又该如何选择呢?
这里我们使用NLLLoss(负对数似然损失)作为损失函数,计算由softmax的输出的log值 再与 -Y(target)相乘 从而计算损失
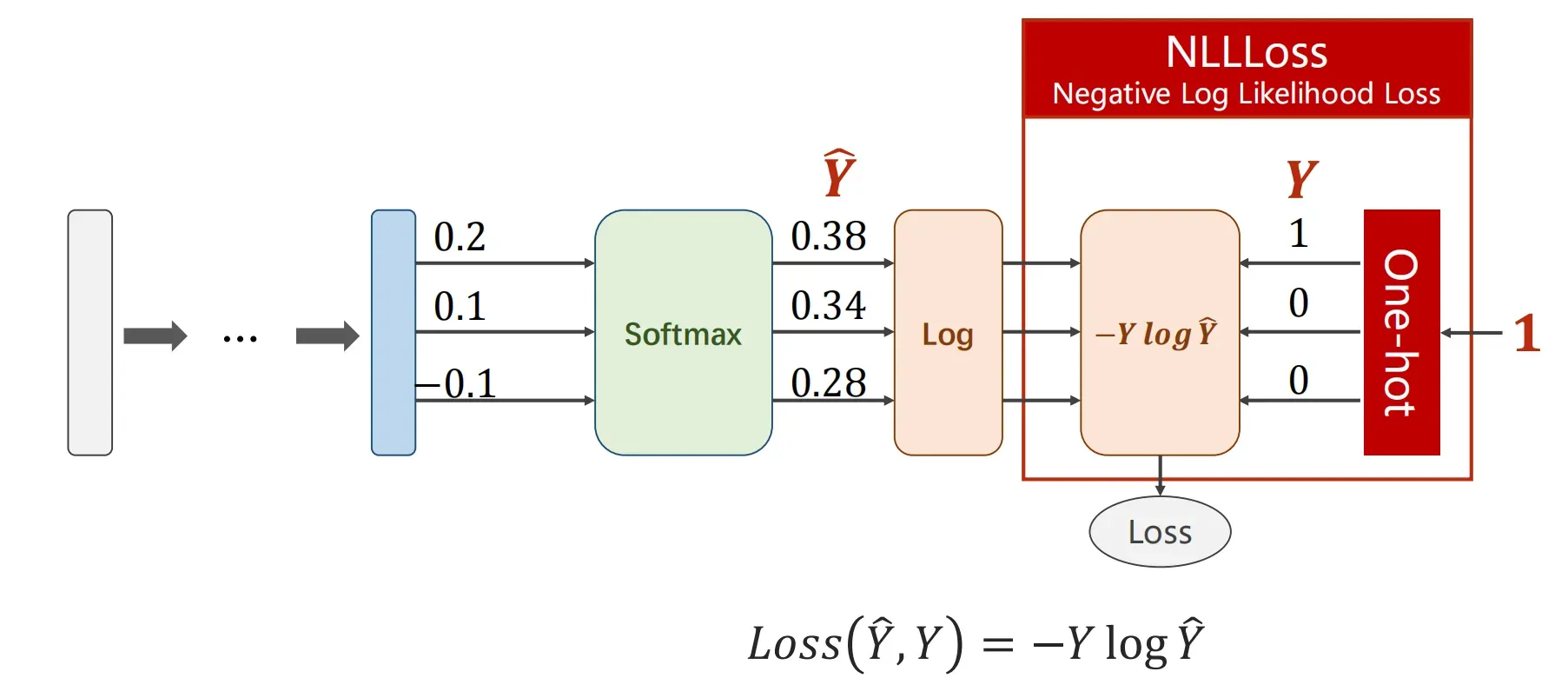
此时使用NLLLoss作为损失函数具体的代码如下:
import numpy as np
y = np.array([1, 0, 0])
z = np.array([0.2, 0.1, -0.1])
y_pred = np.exp(z) / np.exp(z).sum()
loss = (- y * np.log(y_pred)).sum()
print(loss)此时我们可以通过使用CrossEntropyLoss(交叉熵损失) 来简化上述过程(也就是简化多分类问题)
注意:当使用CrossEntropyLoss做损失的时候,我们最后一层不做激活,因为CrossEntropyLoss自带softmax激活
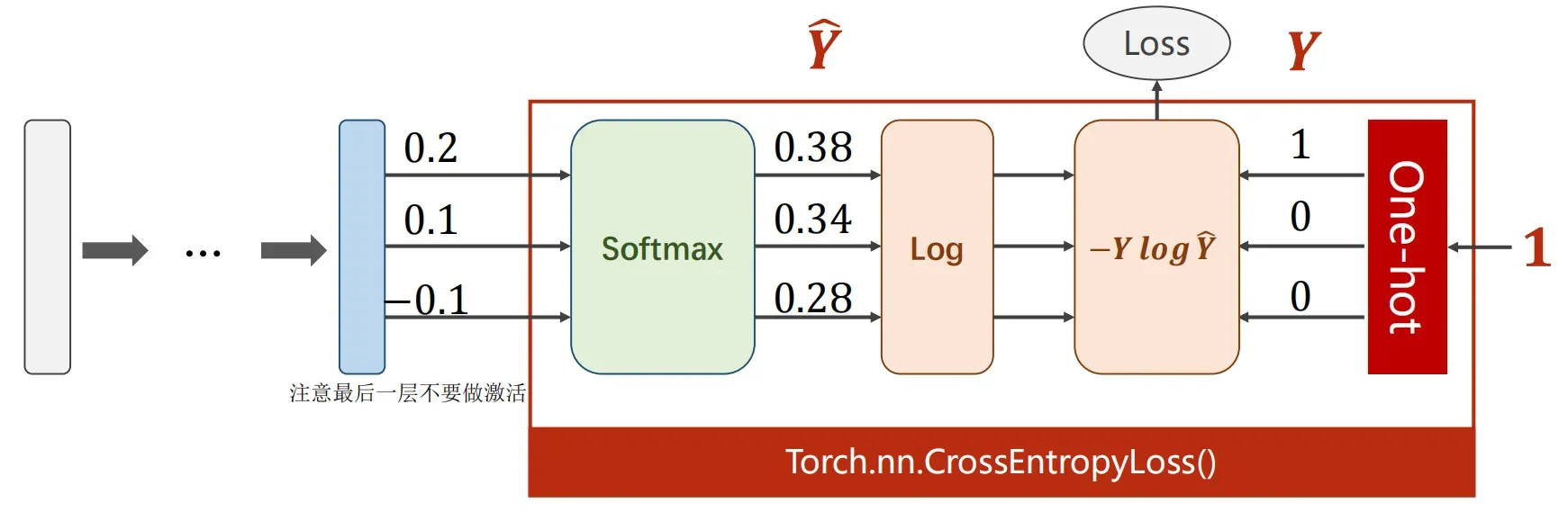
![]()
import torch
# 这里的意思是第0类为真正的分类,也就是说输出的预测值应该是第0类
y = torch.LongTensor([0])
z = torch.Tensor([[0.2, 0.1, -0.1]])
criterion = torch.nn.CrossEntropyLoss()
loss = criterion(z, y)
print(loss)batch计算损失
上述代码为一个样本与目标值之间的损失,如果来了三个样本,要得到他们总体的loss,【这里是为了适用以下batch情况下计算损失】即使用:
import torch
criterion = torch.nn.CrossEntropyLoss()
Y = torch.LongTensor([2, 0, 1])
Y_pred1 = torch.Tensor([[0.1, 0.2, 0.9],
[1.1, 0.1, 0.2],
[0.2, 2.1, 0.1]])
l1 = criterion(Y_pred1, Y)
print("Batch Loss1 = ", l1.data)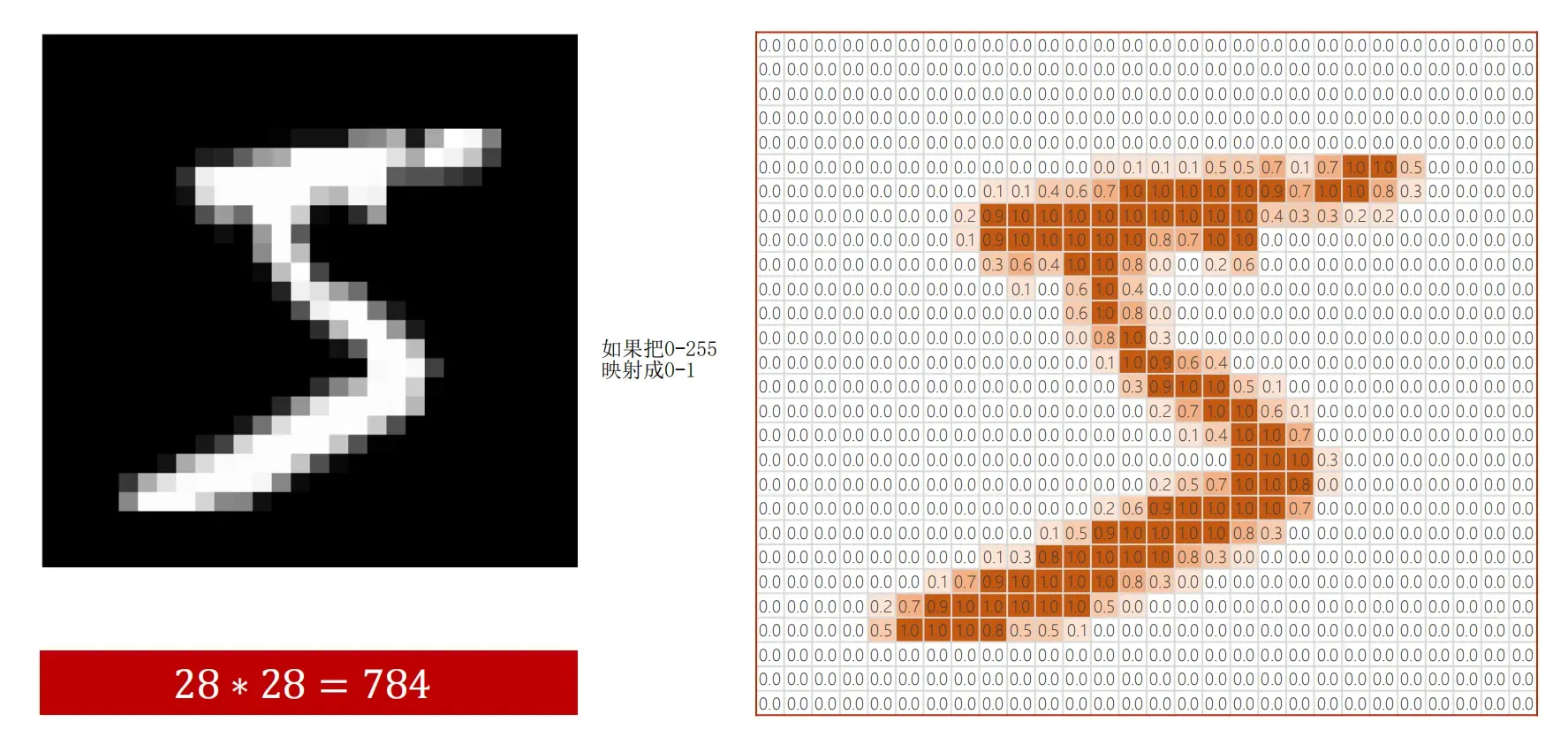
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import torch.nn as nn
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(), # Convert the PIL Image to Tensor.(N(样本数),1,28,28)
transforms.Normalize((0.1307, ), (0.3081, )) # 将每一处的像素值转到 0-1 的正态分布上
])
# 1. Prepare Dataset
train_dataset = datasets.MNIST(root='../../data/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../../data/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# 2. Design Model
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.linear1 = nn.Linear(784, 512)
self.linear2 = nn.Linear(512, 256)
self.linear3 = nn.Linear(256, 128)
self.linear4 = nn.Linear(128, 64)
self.linear5 = nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.linear1(x))
x = F.relu(self.linear2(x))
x = F.relu(self.linear3(x))
x = F.relu(self.linear4(x))
return self.linear5(x)
model = Net().to(device)
# 3. Construct Loss and Optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1, momentum=0.5)
# 4. Train and Test
def train(epoch):
running_loss = 0.0
for batch_inx, data in enumerate(train_loader, 0):
input, target = data # input(64,1,28,28) target(64,)
input = input.to(device)
target = target.to(device)
output = model(input) # input(64,10)此时output输出该图像属于10类中每一类的概率
loss = criterion(output, target) # 计算的是一个batch(64个样本)总体的loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_inx % 300 == 299:
print('[eopch is: %d, current iteration is %d] loss: %.3f' % (epoch+1, batch_inx+1, running_loss/300))
running_loss = 0.0
if epoch%5 == 0:
torch.save(model.state_dict(), 'minist.pth')
def model_test():
correct = 0 # 正确的样本数
total = 0 # 总共实验多少个样本
with torch.no_grad():
for data in test_loader:
input_test, target_test = data
input_test = input_test.to(device)
target_test = target_test.to(device)
output_test = model(input_test)
_, predicted = torch.max(output_test.data, dim=-1)
total += target_test.size(0)
correct += (predicted == target_test).sum().item()
print('Accuracy on test set: %d %%' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
if epoch%2 == 0: # 每两个epoch进行一次test
model_test()
输出:
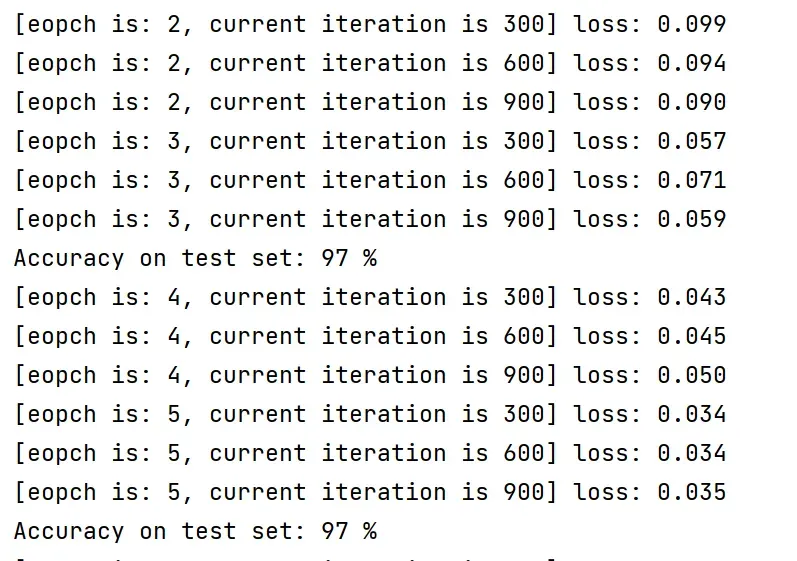
《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
使用卷积替换全连接从而提升准确率
以上代码是使用纯全连接层实现的,假如我们使用卷积、池化…操作,又该如何实现呢?
只需要将design model部分更改即可:
# 2. Design Model
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.polling = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.fc = nn.Linear(320, 10)
def forward(self, x):
# Flatten data form (n,1,28,28) to (n,784)
batch_size = x.size(0)
x = F.relu(self.polling(self.conv1(x)))
x = F.relu(self.polling(self.conv2(x)))
x = x.view(batch_size, -1)
x = self.fc(x)
return x
可以看到,准确率由原来的 97% 提升到了 98%,也就是说错误率由原来的 3% 降低到了 2%,总体提升了33%的性能,而不是提升了1%,Hhhhhhhhhh….
文章出处登录后可见!