Abnormal event detection in videos using generative adversarial nets
Comments: Best Paper / Student Paper Award Finalist, IEEE International Conference on Image Processing (ICIP), 2017
Abstract
使用正常帧和对应的光流图来训练GAN学习场景的正态表示。
Conclusion
作者提出了一种基于两个条件gan的生成式深度学习方法。由于GANs仅使用正常数据进行训练,因此无法生成异常事件。在测试时,使用真实图像和生成图像之间的局部差异来检测可能的异常。在标准数据集上的实验结果表明,作者的方法在帧级和像素级评估协议方面都优于目前的水平。
Introduction
Generative adversarial nets
Image-to-image translation with conditional adversarial networks
Method
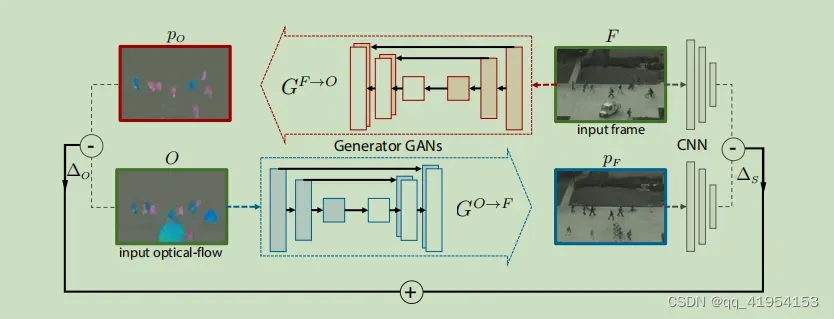
是训练视频的第t帧,
是使用
生成的光流图。作者训练了两个网络一个是
从帧生成光流,一个是
从光流生成帧。模型具体结构采用论文Image-to-image translation with conditional adversarial networks,包括一个条件生成器G和一个条件分类器D。G将图片
和一个噪声向量
作为输入然后产生一个输入
维度相同但是以不同channel表示,如对于
是帧,p是对应光流,对于D输入两个图(或为(x,y)或为(x,p))输出一个标量代表两个输入都为真实数据的概率
G和D都使用条件GAN的损失和重构损失进行训练如,训练集由帧和光流图对组成,
其中
是用水平、垂直和幅度分量的标准三条通道表示的(这是由光流的计算方式决定的不同的计算方式可能有所不同作者此文使用的光流计算方法比较旧了)重构损失为:
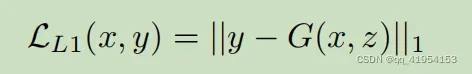
实验
异常分数计算
参照模型图对于用帧构建光流测试时误差为,类似可以获得外观的构建误差。如模型图(bottom)所示,网络在
的异常区域产生“blobs”。即使这些斑点的外观与实际图像F中的对应区域完全不同,我们也可以从经验上观察到,F和
之间简单的逐像素差比在光流通道中计算出的差值信息更少。出于这个原因,使用另一个在ImageNet上预先训练过的AlexNet网络来计算“语义”差异.注意,AlexNet是使用监督数据进行训练的,监督数据是ImageNet中包含的图像和对象标签对。然而ImageNet并没有对人群异常行为进行监督,而是将网络训练为识别一般对象。设
为F在该网络中的conv5表示,
为外观重建的对应表示。选择AlexNet的第5层卷积层(池化之前)是因为它在一个足够抽象的空间中表示输入信息,并且是最后一层保留几何信息。现在可以计算F和
之间基于语义的差异:
最后,将ΔS和ΔO进行融合,得到唯一的异常图。具体说,首先上采样
获得
与
的分辨率一致然后
对其对应的通道值范围进行归一化.,计算所有输入帧产生
则归一化光流为:
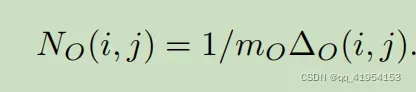
实验结果
数据集使用UCSD pedestrians、UMN
输入resize到256X256,随机梯度下降momentum=0.5,batch为1,网络训练10个epoch
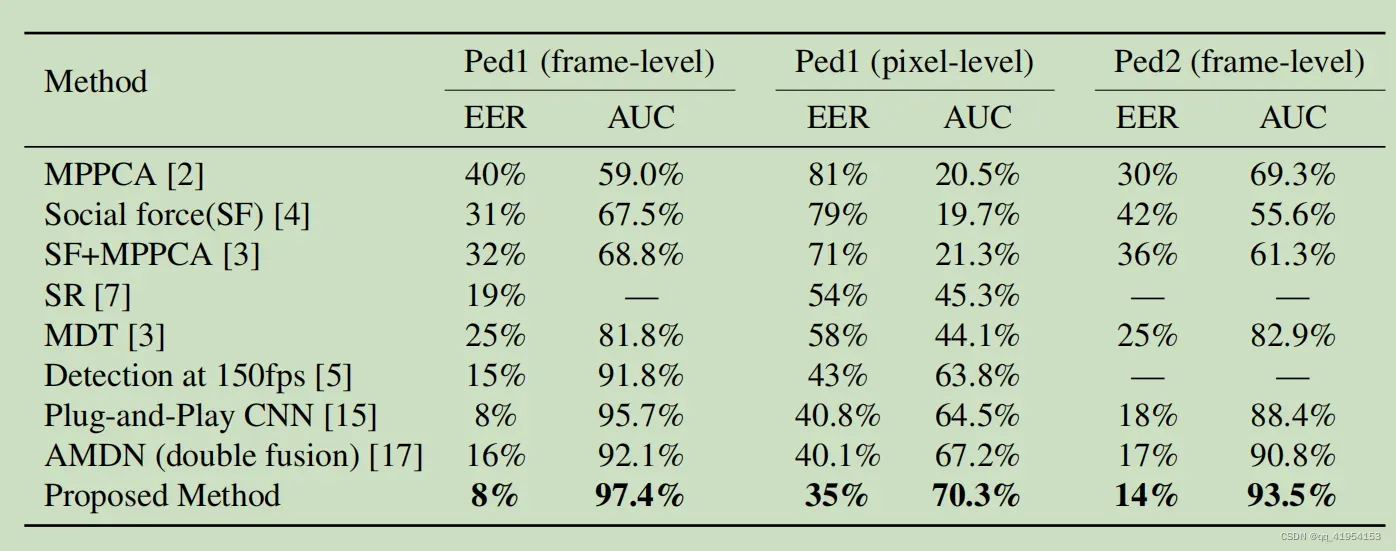
作者最终帧级别 AUC:
ped1(0.974)
ped2(0.935)
Discussion
- 从外观构建光流即运动其实暗含了外观和运动的一致性在里边,这种方式应该也利用到了运动的信息,效果非常好,比利用lstm提取信息效果好很多,利用光流是比较明显的运动而LSTM等很难说利用的是什么信息。而且双模型结果融合。
- 对于外观差异获取异常分数不用重构误差而使用高级语义。作者提出的这个方法是否比重构误差做异常分数有用未做对比试验。
文章出处登录后可见!